 Poly在深度学习领域中发挥的作用
Poly在深度学习领域中发挥的作用
从对上层应用的约束角度来看,作为一种通用程序设计语言的编译优化模型,Poly本身对应用是敏感的,只能处理满足一定约束条件的、规则的应用。Poly要求被分析的应用中,循环边界、数组下标都是仿射表达式,而且控制流必须是静态可判定的,我们暂且把这种对应用的要求称为静态仿射约束。实际上,对于通用语言而言,静态仿射约束的限制对程序的要求不算低,但是深度学习领域的大部分核心计算却恰好满足这种静态仿射约束,所以许多深度学习编译软件栈利用Poly来实现循环优化。
而从充分发挥底层AI芯片架构的能力角度来讲,Poly也非常适合,这得益于Poly能够自动判定和实现上层应用中循环的tiling/blocking(分块)变换并自动将软件循环映射到并行硬件上。本系列文章第一篇中图12和图13就是Poly在GPU上自动实现分块并将分块后对应的循环维度映射到GPU的线程块和线程两级并行硬件抽象上的实例。
为什么Poly需要自动实现分块?这是由底层AI芯片的架构导致的。以GPU为例,图14[15]所示是GPU的架构示意图。每个GPU上拥有自己的全局缓存(Global/Device Memory),然后每个线程块也有自己的局部缓存(Shared/Local Memory)。缓存越靠近计算单元,访存的速度越快,但是缓存空间越小。因此,当计算数据量大于缓存空间的时候,就需要通过将原来的数据进行分块的方式存储到缓存上,以此来适应目标架构的硬件特征。
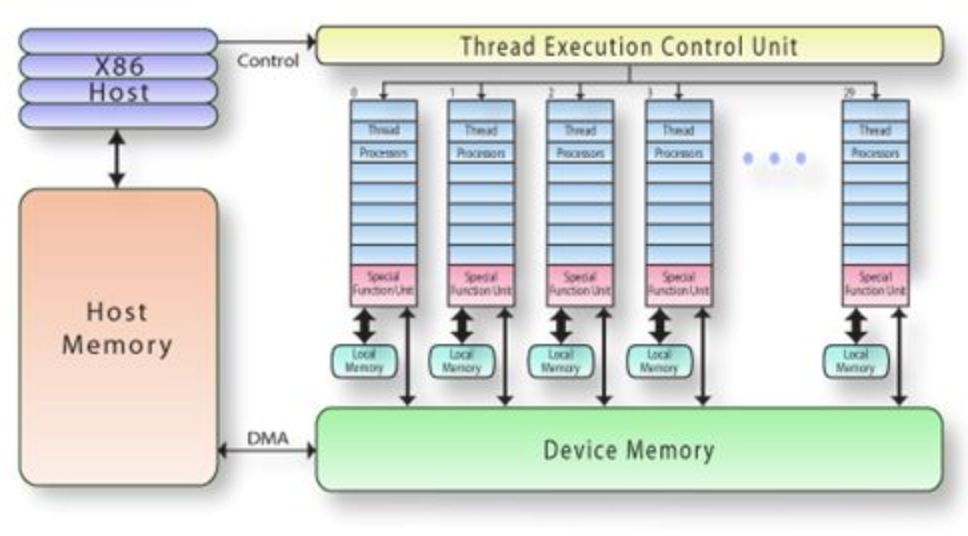
图14 GPU架构示意图
而专用AI芯片的架构可能更复杂,如图15[16]所示是TPU v2和TPU v3的架构示意图,每个TPU有多种不同类型的计算单元,包括标量、向量以及矩阵计算单元,这些不同的计算单元对应地可能会有各自不同的缓存空间,这就给分块提出了更高的要求。只有通过对应用的正确分块才能充分利用好芯片上的架构特征。
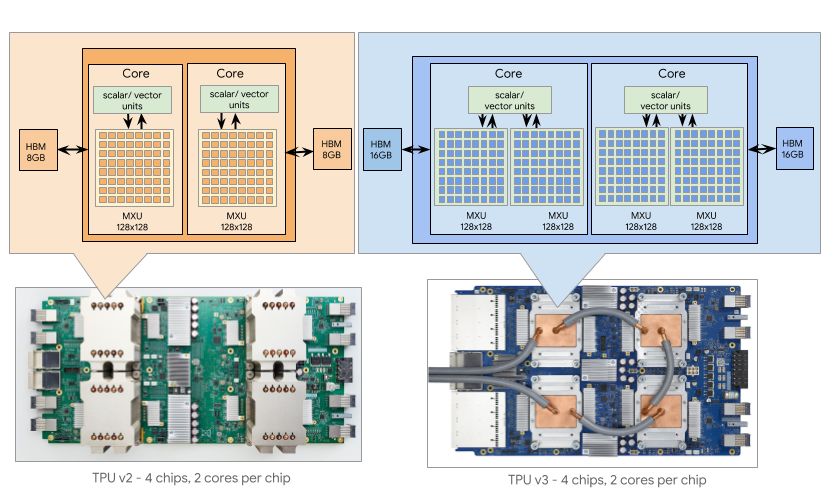
图15 TPU架构示意图
当前一部分深度学习编译软件栈采用了手工调度和映射的方式来将上层应用部署到底层芯片上。以TVM为例,图16[17]中给出了一个TVM的调度示例。其中,调度过程首先将计算s进行分块(对应图16中的split操作),然后将分块后的维度映射到GPU的线程块和线程上(对应图16中的bind操作)。

图16 TVM调度示例
这部分工作需要由熟悉底层芯片架构的人员来编写,并且要人工分析分块的合法性,映射也需要手工完成。而Poly的作用就是将上述手工调度的过程自动实现。为了实现自动调度,许多深度学习编译软件栈开始采用Poly来实现上述功能。那么,Poly在深度学习软件栈上发挥的作用如何呢?
