 让Attention提速9倍!FlashAttention燃爆显存,Transformer上下文长度史诗级提升
让Attention提速9倍!FlashAttention燃爆显存,Transformer上下文长度史诗级提升
FlashAttention新升级!斯坦福博士一人重写算法,第二代实现了最高9倍速提升。
继超快且省内存的注意力算法FlashAttention爆火后,升级版的2代来了。FlashAttention-2是一种从头编写的算法,可以加快注意力并减少其内存占用,且没有任何近似值。比起第一代,FlashAttention-2速度提升了2倍。甚至,相较于PyTorch的标准注意力,其运行速度最高可达9倍。
一年前,StanfordAILab博士Tri Dao发布了FlashAttention,让注意力快了2到4倍,如今,FlashAttention已经被许多企业和研究室采用,广泛应用于大多数LLM库。如今,随着长文档查询、编写故事等新用例的需要,大语言模型的上下文以前比过去变长了许多——GPT-4的上下文长度是32k,MosaicML的MPT上下文长度是65k,Anthropic的Claude上下文长度是100k。但是,扩大Transformer的上下文长度是一项极大的挑战,因为作为其核心的注意力层的运行时间和内存要求,是输入序列长度的二次方。Tri Dao一直在研究FlashAttention-2,它比v1快2倍,比标准的注意力快5到9倍,在A100上已经达到了225 TFLOP/s的训练速度!

项目链接:
https://github.com/Dao-AILab/flash-attention

FlashAttention-2:更好的算法、并行性和工作分区
端到端训练GPT模型,速度高达225 TFLOP/s
虽说FlashAttention在发布时就已经比优化的基线快了2-4倍,但还是有相当大的进步空间。比方说,FlashAttention仍然不如优化矩阵乘法(GEMM)运算快,仅能达到理论最大FLOPs/s的25-40%(例如,在A100 GPU上的速度可达124 TFLOPs/s)。
对注意力计算重新排序
