 LLM的长度外推浅谈
LLM的长度外推浅谈
一、NBCE
NBCE:使用朴素贝叶斯扩展LLM的Context处理长度
苏神最早提出的扩展LLM的context方法,基于bayes启发得到的公式: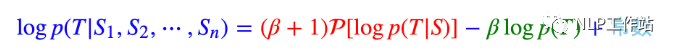
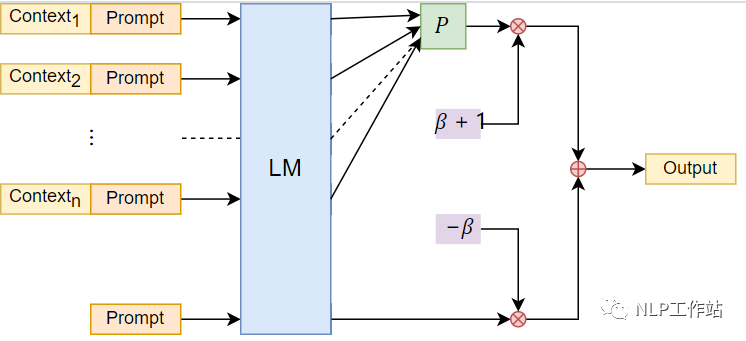
在问答下实测确实不错,在较长context下的阅读理解还算好用。
局限性是,无序性,即无法识别Context的输入顺序,这在续写故事等场景可能表现欠佳,做一些依赖每个context生成答案,比如提取文档摘要,效果较差。
outputs=model(input_ids=input_ids, attention_mask=attention_mask, return_dict=True, use_cache=True, past_key_values=past_key_values ) past_key_values=outputs.past_key_values #=====核心代码开始===== beta=0.25 probas=torch.nn.functional.softmax(outputs.logits[:,-1],dim=-1) logits=probas.log() k=(probas*logits).sum(dim=-1)[1:].argmax()+1 logits_max=logits[k] logits_uncond=logits[0] logits=(1+beta)*logits_max-beta*logits_uncond #=====核心代码结束===== #构建分布,采样 tau=0.01#tau=1是标准的随机采样,tau->0则是贪心搜索 probas=torch.nn.functional.softmax(logits[None]/tau,dim=-1) next_tokens=torch.multinomial(probas,num_samples=1).squeeze(1)
此处代码,图片,文本均选自科学空间。
二、线性内插
llama基于rotary embedding在2048长度上预训练,该方法通过将position压缩到0~2048之间,从而达到长度外推的目的。
longchat将模型微调为上下文长度外扩为16384,压缩比为 8。例如,position_ids = 10000 的 token 变为position_ids = 10000 / 8 = 1250,相邻 token 10001 变为 10001 / 8 = 1250.125
该方法的缺陷是需要进行一定量的微调,让模型来适应这种改变。
importtorch importtransformers importtransformers.models.llama.modeling_llama fromeinopsimportrearrange fromfunctoolsimportpartial classCondenseRotaryEmbedding(torch.nn.Module): def__init__(self,dim,ratio,max_position_embeddings=2048,base=10000,device=None): super().