 语言模型做先验,统一强化学习智能体,DeepMind选择走这条通用AI之路
语言模型做先验,统一强化学习智能体,DeepMind选择走这条通用AI之路
在智能体的开发中,强化学习与大语言模型、视觉语言模型等基础模型的进一步融合究竟能擦出怎样的火花?谷歌 DeepMind 给了我们新的答案。
一直以来,DeepMind 引领了强化学习(RL)智能体的发展,从最早的 AlphaGo、AlphaZero 到后来的多模态、多任务、多具身 AI 智能体 Gato,智能体的训练方法和能力都在不断演进。
从中不难发现,随着大模型越来越成为人工智能发展的主流趋势,DeepMind 在智能体的开发中不断尝试将强化学习与自然语言处理、计算机视觉领域融合,努力实现不同模态任务的统一。Gato 很好地说明了这一点。
近日,谷歌 DeepMind 在一篇新论文《Towards A Unified Agent with Foundation Models》中,探讨了利用基础模型打造统一的智能体。

一作 Norman Di Palo 为帝国理工学院机器学习博士生,在谷歌 DeepMind 实习期间(任职研究科学家)参与完成本论文。
论文地址:https://arxiv.org/pdf/2307.09668.pdf
何谓基础模型(Foundation Models)呢?我们知道,近年来,深度学习取得了一系列令人瞩目的成果,尤其在 NLP 和 CV 领域实现突破。尽管模态不同,但具有共同的结构,即大型神经网络,通常是 transformer,使用自监督学习方法在大规模网络数据集上进行训练。
虽然结构简单,但基于它们开发出了极其有效的大语言模型(LLM),能够处理和生成具有出色类人能力的文本。同时,ViT 能够在无监督的情况下从图像和视频中提取有意义的表示,视觉语言模型(VLM)可以连接描述语言中视觉输入或将语言描述转换为视觉输出的数据模态。
