 AI大模型时代需要什么样的网络?
AI大模型时代需要什么样的网络?
ChatGPT 的爆火掀起了 AI 大模型狂飙热潮,随着国内外原来越多的 AI 大模型应用落地,AI 算力需求快速增加。在算力的背后,网络起到至关重要的作用——网络性能决定 GPU 集群算力,网络可用性决定 GPU 集群算力稳定性。因此,高性能与高可用的网络对 AI 大模型的构建尤为重要。
6 月 26 日,腾讯云举办《面向 AI 大模型的高性能网络》沟通会,首次对外完整披露自研星脉高性能计算网络,并梳理了腾讯的网络架构演进历程。会后,腾讯云副总裁王亚晨、腾讯云数据中心网络总监李翔接受了 InfoQ 在内的媒体采访,进一步分享面向 AI 大模型的高性能网络是如何构建的。
据了解,星脉网络具备业界最高的 3.2T 通信带宽,可提升 40% 的 GPU 利用率、节省 30%~60% 的模型训练成本,进而能为 AI 大模型带来 10 倍通信性能提升。基于腾讯云新一代算力集群,可支持 10 万卡的超大计算规模。
王亚晨表示:“星脉网络是为大模型而生。它所提供的大带宽、高利用率以及零丢包的高性能网络服务,将助力算力瓶颈的突破,进一步释放 AI 潜能,全面提升企业大模型的训练效率,在云上加速大模型技术的迭代升级和落地应用。”
AI 大模型时代需要什么样的网络? 大带宽、高利用率、无损
AI 大模型训练需要海量算力的支撑,而这些算力无法由单台服务器提供,需要由大量的服务器作为节点,通过高速网络组成集群,服务器之间互联互通,相互协作完成任务。有数据显示,GPT-3.5 的训练使用了微软专门建设的 AI 计算系统,由 1 万个 V100 GPU 组成的高性能网络集群,总算力消耗约 3640 PF-days (假如每秒计算一千万亿次,需要计算 3640 天)。
如此大规模、长时间的 GPU 集群训练任务,仅仅是单次计算迭代内梯度同步需要的通信量就达到了百 GB 量级,此外还有各种并行模式、加速框架引入的通信需求。如果网络的带宽不够大、延时长,不仅会让算力边际递减,还增加了大模型训练的时间成本。因此,大带宽、高利用率、无损的高性能网络至关重要。
王亚晨表示,大模型运算实际上是一个通信过程,一部分 GPU 进行运算,运算完成后还需要与其他 GPU 之间交互数据。通信带宽越大,数据传输越快,GPU 利用率越高,等待时间就会越少。此外,大模型训练对时延和丢包要求也比较高。“假设有很多 GPU 运算同一个任务,因为有木桶效应存在,一定要等花费时间最长的 GPU 运算完之后,才能完成一个运算任务。AI 对于时延的敏感度比 CPU 高很多,所以一定要把木桶效应消除,把时延控制在非常短的水平,让 GPU 的效率更高。此外,和带宽、时延相比,丢包对 GPU 效率的影响更加明显,一旦丢包就需要重传,重新进行 GPU 的训练。”
王亚晨认为,大集群不等于大算力。集群训练会引入额外的通信开销,导致 N 个 GPU 算力达不到单个 GPU 算力的 N 倍。这也意味着,一味地增加 GPU 卡或计算节点,并不能线性地提升算力收益。“GPU 利用率的合理水平大概是在 60% 左右。”王亚晨说道。