__init__() inv_freq=1.0/(base**(torch.arange(0,dim,2).float().to(device)/dim)) self.register_buffer("inv_freq",inv_freq) #Buildheretomake`torch.jit.trace`work. self.ratio=ratio max_position_embeddings*=ratio print(f"CondensingPositionalembeddingsfrom{max_position_embeddings}to{max_position_embeddings//ratio}") self.max_seq_len_cached=max_position_embeddings t=torch.arange(self.max_seq_len_cached,device=self.inv_freq.device,dtype=self.inv_freq.dtype)/ratio freqs=torch.einsum("i,j->ij",t,self.inv_freq) #Differentfrompaper,butitusesadifferentpermutationinordertoobtainthesamecalculation emb=torch.cat((freqs,freqs),dim=-1) dtype=torch.get_default_dtype() self.register_buffer("cos_cached",emb.cos()[None,None,:,:].to(dtype),persistent=False) self.register_buffer("sin_cached",emb.sin()[None,None,:,:].to(dtype),persistent=False) defforward(self,x,seq_len=None): #x:[bs,num_attention_heads,seq_len,head_size] #This`if`blockisunlikelytoberunafterwebuildsin/cosin`__init__`.Keepthelogicherejustincase. ifseq_len>self.max_seq_len_cached: self.max_seq_len_cached=seq_len t=torch.arange(self.max_seq_len_cached,device=x.device,dtype=self.inv_freq.dtype)/self.ratio freqs=torch.einsum("i,j->ij",t,self.inv_freq) #Differentfrompaper,butitusesadifferentpermutationinordertoobtainthesamecalculation