 实时语义建图与潜在先验网络和准平面分割
实时语义建图与潜在先验网络和准平面分割
文章摘要
实时语义的可获得性极大地提高了SLAM系统的基本几何功能,使得许多机器人和AR/VR应用成为可能。论文提出了一种新的基于RGB-D序列的实时语义建图方法,该方法结合了2D神经网络和基于SLAM系统的3D网络。在分割新帧时,论文基于可微渲染进行从先前帧的潜在特征重投影。与独立处理图像的基线相比,融合重投影的特征图极大地改善了图像分割质量。对于3D地图处理,论文提出了一种新的基于几何的准平面超分段方法,依靠表面法线对可能属于相同语义类别的3D地图元素进行分组。论文还描述了语义地图后处理的新型轻量级神经网络设计。论文的系统在2D-3D网络为基础的系统中实现了最先进的语义建图质量,并与三个真实室内数据集上的基于3D网络的方法相匹配,同时仍保持实时性能。此外,与仅基于3D网络相比,它显示了更好的跨传感器泛化能力。代码和数据将在项目页面上发布//jingwenwang95.github.io/SeMLaPS。
背景补充
3D网络用于语义建图。这一类方法直接处理场景的3D重建,并生成语义标签作为输出。基于PointNet的语义分割方法在多个尺度上处理无序点云。PointConv和KPConv提出了点云上的卷积操作。稀疏子流形卷积和MinkowskiNet仅处理密集体素网格中的占用表面体素,具有合理的内存需求。BP-Net利用了3D网络和2D网络,由特征投影机制连接。INS-Conv展示了一种在线运行基于3D网络的推理的方式,匹配离线3D网络的精度,然而它不能产生SLAM其他语义任务所需的图像级语义标签。
论文方法介绍
A. 系统概述
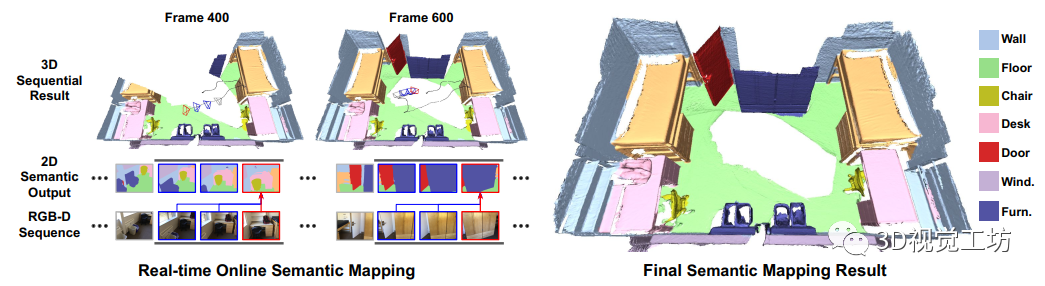
论文在III-B部分描述了论文方法背后的SLAM管道。论文的2D潜在先验网络(LPN)在III-C中描述。LPN输出融合到论文在III-D中描述的论文新颖的准平面超分段(QPOS)方法分割的地图中。接下来,论文运行III-E中描述的Section-Convolutional Network,以获得估计的语义类别。图1显示了整体管道。
B. 实时稠密3D占用建图
论文依靠一个特征为基础的视觉惯性SLAM系统,它另外输出全局校正轨迹,当检测到环路闭合并进行优化时。论文将深度图像和6自由度(DoF)姿态融合到一个子图为基础的3D占用地图中。在每个子图内部,占用信息存储在遵循的自适应分辨率八叉树中。
C. 潜在先验网络
论文的方法通过使用序列中的其他帧的知识来改进RGB-D帧分割,见图3。大多数系统重复独立地分割帧。论文旨在尽可能早地将这种先验知识注入管道中。论文采用SSMA,使用RGB和深度输入的独立编码器,但将ResNet-50编码器替换为计算复杂性方面的轻量级MobileNetV3,见图2。
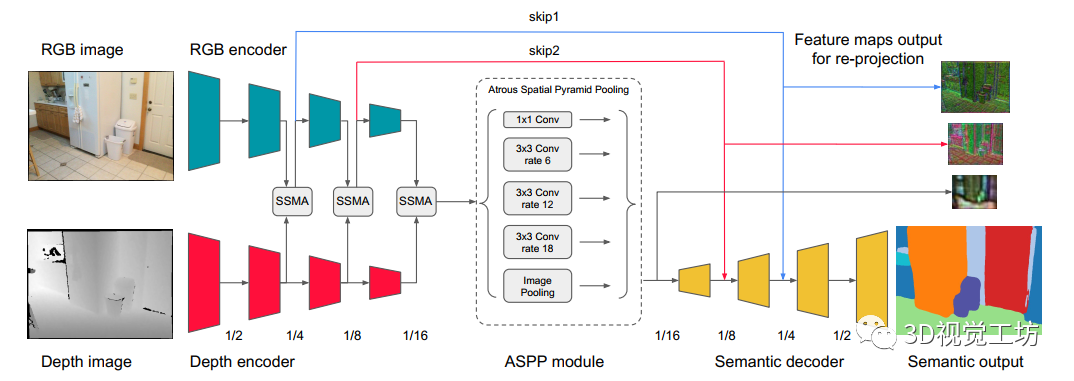
为了强制执行来自多个先前视图的潜在先验,论文提出重新投影不同分辨率的特征图到一个共同的参考视图,使用SLAM系统提供的深度图和相机姿态。论文使用x4、x8和x16下采样的特征图进行重投影,见图2。为了获得平滑的梯度传播,论文使用PyTorch3D提供的可微分渲染器来获得重投影的特征图。然后使用平均池化将重投影的特征图与参考视图特征图融合。
