 HaluEval数据集的构建过程分析
HaluEval数据集的构建过程分析
一、背景
最近,大语言模型(Large Language Models, LLMs)的快速发展带来了自然语言处理领域的范式转变,在各类任务上的优秀表现引发了众多关注。然而,在自然语言社区迎接和拥抱大语言模型时代的同时,也迎来了一些属于大模型时代的新问题,其中大模型的幻象问题(Hallucination in LLMs)是最具代表性的问题之一。大语言模型的幻象问题是指其生成的内容要么与现有的内容有冲突,要么无法通过已有的事实或知识进行验证。图1是一个大模型生成的文本中包含幻象的例子,当用户询问大模型两磅羽毛和一磅砖头哪个更重时,模型给出的答案自相矛盾,首先回答二者一样重,然后又说两磅比一磅重。这也就是众多用户在与大模型交互过程中遇到的,大模型会“一本正经的胡说八道”的现象。对用户来说,大模型生成文本的可信度是一项非常重要的指标。如果生成的文本无法信任,则会严重影响大模型在现实世界中的应用。
为了进一步研究大模型幻象的内容类型和大模型生成幻象的原因,本文提出了用于大语言模型幻象评估的基准——HaluEval。我们基于现有的数据集,通过自动生成和手动标注的方式构建了大量的幻象数据组成HaluEval的数据集,其中包含特定于问答、对话、文本摘要任务的30000条样本以及普通用户查询的5000条样本。在本文中,我们详细介绍了HaluEval数据集的构建过程,对构建的数据集进行了内容分析,并初步探索了大模型识别和减少幻象的策略。
二、HaluEval Benchmark
数据构建
HaluEval包含35000条带幻象的样本和对应的正确样本用于大模型幻象的评估。为了生成幻象数据集,我们设计了自动生成和人工标注两种构建方式。对于特定于问答、基于知识的对话和文本摘要三类任务的样本,我们采用自动生成的构建方式;对于一般的用户查询数据,我们采用人工标注的构建方式。
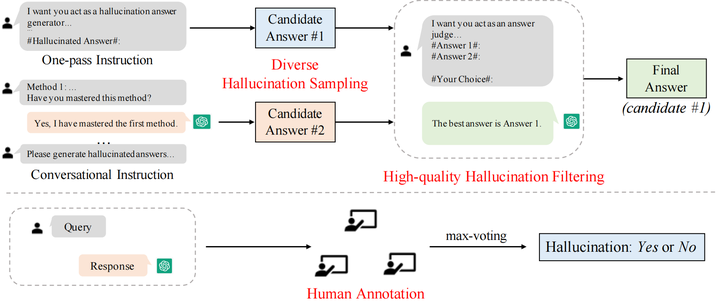
图2 HaluEval的构建方法
自动生成
HaluEval中基于任务的样本共有30000条,其中问答、基于知识的对话和文本摘要各有10000条,分别基于现有的数据集HotpotQA,OpenDialKG, CNN/Daily Mail作为种子数据进行采样生成。
对于自动生成,我们设计了先采样后过滤的两步生成框架,包括多样化的幻象采样和高质量的幻象过滤两个步骤。
多样化的幻象采样 为了在采样指令中给出条理的幻象生成方法,针对三类任务,我们参考现有的工作将幻象分为不同类型,并向模型输入各个类别幻象介绍作为生成幻象样本的方法。对于问答任务,将幻象分为comprehension、factualness、specificity和inference四种类型;对于基于知识的问答任务,将幻象分为extrinsic-soft,、extrinsic-hard和 extrinsic-grouped三类;对于文本摘要任务,将幻象分为factual、non-factual和intrinsic三类。考虑到生成的幻象样本可以有不同的类型,我们提出了两种采样方法来生成幻象。如图2所示,第一种方法采用单指令模式(one-pass instruction),我们直接将包含所有生成幻象方法的完整的指令输入ChatGPT,然后得到生成的幻象答案;第二种方法采用对话式的指令(conversational instruction),每轮对话输入一种生成幻象的方法,确保ChatGPT掌握了每一类方法,最后根据学到的指令生成给定问题的幻象答案。使用两种策略进行采样,每个问题可以得到两个候选的幻象答案。
高质量的幻象过滤 为了得到更加合理和具有挑战性的幻象样本,我们对采样得到的两个候选答案进行过滤。为了提高过滤质量,我们在幻象过滤指令中加入样本过滤的示例。与对两个幻象答案进行过滤不同,过滤指令中的示例包含正确答案和幻象答案,我们选择正确答案作为过滤结果;然后输入测试样本的两个候选幻象答案让模型进行选择,期望ChatGPT选择更加接近真实答案的幻象答案来增强过滤效果。通过进一步的过滤,得到的幻象答案更加难以识别。我们收集过滤得到的更具挑战性的候选样本作为最终的幻象样本。
在先采样后过滤的自动生成框架中,关键在于设计有效的指令来生成和过滤幻象答案。在我们的设计中,幻象的采样指令包括意图描述、幻象模式和幻象示例三部分,图3为问答任务的采样指令,其中蓝色部分表示意图描述,红色部分为幻象模式,绿色部分为幻象示例;幻象的过滤指令包括意图描述和过滤示例两部分,图4为问答任务的幻象过滤指令,其中蓝色部分表示意图描述,绿色部分为过滤示例。