要想通过集群发挥出更强的算力,计算节点需协同工作并共享计算结果,需要优化服务器之间的通信、拓扑、模型并行、流水并行等底层问题。高速、低延迟的网络连接可以缩短两个节点之间同步梯度信息的时间,使得整个训练过程变得更快。同时,降低不必要的计算资源消耗,使计算节点能够专注于运行训练任务。
AI 大模型驱动 DCN 网络代际演进
据介绍,腾讯网络主要提供的功能是“连接”,一是连接用户到机器的流量,二是连接机器到机器的流量。目前,腾讯的网络架构主要分三大部分:
ECN 架构,表示不同类型的客户通过多种网络方式接入云上虚拟网络,这一块主要是外联架构,主要包括终端用户、企业用户、物联网用户分别通过运营商专线、企业专线、边缘网关接入腾讯数据中心。
DCI 网络,主要是数据中心之间的互联,实现一个城市多数据中心或者多个城市的数据中心进行互联,底层会用到光纤传输。
DCN,主要是数据中心的网络,这部分的任务是实现数据中心里面超过 10 万或者几十万服务器进行无阻塞的连接。
腾讯通过 ECN、DCI、DCN 等网络,把用户和业务服务器连接起来,并且把数百万台服务器连接起来。
王亚晨表示,AI 大模型的发展驱动了 DCN 网络代际演进。
在移动互联网时代,腾讯的业务以 to C 为主,数据中心网络服务器规模并不大,当时主要解决的是数据中心、服务器之间的互联,以及运营商之间的互联。所以那时数据中心流量特征很明显,基本都是外部访问的流量,对网络的时延和丢包要求也不高。
随着移动互联网以及云的快速发展,数据中心网络流量模型发生了变化,除了有从运营商访问过来的南北向流量,也有数据中心之间互访的东西向流量,对网络的时延要求也是从前的 10 倍。为了降低设备故障对网络的影响,腾讯采用多平面设计,并引入了控制器的概念,把转发面和控制面进行分离。用定制的设备、多平面以及 SDN 的路由器控制,将故障的解决时间控制在一分钟之内。
在 AI 大模型时代,数据中心网络流量模型进一步发生变化。“到了 AI 大模型时代,我们发现东西向流量比以前大了很多,尤其是 AI 在训练的时候,几乎没有什么南北向流量。我们预计如果大模型逐渐成熟,明年大模型数据中心流量南北向流量可能会有所增长,因为推理需求会上来。但就现在而言,东西向流量需求非常大,我们 DCN 网络设计会把南北向流量和东西向流量分开,以前是耦合在一张网络里,基础网络都是一套交换机,只是分不同层。但到了 GPU 时代,我们需要专门为 GPU 构建一层高性能网络。”王亚晨说道。
基于此,腾讯打造出了高性能网络星脉:具备业界最高的 3.2T 通信带宽,能提升 40% 的 GPU 利用率,节省 30%~60% 的模型训练成本,为 AI 大模型带来 10 倍通信性能提升。基于腾讯云新一代算力集群 HCC,可支持 10 万卡的超大计算规模。
高性能网络星脉是如何设计的?
据李翔介绍,腾讯网络大概由大大小小几十个组件组成,数据中心网络是其中最大、历史最悠久的一个。在 PC 和移动互联网时代,数据中心网络主要解决的是规模问题。而进入算力时代,业务对算力网络有了更高的要求。
“举个例子,如果说过去两个阶段数据中心网络是‘村村通’,解决大规模部署和广覆盖的问题,那么在算力时代,数据中心网络就是全自动化、无拥塞的高速公路。”李翔表示,AI 大模型对互联有比较高的要求,几千张 GPU 协同计算,如果出现任何一个丢包阻塞,那么全部都要降速,这种降速 1 分钟就有几十万的损失。
