 3D DRAM还能这样玩?
3D DRAM还能这样玩?
由于受到半导体材料、制造技术和成本等的限制,如何发展芯片就成为了大家的关注重点。尤其是在存储方面,紧随NAND Flash的步伐,DRAM也走上了3D之路。日前,来自东京东京工业大学的科学家发表了一篇论文,并在其中阐述了一种名为BBcube的 3D DRAM 堆栈设计,其顶部配有处理器,可以提供比高带宽内存 (HBM) 高四倍的带宽和五分之一的位访问能量。
根据该研究团队负责人 Takayuki Ohba 教授所说:“BBCube 3D 有潜力实现每秒 1.6 TB 的带宽,比 DDR5 高 30 倍,比 HBM2E 高四倍。”而在本文中,我们摘译了其关于3D DRAM的一些描述,以其给大家一些参考。更多详细内容,请大家点击文末的原文查看。
以下为论文摘译:
随着特征尺寸的不断减小,半导体器件和计算机系统也在不断发展。另一方面,自 20 世纪 80 年代以来,人们主要从单片IC的角度考虑三维技术。从20世纪90年代末开始,3D技术被广泛研究用于混合结构,包括从芯片级到晶圆级的封装,例如如何堆叠半导体元件以及如何通过TSV等垂直互连在堆叠的芯片之间进行连接。
按照这一趋势,计算机系统体积将达到50 mm3,功耗将达到0.5 mW 。即使在如此小型的计算机中,也需要高性能和大存储容量,同时又不牺牲功率效率和散热。然而,传统的二维(2D)缩放和三维(3D)集成方法,例如高带宽内存(HBM)中使用的方法,由于制造成本和所需的良率而不可避免地面临经济危机。
克服这些问题的一种有前途的方法是将 3D 堆叠与高吞吐量相结合,即使用WOW和COW技术将共集成扩展到三维(z 方向) 。具体来说,多晶圆堆叠的 z 高度必须很小,这意味着裸片之间不应有凸块,并且裸片应该很薄,这是 BBCube 的主要特点,而且,由于 TSV 长度短和高密度信号并行性,它可以实现高带宽和低功耗。又因为高密度 TSV 能充当热管,因此,即使在 3D 结构中,也可以实现低温。
