 北大提出MotionBERT:人体运动表征学习的统一视角
北大提出MotionBERT:人体运动表征学习的统一视角
导 读
本文是对发表于计算机视觉领域顶级会议 ICCV 2023 的论文MotionBERT: A Unified Perspective on Learning Human Motion Representations的解读。该论文由北京大学王亦洲课题组与上海人工智能实验室合作完成。
这项工作提出了一个统一的视角,从大规模、多样化的数据中学习人体运动的通用表征,进而以一个统一的范式完成各种以人为中心的下游视频任务。实验表明提出的框架在三维人体姿态估计、动作识别、人体网格重建等多个下游任务上均能带来显著提升,并达到现有最佳的表现。
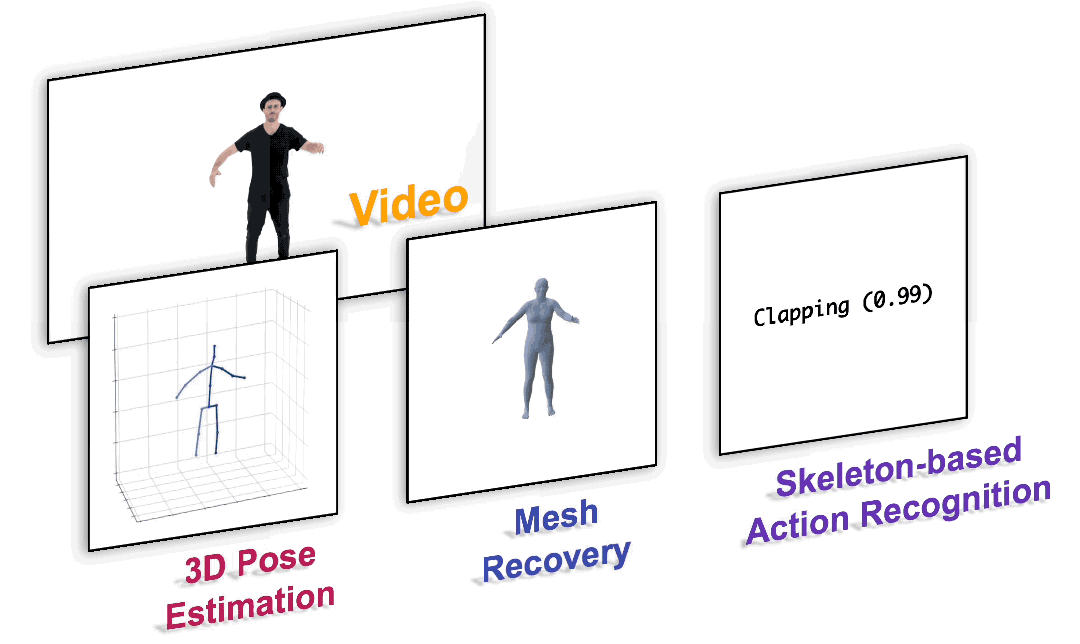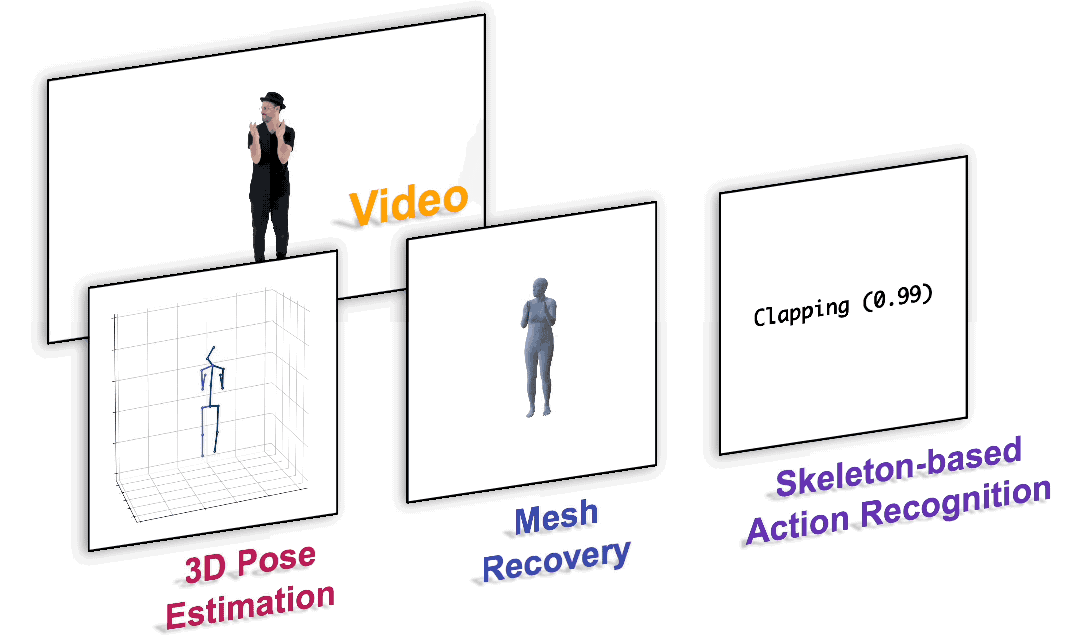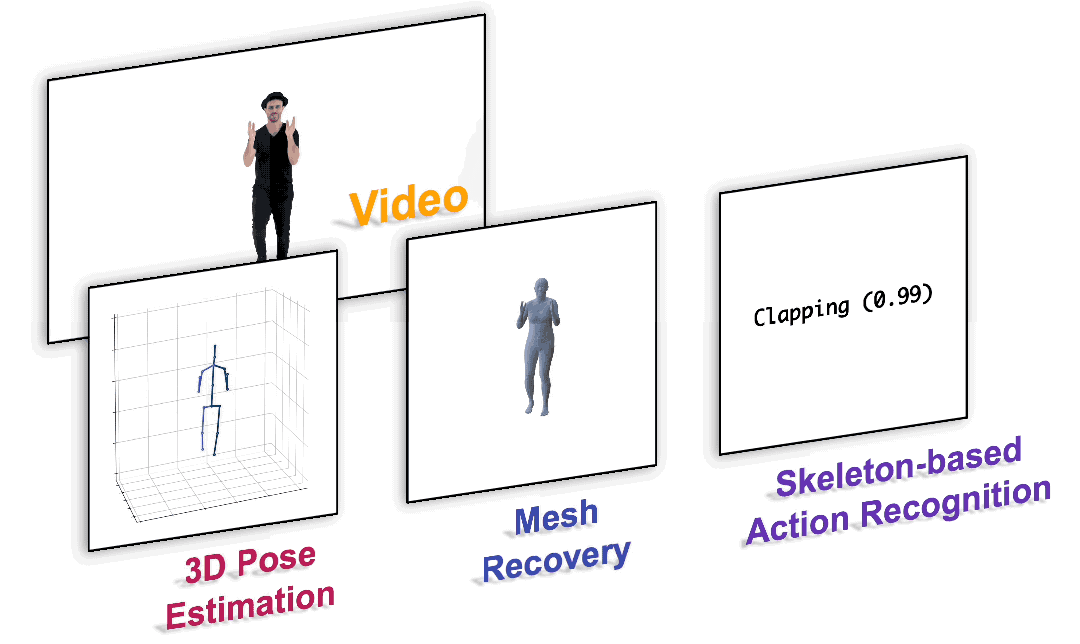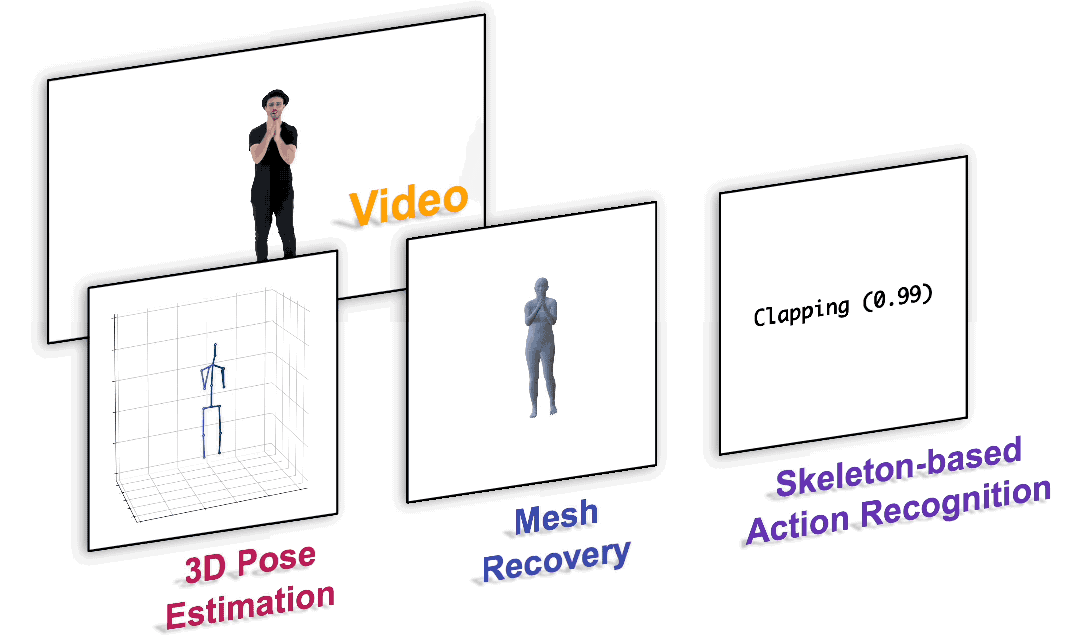