这些模型的规模和能力使社区创造出了「基础模型」一词,这些模型可以用作涵盖各种输入模态的下游任务的支柱。
问题来了:我们能否利用(视觉)语言模型的性能和能力来设计更高效和通用的强化学习智能体呢?
在接受网络规模的文本和视觉数据训练后,这些模型的常识推理、提出和排序子目标、视觉理解和其他属性也出现了。这些都是需要与环境交互并从环境中学习的智能体的基本特征,但可能需要花费大量的时间才能从反复试错中显现出来。而利用存储在基础模型中的知识,我们能够极大地引导这一过程。
受到这一思路的启发,谷歌 DeepMind 的研究者设计了一个全新的框架,该框架将语言置于强化学习机器人智能体的核心,尤其是在从头开始学习的环境中。
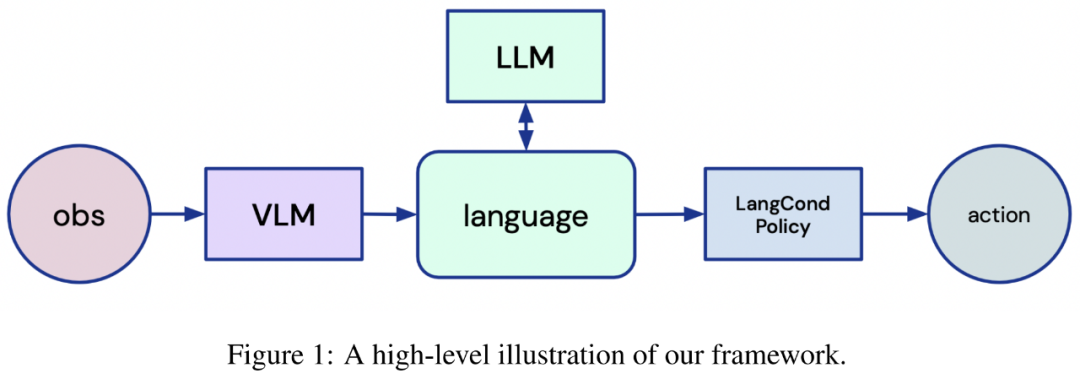
图 1:框架示意图。
他们表示,这个利用了 LLM 和 VLM 的框架可以解决强化学习设置中的一系列基础问题,具体如下:
1)高效探索稀疏奖励环境
2)重新使用收集的数据来有序引导新任务的学习
3)调度学得的技巧来解决新任务
4)从专家智能体的观察中学习
在最近的工作中,这些任务需要不同的、专门设计的算法来单独处理,而本文证明了利用基础模型开发更统一方法的可能性。
此外,谷歌 DeepMind 将在 ICLR 2023 的 Reincarnating Reinforcement Learning Workshop 中展示该研究。
以语言为中心的智能体框架
该研究旨在通过分析基础模型的使用,设计出更通用的 RL 机器人智能体,其中基础模型在大量图像和文本数据集上进行预训练。该研究为 RL 智能体提出了一个新框架,利用 LLM 和 VLM 的出色能力使智能体能够推理环境、任务,并完全根据语言采取行动。
为此,智能体首先需要将视觉输入映射到文本描述;然后该研究要用文本描述和任务描述 prompt LLM,以向智能体提供语言指令。最后,智能体需要将 LLM 的输出转化为行动。