二维缩放的制造成本危机
在讨论大批量制造的3D集成之前,有必要调查一下半导体技术发展的现状和未来前景。
由于所需的昂贵的光刻工艺和设施,传统的二维缩放将面临严重的经济危机。降低成本需要采用先进的光刻技术,加上缺陷监控系统等外围支持设施,占生产线总成本的三分之一到四分之一。此外,由于不可避免的隐形缺陷减少,位成本在 20 nm 节点附近饱和。同时,除非有足够的良率,否则即使采用高分辨率光刻,总成本也会增加。这是集成多个小型微处理器裸片(chiplet)的主要原因。
简而言之,虽然缩小芯片尺寸很有用,但就资本投资而言,这种微缩是极其繁重的。迄今为止,我们已经对新制造设施(Fab)进行了大规模投资,考虑到未来两到三代的技术将在没有任何重大技术变化的情况下可用。这是基于半导体领域的经验规则,即由于涉及产品销售和设施折旧之间的权衡,投资后几代才能获得利润。
根据这一经验规则,对最近开发的7纳米技术的投资需要考虑其对2-3纳米技术的适用性。对于 ArF (λ = 193 nm),需要采用浸没式光刻、一层的双重或四重图案化来满足这些关键图案尺寸。极紫外(EUV;λ = 13.5 nm)光刻有可能在一步中实现图案化,因此 EUV 优于 ArF。然而,EUV***的价格超过1.2亿美元,是 ArF 浸没式 (iArF) ***的两倍以上,但其当前的吞吐量小于 iArF 机器。
换算成当前大型晶圆厂的处理能力(例如每月5万片来料晶圆),基于此系统性能,EUV技术将需要约20亿美元的投资。假设每一代人的终生销售额约为相应商业投资的10倍,则该投资所需的相应市场规模将超过200亿美元。尽管这一估计是基于 2020 年全球半导体销售额 4400 亿美元来做的,但对于一种产品和一家制造商来说,这一市场规模并不现实。
总而言之,从行业经济角度来看,这是二维缩放的限制之一,市场目前很难找到胜利的场景,尤其是在纳米节点之外。
