 Disruptor高性能队列的原理
Disruptor高性能队列的原理
来源:www.qin.news/disruptor/
介绍
Disruptor 是英国外汇交易公司 LMAX 开发的一个高性能队列,研发的初衷是解决内存队列的延迟问题(在性能测试中发现竟然与 I/O 操作处于同样的数量级)。基于Disruptor 开发的系统单线程能支撑每秒 600 万订单,2010 年在 QCon 演讲后,获得了业界关注。2011 年,企业应用软件专家 Martin Fowler 专门撰写长文介绍。同年它还获得了 Oracle 官方的 Duke 大奖。
这里所说的队列是系统内部的内存队列,而不是Kafka这样的分布式队列。
许多应用程序依靠队列在处理阶段之间交换数据。我们的性能测试表明,当以这种方式使用队列时,其延迟成本与磁盘(基于RAID或SSD的磁盘系统)的IO操作成本处于同一数量级都很慢。如果在一个端到端的操作中有多个队列,这将使整个延迟增加数百微秒。
测试表明,使用 Disruptor 的三阶段流水线的平均延迟比基于队列的同等方法低 3 个数量级。此外,在相同的配置下,Disruptor 处理的吞吐量约为 8 倍。
并发问题
在本文以及在一般的计算机科学理论中,并发不仅意味着两个以上任务同时并行发生,而且意味着它们在访问资源时相互竞争。争用的资源可以是数据库、文件、socket,甚至是内存中的一个位置。
代码的并发执行涉及两件事:互斥和内存可见性。互斥是关于如何管理保证某些资源的独占式使用。内存可见性是关于控制内存更改何时对其他线程可见。如果你可以避免多线程竞争的去更新共享资源,那么就可以避免互斥。如果您的算法可以保证任何给定的资源只被一个线程修改,那么互斥是不必要的。读写操作要求所有更改对其他线程可见。但是,只有争用的写操作需要对更改进行互斥。
在任何并发环境中,最昂贵的操作是争用写访问。要让多个线程写入同一资源,需要复杂而昂贵的协调。通常,这是通过采用某种锁策略来实现的。
但是锁的开销是非常大的,在论文中设计了一个实验:
这个测试程序调用了一个函数,该函数会对一个 64 位的计数器循环自增 5 亿次。
