 图像识别技术原理 图像识别算法有哪些
图像识别技术原理 图像识别算法有哪些
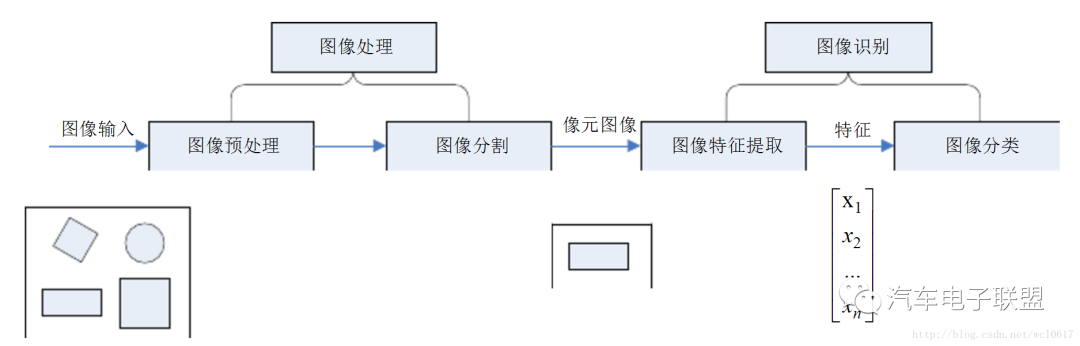
图像识别过程分为图像处理和图像识别两个部分。
01
图像处理
图像处理(imageProcessing)利用计算机对图像进行分析,以达到所需的结果。
图像处理可分为模拟图像处理和数字图像处理,而图像处理一般指数字图像处理。
这种处理大多数是依赖于软件实现的。
其目的是去除干扰、噪声,将原始图像编程适于计算机进行特征提取的形式,主要包括图像采样、图像增强、图像复原、图像编码与压缩和图像分割。
1)图像采集
图像采集是数字图像数据提取的主要方式。数字图像主要借助于数字摄像机、扫描仪、数码相机等设备经过采样数字化得到的图像,也包括一些动态图像,并可以将其转为数字图像,和文字、图形、声音一起存储在计算机内,显示在计算机的屏幕上。图像的提取是将一个图像变换为适合计算机处理的形式的第一步。
2)图像增强
图像在成像、采集、传输、复制等过程中图像的质量或多或少会造成一定的退化,数字化后的图像视觉效果不是十分满意。为了突出图像中感兴趣的部分,使图像的主体结构更加明确,必须对图像进行改善,即图像增强。通过图像增强,以减少图像中的图像的噪声,改变原来图像的亮度、色彩分布、对比度等参数。图像增强提高了图像的清晰度、图像的质量,使图像中的物体的轮廓更加清晰,细节更加明显。图像增强不考虑图像降质的原因,增强后的图像更加赏欣悦目,为后期的图像分析和图像理解奠定基础。
3)图像复原
图像复原也称图像恢复,由于在获取图像时环境噪声的影响、运动造成的图像模糊、光线的强弱等原因使得图像模糊,为了提取比较清晰的图像需要对图像进行恢复,图像恢复主要采用滤波方法,从降质的图像恢复原始图。图像复原的另一种特殊技术是图像重建,该技术是从物体横剖面的一组投影数据建立图像。
4)图像编码与压缩
数字图像的显著特点是数据量庞大,需要占用相当大的存储空间。但基于计算机的网络带宽和的大容量存储器无法进行数据图像的处理、存储、传输。为了能快速方便地在网络环境下传输图像或视频,那么必须对图像进行编码和压缩。目前,图像压缩编码已形成国际标准,如比较著名的静态图像压缩标准JPEG,该标准主要针对图像的分辨率、彩色图像和灰度图像,适用于网络传输的数码相片、彩色照片等方面。由于视频可以被看作是一幅幅不同的但有紧密相关的静态图像的时间序列,因此动态视频的单帧图像压缩可以应用静态图像的压缩标准。图像编码压缩技术可以减少图像的冗余数据量和存储器容量、提高图像传输速度、缩短处理时间。
5)图像分割技术
图像分割是把图像分成一些互不重叠而又具有各自特征的子区域,每一区域是像素的一个连续集,这里的特性可以是图像的颜色、形状、灰度和纹理等。图像分割根据目标与背景的先验知识将图像表示为物理上有意义的连通区域的集合。即对图像中的目标、背景进行标记、定位,然后把目标从背景中分离出来。目前,图像分割的方法主要有基于区域特征的分割方法、基于相关匹配的分割方法和基于边界特征的分割方法。由于采集图像时会受到各种条件的影响会是图像变的模糊、噪声干扰,使得图像分割是会遇到困难。在实际的图像中需根据景物条件的不同选择适合的图像分割方法。图像分割为进一步的图像识别、分析和理解奠定了基础。
02
图像识别
图像识别将图像处理得到的图像进行特征提取和分类。识别方法中基本的也是常用的方法有统计法(或决策理论法)、句法(或结构)方法、神经网络法、模板匹配法和几何变换法。
1)统计法(StatisticMethod)
该方法是对研究的图像进行大量的统计分析,找出其中的规律并提取反映图像本质特点的特征来进行图像识别的。它以数学上的决策理论为基础,建立统计学识别模型,因而是一种分类误差最小的方法。常用的图像统计模型有贝叶斯(Bayes)模型和马尔柯夫(Markow)随机场(MRF)模型。但是,较为常用的贝叶斯决策规则虽然从理论上解决了最优分类器的设计问题,其应用却在很大程度受到了更为困难的概率密度估计问题的限制。同时,正是因为统计方法基于严格的数学基础,而忽略了被识别图像的空间结构关系,当图像非常复杂、类别数很多时,将导致特征数量的激增,给特征提取造成困难,也使分类难以实现。尤其是当被识别图像(如指纹、染色体等)的主要特征是结构特征时,用统计法就很难进行识别。