我们知道,FlashAttention是一种对注意力计算进行重新排序的算法,利用平铺、重新计算来显著加快计算速度,并将序列长度的内存使用量从二次减少到线性。
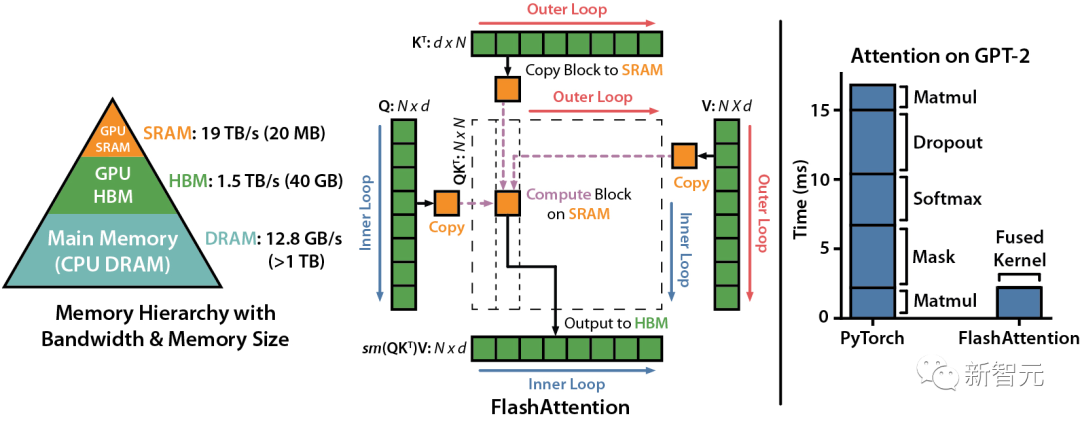
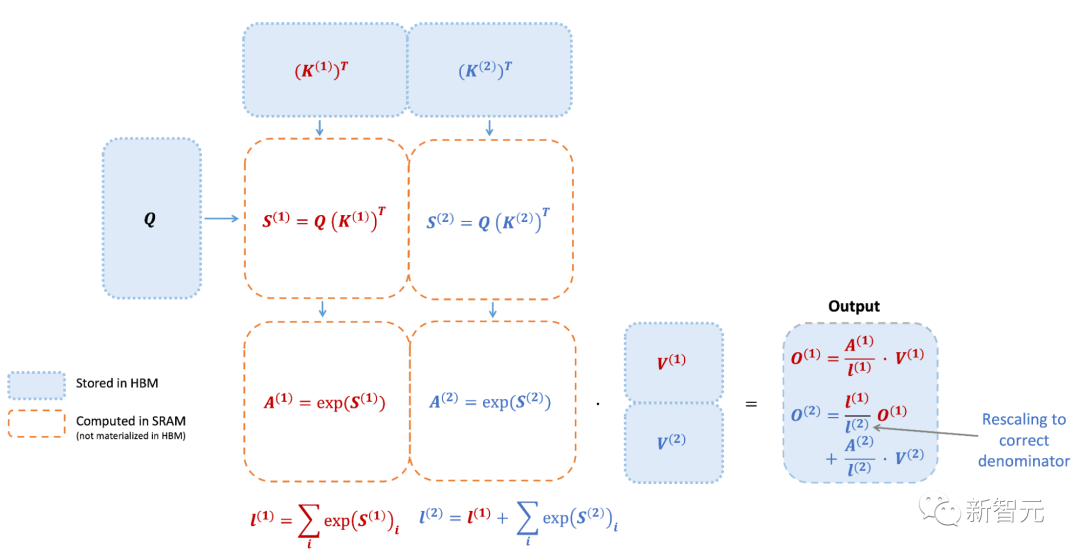
然而,FlashAttention仍然存在一些低效率的问题,这是由于不同线程块之间的工作划分并不理想,以及GPU上的warp——导致低占用率或不必要的共享内存读写。
更少的non-matmulFLOP(非矩阵乘法浮点计算数)
研究人员通过调整FlashAttention的算法来减少non-matmul FLOP的次数。这非常重要,因为现代GPU有专门的计算单元(比如英伟达GPU上的张量核心),这就使得matmul的速度更快。例如,A100 GPU FP16/BF16 matmul的最大理论吞吐量为312 TFLOPs/s,但non-matmul FP32的理论吞吐量仅为 19.5 TFLOPs/s。另外,每个非matmul FLOP比matmul FLOP要贵16倍。所以为了保持高吞吐量,研究人员希望在matmul FLOP上花尽可能多的时间。研究人员还重新编写了FlashAttention中使用的在线softmax技巧,以减少重新缩放操作的数量,以及边界检查和因果掩码操作,而无需更改输出。更好的并行性
FlashAttention v1在批大小和部数量上进行并行化处理。研究人员使用1个线程块来处理一个注意力头,共有 (batch_size * head number) 个线程块。
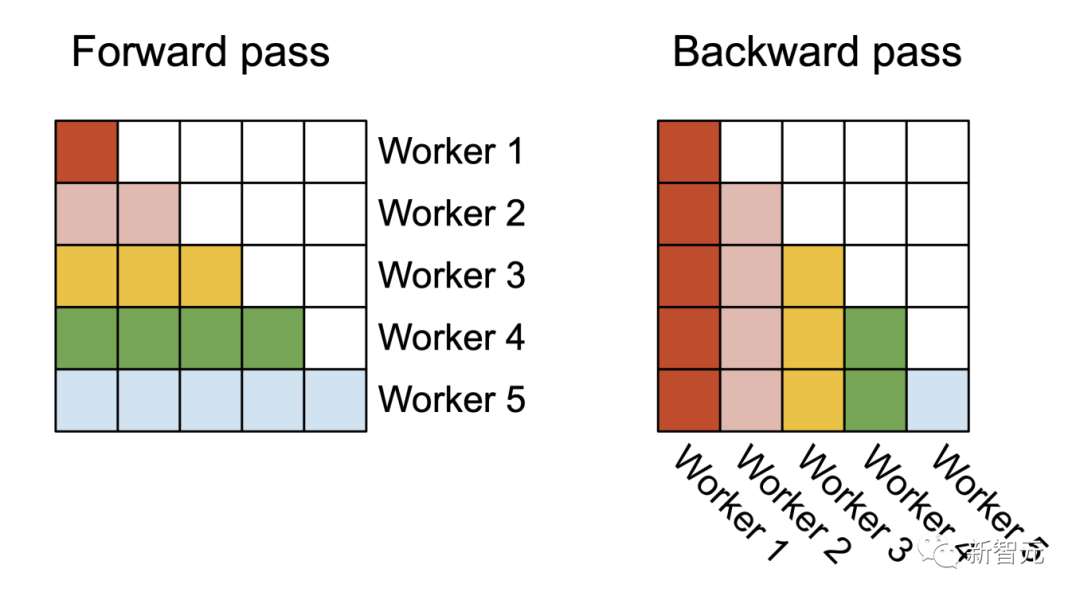
每个线程块都在流式多处理器 (SM)运行,例如,A100 GPU上有108个这样的处理器。当这个数字很大(比如 ≥80)时,这种调度是有效的,因为在这种情况下,可以有效地使用GPU上几乎所有的计算资源。在长序列的情况下(通常意味着更小批或更少的头),为了更好地利用GPU上的多处理器,研究人员在序列长度的维度上另外进行了并行化,使得该机制获得了显著加速。
