 苹果的差分隐私技术原理详解
苹果的差分隐私技术原理详解
来源| OSCHINA 社区
作者 |PrimiHub开源
原文链接:https://my.oschina.net/u/6662337/blog/10087905
在 2016 年 6 月份的苹果 WWDC 大会上提到了一项差分隐私技术(Differential Privacy),其作用是对用户的数据进行扰动,然后上传到苹果服务器。苹果能通过这些扰动过的数据计算出用户群体的行为模式,但是对每个用户个体的数据却无法解析。
苹果通过采用差分隐私技术,实现了在不得到用户原始数据的前提下,学习用户行为。如果你想知道 “数据可用不可见” 背后的技术,就跟着我们一起来学习下苹果的差分隐私技术背后的原理吧!
一、简介
差分隐私是一种数据隐私保护技术,它通过在数据中引入随机化扰动的手段来保护隐私。简单来说,扰动后的数据是无法精确地推断出其原始值。同时,它允许对随机化后数据进行统计分析,保证了数据的有用性。差分隐私提供了衡量隐私的严格数学定义,是近些年来业界常见的一种隐私保护技术。
1.1 差分隐私应用场景
苹果使用本地化差分隐私(Local Differential Privacy)技术来收集用户设备上的信息,其部署的产品见下表 [1, 2]。
| QuickType suggestions | 学习热门新词汇,用于键盘打字预测 |
| Emoji suggestions(Emoji 预测) | 学习流行表情包趋势,预测用户使用的表情包 |
| Lookup Hints(搜索提示) | iOS 搜索框提示 |
| Safari Energy Draining Domains & Crashing Domains | 统计电量消耗大(高 CPU、高内存使用)的网站、易崩溃的网站 |
| Safari Autoplay Intent Detection | 统计用户倾向于自动播放且不静音的网站 |
| Health Type Usage | 流行的健康数据类型(睡眠、心率、卡路里等)统计 |
| 产品名称 | 用途 |
|---|
1.2 本地化差分隐私
在本地化差分隐私框架中,用户在上传的原始数据中添加噪声(扰动),服务器则无法知道用户的真实数据。这项技术最早是由 Warner 提出的随机响应(Randomized response)[3]。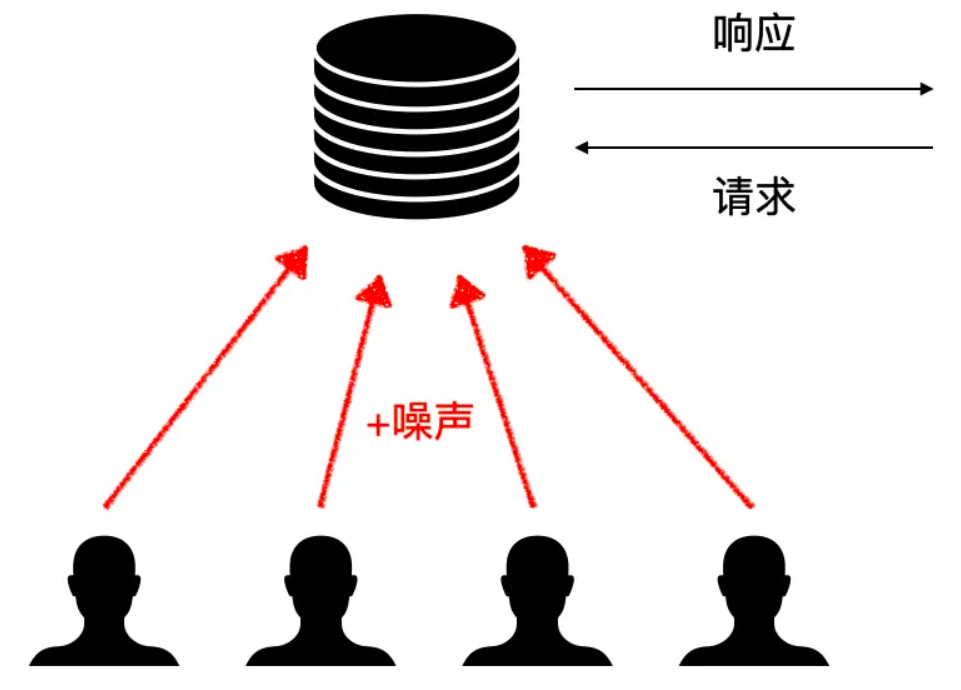
本地化差分隐私技术可用于联合统计,比如计算平均数、中位数、频率直方图等。其算法框架(E-R-A-P)一般分为四个步骤:
编码(Encoding,E)
随机化(Randomizing,R)
聚合(Aggregation,A)
后处理(Post-processing,P)
