 虹科干货 | 什么是数据库一致性?
虹科干货 | 什么是数据库一致性?
数据库一致性(database consistency)由一组值定义,数据库系统中的所有数据点都必须与这些值保持一致,才能正确读取和接受数据。如果任何不符合先决条件值的数据进入数据库,将导致数据集出现一致性错误。数据库一致性通过建立规则来实现。任何写入数据库的数据事务都只能按照数据库开发人员制定的规则,包括特定约束、触发器、变量、级联等来更改受影响的数据。
例如,假设您某地区的交通安全研究所工作。您的任务是创建一个新驾照数据库。在过去的十年中,该地区的人口激增,因此需要为所有首次申领驾照的人提供新的字母和数字格式。在您的数据库中,该地区驾照的新设定值如下:1个字母+ 7个数字,现在每个条目都必须遵循这一规则。如果输入"C08846024",则返回错误。为什么?因为输入的值是1个字母+8个数字,这实质上是一种不一致的数据形式。
一致性还意味着,一个表中任何一个特定对象的任何数据更改都需要在该对象所在的所有其他表中进行更改。继续以驾照为例,如果驾驶员的家庭地址发生变化,则必须在所有存在该地址的表中体现该更新。如果一个表中是旧地址,而其他所有表中却是新地址,这也是数据不一致的典型例子。
注意:数据库一致性并不保证在任何给定事务中引入的数据是正确的,它只保证在系统中写入和读取的数据符合所有有资格进入数据库的数据的先决条件。更简单地说,在上面的示例中,您可以输入符合1个字母+ 7个数字规则的数据事务,但这并不能保证数据与实际的驾照相对应。数据库一致性并不考虑数据所代表的内容,只考虑其格式。
为什么数据库一致性很重要?
一致的数据使数据库能够像运转良好的机器一样运行。已建立的规则/值可将不一致的数据排除在主数据库和副本之外,从而保持其操作顺利:
准确性
增加数据库空间
更快、更高效的数据检索
数据库一致性对所有输入数据进行管理。因此,尽管数据库在接受新数据时会发生变化,但它至少会根据一开始制定的验证规则一致地发生变化。如今,全球每天都有数十亿美元的决策是根据数据库的一致性做出的。当实时信息成为现代数字业务的基础时,制定验证规则以确保数据集没有错误信息就显得至关重要。因为数据错误增加延迟,损害实时体验。
数据库一致性示例
现实世界中有哪些数据库一致性操作的例子?我们已经在上文的驾照数据库场景中探讨了一个例子。现在我们转向银行业看看。
假设您正在将资金从一个账户转入另一个账户。您刚刚将12000元转入一个已有3000元的账户中。假设正确刷新后,账户余额会显示为15000元。但是,新余额现在显示为0元,说明最新的操作并没有反映在您的余额中。这种技术上的疏忽是数据库弱一致性的一个典型例子。诸如此类的问题可能会损害银行声誉并造成巨大损失。对于任何行业的数据库开发人员和消费者来说,数据库系统的强一致性正变得越来越不可或缺。
强一致性 vs 弱一致性
强一致性:主节点、副本及其所有相应节点中的所有数据都符合验证规则,并且在任何给定时间内都是相同的。有了强数据库一致性,无论从哪个客户端访问数据—客户将始终看到遵循数据库既定规则的更新版本数据。
弱一致性:无法保证主节点、副本节点或节点中的数据在任何时刻都是相同的。某个客户可以访问数据,并看到通过验证规则的信息,但可能不是最近更新的数据,从而导致一致性错误。