更好的工作分区
即使在每个线程块内,研究人员也必须决定如何在不同的warp(线程束)之间划分工作(一组32个线程一起工作)。研究人员通常在每个线程块使用4或8个warp,分区方案如下图所示。研究人员在FlashAttention-2中改进了这种分区,减少了不同warp之间的同步和通信量,从而减少共享内存读/写。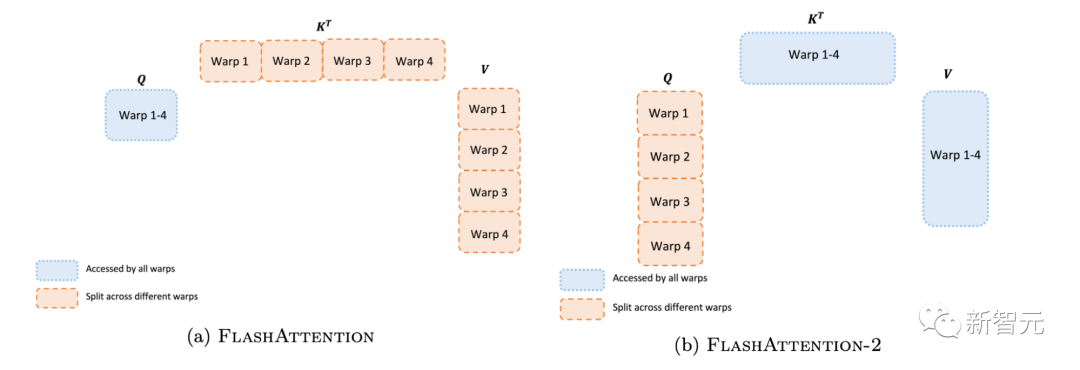 对于每个块,FlashAttention将K和V分割到4个warp上,同时保持Q可被所有warp访问。这称为「sliced-K」方案。然而,这样做的效率并不高,因为所有warp都需要将其中间结果写入共享内存,进行同步,然后再将中间结果相加。而这些共享内存读/写会减慢FlashAttention中的前向传播速度。在FlashAttention-2中,研究人员将Q拆分为4个warp,同时保持所有warp都可以访问K和V。在每个warp执行矩阵乘法得到Q K^T的一个切片后,它们只需与共享的V切片相乘,即可得到相应的输出切片。这样一来,warp之间就不再需要通信。共享内存读写的减少就可以提高速度。
对于每个块,FlashAttention将K和V分割到4个warp上,同时保持Q可被所有warp访问。这称为「sliced-K」方案。然而,这样做的效率并不高,因为所有warp都需要将其中间结果写入共享内存,进行同步,然后再将中间结果相加。而这些共享内存读/写会减慢FlashAttention中的前向传播速度。在FlashAttention-2中,研究人员将Q拆分为4个warp,同时保持所有warp都可以访问K和V。在每个warp执行矩阵乘法得到Q K^T的一个切片后,它们只需与共享的V切片相乘,即可得到相应的输出切片。这样一来,warp之间就不再需要通信。共享内存读写的减少就可以提高速度。
 新功能:头的维度高达256,多查询注意力