用户端进行编码与随机化,保证传输的数据是扰动后的;服务器端进行聚合与后处理,得到相应的统计量。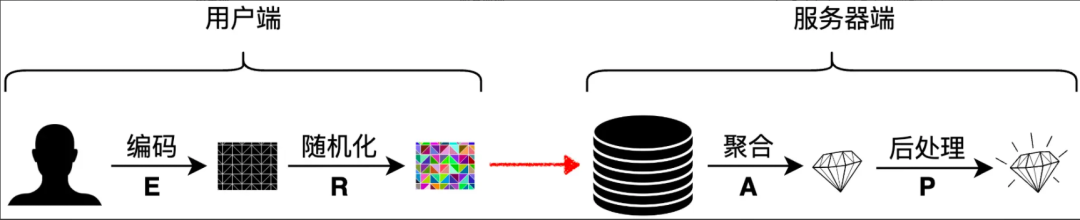
二、苹果的方案
苹果的本地化差分隐私方案参见 [2, 4, 5],其中 [4, 5] 是专利。这里介绍 [2] 中方案的简易版本,以统计表情包的频率直方图为例。
2.1 用户端
依照上面提到的 算法框架(E-R-A-P),用户端需要在上传数据之前对做原始数据做编码 (E)和随机化 (R)。 编码 (E):编码是为了后续的随机化和聚合步骤。苹果的编码采用哈希表的方式,初始表中的元素均为 “-1”。然后通过哈希函数hh将元素dd(使用频率最高的表情包)映射到位置h(d)h(d),并标记 “1”。假设哈希表的长度为mm(聚合时会用到该参数)。
2.2 服务器端
依照上面提到的 算法框架(E-R-A-P),服务器端需要在接收到数据后对做 “扰动” 后的数据做聚合 (A)和后处理 (P)。
后处理 (P):在不同应用场景中,计算的统计量可能有先验知识,比如取值范围的限制(如大于 0),或者保持加和不变(如统计个数),这时就需要进行后处理操作。差分隐私的性质使得任何后处理操作均不影响其结果的隐私性。
2.3 其他技术
数据隐私保护需要考虑的方面很多,仅使用差分隐私技术无法解决所有的问题。苹果在方案中还使用了其他技术来保护数据隐私,例如数据脱敏、通信加密、访问控制等。
用户上传的数据已移除设备标识符、时间戳等信息
用户与服务器通信使用 TLS 协议,即数据加密传输
服务器收到用户数据后首先移除 IP、地址、时间戳等 meta 信息,并将数据顺序打乱(shuffle)
数据聚合在受限访问环境中执行
数据只在苹果内部流通,且苹果的员工不能随意访问数据
2.4 隐私预算
看到这里大家应该明白了,差分隐私是通过在增加噪声(扰动)来实现隐私保护,但由于扰动增加,聚合的结果会变得不精确(统计量的方差增大)。所以下面介绍平衡算法的隐私性和实用性的隐私预算ϵϵ。
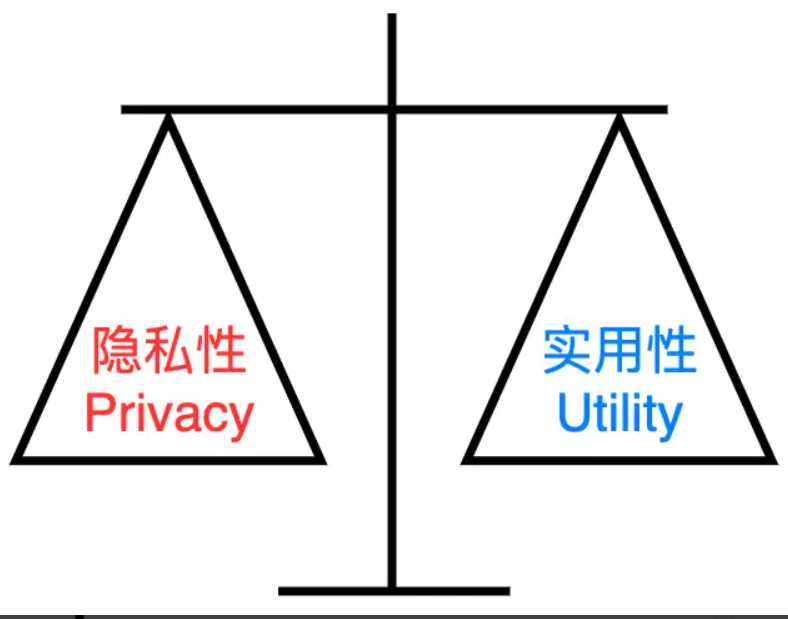
而且,虽然数据添加了差分隐私扰动,但同一用户会不断地上传新数据,根据差分隐私的串型组合定理,隐私预算ϵϵ会随着时间累积逐步增加。因此,苹果限制了用户每天上传数据的最大次数,并表示数据最多只会留存三个月。
| QuickType suggestions | 8 | 2 |
| Emoji suggestions(Emoji 预测) | 4 | 1 |
| Lookup Hints(搜索提示) | 4 | 2 |
| Safari Energy Draining Domains & Crashing Domains | 4 | 2 |