在训练过程中,在每次迭代中,论文对N个相邻帧进行采样,并随机选择一个作为参考视图。来自N-1个相邻视图的潜在特征先验被变形到参考视图上。然后论文计算交叉熵损失:Lsem来自参考视图输出,和Laux邻近视图,以鼓励单视图预测的合理性。论文的最终损失是加权和L = Lsem + wLaux。
注意,论文的LPN设计为从附近的帧中编码潜在先验知识提供了灵活性。首先,尽管N在训练期间是固定的,但在测试时论文的LPN可以接受任意数量的视图。其次,论文可以以顺序模式进行推理,即按顺序即时处理帧。这允许论文重用在先前视图中计算的特征图,因此LPN仅对每个帧进行一次处理。最后,虽然论文的LPN需要深度进行特征重投影和跨视图融合,但在特征提取阶段,论文可以仅依赖于RGB输入并删除深度编码器(图3中的红色部分)。
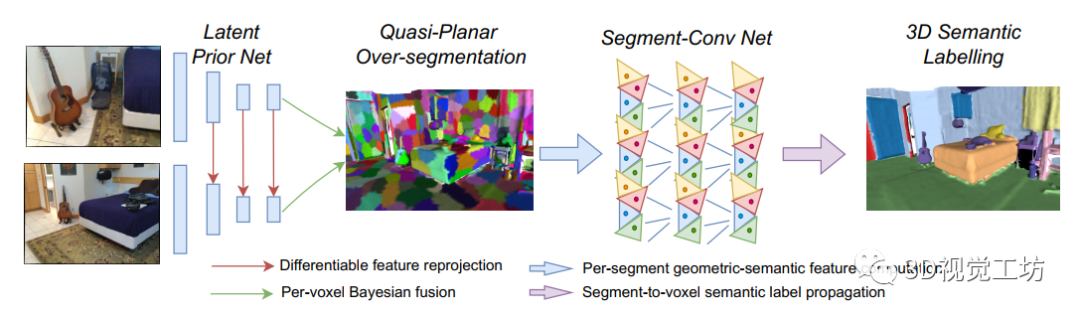
D. 准平面超分段
论文旨在通过将体素分组为段来减少地图基数,提取表面体素的列表,并使用距离场估计它们的法线,构建带权无向图(V,E,w),其中体素为顶点V,边E在共面体素之间。超分段S将体素映射到段标签。论文设S(i)=i,按权重排序边,如果代价F(S)减小则逐个合并:
其中L(S)是段标签集合,是期望的空间段大小。
为了改善段边界的质量,论文应用一个快速的后处理步骤,将体素分配给关联成本最低的段:
其中,是体素i的位置和法线,,,是段l的中心,协方差和法线,是加权因子。 为了效率,论文使用段中心的KD树。
QPOS方法具有O(|E|)复杂度,论文以增量方式在地图更新后使用它,仅使用更新的V和E中的体素,在使用(2)与观察到的段关联之前,试图将新体素与观察到的段关联。论文将QPOS结果用作输入到下面描述的分段卷积网络。
E. 分段卷积网络
段的大小可能不同:在低频场景部分如地板或墙壁中它们更大,而对于桌面上的物体它们更小。论文提出定制非均匀大小段的卷积操作,而SVCNN假设大小统一。
与PointConv 类似,论文将权重网W(·)定义为多层感知器(MLP)以预测卷积核,将特征网Φ(·)定义为特征处理的MLP:
其中是x的相邻段,,是段的中心, 是段内平均特征, 是10D特征向量定义为:
其中是段的表面法线,是两个段之间的位移向量,r、v、w通过格拉姆-施米特正交化过程从和构建正交基。,,其中,表示和的空间协方差。论文的通过方差,增强了中提出的视点不变(VI)特征。 输入段特征,论文使用体素级预测类概率的平均值以及由RGB颜色、位置和表面法线组成的9D几何特征。 对于每个段卷积层,论文使用隐藏维度为8的2层MLP作为W(·),使用隐藏维度为64的2层MLP作为Φ(·)。论文堆叠3个段卷积层形成论文的分段卷积网络。
F. 使用RealSense的语义建图
为了理解不同语义建图方法的跨传感器泛化能力,论文提出了一个使用RealSense D455 [17]采集的四个RGB-D测试序列数据集。它具有使用论文的视觉惯性SLAM系统获得的真实姿态,并使用基于体素大小为0.01米的TSDF融合的稠密映射系统重建网格。 网格使用与ScanNet一致的语义标签进行手动注释。 有四个室内场景(会议室、实验室、厨房和休息室)