在本文中,我们会介绍由东京工业大学创新研究所推出的一种BBCube解决方案在3D DRAM实现的一种解决方案。
BBCube技术介绍
通过三维堆叠结合传统的二维集成将结构延伸到垂直空间(z方向)有望克服上述问题。BBCube的概念是下一代 2.5D(side-by-side arrays)和 3D 堆栈系统问题的解决方案,其中器件芯片和中介层无凸块连接。
下图显示了使用 TSV 的凸块互连和无凸块互连的比较,假设一个内存核心有 8 个芯片,一个逻辑控制器。由于采用凸块连接的片上芯片 (COC) 技术形成的芯片级堆叠需要拾取和放置来进行芯片转移,因此芯片厚度受到机械刚度要求和翘曲的限制,导致芯片间距约为80–100 微米。机械刚度随着裸片厚度的增加而降低。
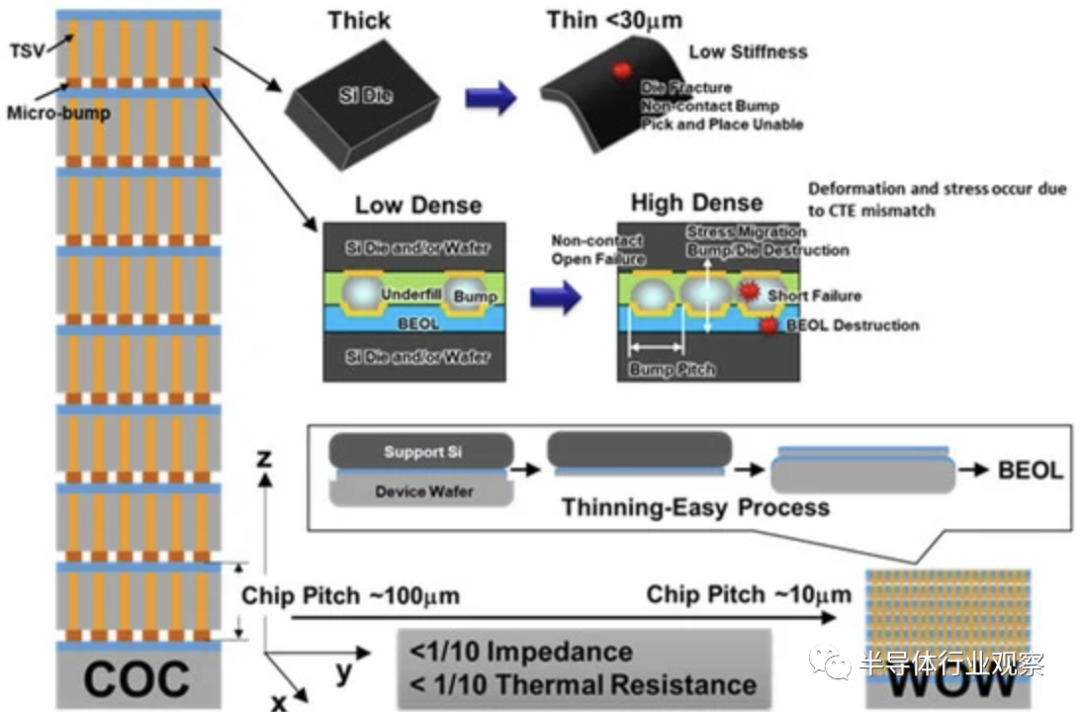
由于使用支撑晶圆减薄后的键合工艺可以将硅晶圆减薄至 4 μm,而不会降低器件特性,因此包括器件层和粘合层在内的晶圆总厚度仅为 10 至 20 μm。这是使用 TSV 的传统凸块互连厚度的 1/3 至 1/5。因此,即使堆叠的晶圆数量为100,我们假设晶圆厚度为10μm,那么堆叠后的总厚度为1mm。该总高度满足当前的封装标准。在这些多级堆叠工艺之后,当四个、八个、十六个等这些器件与由30Gb/cm² 的存储密度制造的传统存储器件堆叠时例如,采用22nm技术,3D存储器件的总容量可以分别线性增加到120Gb、240Gb、480Gb等,如下图所示。
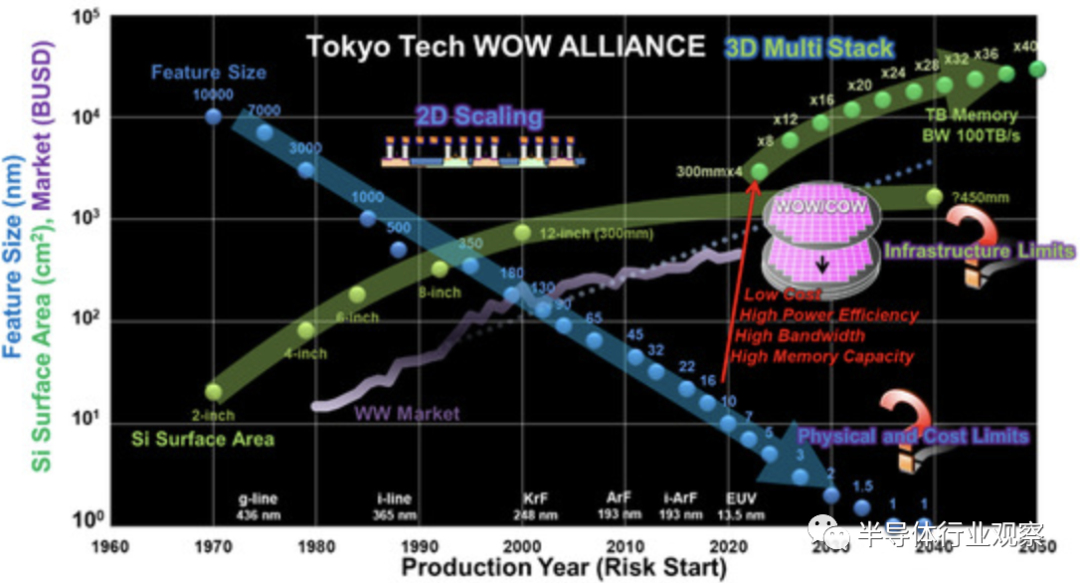
通过堆叠40层可以实现太比特容量的3D存储器。相比之下,要使用极端缩放的单个晶圆实现等效容量,将需要1 nm节点技术,其等效尺寸约为0.23 nm的Si-Si键长dSi-Si的四倍。因此,不仅需要针对 3D 晶体管的创新技术,还需要针对 3D 芯片堆栈的创新技术。