emb=torch.cat((freqs,freqs),dim=-1).to(x.device) self.register_buffer("cos_cached",emb.cos()[None,None,:,:].to(x.dtype),persistent=False) self.register_buffer("sin_cached",emb.sin()[None,None,:,:].to(x.dtype),persistent=False) return( self.cos_cached[:,:,:seq_len,...].to(dtype=x.dtype), self.sin_cached[:,:,:seq_len,...].to(dtype=x.dtype), ) defreplace_llama_with_condense(ratio): transformers.models.llama.modeling_llama.LlamaRotaryEmbedding=partial(CondenseRotaryEmbedding,ratio=ratio)
三、NTK-Aware Scaled RoPE
RoPE是一种β进制编码//spaces.ac.cn/archives/9675
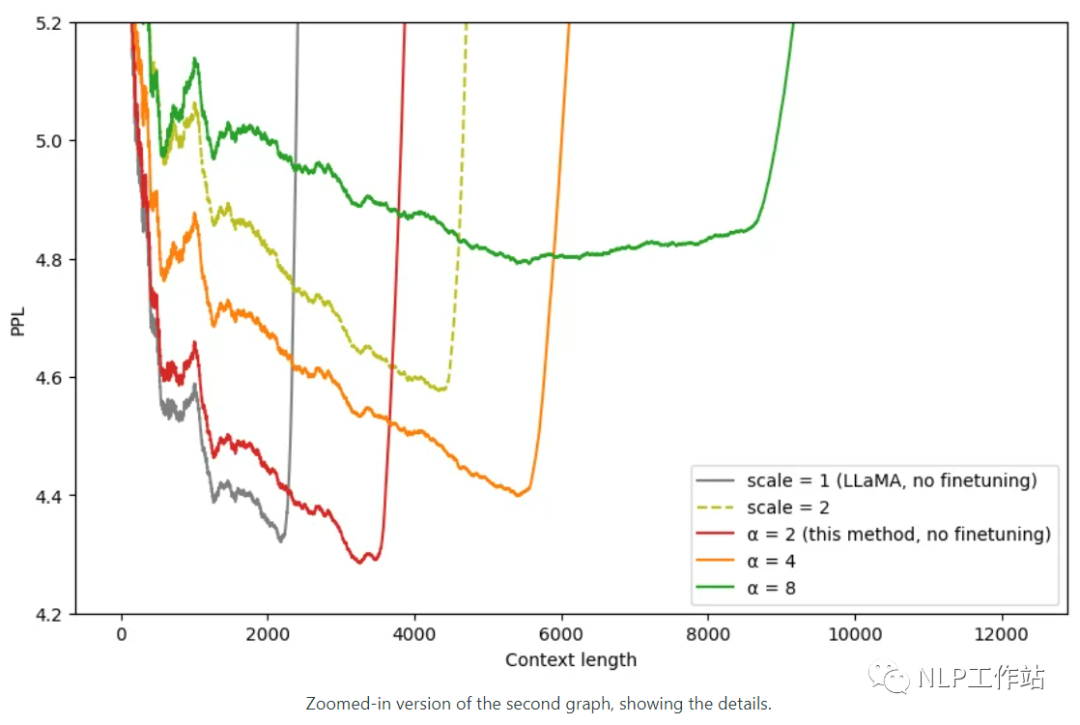
有意思的解释一下,RoPE 的行为就像一个时钟。12小时时钟基本上是一个维度为 3、底数为 60 的 RoPE。因此,每秒钟,分针转动 1/60 分钟,每分钟,时针转动 1/60。
现在,如果将时间减慢 4 倍,那就是二使用的线性RoPE 缩放。不幸的是,现在区分每一秒,因为现在秒针几乎每秒都不会移动。
因此,如果有人给你两个不同的时间,仅相差一秒,你将无法从远处区分它们。NTK-Aware RoPE 扩展不会减慢时间。一秒仍然是一秒,但它会使分钟减慢 1.5 倍,将小时减慢 2 倍。
这样,您可以将 90 分钟容纳在一个小时中,将 24 小时容纳在半天中。
所以现在你基本上有了一个可以测量 129.6k 秒而不是 43.2k 秒的时钟。由于在查看时间时不需要精确测量时针,因此与秒相比,更大程度地缩放小时至关重要。
不想失去秒针的精度,但可以承受分针甚至时针的精度损失。
importtransformers old_init=transformers.models.llama.modeling_llama.LlamaRotaryEmbedding.__init__ defntk_scaled_init(self,dim,max_position_embeddings=2048,base=10000,device=None): #Themethodisjustthesethreelines max_position_embeddings=16384 a=8#Alphavalue base=base*a**(dim/(dim-2))#Basechangeformula old_init(self,dim,max_position_embeddings,base,device) transformers.models.llama.modeling_llama.LlamaRotaryEmbedding.__init__=ntk_scaled_init
四、Dynamically Scaled RoPE