首先,Poly能够计算精确的数据流信息。Poly通过将传统的编译器中语句之间的依赖关系细化到语句实例的粒度,分析的结果比传统的方法更精确。计算精确的数据流信息有以下三点好处。
1.计算精确的缓存搬移数据量。Poly不仅能自动计算出从管理核心(如CPU)到加速芯片(如GPU)之间传输的数据总量,还负责计算加速芯片上多级缓存之间的数据搬移总量,例如从GPU的global memory到shared memory上的数据搬移。“存储墙”问题给我们揭示了一个道理:数据搬移是程序性能提升的关键,尤其是现在市场上越来越复杂的多级缓存架构上,数据总量计算是否精确对程序性能的影响更加明显。
2.降低内存空间使用。通过计算精确的数据流信息,Poly可以计算出临时tensor变量,这些临时变量的声明可在对应的缓存级别上实现,从而降低加速芯片上数据的访存开销。例如,图9所示的代码段中,tensor b就可以看作是一个临时tensor变量。
3.自动实现缓存上的数据部署。以华为刚公布的昇腾AI处理器芯片为例,如图17[18]是该芯片的AI Core架构示意图。其中,UnifiedBuffer(输出缓冲区)和L1 Buffer(输入缓冲区)是低级缓存,离计算单元较远;BufferA L0/B L0/C L0是高级缓存,靠近计算单元。在低级缓存上,Poly可以借助标记节点,将不同计算单元所需的数据分别流向UnifiedBuffer和L1 Buffer;同时,当数据到达高级缓存时,Poly仍然可以借助标记节点将数据自动部署到BufferA L0/B L0/C L0。(注:这里描述的是如何通过Poly来实现这样的数据分流,只是为了说明Poly能够实现这样的自动数据部署功能,与具体实现无关。至于昇腾AI处理器芯片的编译团队是否使用了Poly,或者是否使用了这种方法来实现数据的自动部署还请以官方公布为准。)
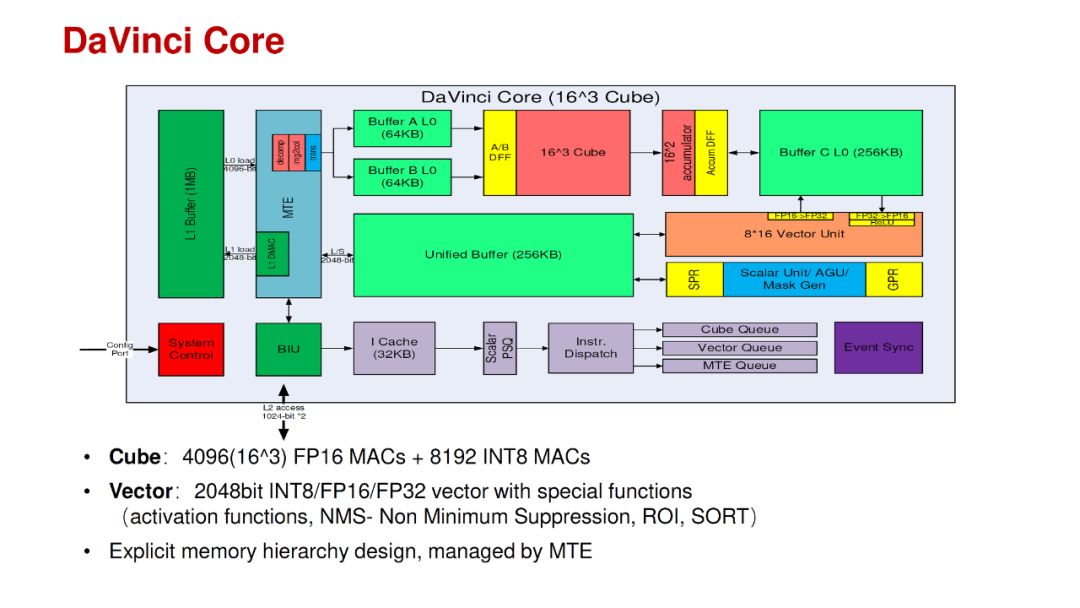
图17 昇腾AI处理器的DaVinci Core架构示意图