考虑到技术路线图,缩放技术和制造 3D 结构技术的问题通常会分开讨论。人们认为封装可以负责3D结构。然而,这两种技术并不总是相互排斥的。通过使用3D高密度集成技术与量产技术相结合,微缩技术将不再受到严格的要求。换句话说,可以确保足够长的学习时间,并且通过集中控制代际差异和缩短流程,可以预期进一步降低成本。
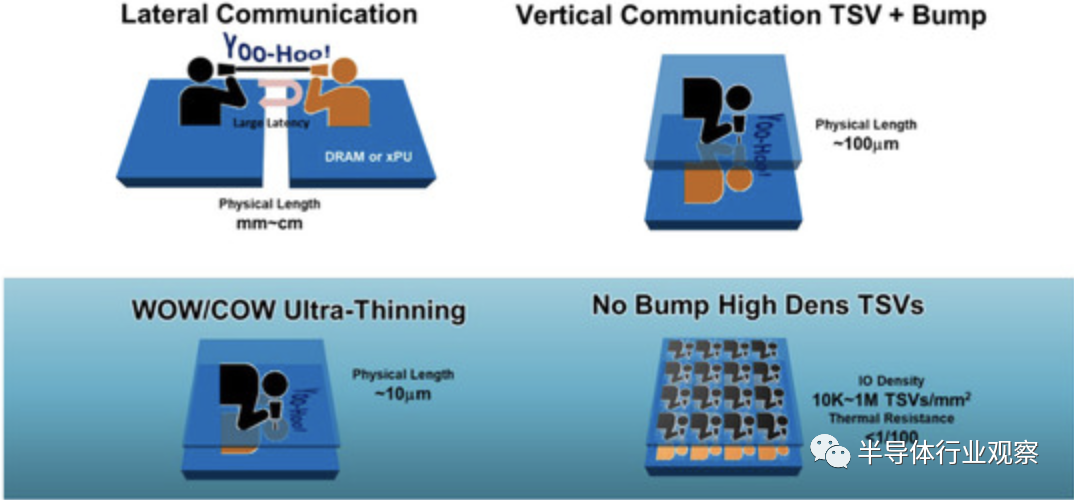
下图显示了芯片间连接的芯片级配置示意图。该配置是从并排到芯片堆栈的演变,以减少信号延迟、IR 压降和封装板上的占用空间。BBCube 是满足这些要求的候选者之一。无凸块连接和超薄化可实现最短的布线和高密度 TSV,并改善晶圆堆叠中的错位。高密度 TSV 非常有用,因为并行通信可提供高带宽。根据上述功能,BBCube架构为长期以来关于高密度LSI中信号传播、功率分配和散热的讨论提供了解决方案。
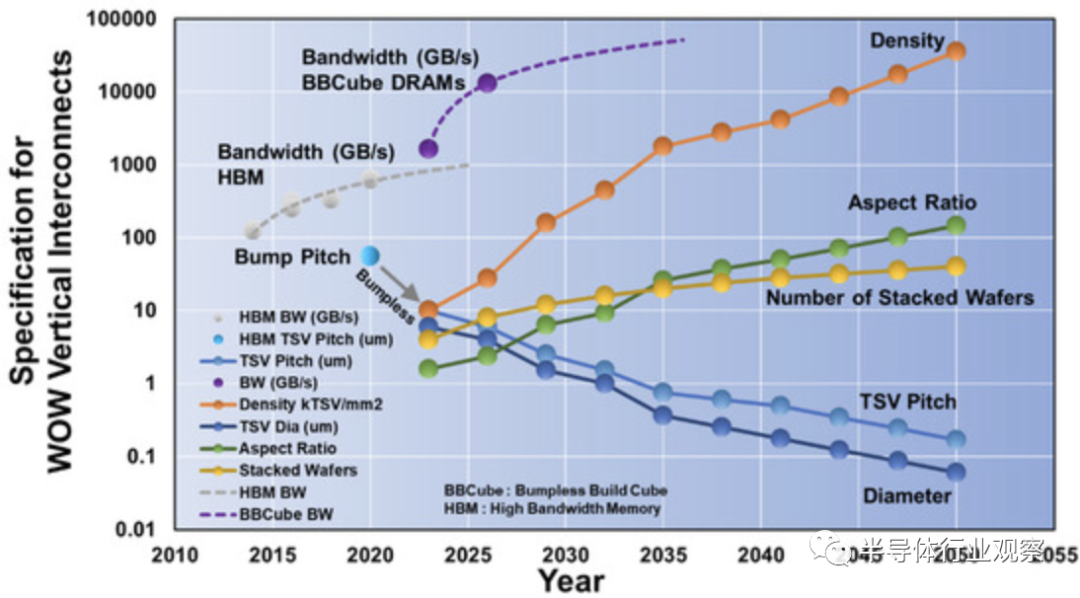
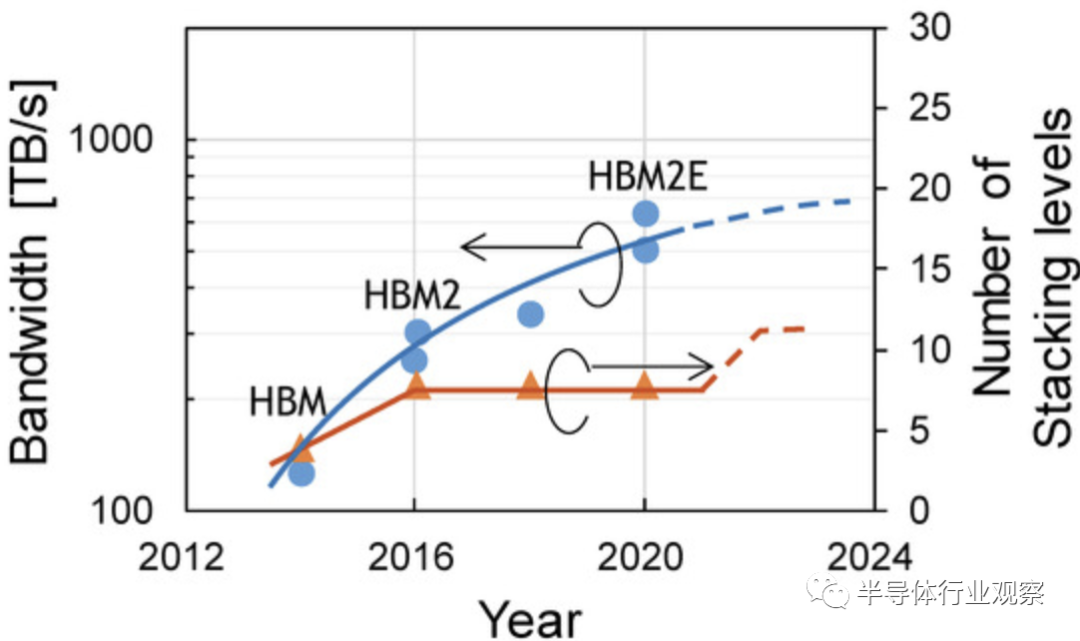
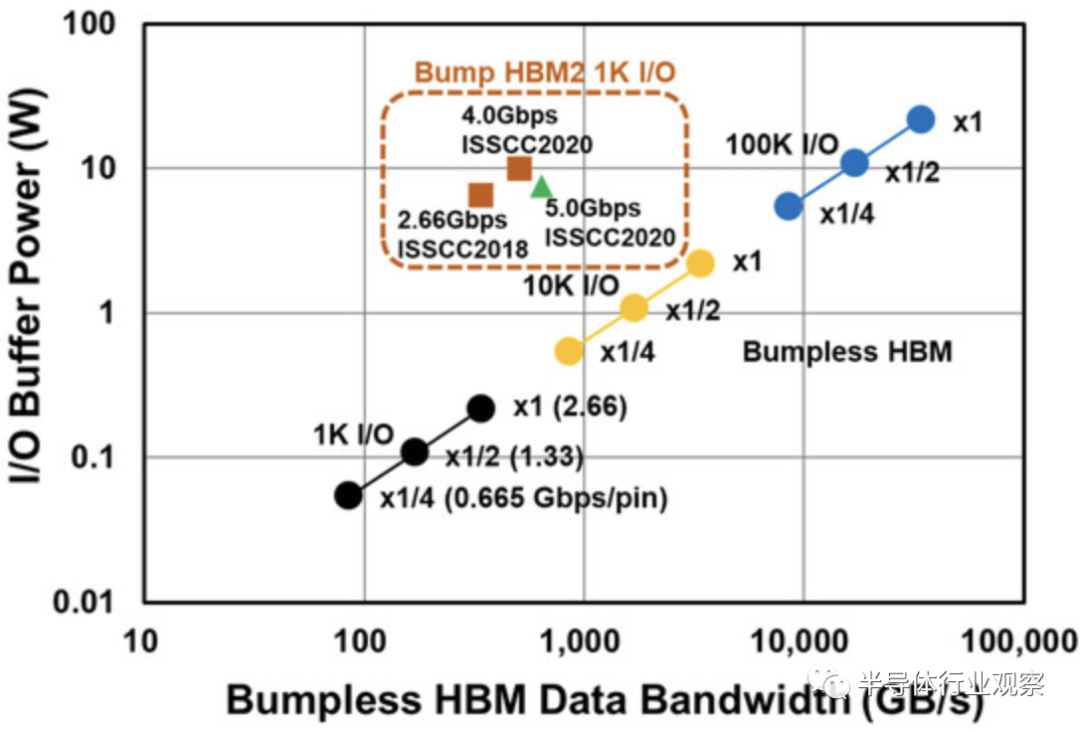
事实上,由于凸点间距的限制,最近的高带宽存储器(HBM)的带宽趋于饱和,如下图所示。但就 BBCube 而言,由于 BBCube 使用高密度 TSV 和新颖的内存架构,因此可以实现高一个数量级的带宽。根据WOW联盟的说法,考虑到键合对准的成熟度,TSV间距将每三年缩小一次。
基于BBCube的DRAM
众所周知,计算系统历史上存在三个关键挑战:(1)尺寸减小,(2)功耗降低,(3)速度提高。在这些关键要素中,尺寸减小是最迫切的挑战,因为低功耗和高速都可以通过尺寸减小本身来实现。下图显示了计算系统路线图。根据推断趋势,到2035年,目标器件体积将达到50 mm3,功耗为0.5 mW。这样的设备可能类似于人工智能机器蜜蜂,具有 CPU/GPU、DRAM、NAND 闪存和传感器。它将服务于人类用户,让AI机器蜂可以观察用户周围的环境,保护用户,并充当行政秘书。