使用 VLM 连接视觉和语言
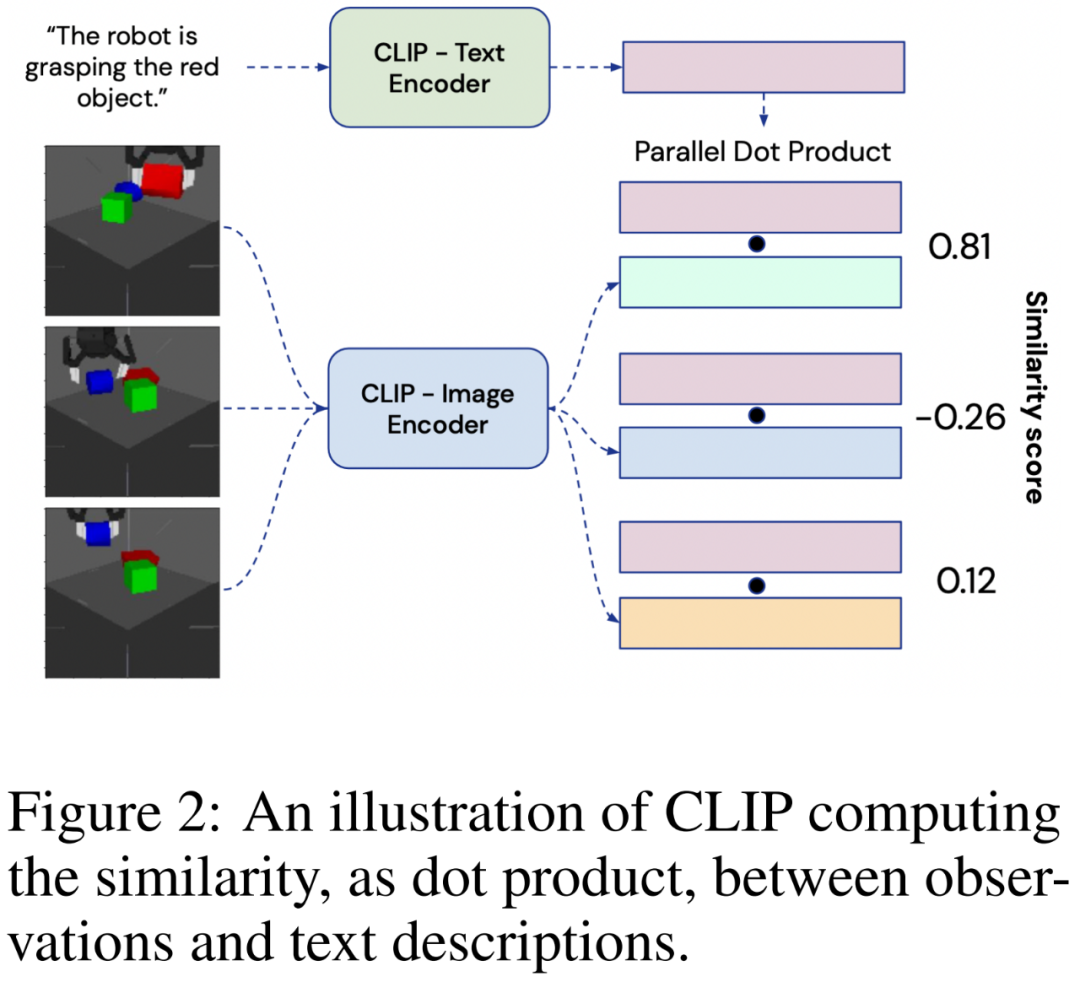
为了以语言形式描述从 RGB 相机获取的视觉输入,该研究使用了大型对比视觉语言模型 CLIP。
CLIP 由图像编码器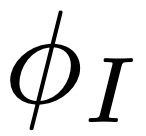 和文本编码器
和文本编码器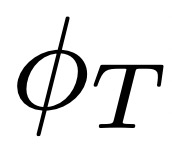 组成,在含有噪声的大型图像 - 文本描述对数据集上进行训练。每个编码器输出一个 128 维的嵌入向量:图像嵌入和匹配的文本描述会经过优化以具有较大的余弦相似度。为了从环境中生成图像的语言描述,智能体会将观察Ot提供给,并将可能的文本描述 ln提供给,如下图 2 所示:
组成,在含有噪声的大型图像 - 文本描述对数据集上进行训练。每个编码器输出一个 128 维的嵌入向量:图像嵌入和匹配的文本描述会经过优化以具有较大的余弦相似度。为了从环境中生成图像的语言描述,智能体会将观察Ot提供给,并将可能的文本描述 ln提供给,如下图 2 所示:
用 LLM 进行推理
语言模型将语言形式的 prompt 作为输入,并通过自回归计算下一个 token 的概率分布并从此分布中采样来生成语言形式的输出。该研究旨在让 LLM 获取表征任务的文本指令,并生成一组供机器人解决的子目标。在模型方面,该研究使用 FLAN-T5,定性分析表明,FLAN-T5 的表现略好于未根据指令进行微调的 LLM。
LLM 的 in-context 学习能力使该研究能够直接使用它们,无需进行域内微调,并仅需要提供两个任务指令和所需的语言输出样本来指导 LLM 的行为。
将指令转化为行动