新功能:头的维度高达256,多查询注意力FlashAttention仅支持最大128的头的维度,虽说适用于大多数模型,但还是有一些模型被排除在外。FlashAttention-2现在支持256的头的维度,这意味着GPT-J、CodeGen、CodeGen2以及Stable Diffusion 1.x等模型都可以使用FlashAttention-2来获得加速和节省内存。v2还支持多查询注意力(MQA)以及分组查询注意力(GQA)。
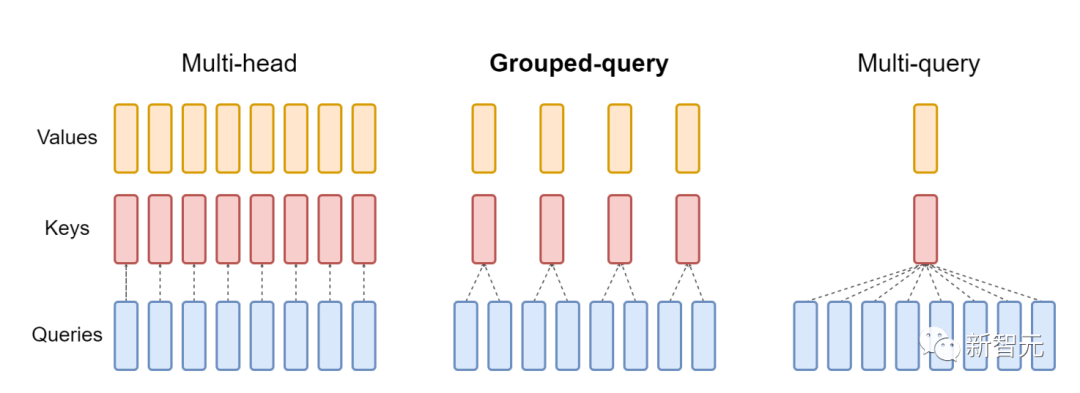
▲GQA为每组查询头共享单个key和value的头,在多头和多查询注意之间进行插值
这些都是注意力的变体,其中多个查询头会指向key和value的同一个头,以减少推理过程中KV缓存的大小,并可以显著提高推理的吞吐量。

注意力基准
研究人员人员在A100 80GB SXM4 GPU 上测量不同设置(有无因果掩码、头的维度是64或128)下不同注意力方法的运行时间。
 研究人员发现FlashAttention-2比第一代快大约2倍(包括在xformers库和Triton中的其他实现)。与PyTorch中的标准注意力实现相比,FlashAttention-2的速度最高可达其9倍。
研究人员发现FlashAttention-2比第一代快大约2倍(包括在xformers库和Triton中的其他实现)。与PyTorch中的标准注意力实现相比,FlashAttention-2的速度最高可达其9倍。
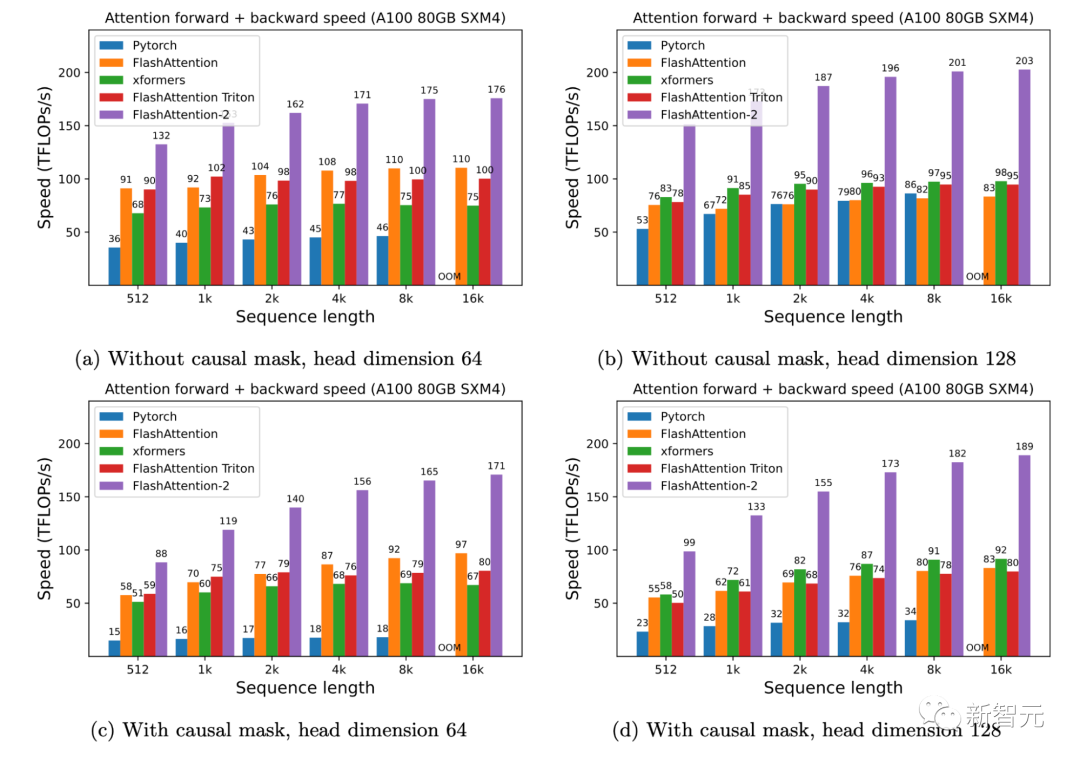
▲A100 GPU上的前向+后向速度
只需在H100 GPU上运行相同的实现(不需要使用特殊指令来利用TMA和第四代Tensor Core等新硬件功能),研究人员就可以获得高达335 TFLOPs/s的速度。
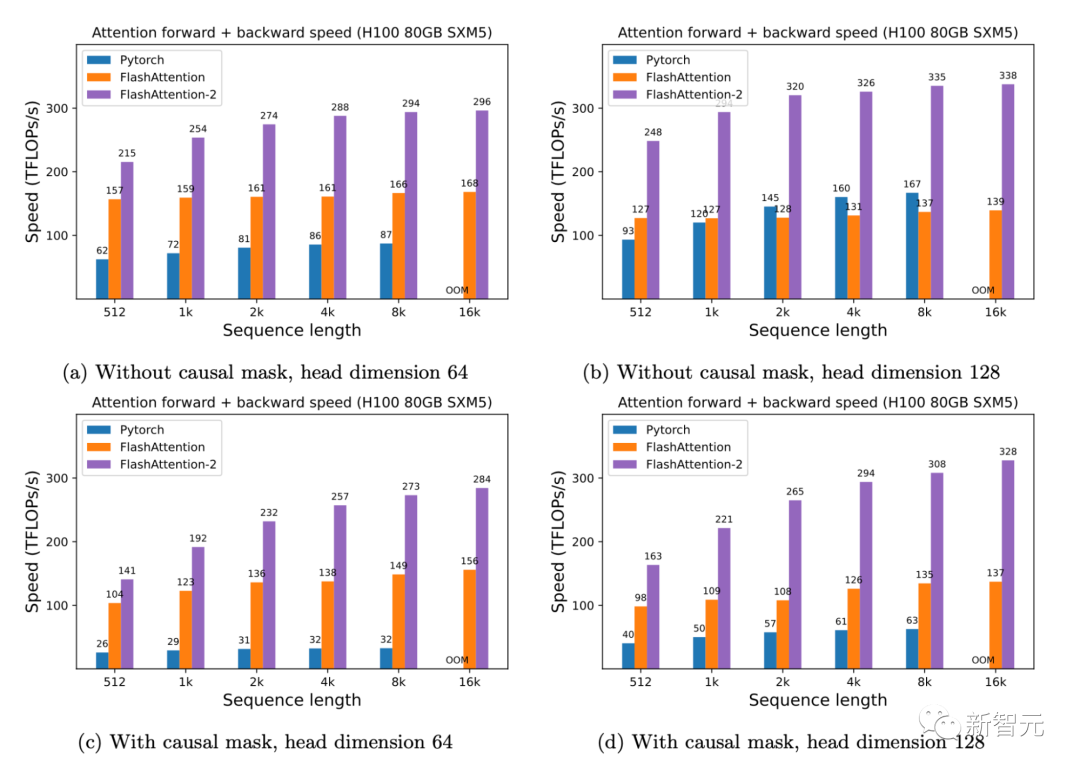
▲H100 GPU上的前向+后向速度
当用于端到端训练GPT类模型时,FlashAttention-2能在A100 GPU上实现高达225TFLOPs/s的速度(模型FLOPs利用率为72%)。与已经非常优化的FlashAttention模型相比,端到端的加速进一步提高了1.3倍。


未来的工作