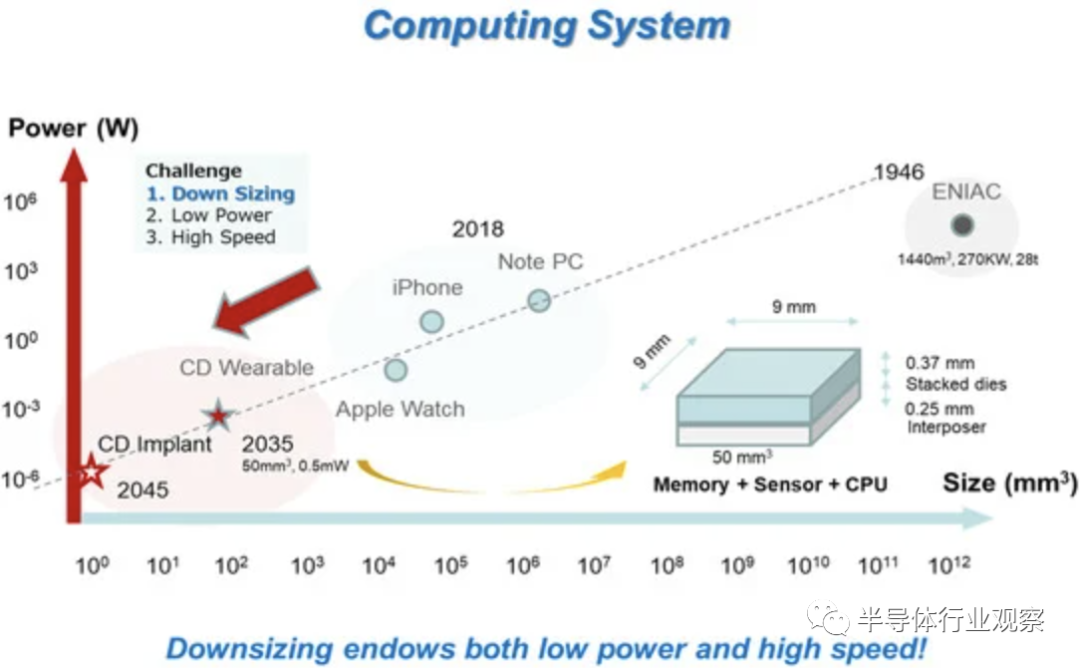
具有微凸块的TSV通常用于高带宽存储器(HBM),如图29所示。然而,使用微凸块时存在几个问题。一个主要问题是,即使是 HBM 也很难跟上 GPU 或 CPU 速度的提高。例如,NVIDIA生产的Pascal的处理速度为1TB/s,因此必须使用四组256GB/s的HBM。GPU/CPU供应商不断努力提高其产品的速度,例如提高到2TB/s和4TB/s,重点关注AI系统。HBM 必须将 I/O 引脚速度提高 2.5 倍,例如从2.0 Gb/s/pin提升到 5.0 Gb/s/pin ,因此,功率和热量也将增加。
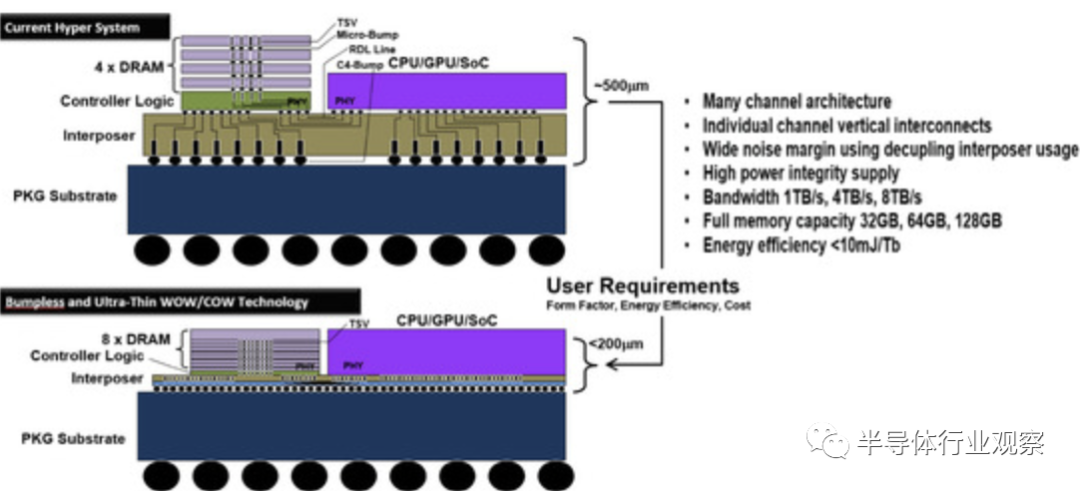
如图所示,具有竞争力的 BBCube DRAM 结构是一种能够通过无凸块 TSV 实现 8 芯片堆叠的结构。通过增加通道数量并降低 TSV 阻抗,应该可以实现 1、4 和 8 TB/s 的超高带宽。
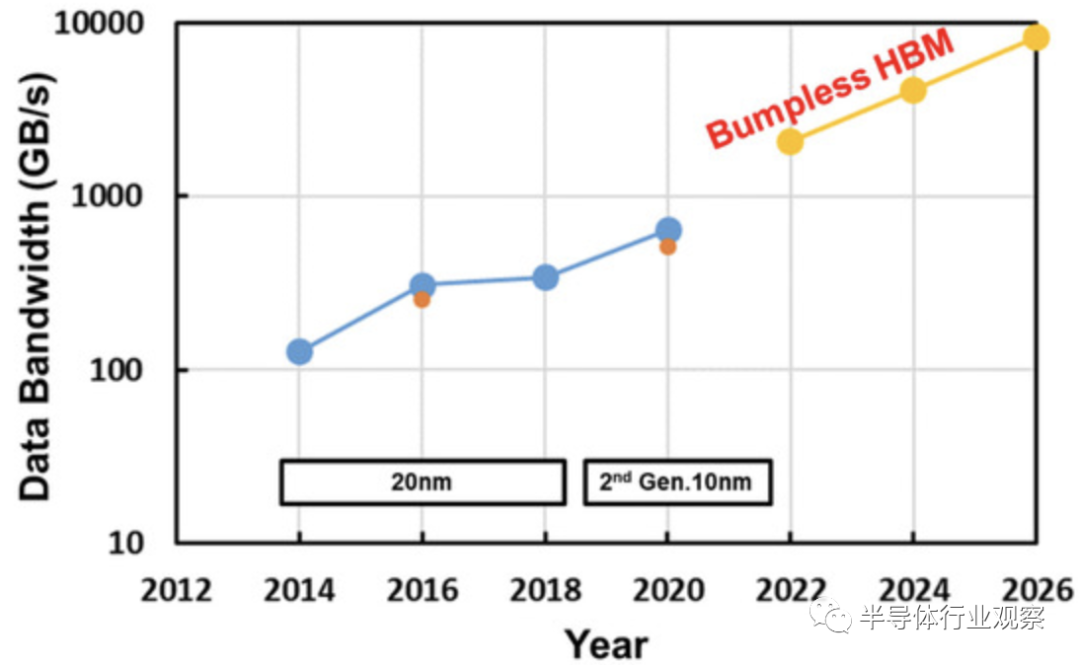
从上图我们可以看到HBM 数据带宽路线图。通过实现因 I/O 数量增加而带来的并行性增强,预计没有任何bumps的 HBM 带宽将不断增加。至于I/O功耗,bumpless HBM的第一个目标是当前HBM2的三十分之一,如下图所示。
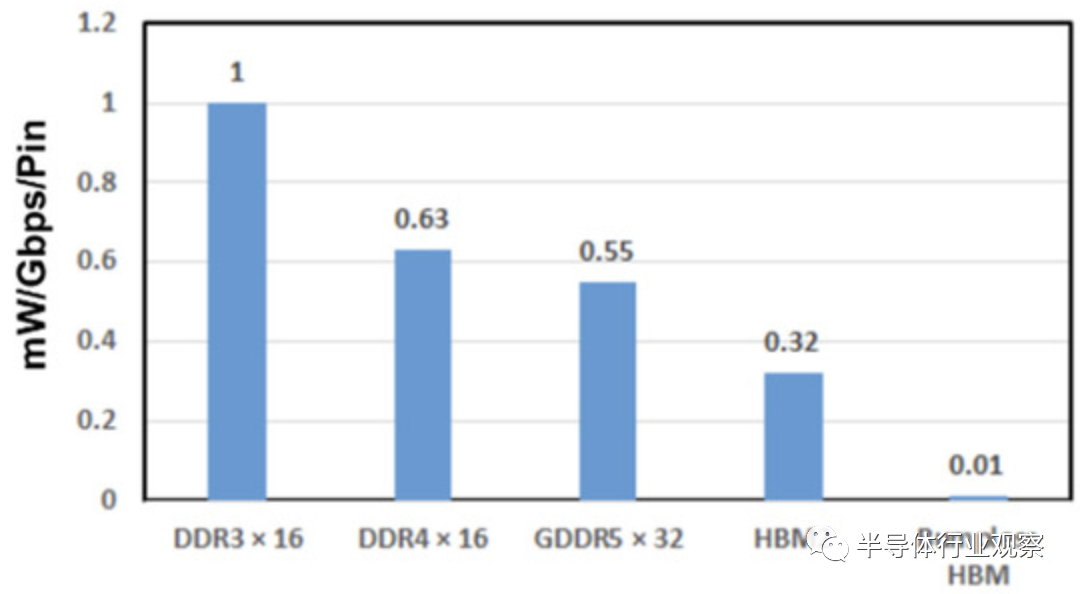
根据I/O 数量,我们还能从下图获得了带凸块 HBM2 和无凸块HBM的数据带宽和I/ O缓冲功率。
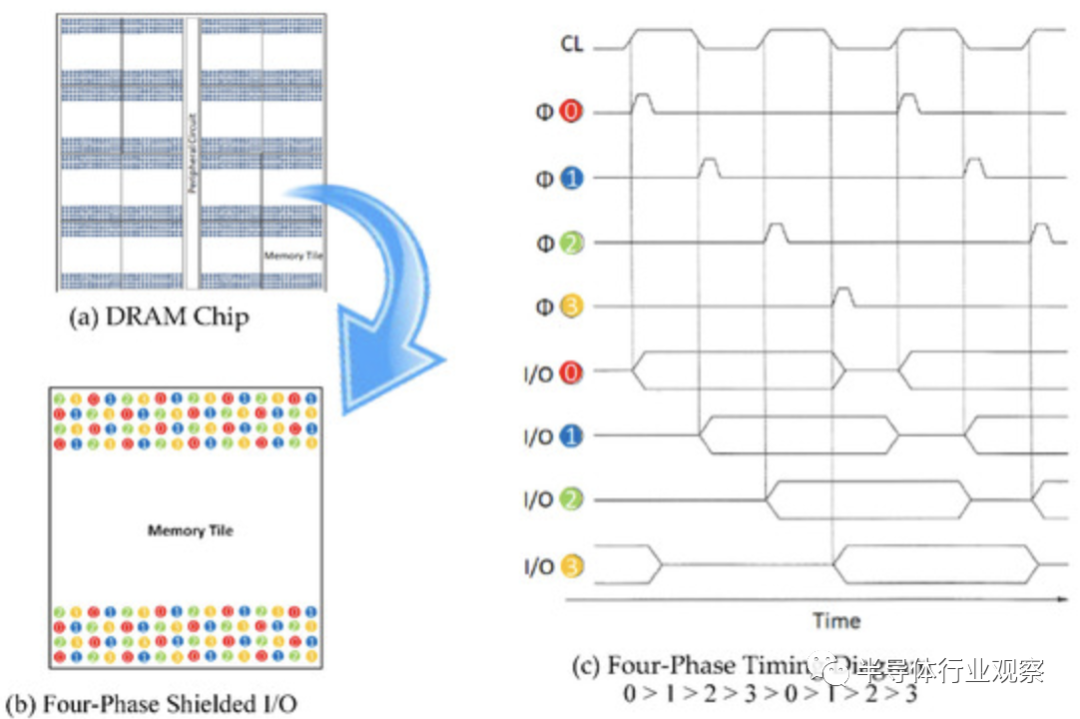