Redis Enterprise(Redis企业版数据库)的Active-Active地理分布允许多个主数据库,使您能够灵活地处理越来越大的工作负载。所谓"Active-Active",是指数据库的每个实例都可以接受对任何键的读写操作。每个数据库实例,无论距离多远,都是网络上的一个对等节点。这意味着,当对任何实例进行写操作时,该节点会自动向网络上的所有其他实例发送消息,说明缓存中的哪些内容发生了更改,并确保所有实例保留一致的缓存数据集。
Redis Enterprise独特的Active-Active地理分布采用了复杂的算法,旨在处理可能导致缓存不一致的潜在写入冲突。这些算法基于无冲突复制数据类型(CRDT),确保来自多个副本的写入数据能够以有效保持一致性的方式进行合并。
虹科是Redis企业版数据库中国区战略合作伙伴,可为您提供技术支持和解决方案服务。Redis企业版软件(Redis Enterprise)是企业级的数据库软件,也是一款实时数据平台,为全球超过8500家知名企业提供实时数据服务。具有线性可扩展性、高可用性、持久性、备份和恢复、地理分布、分层内存访问、多租户、安全性等8大核心功能、拥有RediSearch、RedisJSON等7大【Redis企业版特有模块】,可以任何规模在云、本地和混合部署中运行现代应用程序,提供无服务器、多模型的数据库解决方案。
一致性级别
一致性级别是另一组先决条件值,它决定了有多少个副本或节点必须响应新的允许数据,然后才被确认为有效事务。这种操作可以根据每笔事务进行更改。例如,程序员可以规定,在确认数据一致性之前,只有两个节点需要读取新输入的数据。一旦数据跨过了这个界限,它就会被认为是一致的数据。
隔离级别
隔离级别是数据库ACID(原子性、一致性、隔离性、持久性)属性的一部分。ACID是SQL数据库一致性的基本概念,也是某些数据库为优化数据库一致性而遵循的基本概念。隔离(Isolation)是ACID属性之一,它将某些数据块与特定数据库网络中的所有信息隔离开来,使其不会被其他用户事务修改。隔离被用来减少并发事务中产生的无关数据的读写。
有四种类型的隔离级别:
(1)未提交读取:最低级别。如果前一个事务对该行进行了未提交更新,则停止该行的更新。
(2)已提交读取:不允许"脏读"。如果事务已经更新,但尚未提交,则会阻止任何读取或写入。
(3)可重复读取:该级别使正在读取的数据行不会被访问和更新。
(4)可序列化:最高隔离级别,可序列化通常锁定整个表,而不是特定的数据行。
复制过程中的一致性
Redis企业版数据库软件能够将数据复制到另一个数据库实例,以获得高可用性,并将内存中的数据永久持久化到磁盘上,以获得持久性。使用WAIT命令,可以控制复制和持久化数据库的一致性和持久性保证。
向数据库发布的任何更新通常按以下流程执行:
(1)应用程序发出写操作
(2)代理与系统中包含给定键的正确主(也称为“master”)"分片"通信
(3)分片写入数据并向代理发送回执
(4)代理将回执发送给应用程序
(5)主分片向副本发送写入信息
(6)副本将写入确认发回给主服务器
(7)写入副本的内容被持久化到磁盘上
(8)副本内部确认写入
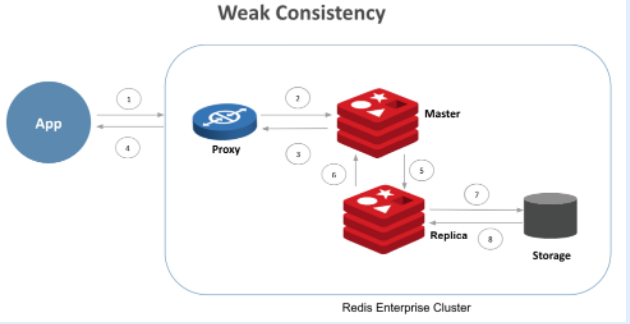
使用WAIT命令,应用程序可以要求仅在复制或持久性在副本上确认后等待确认。
命令的写操作流程如下所示:
(1)应用程序发出写操作
(2)代理与系统中包含给定key的正确主 "分片"通信
(3)复制将更新传递给副本分片
(4)复制将更新持久化到磁盘(假设选择了每次写入都自动更新)
(5-8)通过步骤5至8,确认从副本一直发回代理。
通过此流程,应用程序只有在复制到副本和持久化存储实现耐久性后,才能从写入中获得确认。
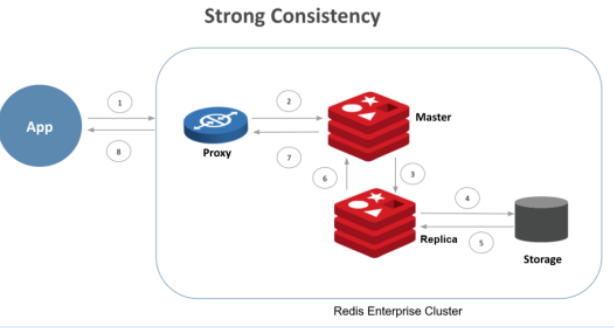
使用WAIT命令,应用程序可以保证,在节点故障或节点重新启动的情况下也会记录已确认的写入。
数据库一致性常见问题解答(QA)
Q:数据一致性意味着什么?
A:如果数据在同一时间出现在所有相应的节点中,无论用户在哪里访问数据,数据都是一致的。
Q:数据一致性与数据库一致性是一回事吗?
A:数据一致性是指数据在整个网络中以及在使用该数据的众多应用程序之间尽可能保持一致的过程。数据库一致性要求对进入网络的数据制定验证规则,以使其在公式上与表中的所有其他数据保持一致。
Q:什么是最终一致性?
A:通过最终一致性,经过更新的数据最终将反映在存储该数据的所有节点中。最终,通过最终一致性,无论任何客户端在网络中访问数据,所有节点都将生成相同的数据。
Q:关系数据库中的单个表包括?
A:关系数据库中的所有数据都存储在表中,表由行和列组成。数据点被组织在这些行和列中。行通常被称为 "记录",代表数据类别,而列或 "字段 "则代表 "实例"。在数据库中可以找到表格,其基于主题的设计有助于防止数据冗余。
Q:关系数据库由哪些部分组成?
A:关系数据库由表组成
Q:ACID模型与BASE模型相比有何不同?
A:ACID和BASE(基本可用、软状态、最终一致)模型之间的主要区别在于,ACID致力于优化数据库一致性,而BASE则加强高可用性。ACID可保持事务一致性,因此如果您采用BASE模型,请确保一致性仍是重中之重,并得到彻底解决。
Q:Redis数据库是否一致?
A:当Redis用作缓存时,一致性问题可能发生在Redis实例(主/副本)之间,以及Redis缓存和作为主数据库的Redis之间。在这种情况下,如果两者之间的数据不匹配,数据就会不一致。对于开源Redis来说,一致性较弱,但Redis Enterprise的Active-Active Geo-Distribution提供了较强的最终一致性。
审核编辑 黄宇
-
数据库
+关注
关注
7文章
3866浏览量
64956
发布评论请先 登录
相关推荐
如何使用cmp进行数据库管理的技巧
Oracle报错“system01.dbf需要更多的恢复来保持一致性”的数据恢复案例
一致性测试系统的技术原理和也应用场景
异构计算下缓存一致性的重要性
Oracle数据恢复—异常断电后Oracle数据库启库报错的数据恢复案例
数据库数据恢复—Oracle数据库文件system01.dbf损坏的数据恢复案例

铜线键合焊接一致性:如何突破技术瓶颈?

请问ESP-NOW对数据的完整性和一致性有校验吗?
为什么主机厂愈来愈重视CAN一致性测试?

QSFP一致性测试的专业测试设备
铜线键合焊接一致性:微电子封装的新挑战

企业数据备份体系化方法论的七大原则:深入理解数据备份的关键原则:应用一致性与崩溃一致性的区别

深入理解数据备份的关键原则:应用一致性与崩溃一致性的区别






 工商网监
工商网监
评论