速度上快2倍,意味着研究人员可以用与之前训练8k上下文模型相同的成本,来训练16k上下文长度的模型。这些模型可以理解长篇书籍和报告、高分辨率图像、音频和视频。同时,FlashAttention-2还将加速现有模型的训练、微调和推理。在不久的将来,研究人员还计划扩大合作,使FlashAttention广泛适用于不同类型的设备(例如H100 GPU、AMD GPU)以及新的数据类型(例如fp8)。下一步,研究人员计划针对H100 GPU进一步优化FlashAttention-2,以使用新的硬件功能(TMA、第四代Tensor Core、fp8等等)。将FlashAttention-2中的低级优化与高级算法更改(例如局部、扩张、块稀疏注意力)相结合,可以让研究人员用更长的上下文来训练AI模型。研究人员也很高兴与编译器研究人员合作,使这些优化技术更好地应用于编程。
 作者介绍
作者介绍Tri Dao曾在斯坦福大学获得了计算机博士学位,导师是Christopher Ré和Stefano Ermon。根据主页介绍,他将从2024年9月开始,任职普林斯顿大学计算机科学助理教授。
Tri Dao的研究兴趣在于机器学习和系统,重点关注高效训练和长期环境:- 高效Transformer训练和推理 - 远程记忆的序列模型 - 紧凑型深度学习模型的结构化稀疏性。
值得一提的是,Tri Dao今天正式成为生成式AI初创公司Together AI的首席科学家。

原文标题:让Attention提速9倍!FlashAttention燃爆显存,Transformer上下文长度史诗级提升
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
物联网
+关注
关注
2909文章
44605浏览量
373045
原文标题:让Attention提速9倍!FlashAttention燃爆显存,Transformer上下文长度史诗级提升
文章出处:【微信号:tyutcsplab,微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
《具身智能机器人系统》第7-9章阅读心得之具身智能机器人与大模型
学习任务、上下文长度、记忆和隐藏状态提高适应性。