据统计,无凸块HBM 可通过将 I/O 数量增加到 1 K、10 K 和 100 K 来实现超高数据带宽,并可通过采用四相屏蔽 I/O 方案减少 I/O 引脚频率,以将 I/O buffer功率降低至 1/2 或 1/4。
在实际测试中,从下图a我们可以看到该方案的 TSV 电容的频率特性。由于慢波(slow-wave)模式,它增加到 3 GHz 以下。下图b则指出,衬垫厚度(liner thickness)决定了 3 GHz 以下的 TSV 电容。TSV 直径和 Si 厚度也决定了 TSV 电容,可以通过采用 BBCube 来减小 TSV 电容。
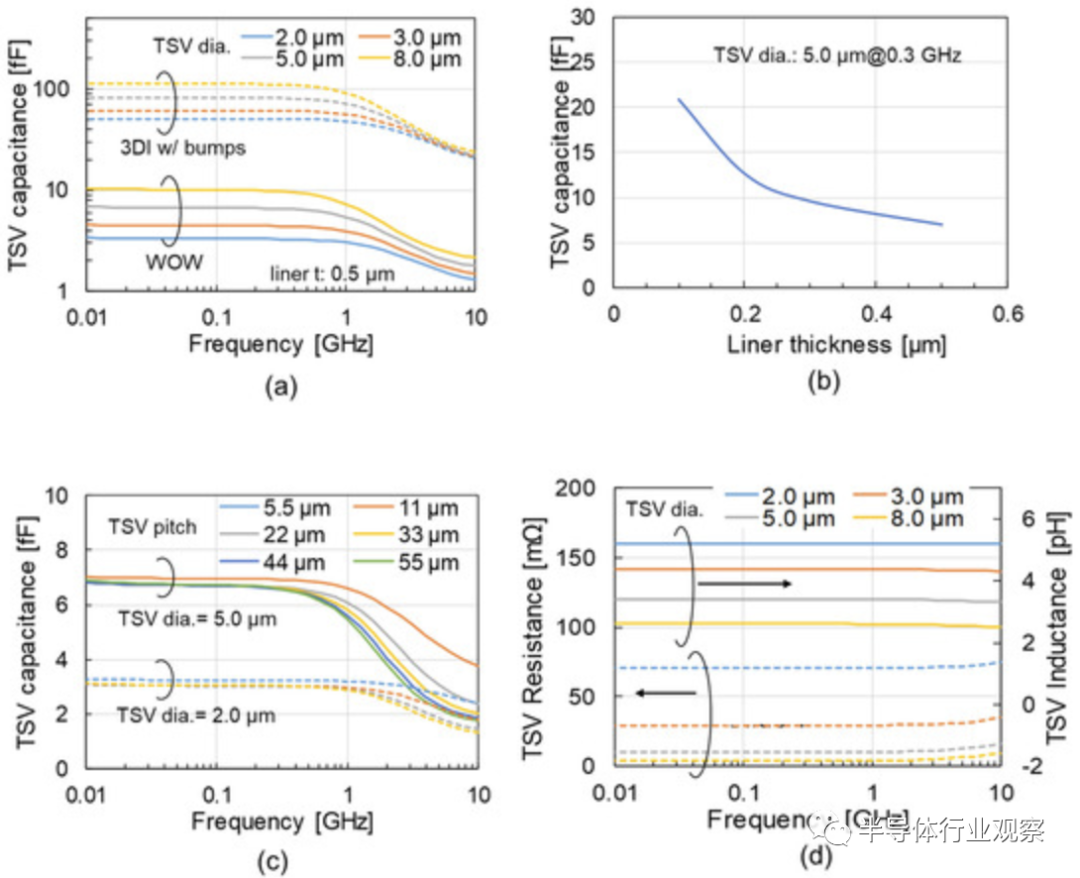
如图上图c、TSV间距不影响TSV电容。因此,当TSV直径为5μm时,BBCube能够在不增加电容的情况下将TSV间距缩短至11μm。此外,当TSV直径为2μm时,BBCube能够将TSV间距缩短至5.5μm。与传统3DI相比,BBCube的TSV电容变为1/20。如上图d所示,TSV 电阻的频率依赖性由于集肤效应(skin effect)而在 5 GHz 以上增加,但这高于 BBCube 的工作频率,因此没有任何影响。
此外,由于DRAM cell的温度会影响其保留时间并限制堆栈数量。因此,研究人员还对堆叠式 DRAM 进行了热分析。
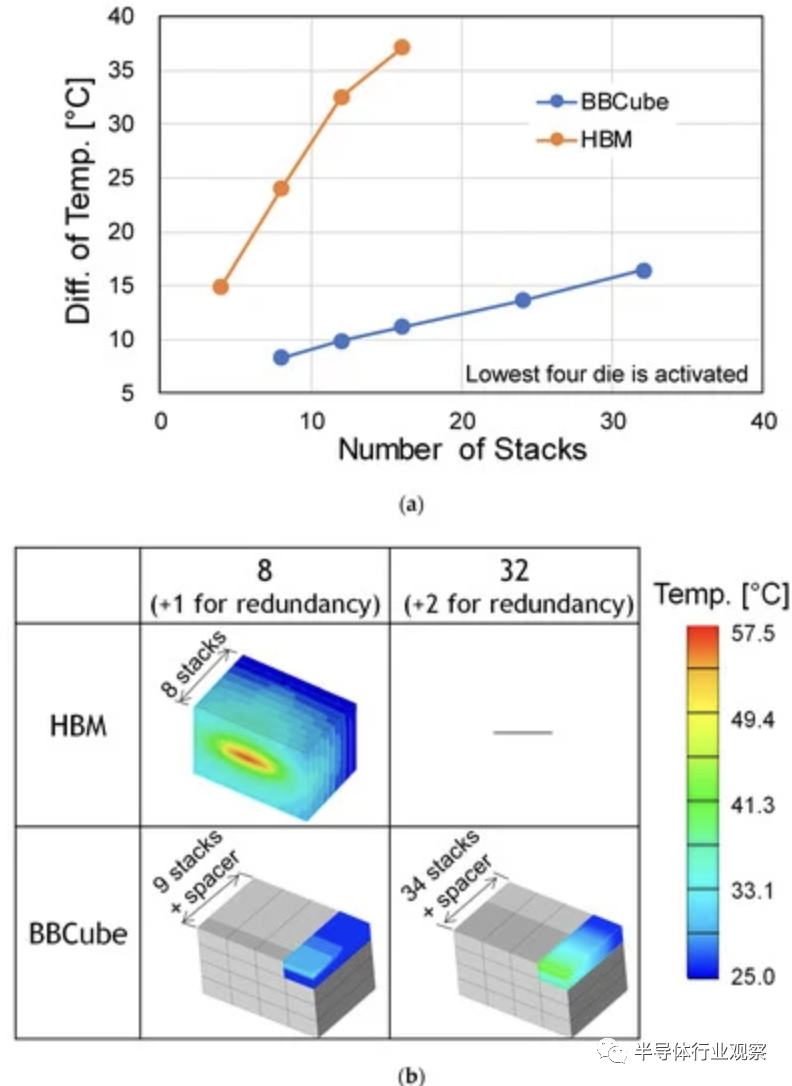
从技术上看,BBCube 中的 TSV 直接连接到底部裸片,而对于传统 3DI,需要在 TSV 之间放置焊料和 BEOL 层,这会增加热阻。BBCube 情况下的热阻是传统 3DI 的 1/4。下图则显示了室温下堆叠 DRAM 顶部与DRAM Cell最高温度的温度差。在堆叠DRAM的底部,HBM 和 BBCube 中均放置了具有相同功耗的基础裸片。对于具有 9 个堆栈的 BBCube,由于热阻较低,DRAM 单元温度差异为 8.3 °C。即使堆叠 34 个芯片,BBCube 中的温差仍为 16 °C,大约是堆叠 8 个芯片的 HBM 的三分之二。BBCube 允许堆叠的芯片数量是 HBM 的 4 倍。这使得使用 16 Gb DRAM 芯片的内存容量达到 64 GB。