其次,Poly能够实现几乎全部的循环变换。Poly通过仿射函数来实现几乎所有循环变换及其组合,这种仿射函数的计算过程不仅要考虑应用程序的并行性和局部性,还要考虑底层加速芯片的硬件特征。从循环变换角度来讲,Poly对编译软件栈的贡献包括以下几个方面。
1.Poly中的调度算法[19-22]能够根据依赖关系分析的结果自动计算出变换后循环的并行性、循环维度是否可以实施分块等特征,这些特征为后面硬件上的计算任务分配、缓存上的循环变换提供了理论依据。(这些信息保存在band节点(下面会介绍)的属性中)而部分循环变换如skewing/shifting(倾斜/偏移)、interchange(交换)等都可以在调度阶段自动完成。我们仍然以图9中所示的例子来说明。对于图10生成的代码,Poly计算出来的调度用其中间表示(schedule tree)[23]后得到的结果如图18所示,而图11生成的代码对应的调度如图19所示。(注:为方便说明,这里的schedule tree可能和实际在Poly中使用的有所不同,我们只是为了更直观地表示schedule tree的表示方式。)其中,domain节点包含所有的语句实例集合,sequence节点表示其子节点按序执行,而“[]”包含的节点称为band节点,可以想象成循环。
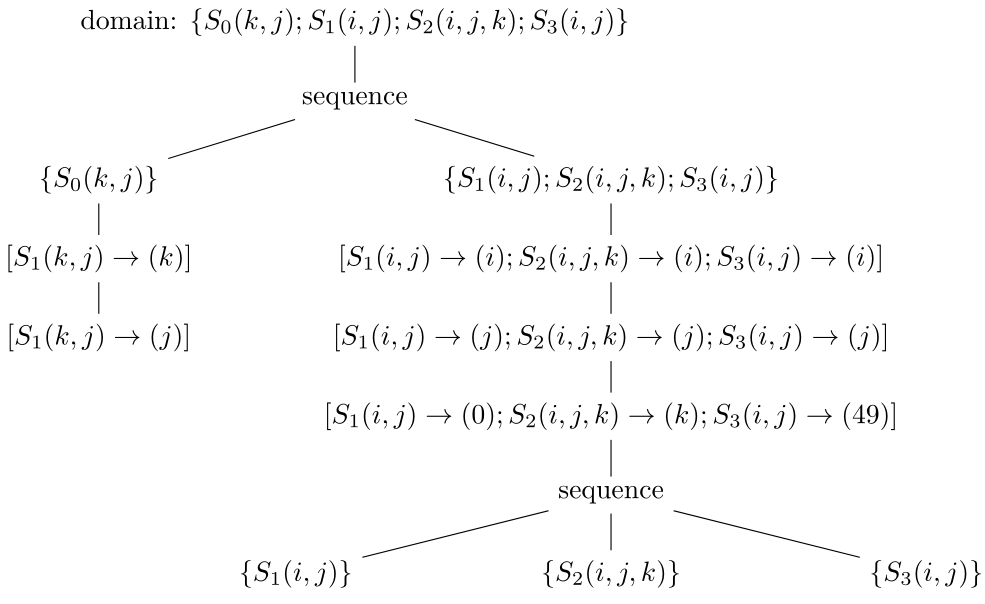
图18 图10对应的schedule tree表示
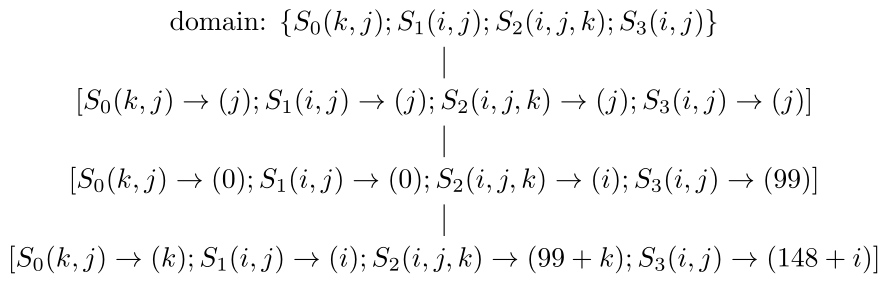
图19 图11对应的schedule tree表示
2.自动实现深度学习应用中最关键的tiling/blocking(分块)和fusion(合并)变换。分块的目的是为了充分利用加速芯片上的缓存,而合并的目的是为了生成更多的临时缓存变量,降低访存开销。而且,Poly通过数学变换,能够自动实现更复杂的、手工难以实现的分块形状[6, 24-26]。其中,合并可根据调度选项在调度变换过程实现,分块则是在调度变换之后根据循环维度是否可分块等特征来实现。如图18和19就是根据不同的编译选项实现的合并策略对应的schedule tree,其中合并已经通过sequence节点实现,而分块的实现在Poly上很简单,只需要将band节点中的仿射函数进行修改就可以得到分块对应的schedule tree。如图20是图18经过分块之后的调度树,图19的分块也可以同样的方式得到,我们就不再赘述了。