任务适应
依赖数据采集和微调,可能效率较低。
利用复杂指令并自动从多样的上下文中学习。
预训练阶段
专注于世界知识和理解硬件。
强调在各种任务上学
发表于 12-24 15:03
阿里通义千问发布Qwen2.5-Turbo开源AI模型
近日,阿里通义千问官方宣布,经过数月的精心优化与改进,正式推出了Qwen2.5-Turbo开源AI模型。这款新模型旨在满足社区对更长上下文长度的迫切需求,为用户带来更加便捷、高效的AI
SystemView上下文统计窗口识别阻塞原因
SystemView工具可以记录嵌入式系统的运行时行为,实现可视化的深入分析。在新发布的v3.54版本中,增加了一项新功能:上下文统计窗口,提供了对任务运行时统计信息的深入分析,使用户能够彻底检查每个任务,帮助开发人员识别阻塞原因。
鸿蒙Ability Kit(程序框架服务)【应用上下文Context】
[Context]是应用中对象的上下文,其提供了应用的一些基础信息,例如resourceManager(资源管理)、applicationInfo(当前应用信息)、dir(应用文件路径)、area
编写一个任务调度程序,在上下文切换后遇到了一些问题求解
大家好,
我正在编写一个任务调度程序,在上下文切换后遇到了一些问题。
为下一个任务恢复上下文后:
__builtin_tricore_mtcr_by_name(\"pcxi\"
发表于 05-22 07:50
MiniMax推出“海螺AI”,支持超长文本处理
近日,大模型公司MiniMax宣布,其全新产品“海螺AI”已正式上架。这款强大的AI工具支持高达200ktokens的上下文长度,能够在1秒内处理近3万字的文本。
OpenAI发布GPT-4o模型,支持文本、图像、音频信息,速度提升一倍,价格不变
此外,该模型还具备128K的上下文记忆能力,知识截止日期设定为2023年10月。微软方面也宣布,已通过Azure OpenAI服务提供GPT-4o的预览版。
微信大模型扩容并开源,推出首个中英双语文生图模型,参数规模达15亿
基于Diffusion Transformer的混元DiT是一种文本到图像生成模块,具备中英细粒度理解能力,能与用户进行多轮对话,根据上下文生成并完善图像。