| Safari Autoplay Intent Detection | 8 | 2 |
| Health Type Usage | 2 | 1 |
| 产品名称 | 隐私预算ϵϵ的取值 | 数据最多上传次数 / 每天 |
|---|
有研究 [6] 指出,苹果应该解释是如何设置隐私预算ϵϵ的取值的,告知用户并将其透明化。例如,虽然 Emoji 产品中宣称的隐私预算ϵϵ取值为 1,但通过代码逆向工程后发现其取值为 2(iOS 10.1.1 和 MacOS 10.12.3 版本的数据)。而且,隐私预算随时间累积也是其方案存在的一个重要问题。
三、方案优化
第 2 节中描述的是方案的简易版,而苹果的方案针对通信、统计量的精确性、场景适配等均做了优化 [2] 如下:
为了减少哈希碰撞的影响,实际有kk个哈希函数,每个用户在编码时随机选择一个,并将选择的哈希函数告诉服务器。服务器则构建kk个哈希表,然后进行聚合计算。
为了降低通信量,苹果的方案中对编码后的数据进行了阿达马变换(Hadamard transform),并通过采样的方式,随机选择 1 比特的数据发送到服务器。这样不仅可以降低通信量,而且不会增加统计值的方差。
表情包的数据一般是固定的,但在一些场景下,用户数据是无法预知的。比如学习热门新词汇,统计网站。苹果对此采用了 Sequence Fragment Puzzle 技术,并设计了本地化差分隐私的方案。
四、无偏估计证明
这里依旧是按照 算法框架(E-R-A-P)顺序进行讲解,证明f~(d)f~(d)是f(d)f(d)的无偏估计。
4.1 编码
4.2 随机化
4.3 聚合

统计量的方差小才意味着估计的精确性高。 以上通过公式推导的方式证明了苹果采用的「差分隐私」算法的准确性,可以实现在 “数据可用不可见” 的情况下实现统计计算。
五、最后
看似 “高不可攀” 的差分隐私技术,其实早已走进了我们的日常生活和工作中,为我们的个人隐私保驾护航。 本文通过通俗易懂的图文和严谨的公式推导,讲解了苹果的差分隐私技术原理,希望能够勾起你对隐私计算技术的兴趣。
审核编辑:刘清
-
编码器
+关注
关注
45文章
3692浏览量
135536 -
苹果手机
+关注
关注
1文章
2245浏览量
35200
原文标题:一文读懂苹果的差分隐私技术原理
文章出处:【微信号:OSC开源社区,微信公众号:OSC开源社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐

差分隐私和现有的隐私保护方法相结合:从用户群体中学习的系统架构详解
基于差分隐私的数据匿名化隐私保护模型
本地化差分隐私研究综述


面向随机森林的差分隐私保护算法

一种支持本地化差分隐私技术的聚类方案






 工商网监
工商网监
评论