图3 问答任务的幻象采样指令
 图4 问答任务的幻象过滤指令
图4 问答任务的幻象过滤指令
人工标注
对于一般的用户查询,我们采用人工标注的方法构建数据。我们邀请三位专家对来自Alpaca数据集的普通用户查询和ChatGPT回复进行人工标注,判断ChatGPT的回复中是否包含幻象并标注包含幻象的片段。在进行人工标注之前,为了筛选出更有可能产生幻觉的用户查询,我们首先设计了一个预选程序。具体来说,我们使用 ChatGPT 对每个用户查询生成三个响应,然后使用 BERTScore 计算它们的平均语义相似度,最终保留了 5000 个相似度最低的用户查询。如图2所示,筛选出来的每个样本由三个专家进行标记,标注者从三个方面判断回复中是否包含幻象并标注幻象所在位置:unverifiable,、non-factual和irrelevant,我们最终采用最大投票策略来确定回复中是否包含幻象。
基准使用
为了帮助大家更好地使用HaluEval,我们提出了使用HaluEval来进行大模型幻象研究的三个可能的方向。
基于HaluEval中生成和注释的幻象样本,研究人员可以分析大模型产生幻象的查询属于什么主题;
HaluEval可以用于评估大模型识别幻象的能力,例如给定一个问题及答案,要求大模型判断答案中是否包含幻象;
HaluEval包含正确样本和幻象样本,因此也可用于评估大模型的输出是否包含幻象。
三、实验
在实验部分,为了测试大模型在HaluEval上的幻象识别表现,我们使用所构造的HaluEval,在davinci、text-davinci-002、text-davinci-003和gpt-3.5-turbo四个模型上进行了幻象识别实验,并针对实验结果进行了详细分析,最后提出了一些可能对提高识别效果有用的策略。
幻象识别实验
在幻象识别实验中,对于每一个测试样本我们以50%的概率从幻象答案和正确答案中选择一个作为测试答案,将问题与测试答案一起输入模型,让模型判断测试答案中是否包含幻象。如图5所示,类似于幻象生成和过滤的步骤,我们设计了用于幻象识别的指令,包括意图描述、幻象模式和幻象识别示例,并在上述四个模型上进行测试。表1中展示了四个模型在幻象识别任务上的准确率。