然后,使用语言条件策略网络将 LLM 提供的语言目标转化为行动。该参数化为 Transformer 的网络将语言子目标的嵌入和时间步 t 时的 MDP 状态(包括物体和机器人终端执行器的位置)作为输入,每个输入都用不同的向量表征,然后输出机器人在时间步 t + 1 时要执行的动作。如下所述,该网络是在 RL 循环中从头开始训练的。
收集与推断的学习范式
智能体从与环境的交互中学习,其方法受到收集与推理范式的启发。
在「收集」阶段,智能体与环境互动,以状态、观察结果、行动和当前目标(s_t, o_t, a_t, g_i)的形式收集数据,并通过其策略网络 f_θ(s_t, g_i) → a_t 预测行动。每一集结束后,智能体都会使用 VLM 来推断收集到的数据中是否出现了任何子目标,从而获得额外奖励,将在后面详细说明。
在「推断」阶段,研究者会在每个智能体完成一集后,即每完成 N 集后,通过行为克隆对经验缓冲区中的策略进行训练,从而在成功的情节上实现一种自我模仿。然后,更新后的策略权重将与所有分布式智能体共享,整个过程重复进行。
应用与成果
将语言作为智能体的核心,这为解决 RL 中的一系列基本挑战提供了一个统一的框架。在这部分内容中,研究者讨论了这些贡献:探索、重用过去的经验数据、调度和重用技能以及从观察中学习。算法 1 描述了整体框架:

探索:通过语言生成课程
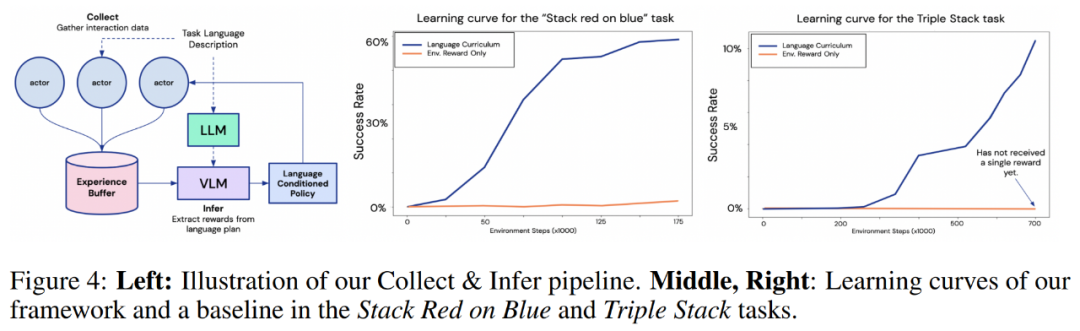
Stack X on Y 和 Triple Stack 的结果。在下图 4 中,研究者所提出框架与仅通过环境奖励进行学习的基线智能体进行了比较。从学习曲线可以清楚地看到,在所有任务中,本文的方法都比基线方法高效得多。
值得注意的是,在 Triple Stack 任务中,本文智能体的学习曲线迅速增长,而基线智能体仍然只能获得一个奖励,这是因为任务的稀疏度为 10^6 。
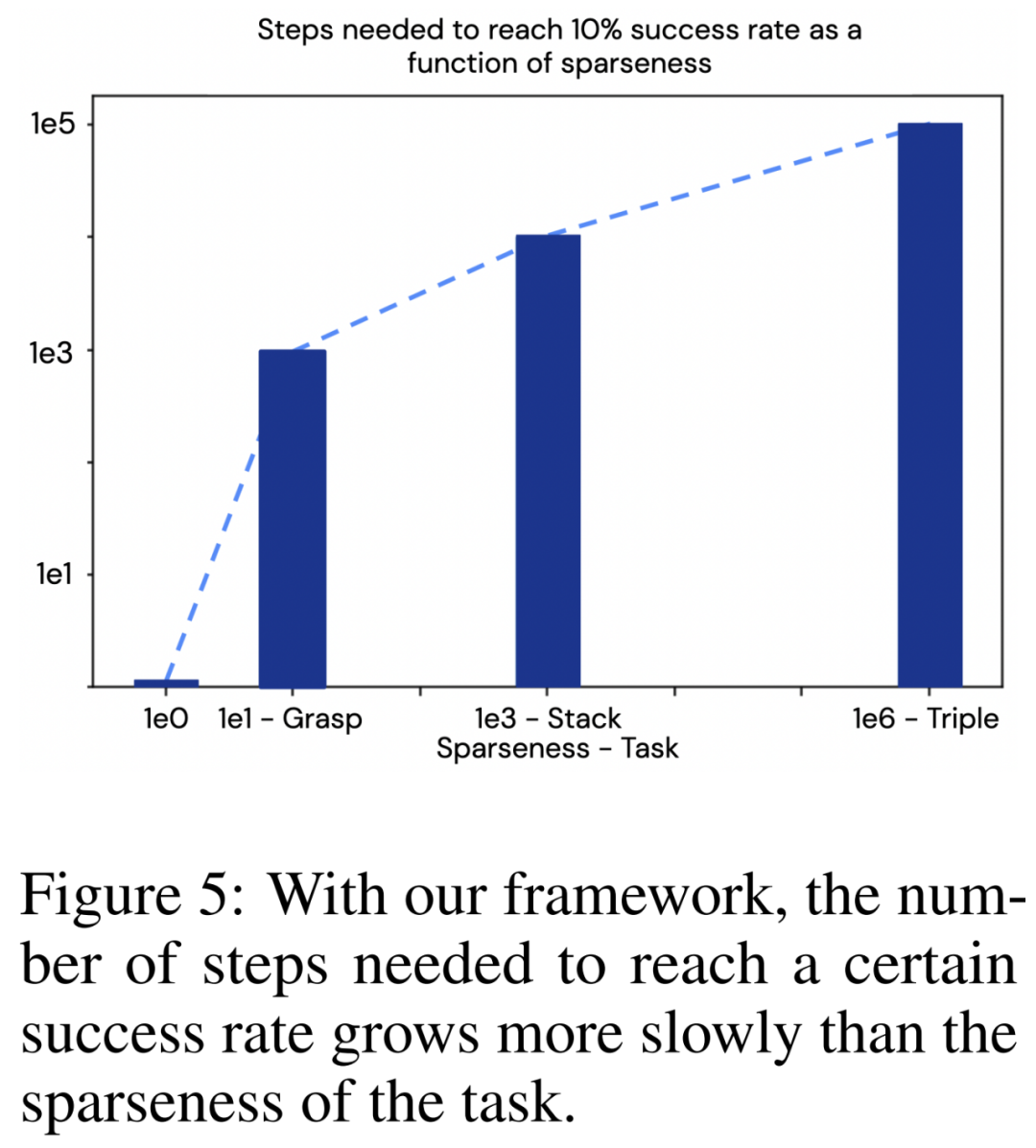
