 大模型训练中RM分数越来越高,那训出来LLM的效果一定好吗?
大模型训练中RM分数越来越高,那训出来LLM的效果一定好吗?
之前在文章大模型面试八股中提到一个问题,大模型训练中RM分数越来越高,那训出来LLM的效果一定好吗?
这么肯定的判断肯定是有坑的,值得怀疑。
如果你动手跑几次ppo的过程就发现了,大模型的强化学习非常难以训练,难以训练不仅仅指的是费卡,还是指的非常容易训崩。
第一,费卡。假设你训llama 7b,SFT 和 RM 都用7B的模型,那么显存耗费 = 2*7B(TRIAN MODE) + *7B(EVAL MODE), 分别对应 policy model / critic model,还有ref model/reward model
本来你能用几张40GB A100的卡+deepspeed 做7b的全参数微调,强化学习就得升级到80GB的A100了,勉勉强强能跑到7B。想跑更大的就得充钱了。
第二,容易崩。LLM训着训着就不听你话了,要么变成停不下来的复读机,输出到后面没有逻辑直到maxlen,要么变成哑巴,直接一个eosid躺平。
RLHF中的问题其实在RL游戏训练里面很常见了,如果环境和参数设置不好的话,agent很容走极端,在 一头撞死or循环鬼畜之间反复横跳。
原始的ppo就是很难训,对SFT基模型和RM的训练数据以及采样prompt的数据要求很高,参数设置要求也很高。
自从openai带了一波RLHF的节奏后,大家都觉得强化学习在对齐方面的无敌功力,但自己跑似乎又不是那么回事,这玩意也太有讲究了吧。
更多的魔鬼在细节了,openai像拿了一个比赛的冠军,告诉你了成功的solution,结果没告诉你各个步骤的重要性和关键设置,更没有告诉你失败和无效的经验。
在讲trick之前,首先复旦-MOSS也对LLM的训练过程加了更多监测,其实这些都是实验中非常重要的监控过程指标,能很清楚的发现你模型是否出现异常。
然后这个图很好,非常清楚地讲述了trick是如何作用在RLHF中的各个阶段的,另外配套的开源代码实现也非常清晰易懂,典型的面条代码没有什么封装,一码到底,易读性和魔改都很方便。
下面我们看看这7个trick,对应图中右侧画星号的部分。
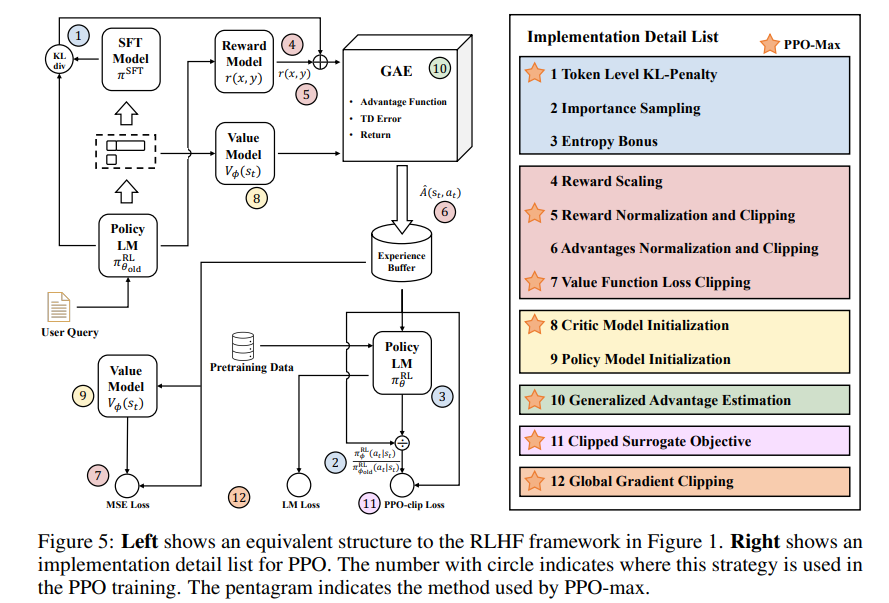
1, token级别的KL散度惩罚
kl_penalty = (-self.kl_penalty_weight * (logprobs - ref_logprobs)).cpu()
这一步主要解决的问题是训练稳定性,防止步子太大扯着蛋,如果你输出的和参考模型差别过大的话就减分。
2,Reward Normalization and Clipping
3,Value Function Loss Clipping
Clipping类似梯度裁剪,也是止步子太大扯着蛋,对一些异常的loss和reward做了限制,Normalization为了对reward做标准化。
这部分的代码可以对应开源中的这些设置仔细查看,原理大同小异