机器环境:2.4G 6 核
运算:64 位的计数器累加 5 亿次
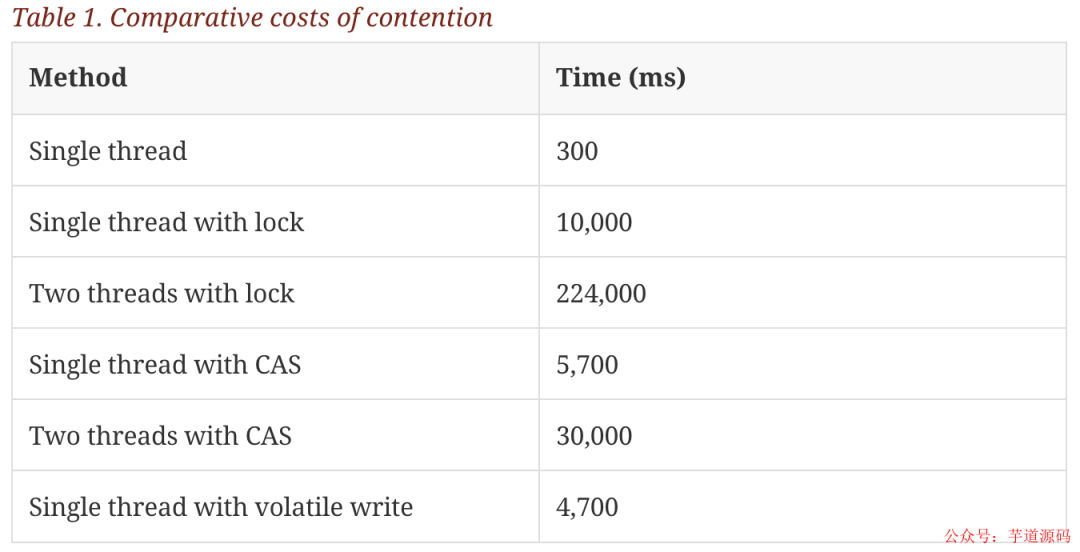
单线程情况下,不加锁的性能 > CAS 操作的性能 > 加锁的性能。
在多线程情况下,为了保证线程安全,必须使用 CAS 或锁,这种情况下,CAS 的性能超过锁的性能,前者大约是后者的 8 倍。
保证线程安全一般使用锁或者原子变量。
采取加锁的方式,默认线程会冲突,访问数据时,先加上锁再访问,访问之后再解锁。通过锁界定一个临界区,同时只有一个线程进入。
原子变量能够保证原子性的操作,意思是某个任务在执行过程中,要么全部成功,要么全部失败回滚,恢复到执行之前的初态,不存在初态和成功之间的中间状态。例如 CAS 操作,要么比较并交换成功,要么比较并交换失败。由 CPU 保证原子性。
通过原子变量可以实现线程安全。执行某个任务的时候,先假定不会有冲突,若不发生冲突,则直接执行成功;当发生冲突的时候,则执行失败,回滚再重新操作,直到不发生冲突。
CAS 操作是一种特殊的机器代码指令,它允许将内存中的字有条件地设置为原子操作。比如对于前面的“递增计数器实验”例子,每个线程都可以在一个循环中自旋,读取计数器,然后尝试以原子方式将其设置为新的递增值。
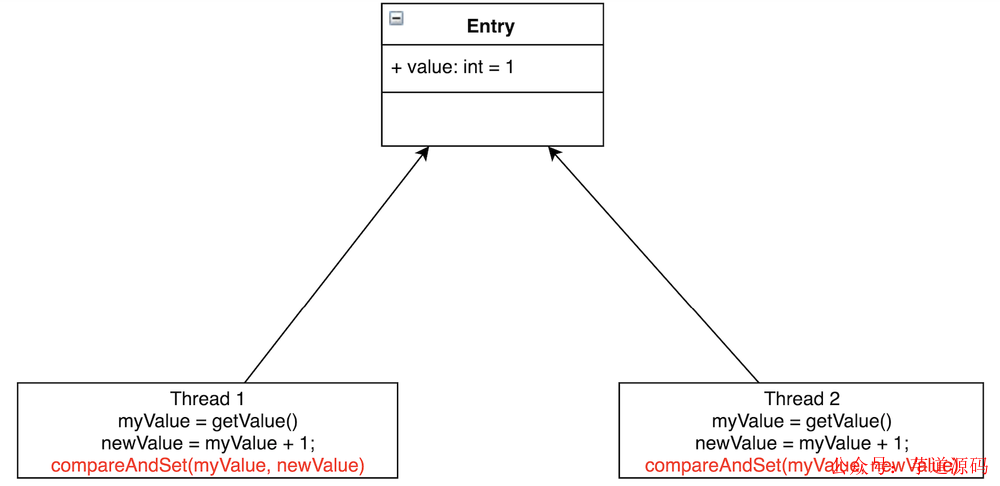
如图所示,Thread1 和 Thread2 都要把 Entry 加 1。若不加锁,也不使用 CAS,有可能 Thread1 取到了myValue=1,Thread2 也取到了 myValue=1,然后相加,Entry 中的 value 值为 2。这与预期不相符,我们预期的是 Entry 的值经过两次相加后等于3。
CAS 会先把 Entry 现在的 value 跟线程当初读出的值相比较,若相同,则赋值;若不相同,则赋值执行失败。一般会通过 while/for 循环来重新执行,直到赋值成功。CAS无需线程进行上下文切换到内核态去执行,在用户态执行了 CPU 的原语指令 cmpxchg,CAS 相当于在用户态代码里边插入了一个 cmpxchg 指令,这样 CPU 一直在用户态执行,执行到 cmpxchg 指令就开始执行内核态内存空间的操作系统的代码。执行指令要比上下文切换的开销要小,所以 CAS 要比重量级互斥锁性能要高。(用户态和内核态没有切换)