这些结果说明了一些值得注意的问题:可以将任务的稀疏程度与达到一定成功率所需的步骤数进行比较,如下图 5 所示。研究者还在 「抓取红色物体」任务上训练了该方法,这是三个任务中最简单的一个,其稀疏程度约为 10^1。可以看到,在本文的框架下,所需步骤数的增长速度比任务的稀疏程度更慢。这是一个特别重要的结果,因为通常在强化学习中,情况是正好相反的。
提取和转移:通过重用离线数据进行高效的连续任务学习
研究者利用基于语言的框架来展示基于智能体过去经验的引导。他们依次训练了三个任务:将红色物体堆叠在蓝色物体上、将蓝色物体堆叠在绿色物体上、将绿色物体堆叠在红色物体上,将其称之为 [T_R,B、T_B,G、T_G,R]。
顺序任务学习的经验重用结果。智能体应用这种方法连续学习了 [T_R,B、T_B,G、T_G,R]。在每个新任务开始时,研究者都会重新初始化策略权重,目标是探索本文框架提取和重用数据的能力,因此要隔离并消除可能由网络泛化造成的影响。
下图 7 中绘制了智能体需要在环境中采取多少交互步骤才能在每个新任务中达到 50% 的成功率。实验清楚地说明了本文使用技术在重复利用以前任务收集的数据方面的有效性,从而提高了新任务的学习效率。
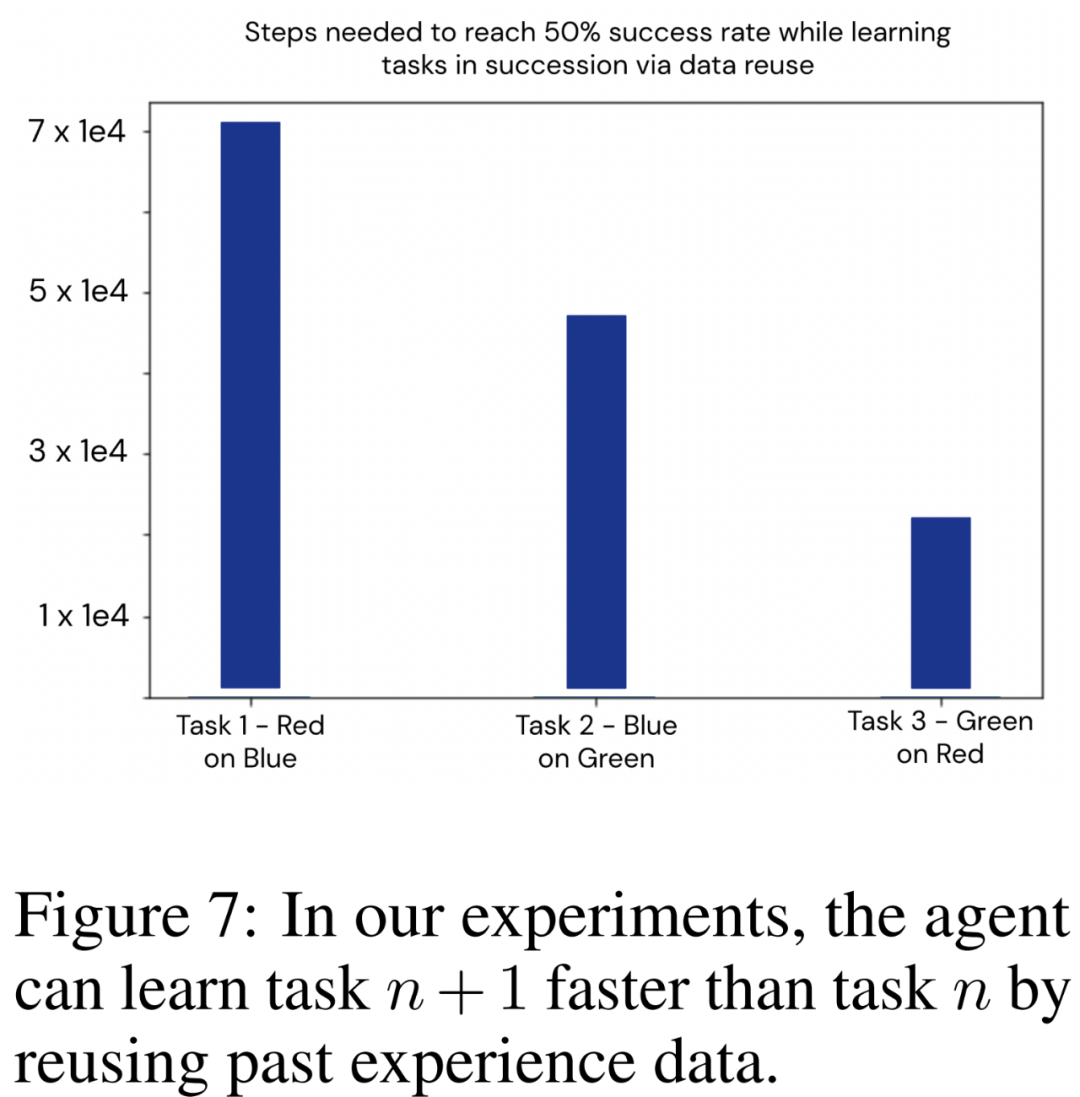
这些结果表明,本文提出的框架可用于释放机器人智能体的终身学习能力:连续学习的任务越多,学习下一个任务的速度就越快。
调度和重复使用所学技能
至此,我们已经了解到框架如何使智能体能够高效地探索和学习,以解决回报稀少的任务,并为终身学习重复使用和传输数据。此外,框架还能让智能体调度和重复使用所学到的 M 技能来解决新任务,而不局限于智能体在训练过程中遇到的任务。
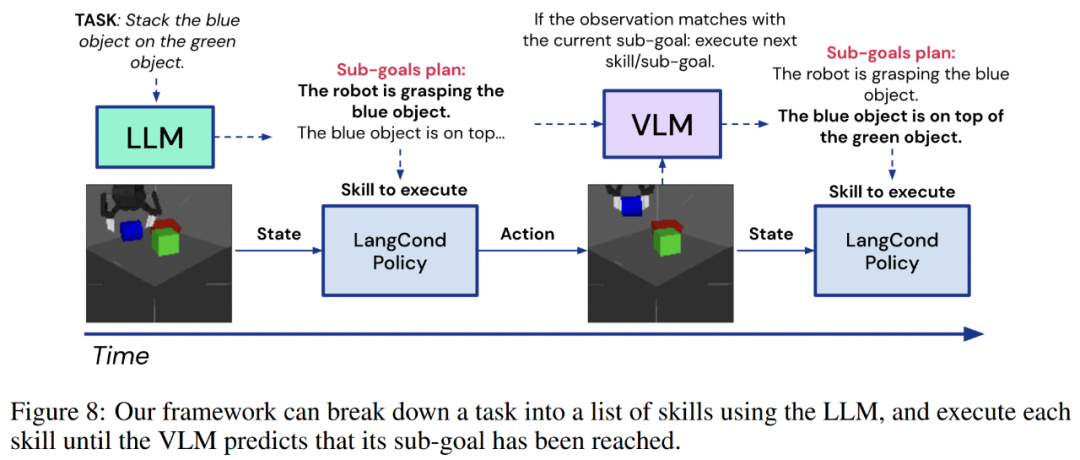