总结
由于器件结构后微缩时代的需求,三维集成技术预计将得到越来越多的采用。通过这样做,当堆叠微米厚度的晶圆时,总厚度减小,晶体管容量与晶圆数量成比例增加。增加 TSV 互连密度可在不牺牲能源效率的情况下实现 TB 级带宽。功耗和散热对于高密度模块(例如 2.5D 和 3D 系统)尤其重要。
2.5D不是一个物理术语,是指将HBM、GPU(图形处理单元)、MPU等三维存储器整合并集成在一个中介层上的高速、高带宽系统,是一种后端进程的总称。最近几年,它已成为一种将具有不同功能的多个芯片和无源元件组合到一个系统模块中的产品差异化技术。本文作者的研究组织“WOW Alliance”提出了使用 WOW 和 COW 流程的 BBCube 架构,适用于包括无源器件的 2.5D 和 3D 系统。
随着堆叠晶圆数量的增加,制造中使用晶圆的数量也成比例增加。最近已采用每月8万片晶圆的量产。为了保持 8 片 DRAM 晶圆堆叠的相同吞吐量,每月使用的晶圆数量将为 640,000 片。在不考虑设备成本和运行成本的情况下,增加制造工厂的规模是可能的。然而,占地八倍的生产线可能无法平衡生产成本。因此,在未来,在这种情况下,可能会重新考虑扩大晶圆尺寸或替代方法,例如减少总工艺步骤与非常高产量的组合。
如果提高晶圆堆叠的对准精度,每平方厘米大约可以形成1至1000万个TSV。如此大规模的 I/O 对于 DRAM 堆叠来说太高了,但如果 TSV 的缩小和布局灵活性的发展,将有可能单独堆叠 MPU 逻辑和 SRAM 缓存。如果电源分配和接地可以位于SRAM单元的正下方,则可以实现稳定的电流和<0.7V的低施加电压和低噪声,因为它们可以通过微米级短互连以等效长度和高并行性连接。这种高密度 TSV 互连与 BBCube(低功耗)相结合将有助于减少 3D 系统的多余热量。