图1. 以统一的范式完成各种以人为中心的视频任务
01
背景介绍
感知和理解人类活动一直是机器智能的核心追求。为此,研究者们定义了各种任务来从视频中估计人体运动的语义标签,例如骨骼关键点、行为类别、三维表面网格等。尽管现有的工作在这些任务上已经取得了显著的进步,但它们往往被建模为孤立的任务。理想情况下,我们可以构建一个统一的以人为中心的运动表征,其可以在所有相关的下游任务中共享。
构建这种表征的一个重要挑战是人体运动数据资源的异质性。运动捕捉(MoCap)系统提供了基于标记和传感器的高精度 3D 运动数据,但其内容通常被限制在简单的室内场景。动作识别数据集提供了动作语义的标注,但它们要么不包含人体姿态标签,要么只有日常活动的有限动作类别。具备外观和动作多样性的非受限人类视频可以从互联网大量获取,但获取精确的姿势标注需要额外的努力,且获取准确真实(GT)的三维人体姿态几乎是不可能的。因此,大多数现有的研究都致力于使用单一类型的人体运动数据解决某一特定任务,而无法受益于其他数据资源的特性。
在这项工作中,我们提供了一个新的视角来学习人体运动表征。关键的想法是,我们可以以统一的方式从多样化的数据来源中学习多功能的人体运动表征,并利用这种表征以统一的范式处理不同的下游任务。