这种模式与前几节中遇到的步骤相同:一条指令会被输入到 LLM,如将绿色物体叠放在红色物体上,或将红色叠放在蓝色物体上,再将绿色叠放在红色物体上,然后 LLM 会将其分解为一系列更短视距的目标,即 g_0:N。然后,智能体可以利用策略网络将这些目标转化为行动,即 f_θ(s_t, g_n) → a_t。
从观察中学习:将视频映射到技能
通过观察外部智能体学习是一般智能体的理想能力,但这往往需要专门设计的算法和模型。而本文智能体可以以专家执行任务的视频为条件,实现 one-shot 观察学习。
在测试中,智能体拍摄了一段人类用手堆叠物体的视频。视频被分为 F 个帧,即 v_0:F。然后,智能体使用 VLM,再配上以子目标 g_0:M 表示的关于所学技能的 M 文本描述来检测专家轨迹遇到了哪些子目标,具体如下图 8:
更多技术细节和实验结果请查阅原论文。
原文标题:语言模型做先验,统一强化学习智能体,DeepMind选择走这条通用AI之路
文章出处:【微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
-
物联网
+关注
关注
2914文章
45142浏览量
379216
原文标题:语言模型做先验,统一强化学习智能体,DeepMind选择走这条通用AI之路
文章出处:【微信号:tyutcsplab,微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
详解RAD端到端强化学习后训练范式

了解DeepSeek-V3 和 DeepSeek-R1两个大模型的不同定位和应用选择
蚂蚁集团收购边塞科技,吴翼出任强化学习实验室首席科学家
如何使用 PyTorch 进行强化学习
【《大语言模型应用指南》阅读体验】+ 基础知识学习
【《大语言模型应用指南》阅读体验】+ 基础篇
大模型应用之路:从提示词到通用人工智能(AGI)
通过强化学习策略进行特征选择







 工商网监
工商网监
评论