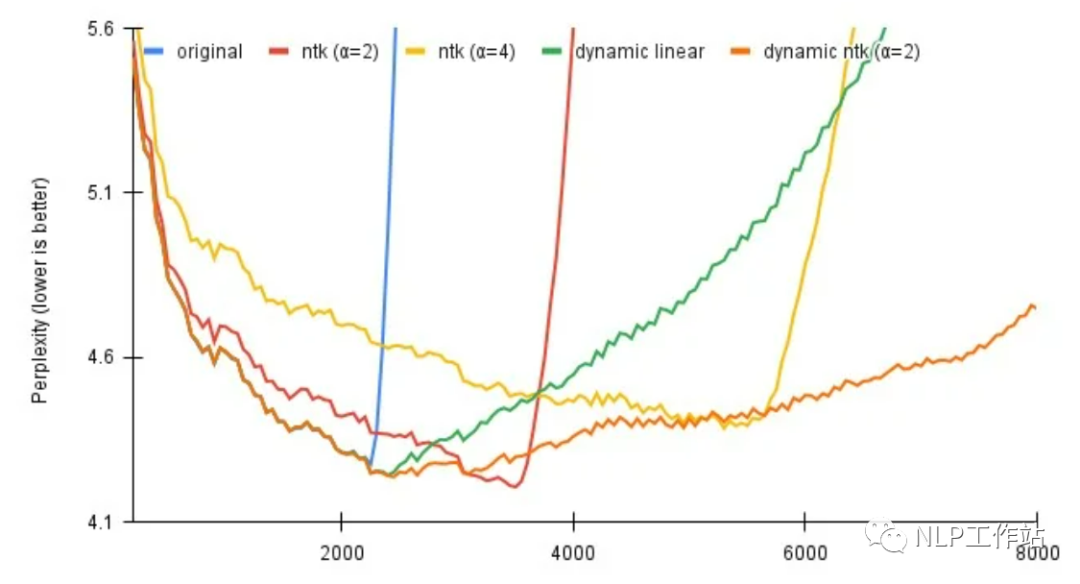
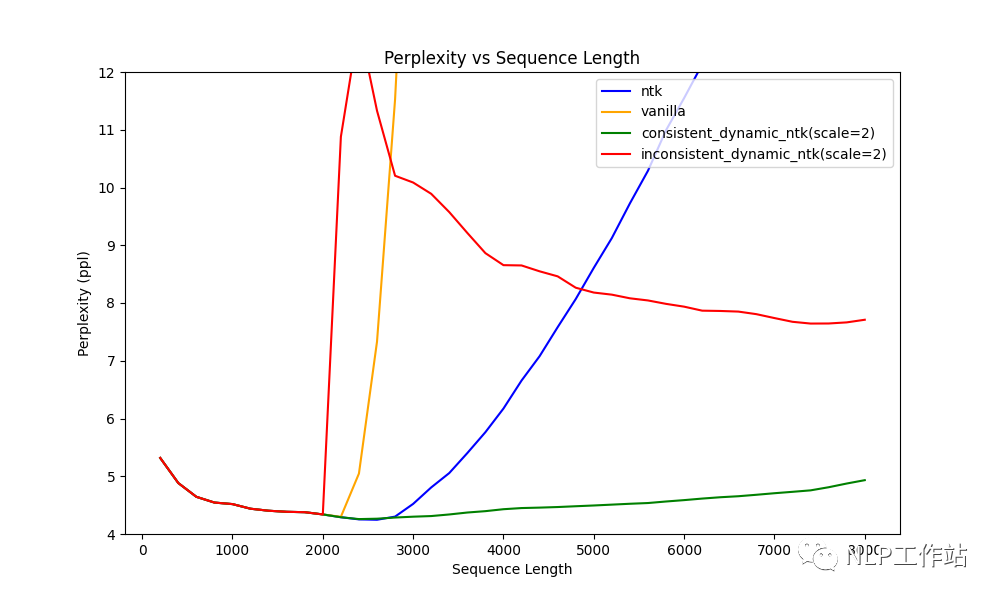
对于上面的方法二、三,都涉及到一个超参数α,用于调节缩放比例,该方法是通过序列长度动态选择正确的比例参数,效果可以看上图。
对于线性插值,前 2k 上下文的精确位置值,然后在模型逐个生成标记时重新计算每个新序列长度的位置向量。本质上,将比例设置为原始模型上下文长度/当前序列长度。
对于动态 NTK,α 的缩放设置为 (α * 当前序列长度 / 原始模型上下文长度) - (α - 1)。随着序列长度的增加动态缩放超参数。
importmath
importtorch
classLlamaDynamicScaledRotaryEmbedding(torch.nn.Module):
def__init__(self,dim,max_position_embeddings=2048,base=10000,ntk=False,device=None):
super().__init__()
self.ntk=ntk
self.base=base
self.dim=dim
self.max_position_embeddings=max_position_embeddings
inv_freq=1.0/(base**(torch.arange(0,dim,2).float().to(device)/dim))
self.register_buffer("inv_freq",inv_freq)
#Buildheretomake`torch.jit.trace`work.
self.max_seq_len_cached=max_position_embeddings
t=torch.arange(self.max_seq_len_cached,device=self.inv_freq.device,dtype=self.inv_freq.dtype)
freqs=torch.einsum("i,j->ij",t,self.inv_freq)
#Differentfrompaper,butitusesadifferentpermutationinordertoobtainthesamecalculation
emb=torch.cat((freqs,freqs),dim=-1)
dtype=torch.get_default_dtype()
self.register_buffer("cos_cached",emb.cos()[None,None,:,:].to(dtype),persistent=False)
self.register_buffer("sin_cached",emb.sin()[None,None,:,:].to(dtype),persistent=False)
defforward(self,x,seq_len=None):
#x:[bs,num_attention_heads,seq_len,head_size]
#This`if`blockisunlikelytoberunafterwebuildsin/cosin`__init__`.Keepthelogicherejustincase.