02
方法概览
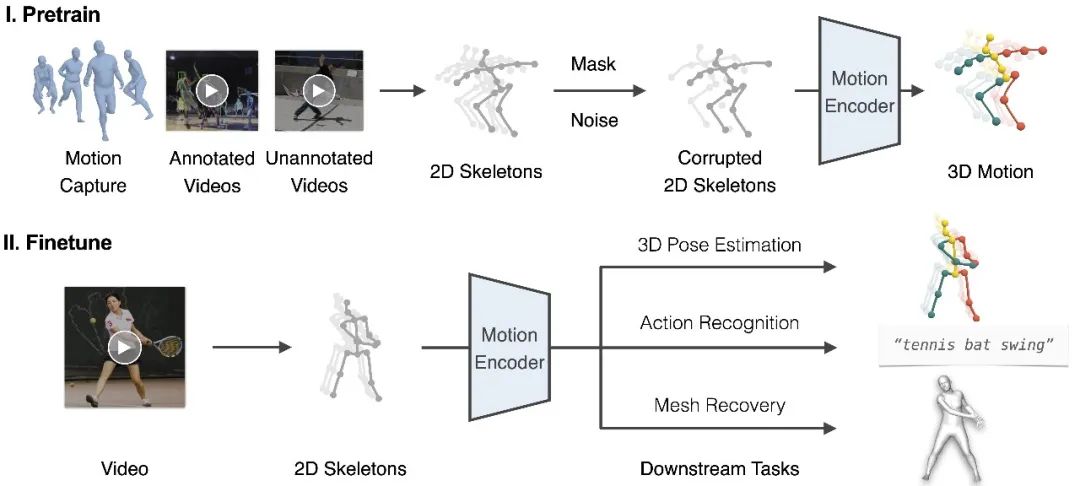
图2. 框架概览
我们提出了一个包括预训练和微调两个阶段的框架,如图2所示。在预训练阶段,我们从多样化的运动数据源中提取 2D 关键点序列,并添加随机掩码和噪声。随后,我们训练运动编码器从损坏的 2D 关键点中恢复 3D 运动。这个具有挑战性的代理任务本质上要求运动编码器(i)从时序运动中推断出潜在的 3D 人体结构;(ii)恢复错误和缺失的数据。通过这种方式,运动编码器隐式地学习到人体运动的常识,如关节拓扑,生理限制和时间动态。在实践中,我们提出双流空间-时间变换器(DSTformer)作为运动编码器来捕获骨骼关键点之间的长距离关系。我们假设,从大规模和多样化的数据资源中学习到的运动表征可以在不同的下游任务之间共享,并有利于它们的性能。因此,对于每个下游任务,我们仅需要微调预训练的运动表征以及一个简单的回归头网络(1-2层 MLP)。
在设计统一的预训练框架时,我们面临两个关键挑战:
如何构建合适的代理任务(pretext task)学习的运动表征。
如何使用大规模但异质的人体运动数据。
针对第一个挑战,我们遵循了语言和视觉建模的成功实践[1]来构建监督信号,即遮蔽输入的一部分,并使用编码的表征来重构整个输入。我们注意到这种“完形填空”任务在人体运动分析中自然存在,即从 2D 视觉观察中恢复丢失的深度信息,也就是 3D 人体姿态估计。受此启发,我们利用大规模的 3D 运动捕捉数据[2],设计了一个 2D 至 3D 提升(2D-to-3D lifting)的代理任务。我们首先通过正交投影 3D 运动来提取 2D 骨架序列 x。然后,我们通过随机遮蔽和添加噪声来破坏 x,从而产生破坏的 2D 骨架序列,这也类似于 2D 检测结果,因为它包含遮挡、检测失败和错误。在此之后,我们使用运动编码器来获得运动表征并重建 3D 运动。
对于第二个挑战,我们注意到 2D 骨架可以作为一种通用的中介,因为它们可以从各种运动数据源中提取。因此,可以进一步将 RGB 视频纳入到 2D 到 3D 提升框架以进行统一训练。对于 RGB 视频,2D 骨架可以通过手动标注或 2D 姿态估计器给出。由于这一部分数据缺少三维姿态真值(GT),我们使用加权的二维重投影误差作为监督。