如果程序的关键部分比计数器的简单增量更复杂,则可能需要使用多个CAS操作的复杂状态机来编排争用。使用锁开发并发程序是困难的;而使用 CAS 操作和内存屏障开发无锁算法要更加复杂多倍,而且难于测试和证明正确性。
内存屏障和缓存问题
出于提升性能的原因,现代处理器执行指令、以及内存和执行单元之间数据的加载和存储都是不保证顺序的。不管实际的执行顺序如何,处理器只需保证与程序逻辑的顺序产生相同的结果即可。这在单线程的程序中不是一个问题。但是,当线程共享状态时,为了确保数据交换的成功与正确,在需要的时候、内存的改变能够以正确的顺序显式是非常重要的。处理器使用内存屏障来指示内存更新顺序很重要的代码部分。它们是在线程之间实现硬件排序和更改可见性的方法。
内存屏障(英语:Memory barrier),也称内存栅栏,内存栅障,屏障指令等,是一类同步屏障指令,它使得 CPU 或编译器在对内存进行操作的时候, 严格按照一定的顺序来执行, 也就是说在内存屏障之前的指令和之后的指令不会由于系统优化等原因而导致乱序。
大多数处理器提供了内存屏障指令:
完全内存屏障(full memory barrier)保障了早于屏障的内存读写操作的结果提交到内存之后,再执行晚于屏障的读写操作。
内存读屏障(read memory barrier)仅确保了内存读操作;
内存写屏障(write memory barrier)仅保证了内存写操作。
现代的 CPU 现在比当前一代的内存系统快得多。为了弥合这一鸿沟,CPU 使用复杂的高速缓存系统,这些系统是有效的快速硬件哈希表,无需链接。这些缓存通过消息传递协议与其他处理器缓存系统保持一致。此外,处理器还具有“存储缓冲区”(store buffer/load buffer,比 L1 缓存更靠近 CPU,跟寄存器同一个级别,用来当作 CPU 与高速缓存之间的缓冲。毕竟高速缓存由于一致性的问题也会阻塞)来缓冲对这些缓存的写入,以及作为“失效队列”,以便缓存一致性协议能够在即将发生写入时快速确认失效消息,以提高效率。