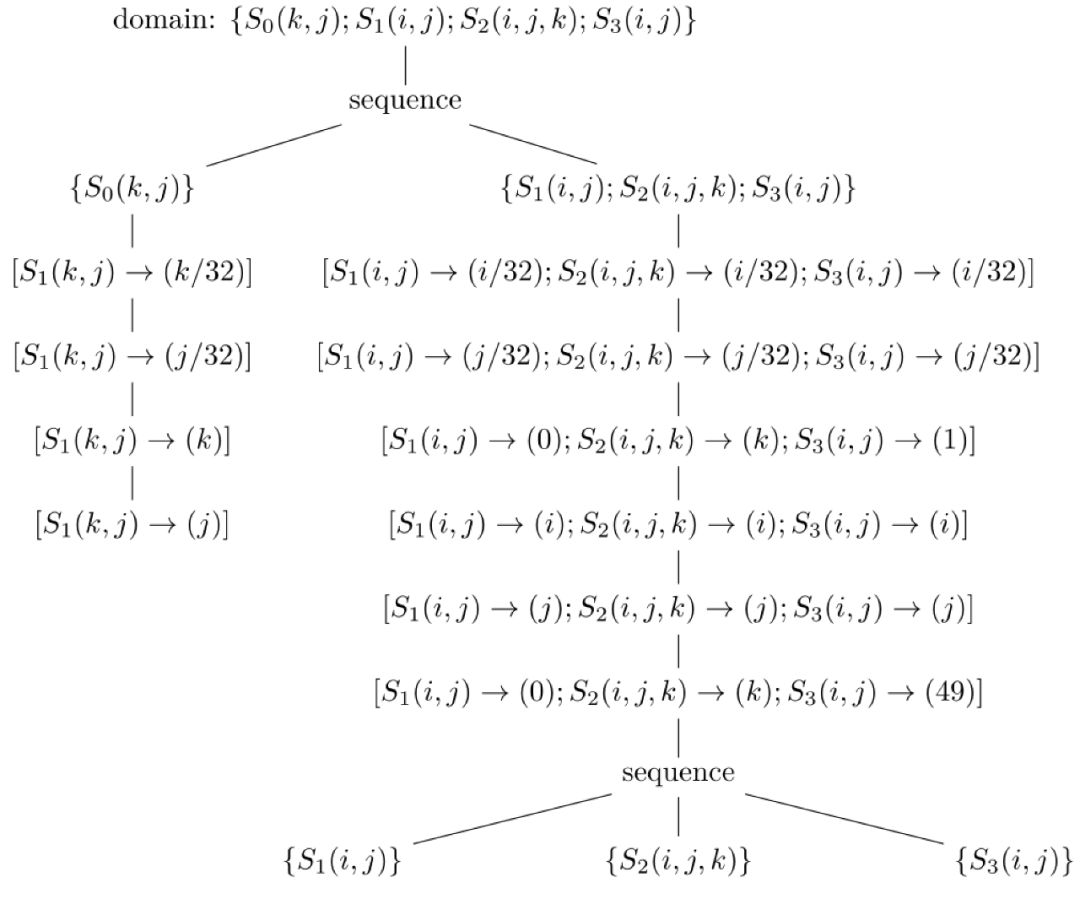
图20 图18分块之后的schedule tree
3.通过代码生成方式自动实现不改变语句顺序、但只改变循环结构的变换。这类循环变换包括peeling(剥离)、unrolling(展开)等。因为这些循环变换不改变语句的执行顺序,而只是对循环的结构进行修改来实现。这些循环变换对特殊加速芯片上的代码生成有十分重要的作用,例如一些架构可能并不喜欢循环上下界中有min/max这样的操作,此时就需要实现这类循环变换。这类循环变换可以通过在schedule tree中的band节点上添加特殊的options属性来实现。(注:我们的图中没有标出options,但实际使用的schedule tree中有options,而options中的内容是一个集合或者映射表达式,计算起来也很方便。)
第三,Poly能够自动实现存储系统的管理。在越来越复杂的加速芯片架构上,复杂的存储系统是实现芯片上计算部署的难点,即便是硬件开发人员来手工实现程序在存储结构上的管理,也是一个十分耗时且易出错的任务。而Poly借助中间表示自动实现了在多级缓存结构上的存储管理[27],使得底层优化和硬件开发人员从这些琐碎的工作中脱离出来。这种自动管理存储系统的实现包括以下两个方面。
1.自动计算缓存之间传递数据需要插入的位置。由于数据传输指令在原程序中是不存在的,所以Poly要能够实现这种从无到有的指令生成过程,并且正确计算出相应的位置。Poly借助schedule tree上的特殊节点和仿射函数,实现了数据传输指令位置的准确计算和自动插入。
2.自动生成数据传输指令的循环信息。确定数据传输指令的位置后,Poly可以根据数学关系计算出当前指令所在循环的层次和维度信息,并自动为数据传输指令计算对应的调度关系,然后交给后端代码生成器生成代码。