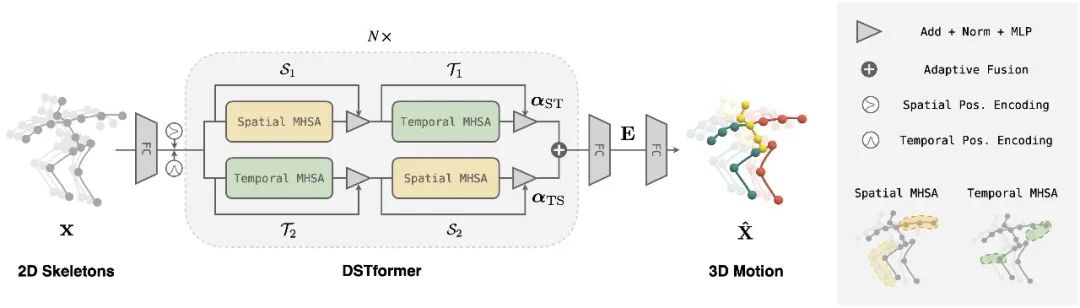
图3. DSTformer 网络结构
在运动编码器的具体实现上,我们根据以下原则设计了一个双流时空变换器(DSTformer)网络结构(如图3所示):
两个流都有综合建模时空上下文信息的能力。
两个流侧重不同方面的时空特征。
将两个流融合在一起时根据输入的时空特征动态平衡融合权重。
03
实验结论
我们在三个下游任务上进行了定性和定量的评估,所提出的方法均取得了最佳表现。
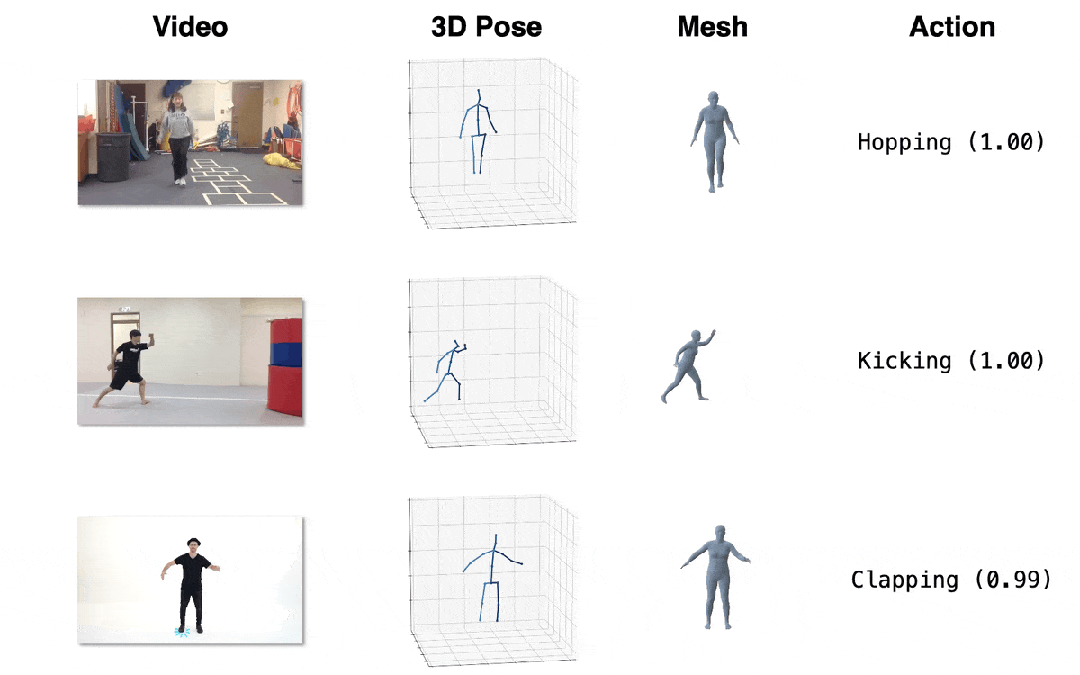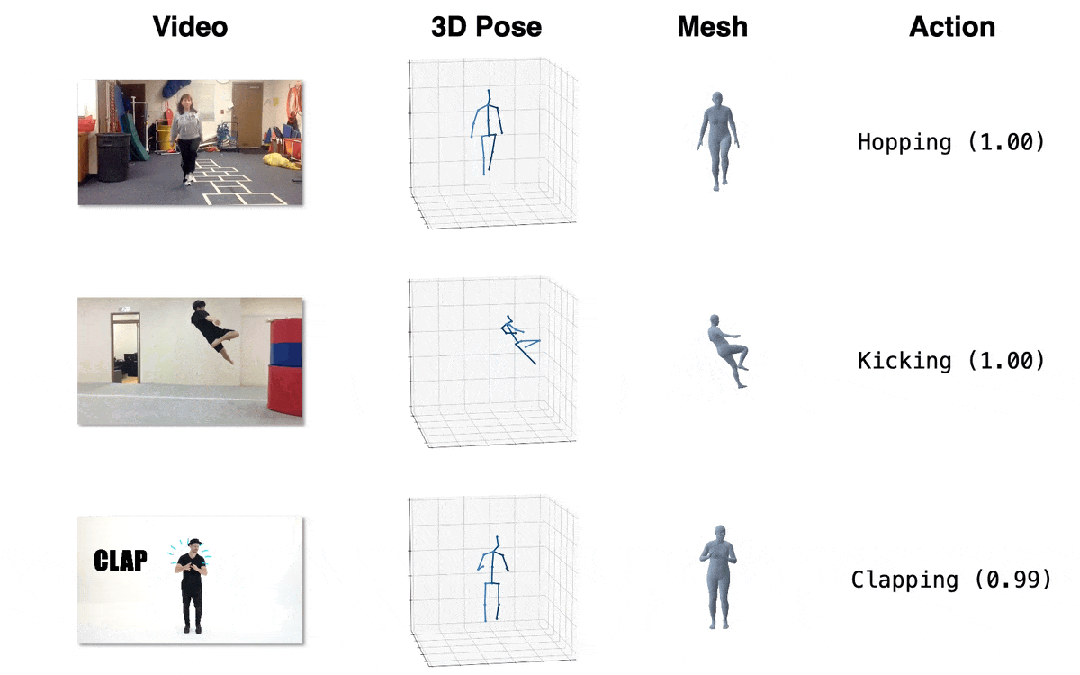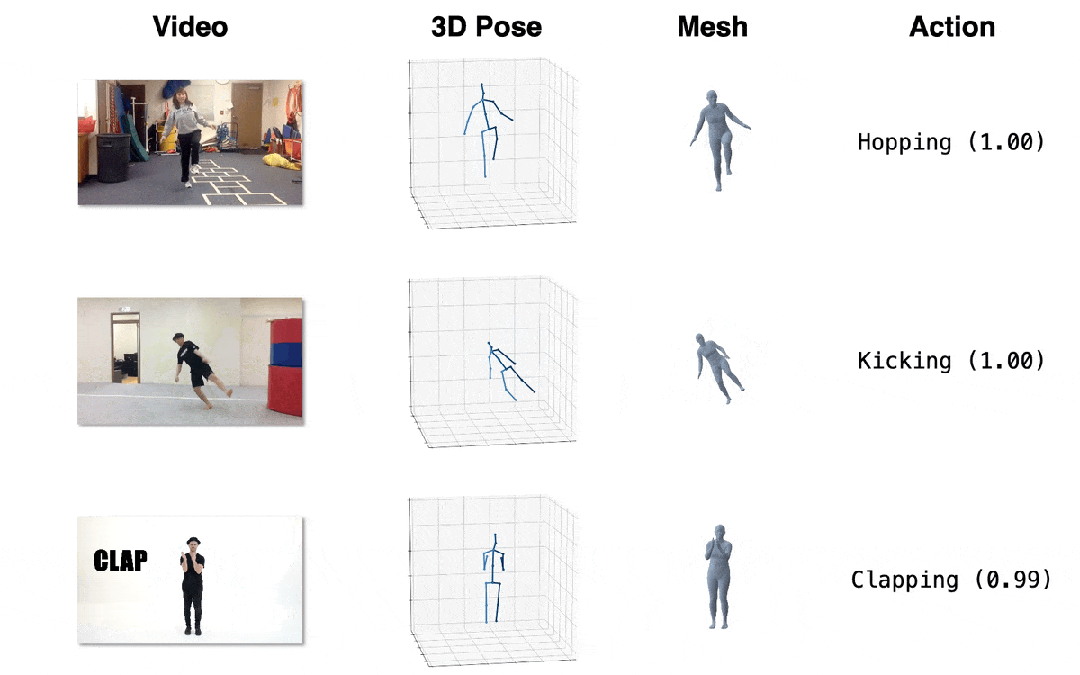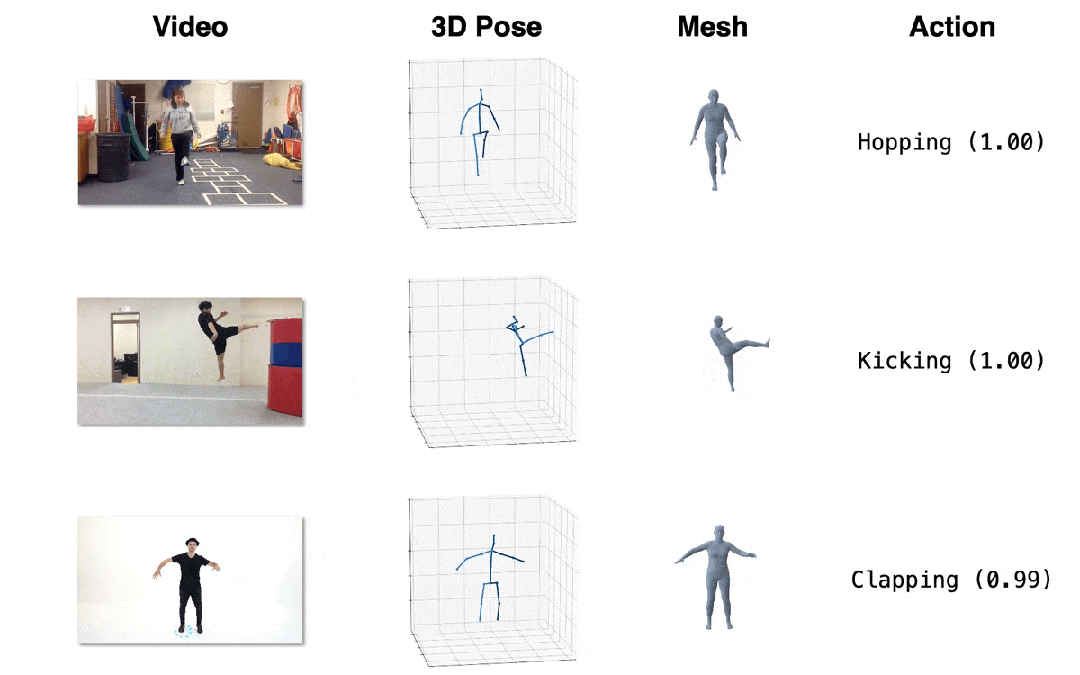
图4. 效果展示
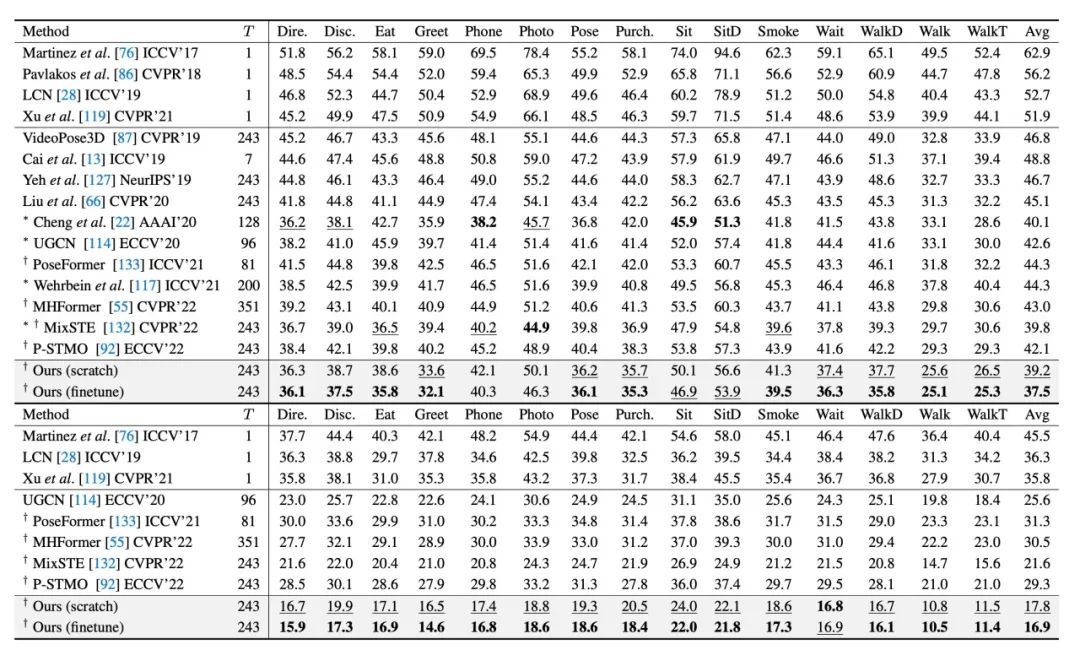