2)句法识别法(Syntactic Recognition)
该方法是对统计识别方法的补充,在用统计法对图像进行识别时,图像的特征是用数值特征描述的,而句法方法则是用符号来描述图像特征的。它模仿了语言学中句法的层次结构,采用分层描述的方法,把复杂图像分解为单层或多层的相对简单的子图像,主要突出被识别对象的空间结构关系信息。模式识别源于统计方法,而句法方法则扩大了模式识别的能力,使其不仅能用于对图像的分类,而且可以用于对景物的分析与物体结构的识别。但是,当存在较大的干扰和噪声时,句法识别方法抽取子图像(基元)困难,容易产生误判率,难以满足分类识别精度和可靠度的要求。
3)神经网络方法(NeuralNetwork)
该方法是指用神经网络算法对图像进行识别的方法。神经网络系统是由大量的,同时也是很简单的处理单元(称为神经元),通过广泛地按照某种方式相互连接而形成的复杂网络系统,虽然每个神经元的结构和功能十分简单,但由大量的神经元构成的网络系统的行为却是丰富多彩和十分复杂的。它反映了人脑功能的许多基本特征,是人脑神经网络系统的简化、抽象和模拟。句法方法侧重于模拟人的逻辑思维,而神经网络侧重于模拟和实现人的认知过程中的感知觉过程、形象思维、分布式记忆和自学习自组织过程,与符号处理是一种互补的关系。由于神经网络具有非线性映射逼近、大规模并行分布式存储和综合优化处理、容错性强、独特的联想记忆及自组织、自适应和自学习能力,因而特别适合处理需要同时考虑许多因素和条件的问题以及信息不确定性(模糊或不精确)问题。在实际应用中,由于神经网络法存在收敛速度慢、训练量大、训练时间长,且存在局部最小,识别分类精度不够,难以适用于经常出现新模式的场合,因而其实用性有待进一步提高。
4)模板匹配法(TemplateMatching)
它是一种最基本的图像识别方法。所谓模板是为了检测待识别图像的某些区域特征而设计的阵列,它既可以是数字量,也可以是符号串等,因此可以把它看为统计法或句法的一种特例。所谓模板匹配法就是把已知物体的模板与图像中所有未知物体进行比较,如果某一未知物体与该模板匹配,则该物体被检测出来,并被认为是与模板相同的物体。模板匹配法虽然简单方便,但其应用有一定的限制。因为要表明所有物体的各种方向及尺寸,就需要较大数量的模板,且其匹配过程由于需要的存储量和计算量过大而不经济。同时,该方法的识别率过多地依赖于已知物体的模板,如果已知物体的模板产生变形,会导致错误的识别。此外,由于图像存在噪声以及被检测物体形状和结构方面的不确定性,模板匹配法在较复杂的情况下往往得不到理想的效果,难以绝对精确,一般都要在图像的每一点上求模板与图像之间的匹配量度,凡是匹配量度达到某一阈值的地方,表示该图像中存在所要检测的物体。经典的图像匹配方法利用互相关计算匹配量度,或用绝对差的平方和作为不匹配量度,但是这两种方法经常发生不匹配的情况,因此,利用几何变换的匹配方法有助于提高稳健性。
5)典型的几何变换方法主要有霍夫变换HT (Hough Transform)。
霍夫变换是一种快速形状匹配技术,它对图像进行某种形式的变换,把图像中给定形状曲线上的所有点变换到霍夫空间,而形成峰点,这样,给定形状的曲线检测问题就变换为霍夫空间中峰点的检测问题,可以用于有缺损形状的检测,是一种鲁棒性(Robust)很强的方法。为了减少计算量和和内存空间以提高计算效率,又提出了改进的霍夫算法,如快速霍夫变换(FHT)、自适应霍夫变换(AHT)及随机霍夫变换(RHT)。其中随机霍夫变换RHT(RandomizedHough Transform)是20世纪90年代提出的一种精巧的变换算法,其突出特点不仅能有效地减少计算量和内存容量,提高计算效率,而且能在有限的变换空间获得任意高的分辨率。
-
编码器
+关注
关注
45文章
3709浏览量
135790 -
存储器
+关注
关注
38文章
7557浏览量
164956 -
神经网络
+关注
关注
42文章
4789浏览量
101616 -
变换器
+关注
关注
17文章
2112浏览量
109855 -
图像处理器
+关注
关注
1文章
104浏览量
15642
发布评论请先 登录
相关推荐
基于DSP的快速纸币图像识别技术研究
基于DSP的快速纸币图像识别技术研究






 工商网监
工商网监
评论