如图21所示,是图20的schedule tree经过插入特殊的extension节点之后,得到的带有数据传输指令的中间表示。其中,kernel0和kernel1分别对应图20中最上面sequence节点下的两棵子树,而to_device_B和to_device_a表示从CPU的内存上拷贝tensor B和a到GPU的global memory,这两个语句在计算之前。from_device_c表示将GPU上的tensor c从global memory传输回CPU内存上,这个语句在计算之后。Poly并没有传输tensor b,而是在GPU的global memory上创建和使用了tensor b。(注:to_device_B和to_device_a也可以颠倒顺序执行,为了便于说明我们在这里假设按序执行。)
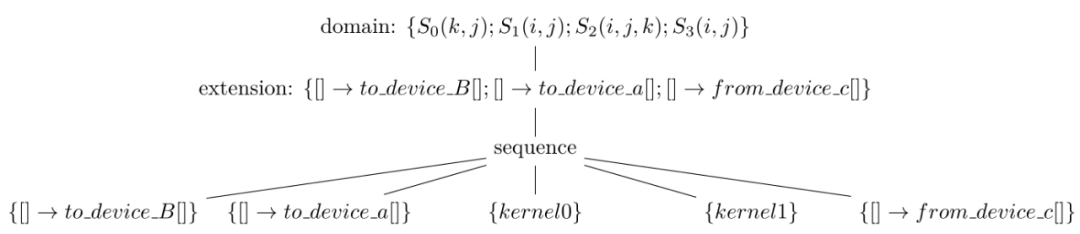
图21 图20的schedule tree插入数据传输指令之后的中间表示
最后,Poly还能够自动计算出变换之后循环到硬件上的映射。在提供多级并行硬件抽象和按计算的类型提供不同计算单元的加速芯片上,软件循环要实现到硬件上的映射,而这种映射关系也可以借助Poly的仿射函数和schedule tree上的标记来自动实现。这可以通过在kernel0和kernel1的子树内的band节点上添加特殊标记来实现。(注:图中未标出。)
-
存储器
+关注
关注
38文章
7516浏览量
164042 -
缓存器
+关注
关注
0文章
63浏览量
11673 -
TPU
+关注
关注
0文章
143浏览量
20754 -
TVM
+关注
关注
0文章
19浏览量
3679 -
AI处理器
+关注
关注
0文章
92浏览量
9521
发布评论请先 登录
相关推荐
如何在交通领域构建基于图的深度学习架构
深度学习介绍
对2017年NLP领域中深度学习技术应用的总结
排序算法如何在机器学习技术中发挥重要作用
深度学习在各个领域有什么样的作用深度学习网络的使用示例分析





 工商网监
工商网监
评论