G. 系统实现细节
最后,论文提供了整个系统及所提出网络的实现细节,以执行在线实时语义建图。
潜在先验网络。论文在ScanNet v2数据集的1201个训练序列上训练LPN,相邻帧之间的步长为20,使用Adam训练20个epoch,初始学习率为1e-4和one-cycle学习率计划器;论文使用N=3并对数据进行随机缩放、裁剪、翻转、高斯模糊和随机视图顺序排列以进行数据增强。 在单个nVidia RTX-3090ti GPU上训练大约需要3天,批量大小为8。
分段卷积网络。论文在ScanNet v2训练拆分的1201个网格上训练III-E部分描述的分段卷积网络。论文首先对具有段大小ar{s}=60顶点的网格运行论文的QPOS,并通过多数投票将顶点级GT标签传输到段级GT标签。论文顺序地在每个场景上运行论文训练好的LPN,使用贝叶斯融合将2D标签预测转移到3D网格。
上述数据生成过程总共创建了约200万个段。论文使用初始学习率为5e-4和one-cycle调度器的Adam 优化器训练分段卷积网络。在单个Nvidia RTX-3090ti GPU上,批量大小为12,训练100个epoch需要大约2小时。
系统设计细节。论文按照顺序运行潜在先验网络,并在后端SLAM系统更新地图几何时在每个关键帧处执行贝叶斯融合。因此,每个帧仅由LPN处理一次,参考帧将非参考帧的重投影特征图作为输入。接下来,如III-D所述,论文仅针对地图更新受影响的区域执行QPOS。这将更新这些段的属性(特征、段中心、连接拓扑等)。最后,受影响的那些段及其K近邻被馈送到分段卷积网络以预测更新后的类别标签。
方法结论
论文提出了SeMLaPS方法,一个遵循2D-3D通道的实时在线语义建图系统。它受益于利用新颖的潜在先验网络融合历史视图的潜在特征,而准平面超分段和分段卷积网络进一步改善了最终结果,与3D离线方法相匹敌,同时仍保持实时性能。与仅3D网络相比,SeMLaPS实现了更好的跨传感器泛化能力。
-
传感器
+关注
关注
2556文章
51714浏览量
758731 -
SLAM
+关注
关注
23文章
428浏览量
32003 -
感知器
+关注
关注
0文章
34浏览量
11876
原文标题:arXiv2023 | 实时语义建图与潜在先验网络和准平面分割
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
【Altium小课专题 第117篇】如何对PCB的电源平面进行平面分割?
van-自然和医学图像的深度语义分割:网络结构
van-自然和医学图像的深度语义分割:网络结构
聚焦语义分割任务,如何用卷积神经网络处理语义图像分割?
Facebook AI使用单一神经网络架构来同时完成实例分割和语义分割

用图卷积网络解决语义分割问题
RGPNET:复杂环境下实时通用语义分割网络
详解ENet:CPU可以实时的道路分割网络


普通视觉Transformer(ViT)用于语义分割的能力
PyTorch教程-14.9. 语义分割和数据集






 工商网监
工商网监
评论