图5 问答任务的幻象识别指令
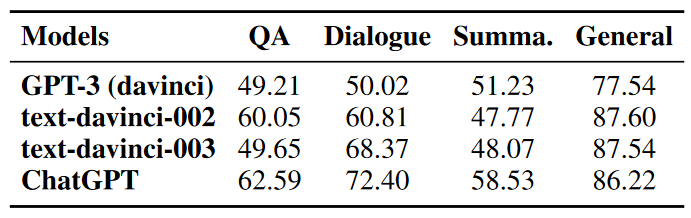
表1 幻象识别实验结果
实验结果表明,LLM在识别文本中的幻象这一任务上表现不佳,ChatGPT在文本摘要任务上仅达到58.53%的准确率,与50%的随机概率相差不大;而其他模型例如GPT-3在问答、对话和摘要任务上的准确率几乎都在50%左右。
为了进一步分析ChatGPT没有检测出的幻象样本,我们使用LDA对所有的测试样本和检测失败样本进行聚类,并对聚类得到的主题进行可视化。我们将各个数据集的测试数据聚类为10个主题,并将其中检测失败的主题标记为红色,如图6所示。从聚类结果来看,我们发现LLM无法识别的幻象集中在几个特定的主题。例如QA中的电影、公司、乐队;对话中的书籍、电影、科学;摘要中的学校、政府、家庭;普通用户查询中的技术、气候和语言等话题。
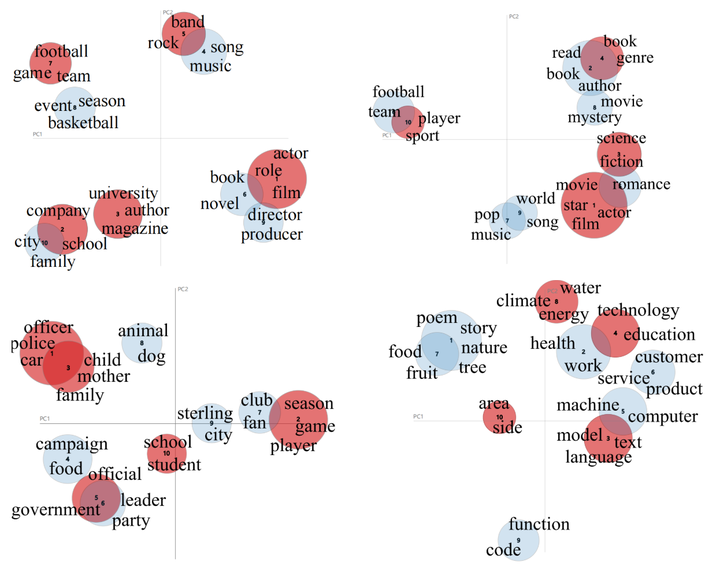
图6 主题聚类
提升策略
鉴于现有的LLM在幻象识别方面表现欠佳,我们尝试提出几种策略来提升大模型识别幻象的能力,包括知识检索、思维链推理和样本对比。我们使用提出的三种策略在ChatGPT上重新进行幻象识别实验,下表为使用各个策略后ChatGPT的幻象识别准确率。
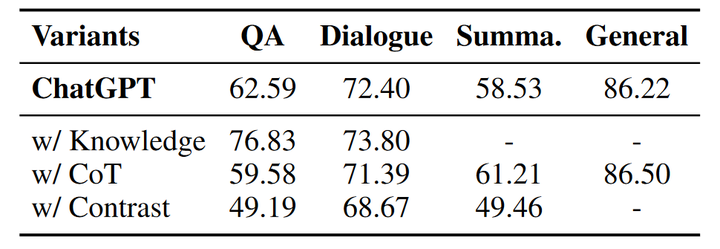
表2 幻象识别能力提升策略实验结果
知识检索
知识检索是一个广泛使用的用于减少幻象的手段。在幻象检测实验中,我们向ChatGPT提供在Wikipedia检索到的相关事实知识(除了摘要任务),并在指令中要求ChatGPT根据给定知识和问题判断答案中是否包含幻象。通过向模型提供相关的事实知识,幻象的识别准确率有较为明显的提升,尤其是在问答任务中,准确率从62.59%提升到了76.83%;对话任务也有小幅度的提升。因此,为LLM提供外部知识可以很大程度上增强其识别幻象的能力。
CoT推理
思维链(chain-of-thought)推理是一种通过使LLM加入中间步骤进行推理来获得最终结果的手段,之前的工作在一些数学问题和逻辑问题中引入思维链,能够明显提升模型解决问题的能力。在幻象识别实验中,我们同样引入思维链推理进行尝试,在识别指令中要求模型逐步生成推理步骤最终得到识别结果。然而和知识检索相比,在输出中添加思维链并没有提高模型识别幻象的能力,反而在部分任务上准确率有所下降。与知识检索相比,思维链推理并不能为模型提供显式的外部知识,反而有可能会干扰最终的判断。
样本对比
我们进一步为模型同时提供正确答案和幻象答案来测试模型是否具备区分正确样本和幻象样本的能力。表中的实验结果显示提供正确样本使得幻象识别的准确率有较大的下降,这可能是由于生成的幻象答案与真实答案有很高的相似性,也进一步说明了HaluEval的幻象识别对LLM来说具有很大的挑战性。
四、总结
本文引入了大型语言模型幻象评估基准——HaluEval,这是一个大规模的自动生成的和人工注释的幻象样本集合,用于评估大语言模型在识别幻象方面的表现。首先我们介绍了HaluEval的构建过程,包含自动生成和人工标注。为了自动生成幻象样本,我们提出先采样后过滤的两步生成框架;人工标注部分我们请专家针对用户查询的回复进行标注。基于HaluEval,我们评估了四个大模型在识别幻象方面的表现,分析了幻象识别实验的结果,并且提出了三个提升幻想识别能力的策略。基于在HaluEval上的测评实验,我们得出以下结论:
ChatGPT很可能会编造无法核实的信息,从而在一些特定主题中产生幻觉内容。
现有的大语言模型在识别文本中的幻觉方面面临着巨大的挑战。
可以通过提供外部知识或增加推理步骤来提高幻觉识别的准确率。
总之,我们提出的HaluEval基准能够帮助分析大模型生成幻象的内容,也可用于大模型幻象识别和减轻的研究,为未来建立更加安全可靠的LLM铺平了道路。
审核编辑:刘清
-
过滤器
+关注
关注
1文章
434浏览量
19858 -
LDA
+关注
关注
0文章
29浏览量
10678 -
ChatGPT
+关注
关注
29文章
1578浏览量
8285
原文标题:幻象 or 事实 | HaluEval:大语言模型的幻象评估基准
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
请问NanoEdge AI数据集该如何构建?
DevEco Studio构建分析工具Build Analyzer 为原生鸿蒙应用开发提速
请问NanoEdge AI数据集该如何构建?
怎么删除分析中的“Ghost”数据集
高阶API构建模型和数据集使用

WSN中能量有效的连通支配集构建算法

如何构建高质量的大语言模型数据集
大模型数据集:构建、挑战与未来趋势
宏集INSYS工业路由器构建可靠的水厂过程控制系统

宏集ASPION数据记录器:分析运输过程中的碰撞、冲击和振动





 工商网监
工商网监
评论