ifseq_len>self.max_seq_len_cached:
self.max_seq_len_cached=seq_len
ifself.ntk:
base=self.base*((self.ntk*seq_len/self.max_position_embeddings)-(self.ntk-1))**(self.dim/(self.dim-2))
inv_freq=1.0/(base**(torch.arange(0,self.dim,2).float().to(x.device)/self.dim))
self.register_buffer("inv_freq",inv_freq)
t=torch.arange(self.max_seq_len_cached,device=x.device,dtype=self.inv_freq.dtype)
ifnotself.ntk:
t*=self.max_position_embeddings/seq_len
freqs=torch.einsum("i,j->ij",t,self.inv_freq)
#Differentfrompaper,butitusesadifferentpermutationinordertoobtainthesamecalculation
emb=torch.cat((freqs,freqs),dim=-1).to(x.device)
self.register_buffer("cos_cached",emb.cos()[None,None,:,:].to(x.dtype),persistent=False)
self.register_buffer("sin_cached",emb.sin()[None,None,:,:].to(x.dtype),persistent=False)
return(
self.cos_cached[:,:,:seq_len,...].to(dtype=x.dtype),
self.sin_cached[:,:,:seq_len,...].to(dtype=x.dtype),
)
五、consistent of Dynamically Scaled RoPE
方法四存在一个问题是,因为α是动态的,因为解码是有cache的,所以,在生成第100个token时,算的α和第200个token时,算的α时不一致的。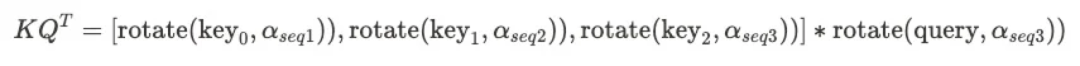
query和key的rotation base不一致,正确的应该时这样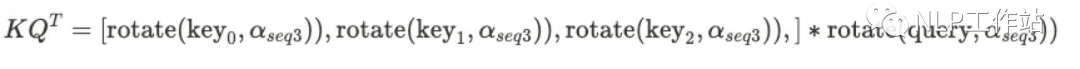
importmath fromtypingimportList,Optional,Tuple,Union importtorch importtorch.nn.functionalasF importtorch.utils.checkpoint fromtorchimportnn fromtransformers.models.llama.modeling_llamaimportrepeat_kv,apply_rotary_pos_emb fromtransformers.models.llama.modeling_llamaimportLlamaAttention defforward( self, hidden_states:torch.Tensor, attention_mask:Optional[torch.Tensor]=None, position_ids:Optional[torch.LongTensor]=None, past_key_value:Optional[Tuple[torch.Tensor]]=None, output_attentions:bool=False, use_cache:bool=False, )->Tuple[torch.Tensor,Optional[torch.Tensor],Optional[Tuple[torch.Tensor]]]: bsz,q_len,_=hidden_states.size() ifself.pretraining_tp>1: key_value_slicing=(self.num_key_value_heads*self.head_dim)//self.pretraining_tp query_slices=self.q_proj.weight.split((self.num_heads*self.head_dim)//self.pretraining_tp,dim=0) key_slices=self.k_proj.weight.split(key_value_slicing,dim=0) value_slices=self.v_proj.weight.split(key_value_slicing,dim=0) query_states=[F.linear(hidden_states,query_slices[i])foriinrange(self.pretraining_tp)] query_states=torch.cat(query_states,dim=-1) key_states=[F.linear(hidden_states,key_slices[i])foriinrange(self.pretraining_tp)] key_states=torch.cat(key_states,dim=-1) value_states=[F.linear(hidden_states,value_slices[i])foriinrange(self.pretraining_tp)] value_states=torch.cat(value_states,dim=-1) else: query_states=self.q_proj(hidden_states) key_states=self.k_proj(hidden_states) value_states=self.v_proj(hidden_states) query_states=query_states.view(bsz,q_len,self.num_heads,self.head_dim).transpose(1,2) key_states=key_states.view(bsz,q_len,self.num_key_value_heads,self.head_dim).transpose(1,2) value_states=value_states.view(bsz,q_len,self.num_key_value_heads,self.head_dim).transpose(1,2) kv_seq_len=key_states.shape[-2] ifpast_key_valueisnotNone: kv_seq_len+=past_key_value[0].shape[-2] cos,sin=self.rotary_emb(value_states,seq_len=kv_seq_len) ifpast_key_valueisnotNone: #reusekw/oRoPE key_states=torch.cat([past_key_value[0],key_states],dim=2) #applyRoPEafterretrievingallkeysandqueries query_states,rotated_key_states=apply_rotary_pos_emb(query_states,key_states,cos,sin,position_ids) ifpast_key_valueisnotNone: #reusev,self_attention value_states=torch.cat([past_key_value[1],value_states],dim=2) past_key_value=(key_states,value_states)ifuse_cacheelseNone#cachethekeyw/oRoPE #repeatk/vheadsifn_kv_heads< n_heads rotated_key_states = repeat_kv(rotated_key_states, self.num_key_value_groups) value_states = repeat_kv(value_states, self.num_key_value_groups) attn_weights = torch.matmul(query_states, rotated_key_states.transpose(2, 3)) / math.sqrt(self.head_dim) if attn_weights.size() != (bsz, self.num_heads, q_len, kv_seq_len): raise ValueError( f"Attention weights should be of size {(bsz, self.num_heads, q_len, kv_seq_len)}, but is" f" {attn_weights.size()}" ) if attention_mask is not None: if attention_mask.size() != (bsz, 1, q_len, kv_seq_len): raise ValueError( f"Attention mask should be of size {(bsz, 1, q_len, kv_seq_len)}, but is {attention_mask.size()}" ) attn_weights = attn_weights + attention_mask # upcast attention to fp32 attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype) attn_output = torch.matmul(attn_weights, value_states) if attn_output.size() != (bsz, self.num_heads, q_len, self.head_dim): raise ValueError( f"`attn_output` should be of size {(bsz, self.num_heads, q_len, self.head_dim)}, but is" f" {attn_output.size()}" ) attn_output = attn_output.transpose(1, 2).contiguous() attn_output = attn_output.reshape(bsz, q_len, self.hidden_size) if self.pretraining_tp >1: attn_output=attn_output.split(self.hidden_size//self.pretraining_tp,dim=2) o_proj_slices=self.o_proj.weight.split(self.hidden_size//self.pretraining_tp,dim=1) attn_output=sum([F.linear(attn_output[i],o_proj_slices[i])foriinrange(self.pretraining_tp)]) else: attn_output=self.o_proj(attn_output) ifnotoutput_attentions: attn_weights=None returnattn_output,attn_weights,past_key_value defreplace_llama_attn_with_consistent_ntk_rope(): LlamaAttention.forward=forward
审核编辑:刘清
-
解码器
+关注
关注
9文章
1141浏览量
40713 -
LLM
+关注
关注
0文章
285浏览量
325
原文标题:浅谈LLM的长度外推
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
对比解码在LLM上的应用
饿了么确认收购百度外卖!最快本周收购,百度外卖为何会变成百度的弃子?
饿了么正式宣布收购百度外卖 内部邮件曝光
LLM性能的主要因素

中国研究人员提出StructGPT,提高LLM对结构化数据的零样本推理能力
使用MLC-LLM支持RWKV-5推理的过程思考

如何利用位置编码实现长度外推?

LLM推理加速新范式!推测解码(Speculative Decoding)最新综述





 工商网监
工商网监
评论