self.use_reward_clip: bool = opt.use_reward_clip self.use_reward_norm:bool=opt.use_reward_norm self.use_advantage_norm:bool=opt.use_advantage_norm self.use_advantage_clip: bool = opt.use_advantage_clip self.use_critic_loss_clip:bool=opt.use_critic_loss_clip self.use_policy_loss_clip:bool=opt.use_policy_loss_clip
4.Critic Model Initialization
用RM model初始化Critic可能不是一个必要的选择,作者做了一些实验证明这个问题,推荐使用critic model pre-training。代码里这部分还没有,还是使用rm初始化的,后续跟进一下这个问题。
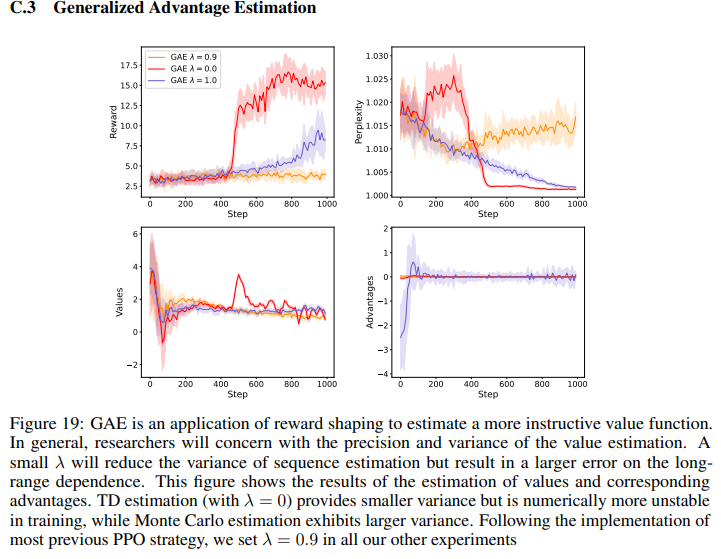
5. Generalized Advantage Estimation
附录里C.3有GAE的调参实验。
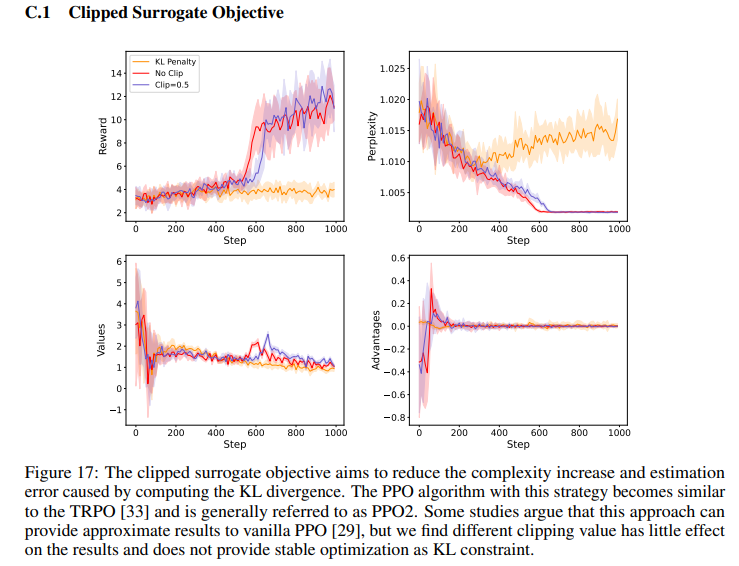
6.Clipped Surrogate Objective
这个也是一种正则化方法,防止步子太大扯着蛋,确保训练过程的中的稳定性,这个方法比一般policy gradient处理的更为高效。
7.Global Gradient Clipping

原理还是同上,所有的Clipping无非都是砍掉太大的步子。
另外作者还用了一个instruct gpt里面用到的方案,增加了训练过程使用 llm_pretrain_loss,参考代码
if self.use_entropy_loss:
loss1 = pg_loss + self.vf_loss_weight * vf_loss + self.entropy_loss_weight * entro_loss
else:
loss1 = pg_loss + self.vf_loss_weight * vf_loss
loss2 = self.ppo_pretrain_loss_weight * pretrain_loss
loss = loss1 + loss2
总结下,整体ppo-max的改进主要集中在训练过程的稳定性上,用的东西还是模型的老三样,训练过程裁剪,初始化,loss改进,主要集中在如何能让RLHF更好调,推荐参考作者的源码进行一些实验。
另外,作者在论文里留了一个彩蛋,技术报告的第二部分预告主要是讲Reward Model的成功和踩坑经验,目前还没有发布,静待作者更新。之前大家一直的争论点用什么scale的RM,说要用远远大于SFT model的RM model,这到底是不是一个关键的问题,是不是deberta 和 65B都行,期待作者第二个技术报告里给一个实验~
审核编辑:刘清
-
处理器
+关注
关注
68文章
19461浏览量
231438 -
SFT
+关注
关注
0文章
9浏览量
6830 -
GAE
+关注
关注
0文章
5浏览量
6784
原文标题:大模型RLHF的trick
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐








 工商网监
工商网监
评论