基于此,腾讯云开始搭建算力集群。4 月 14 日,腾讯云正式发布面向大模型训练的新一代 HCC(High-Performance Computing Cluster)高性能计算集群。网络层面,计算节点间存在海量的数据交互需求,随着集群规模扩大,通信性能会直接影响训练效率。腾讯自研的星脉网络,为新一代集群带来了业界最高的 3.2T 的超高通信带宽。
据介绍,腾讯对大模型集群网络做了以下几大优化:
(1)采用高性能 RDMA 网络
RDMA(GPU 之间直接通信),是一种高性能、低延迟的网络通信技术,主要用于数据中心高性能计算,允许计算节点之间直接通过 GPU 进行数据传输,无需操作系统内核和 CPU 的参与。这种数据传输方法可以显著提高吞吐量并降低延迟,从而使计算节点之间的通信更加高效。
过往的数据中心 VPC 网络,在源服务器与目标服务器之间传输时,需要经过多层协议栈的处理,过往数据每一层都会产生延迟,而腾讯自研的星脉 RDMA 网络,可以让 GPU 之间直接进行数据通信。
打个比方,就像之前货物在运输途中需要多次分拣和打包,现在通过高速传送带、不经过中间环节,货物直接送到目的地
同时,由于星脉 RDMA 直接在 GPU 中传输数据,CPU 资源得以节省,从而提高计算节点的整体性能和效率。
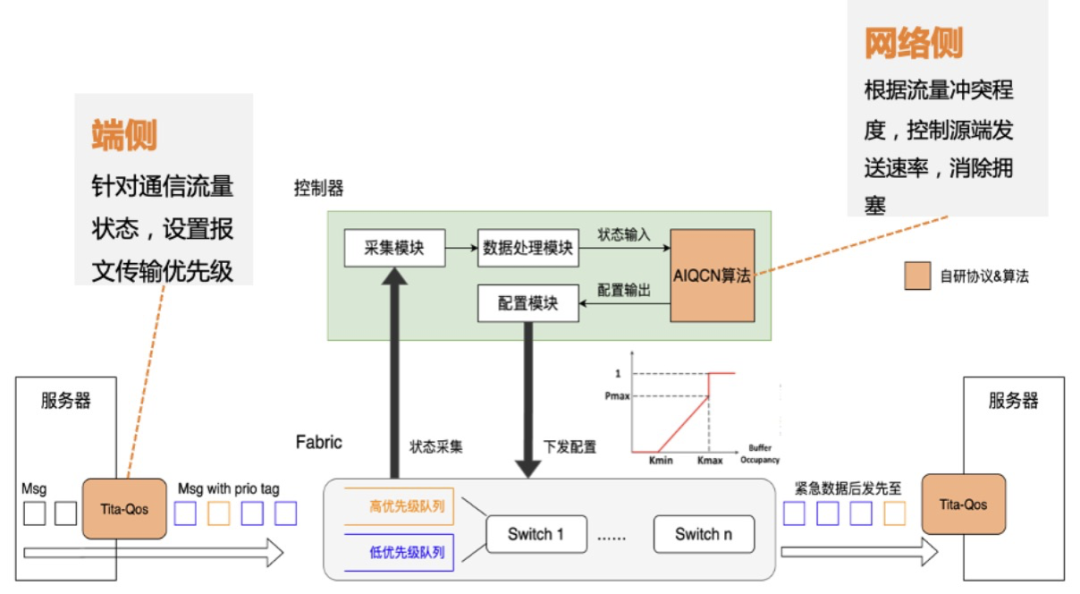
(2)自研网络协议(TiTa)
在网络协议上,腾讯云通过自研 TiTa 协议,让数据交换不拥塞、时延低,使星脉网络可以实现 90% 负载 0 丢包。
网络协议是在计算节点之间传输数据的规则和标准,主要关注数据传输的控制方式,能改善网络连接性能、通信效率和延迟问题。
为了满足大型模型训练中的超低时延、无损和超大带宽要求,传统的网络协议由于其固有的设计与性能限制,无法满足这些需求,还需要对“交通规则”进行优化。
星脉网络采用的自研端网协同协议 TiTa,可提供更高的网络通信性能,特别是在满足大规模参数模型训练的需求方面。TiTa 协议内嵌拥塞控制算法,以实时监控网络状态并进行通信优化,使得数据传输更加流畅且延迟降低。
(3)定制化高性能集合通信库 TCCL
通信库在训练过程中负责管理计算节点间的数据通信。面对定制设计的高性能组网架构,业界开源的 GPU 集合通信库(比如 NCCL)并不能将网络的通信性能发挥到极致,从而影响大模型训练的集群效率。
为解决星脉网络的适配问题,腾讯云还为星脉定制了高性能集合通信库 TCCL(Tencent Collective Communication Library),相对业界开源集合通信库,可以提升 40% 左右的通信性能。
并在网卡设备管理、全局网络路由、拓扑感知亲和性调度、网络故障自动告警等方面融入了定制设计的解决方案。
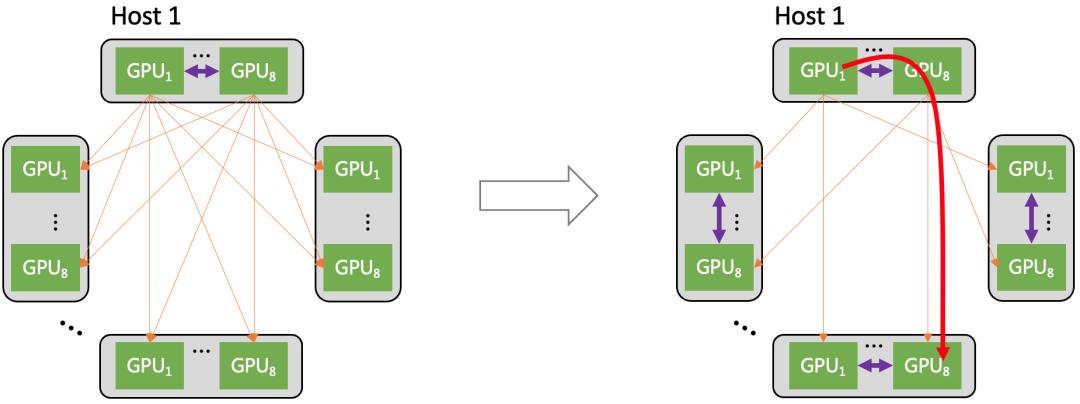
(4)多轨道网络架构
星脉网络对通信流量做了基于多轨道的流量亲和性规划,使得集群通信效率达 80% 以上。