表1. 三维人体姿态估计的定量评估。数字代表 Human3.6M 上的平均关节误差 MPJPE(mm)。(上)使用检测到的 2D 姿态序列作为输入。(下)使用真值(GT)2D 姿态序列作为输入。
对于三维人体姿态估计任务,我们在 Human3.6M[3]上进行了定量测试。如表1所示,本文的两个模型都优于最先进的方法。所提出的预训练运动表征额外降低了误差,这证明了在广泛而多样的人体运动数据上进行预训练的好处。
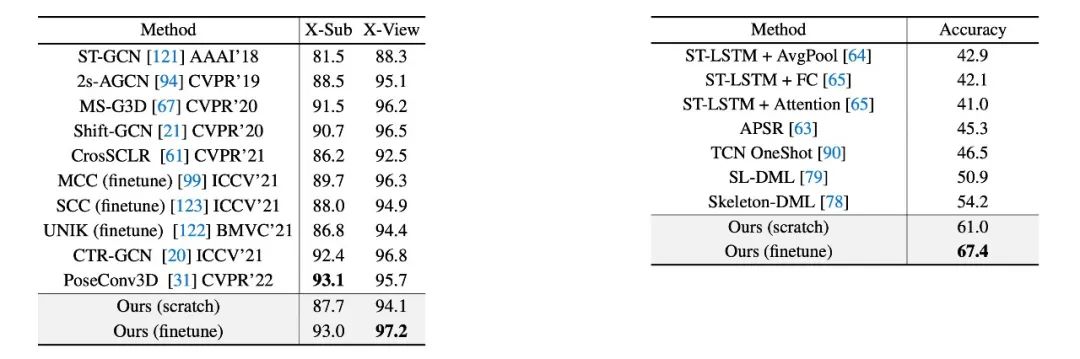
表2. 基于骨架的动作识别准确度的定量评估。(左)NTU-RGB+D 上的跨角色(X-Sub)和跨视角(X-View)识别准确度。(右)NTU-RGB+D-120 上的单样本学习识别精度。所有结果都是第一选项准确度(%)。
对于基于骨架的动作识别任务,我们在 NTU-RGB+D[4]和 NTU-RGB+D-120[5]上进行了定量测试。在完全监督的场景下本文的方法与最先进的方法相当或更好,如表2(左)所示。值得注意的是,预训练阶段带来了很大的性能提升。此外,本文研究了可用于未见动作和稀缺标签的单样本学习设置。表2(右)说明所提出的模型大幅度优于此前最佳的模型。值得注意的是,预训练运动表征只需1-2轮微调即可达到最佳性能。