这对数据意味着,任何值的最新版本在被写入后的任何阶段都可以位于寄存器、存储缓冲区、L1/L2/L3 缓存之一或主内存中。如果线程要共享此值,则需要以有序的方式使其可见,这是通过协调缓存一致性消息的交换来实现的。这些信息的及时产生可以通过内存屏障来控制。
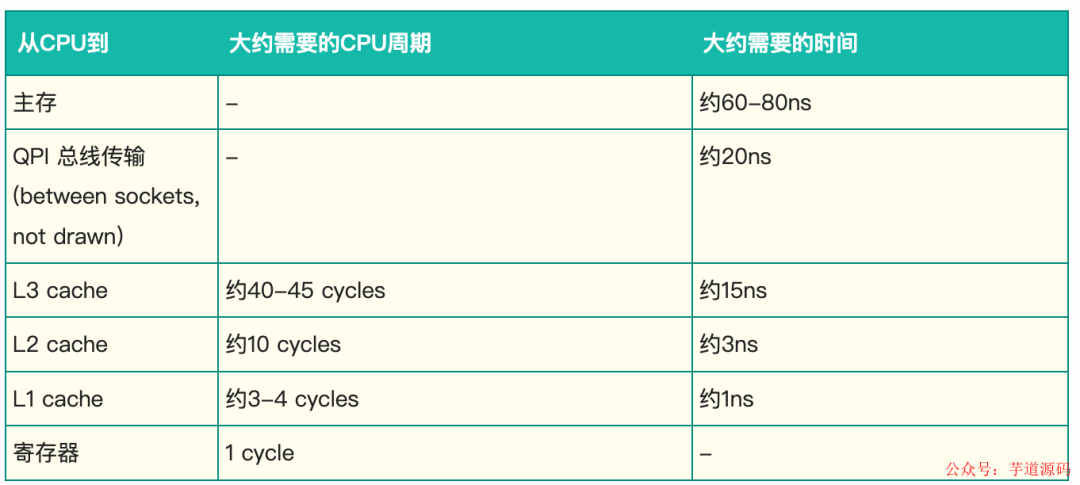
L1、L2、L3 分别表示一级缓存、二级缓存、三级缓存,越靠近 CPU 的缓存,速度越快,容量也越小。所以 L1 缓存很小但很快,并且紧靠着在使用它的 CPU 内核;L2 大一些,也慢一些,并且仍然只能被一个单独的 CPU 核使用;L3 更大、更慢,并且被单个插槽上的所有 CPU 核共享;最后是主存,由全部插槽上的所有 CPU 核共享。
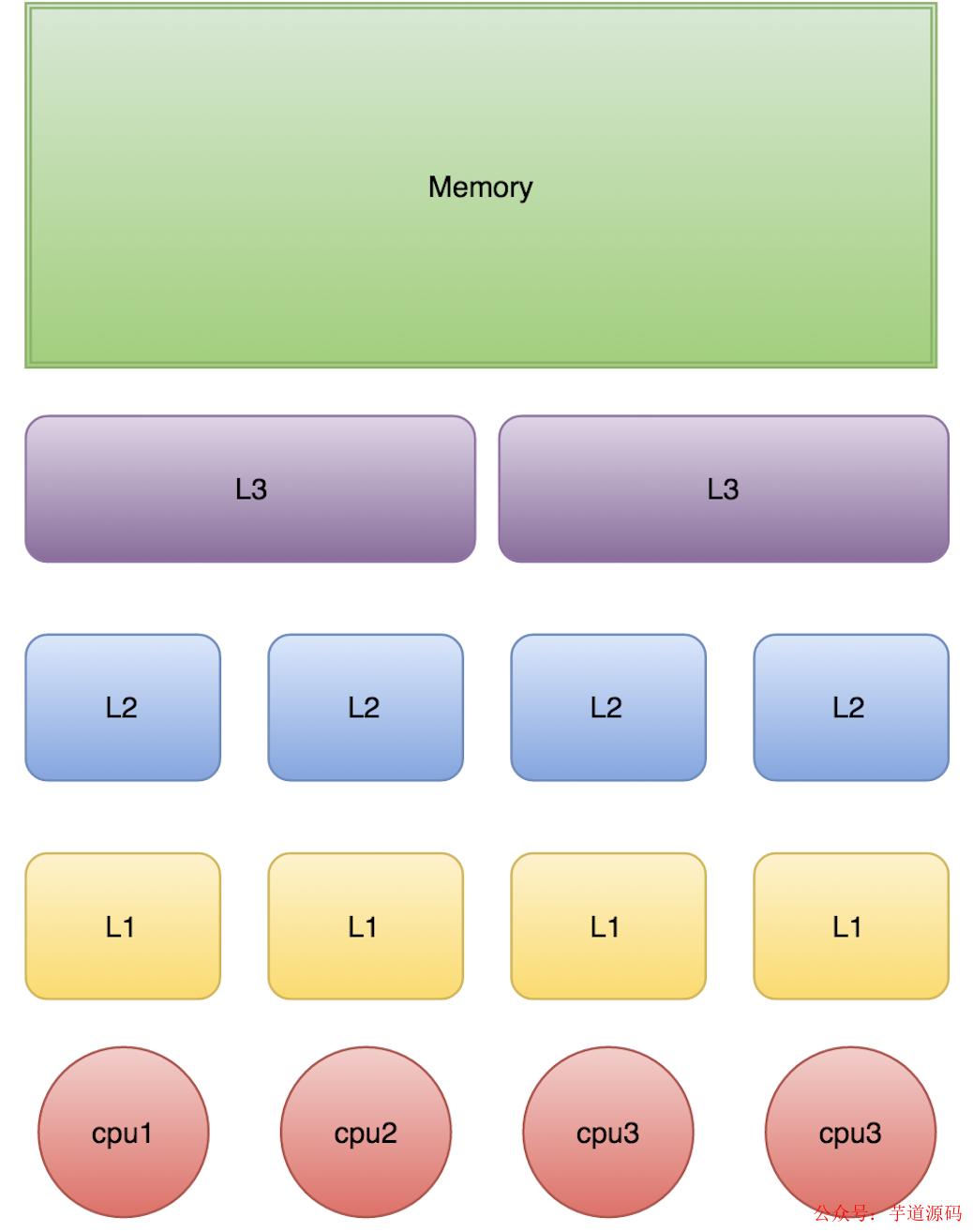
当 CPU 执行运算的时候,它先去 L1 查找所需的数据、再去 L2、然后是 L3,如果最后这些缓存中都没有,所需的数据就要去主内存拿。走得越远,运算耗费的时间就越长。所以如果你在做一些很频繁的事,你要尽量确保数据在 L1 缓存中。
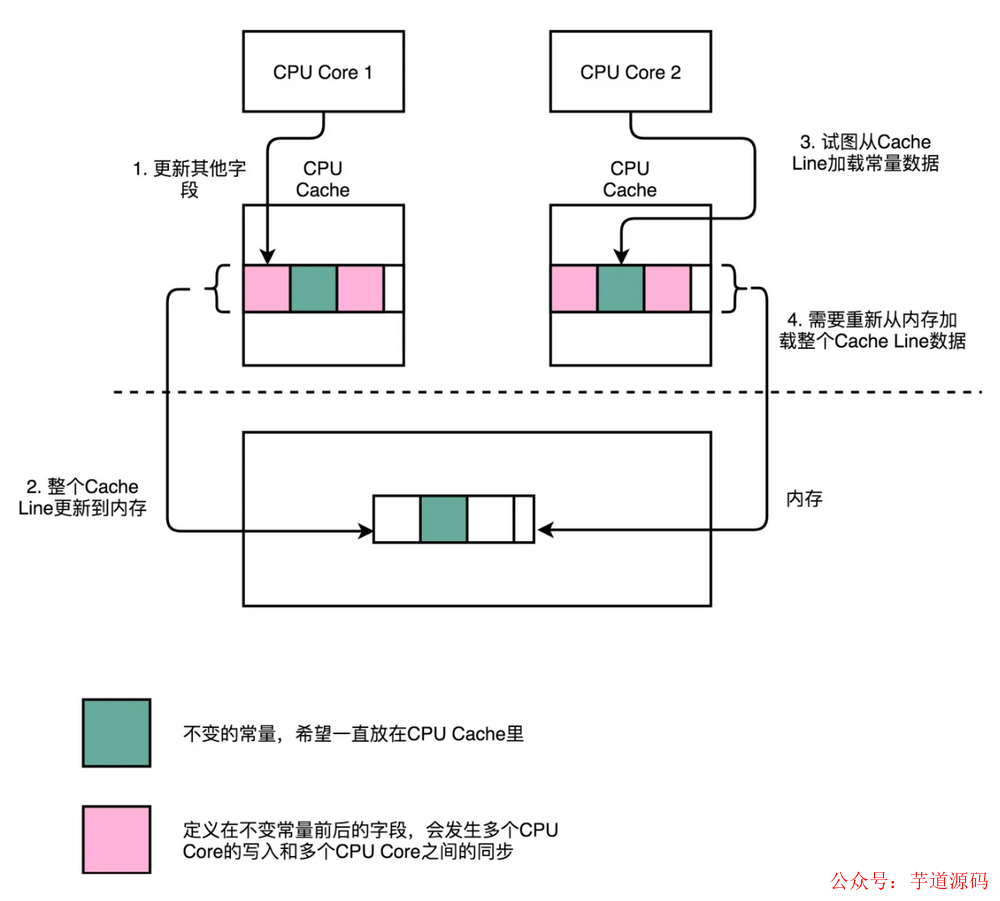
另外,线程之间共享一份数据的时候,需要一个线程把数据写回内存,而另一个线程访问内存中相应的数据。
如果你用一种能被预测的方式访问内存的话,CPU 可以预测下个可能访问的值从内存先缓存到缓存中,来降低下次访问的延迟。但是如果是一些非顺序的、步长无法预测的结构,让 CPU 只能访问内存,性能上与访问缓存差很多。所以为了有效利用 CPU 高速缓存的特性,我们应当尽量使用顺序存储结构。
队列的问题
队列通常使用链表或数组作为元素的底层存储。如果允许内存中的队列是无界的,那么对于许多类的问题,它可以不受约束地增长,直到耗尽内存而达到灾难性的后果,当生产者超过消费者时就会发生这种情况。无界队列在可以在生产者可以保证不超过消费者的系统中使用,因为内存是一种宝贵的资源,但是如果这种假设不成立,而队列增长没有限制,那么总是有风险的。为了避免这种灾难性的结果,队列的大小通常要受到限制(有界)。要使队列保持有界,就需要对其底层选择数组结构或主动跟踪其大小。