多轨道流量聚合架构将不同服务器上位于相同位置的网卡,都归属于同一 ToR switch;不同位置的网卡,归属于不同的 ToR switch。由于每个服务器有 8 张计算平面网卡,这样整个计算网络平面从物理上划分为 8 个独立并行的轨道平面。
在多轨道网络架构中,AI 训练产生的通信需求(AllReduce、All-to-All 等)可以用多个轨道并行传输加速,并且大部分流量都聚合在轨道内传输(只经过一级 ToR switch),小部分流量才会跨轨道传输(需要经过二级 switch),大幅减轻了大规模下的网络通信压力。
(5)异构网络自适应通信
大规模 AI 训练集群架构中,GPU 之间的通信实际上由多种形式的网络来承载的:机间网络(网卡 + 交换机)与机内网络(NVLink/NVSwitch 网络、PCIe 总线网络)。
星脉网络将机间、机内两种网络同时利用起来,达成异构网络之间的联合通信优化,使大规模 All-to-All 通信在业务典型 message size 下的传输性能提升达 30%。
(6)自研全栈网络运营系统
为确保星脉网络的高可用性,腾讯云还自研了端到端全栈网络运营系统,先是实现了端网部署一体化以及一键故障定位,提升高性能网络的易用性,进而通过精细化监控与自愈手段,提升可用性,为极致性能的星脉网络提供全方位运营保障。
具体应用成效方面,大模型训练系统的整体部署时间可以从 19 天缩减至 4.5 天,保证基础配置 100% 准确,并让系统故障的排查时间由天级降低至每分钟级,故障的自愈时间缩短到秒级。
写在最后
AI 大模型时代给网络带来了新的机遇与挑战。随着 GPU 算力的持续提升,GPU 集群网络架构也需要不断迭代升级。
王亚晨表示,未来,星脉网络将围绕算力网卡、高效转发、在网计算、高速互联四大方向持续迭代。“这四个迭代方向也与我们面临的痛点相关,目前我们重点发力算力网卡和高效转发这两大方向。其中,算力网卡需要与交换机做配合,实现更优的、类似主动预测控制的机制,让网络更不容易拥塞;高效转发方面,之后可能会变成定长包的转发机制,这样也能保证整体效率。”
-
gpu
+关注
关注
28文章
4685浏览量
128642 -
服务器
+关注
关注
12文章
8986浏览量
85122 -
大模型
+关注
关注
2文章
2296浏览量
2401 -
AI大模型
+关注
关注
0文章
307浏览量
280
原文标题:AI 大模型狂飙的背后:高性能计算网络是如何“织”成的?
文章出处:【微信号:AI前线,微信公众号:AI前线】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
智算中心网络交换机需要什么样的缓存架构

ai模型训练需要什么配置
【「大模型时代的基础架构」阅读体验】+ 未知领域的感受
AI智能眼镜都需要什么芯片

ai开发需要什么配置


防止AI大模型被黑客病毒入侵控制(原创)聆思大模型AI开发套件评测4


【飞腾派4G版免费试用】仙女姐姐的嵌入式实验室之五~LLaMA.cpp及3B“小模型”OpenBuddy-StableLM-3B
ChatGPT时代,我们需要什么样的连接器?







 工商网监
工商网监
评论