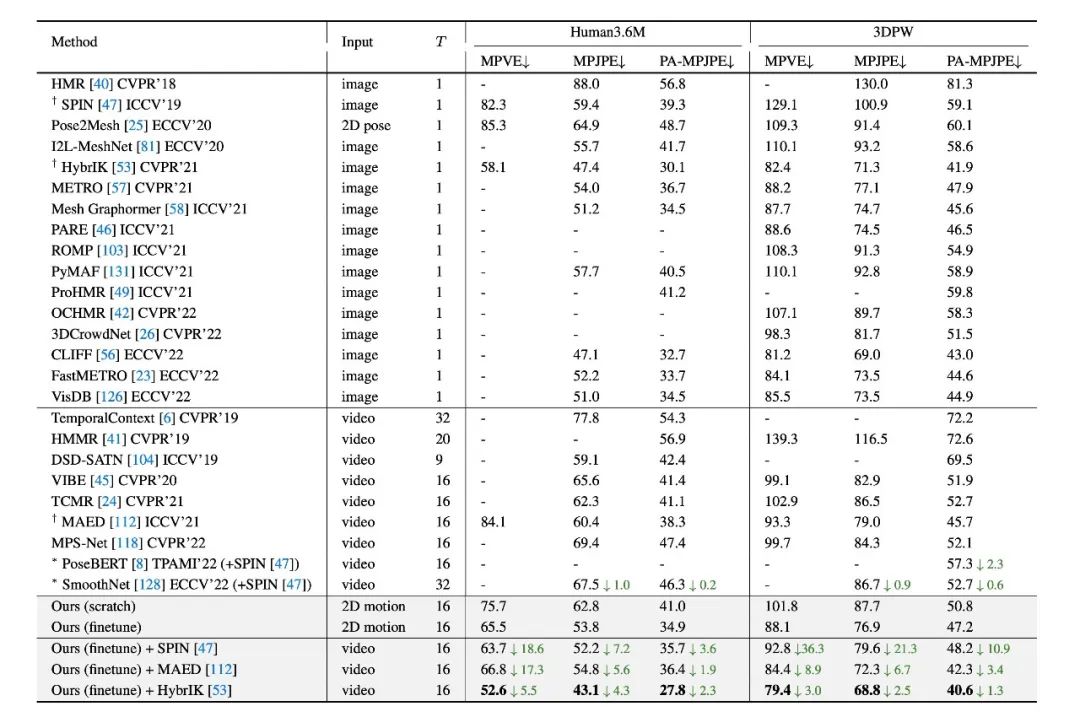
表3. 人体表面网格重建的定量评估。数字代表平均三维位置误差(mm)。
对于人体表面网格重建任务,我们在 Human3.6M[3] 和 3DPW[6]数据集上进行了定量测试。本文的模型超过了此前所有基于视频的方法。此外,所提出的预训练运动表征可以和 RGB 图像的方法相结合并进一步改善其表现。
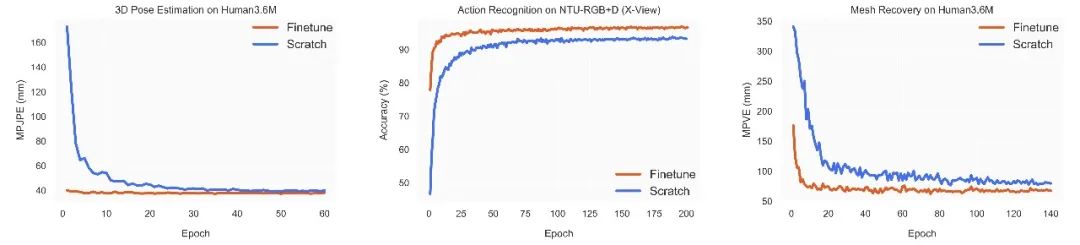
图5. 在三个下游任务上随机初始化训练和微调预训练运动表征的学习曲线对比。
我们还比较了微调预训练运动表征和随机初始化训练模型的训练过程。如图5所示,使用预训练运动表征的模型在所有三个下游任务上都具有更好的性能和更快的收敛速度。这表明该模型在预训练期间学习了关于人体运动的可迁移知识,有助于多个下游任务的学习。
04
总 结
在这项工作中,我们提出了:
一个统一的视角以解决各种以人为中心的视频任务。
一个预训练框架以从大规模和多样化的数据源中学习人体运动表征。
一个通用的人体运动编码器 DSTformer 以全面建模人体运动的时空特征。
在多个基准测试上的实验结果证明了学习到的运动表征的多功能性。未来的研究工作可以探索将学习到的运动表征作为一种以人为中心的语义特征与通用视频架构融合,并应用到更多视频任务(例如动作评价、动作分割等)。
-
编码器
+关注
关注
45文章
3640浏览量
134466 -
模型
+关注
关注
1文章
3238浏览量
48824 -
数据源
+关注
关注
1文章
63浏览量
9676
原文标题:ICCV 2023 | 北大提出MotionBERT:人体运动表征学习的统一视角
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
多站低频雷达运动人体微多普勒特征提取与跟踪技术【论文干货】
人体上肢运动表面肌电特征研究
基于多区域的人体运动跟踪研究

监测人体健康和运动表现
基于多区域的人体运动跟踪分析
基于块稀疏模型的人体运动模式识别方法
基于多视角自步学习的人体动作识别方法





 工商网监
工商网监
评论