队列的实现往往要在 head、tail 和 size 变量上有写争用。在使用时,由于消费者和生产者之间的速度差异,队列通常总是接近于满或接近于空。它们很少在生产和消费速率均衡的中间地带运作。这种总是满的或总是空的倾向会导致高级别的争用、和/或昂贵的缓存一致性。问题在于,即使 head 和 tail 使用不同的并发对象(如锁或CAS变量)来进行读写锁分离,它们通常也占用相同的 cacheline。
管理生产者申请队列的 head,消费者申请队列的 tail,以及中间节点的存储,这些问题使得并发实现的设计非常复杂,除了在队列上使用一个粗粒度的锁之外,还难以管理。对于 put 和 take 操作,使用整个队列上的粗粒度锁实现起来很简单,但对吞吐量来说是一个很大的瓶颈。如果并发关注点在队列的语义中被分离开来,那么对于除单个生产者-单个消费者之外的任何场景,实现都变得非常复杂。
而使用相同的 cacheline 会产生伪共享问题。比如 ArrayBlockingQueue 有三个成员变量:
takeIndex:需要被取走的元素下标;
putIndex:可被元素插入的位置的下标;
count:队列中元素的数量;
这三个变量很容易放到一个缓存行中,但是之间修改没有太多的关联。所以每次修改,都会使之前缓存的数据失效,从而不能完全达到共享的效果。
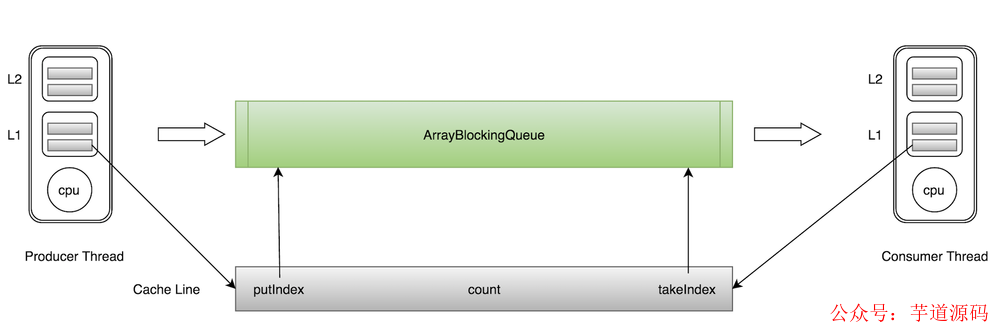
如上图所示,当生产者线程 put 一个元素到 ArrayBlockingQueue 时,putIndex 会修改,从而导致消费者线程的缓存中的缓存行无效,需要从主存中重新读取。一般的解决方案是,增大数组元素的间隔使得由不同线程存取的元素位于不同的缓存行上,以空间换时间。
Disruptor 解决思路