总之,正如所讨论的,通过采用三维集成技术可以实现半导体路线图的下一步。虽然需要开发高生产率的3DI技术,例如前端晶圆技术,但许多成熟的工艺都可以应用。因此,3DI的新技术只是薄化和堆叠工艺。这些技术也可以得到改进,因为有来自前端的众所周知的技术和新颖的候选材料,这些技术有望通过应用在半导体行业多年获得的专业知识而变得成熟。
审核编辑:刘清
-
半导体
+关注
关注
334文章
27286浏览量
218071 -
DRAM
+关注
关注
40文章
2311浏览量
183445 -
Nand flash
+关注
关注
6文章
241浏览量
39802 -
TSV技术
+关注
关注
0文章
17浏览量
5673 -
HBM
+关注
关注
0文章
379浏览量
14744
原文标题:3D DRAM,还能这样玩!
文章出处:【微信号:wc_ysj,微信公众号:旺材芯片】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
3D DRAM内嵌AI芯片,AI计算性能暴增
裸眼3D笔记本电脑——先进的光场裸眼3D技术
SK海力士5层堆叠3D DRAM制造良率已达56.1%
SK海力士五层堆叠的3D DRAM生产良率达到56.1%
三星已成功开发16层3D DRAM芯片
三星电子研发16层3D DRAM芯片及垂直堆叠单元晶体管
3D DRAM进入量产倒计时,3D DRAM开发路线图

三星电子:2025年步入3D DRAM时代
三星2025年后将首家进入3D DRAM内存时代

三星电子在硅谷设立下一代3D DRAM研发实验室
三星在硅谷建立3D DRAM研发实验室
三星电子新设内存研发机构,专攻下一代3D DRAM技术研发

如何搞定自动驾驶3D目标检测!






 工商网监
工商网监
评论