【大语言模型:原理与工程实践】大语言模型的基础技术
Transformer有效避免了CNN中的梯度消失和梯度爆炸问题,同时提高了处理长文本序列的效率。此外,模型编码器可以运用更多层,以捕获输入序列中元素间的深层关系,并学习更全面的上下文向量表示。
预训练语言模型
发表于 05-05 12:17
关于嵌入式C语言的弱符号和弱引用解析
总之,__attribute__ 起到了给编译器提供上下文的作用,如果错误的使用 __attribute__ 指令,因为给编译器提供了错误的上下文,由此引起的错误通常很难被发现。
发表于 05-03 10:48
•233次阅读
TC397收到EVAL_6EDL7141_TRAP_1SH 3上下文管理EVAL_6EDL7141_TRAP_1SH错误怎么解决?
我收到EVAL_6EDL7141_TRAP_1SH 3 类(TIN4-Free 上下文列表下溢)上下文管理EVAL_6EDL7141_TRAP_1SH错误。 请告诉我解决这个问题的办法。
发表于 03-06 08:00
OpenAI一键调用GPTs功能上线
OpenAI近日宣布,其最新功能GPT Mentions现已上线。这一功能为用户提供了一个便捷的方式来调用不同的GPTs(Generative Pre-trained Transformer),并支持不同GPT之间共享上下文内容。
ISR的上下文保存和恢复是如何完成的?
函数:ifxCPU_enableInterrupts ();如果我让更高优先级的 ISR 中断优先级较低的 ISR,那么 ISR 的上下文保存和恢复是如何完成的?
发表于 01-22 06:28
如何利用位置编码实现长度外推?
无论是缩放位置索引还是修改基地,所有token都变得彼此更接近,这将损害LLM区分相近token的位置顺序的能力。结合他们对RoPE的波长的观察,存在一些波长比预训练的上下文窗口长的维度,NTK-by-parts插值的作者建议完全不插值较高的频率维度。
发表于 01-08 09:58
•467次阅读






 工商网监
工商网监
评论