启动时,将预先分配环形缓冲区的所有内存。环形缓冲区可以存储指向 entry 的指针数组,也可以存储表示 entry 的结构数组。这些 entry 中的每一个通常不是传递的数据本身,类似对象池机制,而是它的容器。这种 entry 的预分配消除了支持垃圾回收的语言中的问题,因为 entry 将被重用,并在整个 Disruptor 实例存活期间都有效。这些 entry 的内存是同时分配的。
一般的数据结构是像下面这样的:
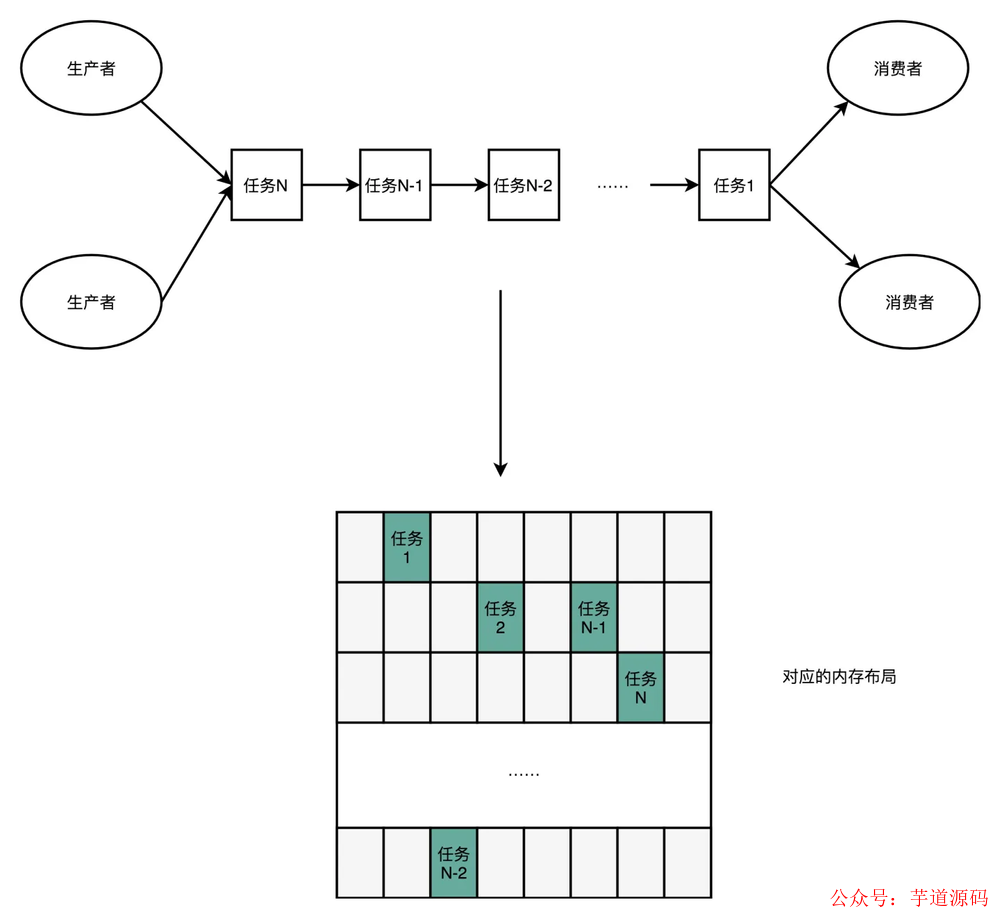
我们可以使用一个环状的数组结构改进成下面这样:
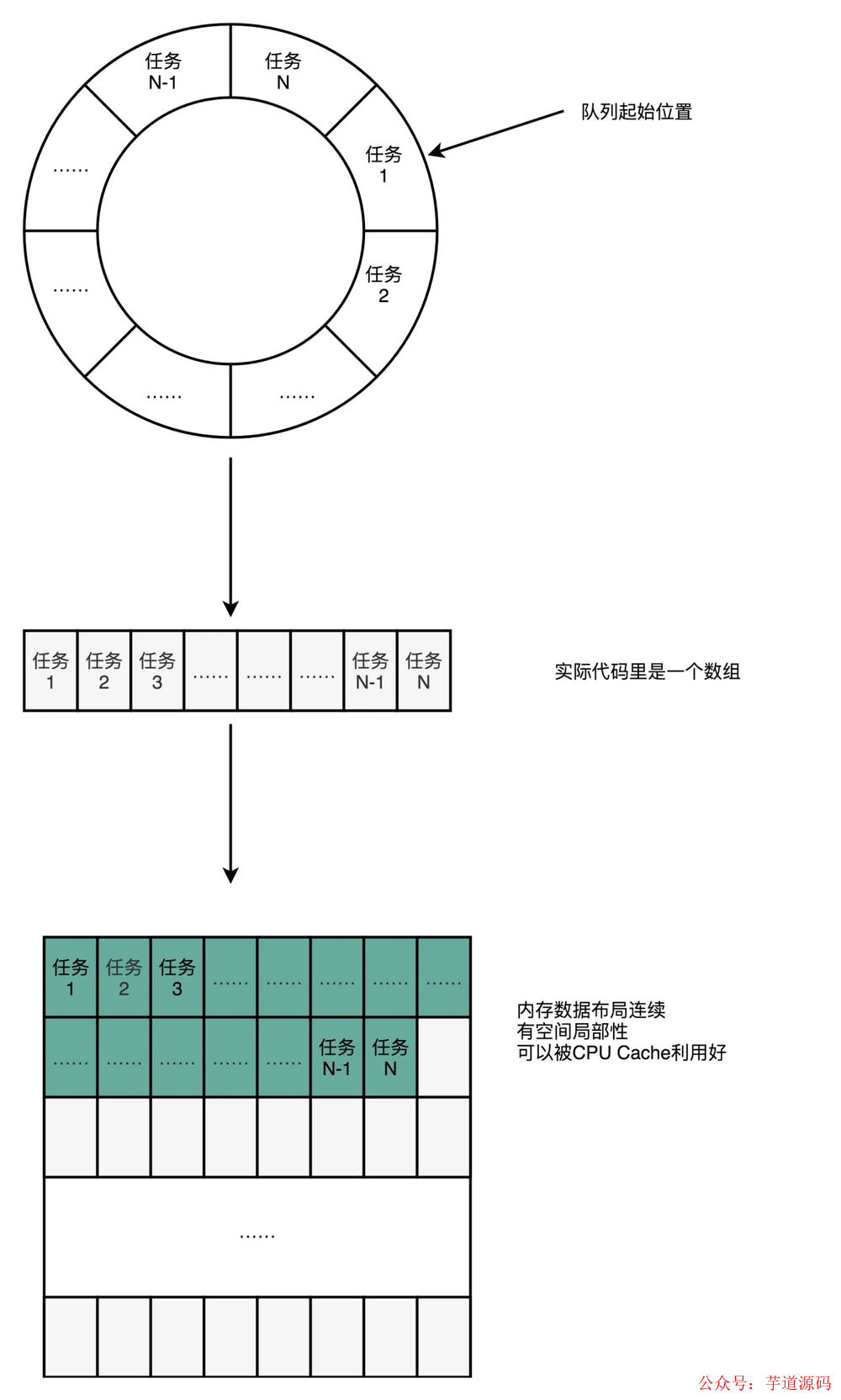
数组的连续多个元素会一并加载到 CPU Cache 里面来,所以访问遍历的速度会更快。而链表里面各个节点的数据,多半不会出现在相邻的内存空间,自然也就享受不到整个 Cache Line 加载后数据连续从高速缓存里面被访问到的优势。遍历访问时 CPU 层面的分支预测会很准确。这可以使得我们更有效地利用了 CPU 里面的多级流水线,我们的程序就会跑得更快。
在像 Java 这样的托管运行时环境中开发低延迟系统时,垃圾收集机制可能会带来问题。分配的内存越多,给垃圾收集器带来的负担就越大。当对象的寿命很短或实际上是常驻的时候,垃圾收集器工作得最好。在环形缓冲区中预先分配 entry 意味着它对于垃圾收集器来说是常驻内存的,垃圾回收的负担就很轻。同时,数组结构对处理器的缓存机制更加友好。数组长度 2^n,通过位运算,加快定位的速度。下标采取递增的形式。不用担心 index 溢出的问题。index 是 long 类型,即使 100 万 QPS 的处理速度,也需要 30 万年才能用完。
一般的 Cache Line 大小在 64 字节左右,然后 Disruptor 在非常重要的字段前后加了很多额外的无用字段。可以让这一个字段占满一整个缓存行,这样就可以避免未共享导致的误杀。
每个生产者或者消费者线程,会先申请可以操作的元素在数组中的位置,申请到之后,直接在该位置写入或者读取数据。
下面用非环形的结构模拟无锁读写。
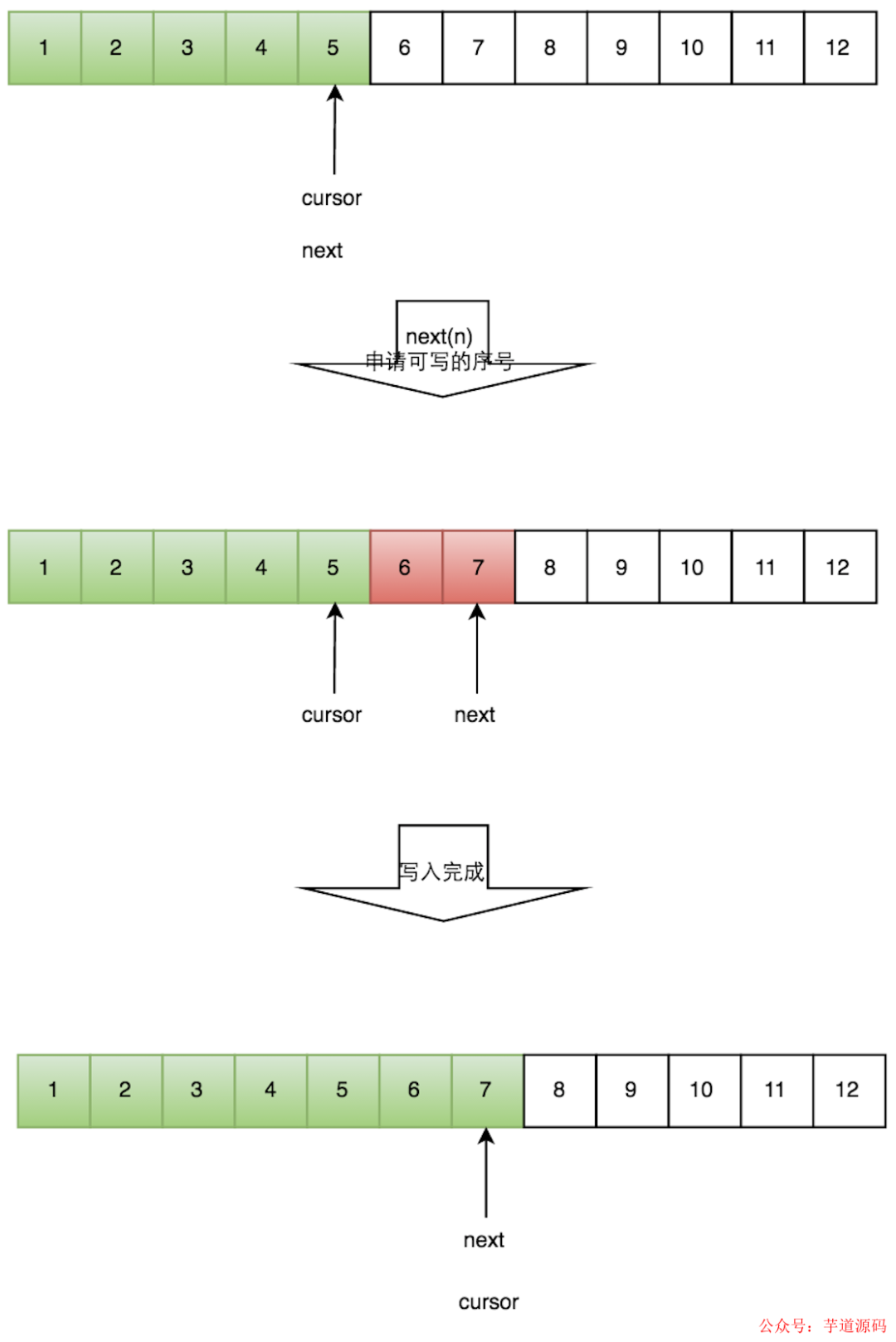
一个生产者的流程
申请写入m个元素;
若是有m个元素可以入,则返回最大的序列号。这儿主要判断是否会覆盖未读的元素;
若是返回的正确,则生产者开始写入元素。
多个生产者流程
多个生产者的情况下,会遇到“如何防止多个线程重复写同一个元素”的问题。Disruptor 的解决方法是,每个线程获取不同的一段数组空间进行操作。这个通过 CAS 很容易达到。只需要在分配元素的时候,通过 CAS 判断一下这段空间是否已经分配出去即可。
但如何防止读取的时候,读到还未写的元素。Disruptor 在多个生产者的情况下,引入了一个与 Ring Buffer 大小相同的 buffer,Available Buffer。当某个位置写入成功的时候,便把 Availble Buffer 相应的位置置位,标记为写入成功。读取的时候,会遍历 Available Buffer,来判断元素是否已经就绪。
读数据流程
生产者多线程写入的情况会复杂很多:
申请读取到序号n;
若 writer cursor >= n,这时仍然无法确定连续可读的最大下标。从 reader cursor 开始读取 available Buffer,一直查到第一个不可用的元素,然后返回最大连续可读元素的位置;
消费者读取元素。
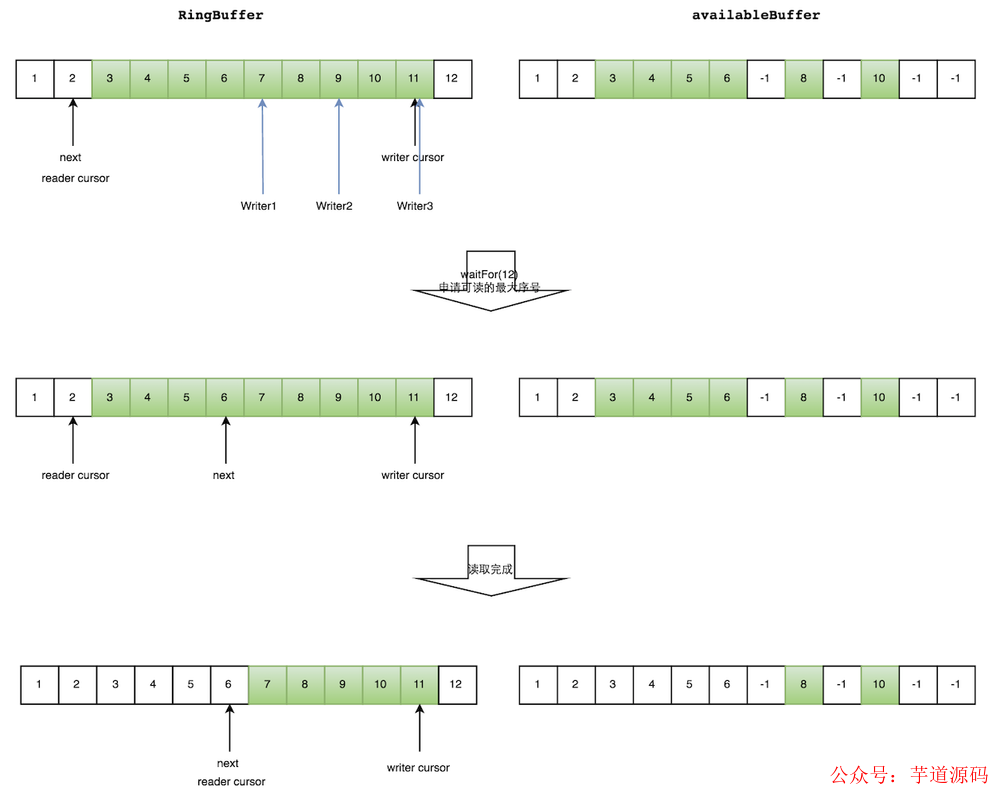
如下图所示,读线程读到下标为 2 的元素,三个线程 Writer1/Writer2/Writer3 正在向 RingBuffer 相应位置写数据,写线程被分配到的最大元素下标是 11。
读线程申请读取到下标从3到11的元素,判断 writer cursor>=11。然后开始读取 availableBuffer,从 3 开始,往后读取,发现下标为7的元素没有生产成功,于是WaitFor(11)返回6。
然后,消费者读取下标从 3 到 6 共计 4 个元素(多个生产者情况下,消费者消费过程示意图)。
写数据流程
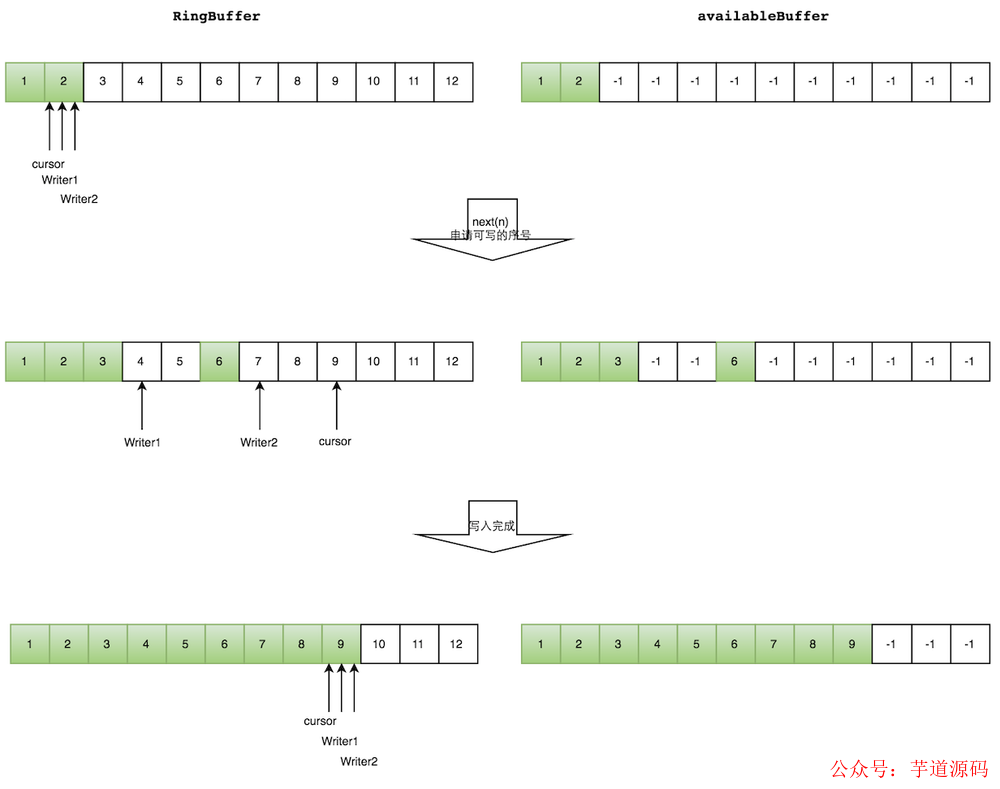
多个生产者写入的时候:
申请写入 m 个元素;
若是有 m 个元素可以写入,则返回最大的序列号。每个生产者会被分配一段独享的空间;
生产者写入元素,写入元素的同时设置 available Buffer 里面相应的位置,以标记自己哪些位置是已经写入成功的。
如下图所示,Writer1 和 Writer2 两个线程写入数组,都申请可写的数组空间。Writer1 被分配了下标 3 到下表 5 的空间,Writer2 被分配了下标 6 到下标 9 的空间。
Writer1 写入下标 3 位置的元素,同时把 available Buffer 相应位置置位,标记已经写入成功,往后移一位,开始写下标 4 位置的元素。Writer2 同样的方式。最终都写入完成。
总结
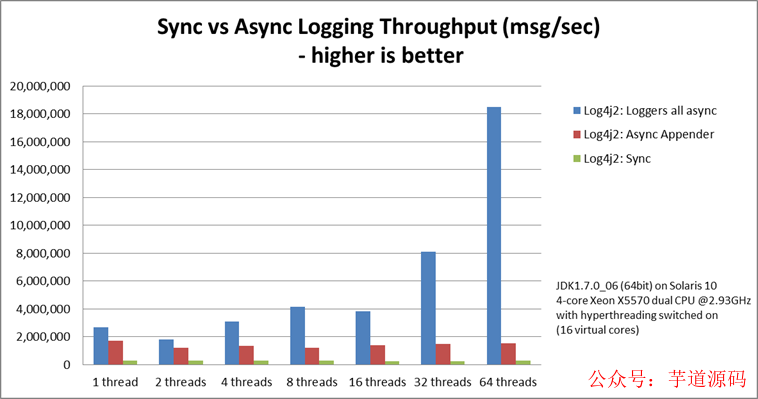
整体上来看 Disruptor 在提高吞吐量、减少并发执行损耗上做出了很大贡献,通过贴合硬件机制的方式进行设计,消除写争用,最小化读争用,并确保代码与现代处理器使用的 Cache 特性良好配合。我们可以看下 Log4j 2 的性能数据,Log4j 2 的 Loggers all async 就是基于 Disruptor 的。
总结来说 Disruptor 是性能极高的无锁队列,提供了一种很好的利用硬件特性实现尽可能从缓存读取来加速访问的无锁方案。
审核编辑:刘清
-
处理器
+关注
关注
68文章
19293浏览量
229918 -
计数器
+关注
关注
32文章
2256浏览量
94600 -
SSD
+关注
关注
21文章
2863浏览量
117450 -
RAID技术
+关注
关注
0文章
7浏览量
6226 -
CAS
+关注
关注
0文章
34浏览量
15210
原文标题:Disruptor 高性能队列原理浅析
文章出处:【微信号:芋道源码,微信公众号:芋道源码】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐









可扩展的高性能RISC-V 内核IP
解密方舟的高性能内存回收技术——HPP GC
消息总线和消息队列的区别是什么?






 工商网监
工商网监
评论