 立创·梁山派开发板-21年电赛F题-送药小车-K210的KPU数字识别训练
立创·梁山派开发板-21年电赛F题-送药小车-K210的KPU数字识别训练

送药小车代码仓库:https://gitee.com/lcsc/medical_car
更好的观看体验请去:12_K210的KPU数字识别训练
送药小车立创开源平台资料:https://oshwhub.com/li-chuang-kai-fa-ban/21-dian-sai-f-ti-zhi-neng-song-yao-xiao-che
K210的KPU数字识别训练
K210自带 KPU(通用的神经网络处理器),非常适合用来作数字识别。要采集的数据集图像尺寸为 224*224(这是目前最常用的网络数据大小),为了让结果更准确,所以要训练的数据集要尽可能多,每种数字的数据量尽可能相等。但 k210 的算力也是有限的,他所能运行的模型也是有限的,对于 k210:运行 c 代码时最大可以加载 6MB 左右的模型,运行 maixpy 的最小固件时,能加载 3MB 左右的模型,运行 maixpy 的最大固件时,能够加载约 2MB 左右的模型。(值得注意的一点,模型大小和数据集没有必然关系,所以不用担心数据集采集太多导致K210的内存装载不下的问题,选好Alpha参数就能确定模型的大小)
简单来说,实现K210的数字识别就是三步:
采集数据集
对数据集进行标注
开始训练并得到
采集数据集
因为我们运算是在 K210 本地的,图像来源也是 K210 自带的摄像头,为了让结果更准确,可以用 python 编写一个 K210 的拍照程序,采集固定的 224*224 图像并保存到 TF 卡里面。最好是搭好小车框架后,选好摄像头的安装位置和角度,将拍照程序保存到 K210 的运行 sd 卡里面。当按下按钮的时候就进行当前图像的保存。
拍照的代码如下所示(具体代码在2_Code->application->sensor->k210->pyconde-take_picture.py):
import sensor, image, time, lcd, struct, ustruct, _thread from maix import KPU,GPIO, I2S, FFT import gc,os from machine import Timer,PWM,I2C from fpioa_manager import fm lcd.init() # Init lcd display lcd.clear(lcd.RED) # Clear lcd screen. sensor.reset() # Reset and initialize the sensor. sensor.reset(freq=24000000, dual_buff=1) # 设置摄像头频率 24M 开启双缓冲模式 会提高帧率 但内存占用增加 sensor.set_auto_exposure(1) # 设置自动曝光 sensor.set_auto_gain(False) # 颜色跟踪必须关闭自动增益 sensor.set_auto_whitebal(False) # 颜色跟踪必须关闭白平衡 sensor.set_pixformat(sensor.RGB565) # Set pixel format to RGB565 (or GRAYSCALE) sensor.set_framesize(sensor.QVGA) # Set frame size to QVGA (320x240) sensor.set_windowing((224,224)) # 分辨率为B224X224 sensor.set_vflip(1) sensor.skip_frames(time = 2000) # Wait for settings take effect. clock = time.clock() # Create a clock object to track the FPS. #要拍摄不同的数字就切换这里的数字 need_number_ficture= 1 #保存文件名计数 save_count =0 #注册IO,注意高速GPIO口才有中断 fm.register(35, fm.fpioa.GPIO0) fm.register(16, fm.fpioa.GPIOHS0) #构建案件对象 KEY=GPIO(GPIO.GPIOHS0, GPIO.IN, GPIO.PULL_UP) #按键标志位 key_node = 0 key_press_long = 0 #中断回调函数 def fun(KEY): global state,key_node,need_number_ficture temp_count = 0 time.sleep_ms(10) #消除抖动 while KEY.value()== 0: key_node = 1 time.sleep_ms(10) #长按延时 #长按检测计数 temp_count=temp_count+1 if temp_count >= 50: key_node = 0 beep.duty(50) time.sleep_ms(500) beep.duty(0) time.sleep_ms(100) need_number_ficture=need_number_ficture+1 if(need_number_ficture == 9): need_number_ficture=0 #开启中断,下降沿触发 KEY.irq(fun, GPIO.IRQ_FALLING) #先把文件路径切换到文件卡里面 os.chdir("/sd") #os.mkdir("img/0") #os.mkdir("img/1") #os.mkdir("img/2") #os.mkdir("img/3") #os.mkdir("img/4") #os.mkdir("img/5") #os.mkdir("img/6") #os.mkdir("img/7") #os.mkdir("img/8") #PWM通过定时器配置,接到IO15引脚 tim = Timer(Timer.TIMER0, Timer.CHANNEL0, mode=Timer.MODE_PWM) beep = PWM(tim, freq=1000, duty=0, pin=9) clock = time.clock() # 创建一个clock对象,用来计算帧率 while True: clock.tick() # 更新计算帧率的clock img=sensor.snapshot() #按键按下进入 if key_node == 1: save_count=save_count+1 img.save("img/"+str(need_number_ficture)+"/"+str(save_count)+".jpg") beep.duty(50) time.sleep_ms(100) beep.duty(0) time.sleep_ms(100) key_node = 0 #清除按键标志位 # 在图像上画字符串 img.draw_string(0, 10,str(need_number_ficture)+"/"+str(save_count)+".jpg", color = (200, 0, 0), scale = 2, mono_space = False, char_rotation = 0, char_hmirror = False, char_vflip = False, string_rotation = 0, string_hmirror = False, string_vflip = False) lcd.display(img)
下面来解释一下上面这段代码做了什么:
导入必要的库:导入需要的库和模块(就像C语言的.h头文件一样),如sensor, image, time, lcd, GPIO, Timer, PWM, I2C等。
初始化LCD屏幕:使用lcd.init()初始化LCD屏幕,并使用lcd.clear(lcd.RED)清空屏幕,防止出现误显示问题。
设置摄像头:使用sensor.reset()重置摄像头并进行初始化。然后,设置摄像头的相关参数,比如时钟频率、设置双缓冲来增加帧率,关闭自动曝光、关闭自动增益、关闭自动白平衡、设置像素格式、帧大小、窗口大小、垂直翻转(这个和用的摄像头有关)等。
初始化变量:初始化必要的变量,如当前拍摄的数字(need_number_ficture)、保存计数(save_count)、按键标志位(key_node)等。
设置GPIO和按键中断:注册GPIO,并创建一个按键对象KEY。定义一个中断回调函数fun(KEY),用于在按键按下时改变当前拍摄的数字。最后,配置按键中断,使其在下降沿触发。
设置蜂鸣器:使用Timer和PWM初始化蜂鸣器,并连接到指定的引脚。
主循环:在主循环中,首先更新帧率计算的clock。然后,从摄像头捕获一帧图像。如果按键被按下(key_node为1),则将当前帧图像保存到SD卡的相应目录(对应于当前拍摄的数字)。同时,蜂鸣器发出提示音(提示我们拍照OK了)。最后,在图像上绘制当前拍摄数字和已保存的图片计数,并将图像显示在LCD屏幕上,方便提示我们拍摄下一张照片。
对数据集进行标注
这个就需要用到一个大神开发的软件了(现在最新版自带Python环境,无需麻烦的环境配置了),下载地址,找下面的百度网盘下载链接,找到里面的V4.0.0下载下来安装后就可以使用了。用读卡器把 K210的TF 卡里面采集到的训练集保存到电脑上。
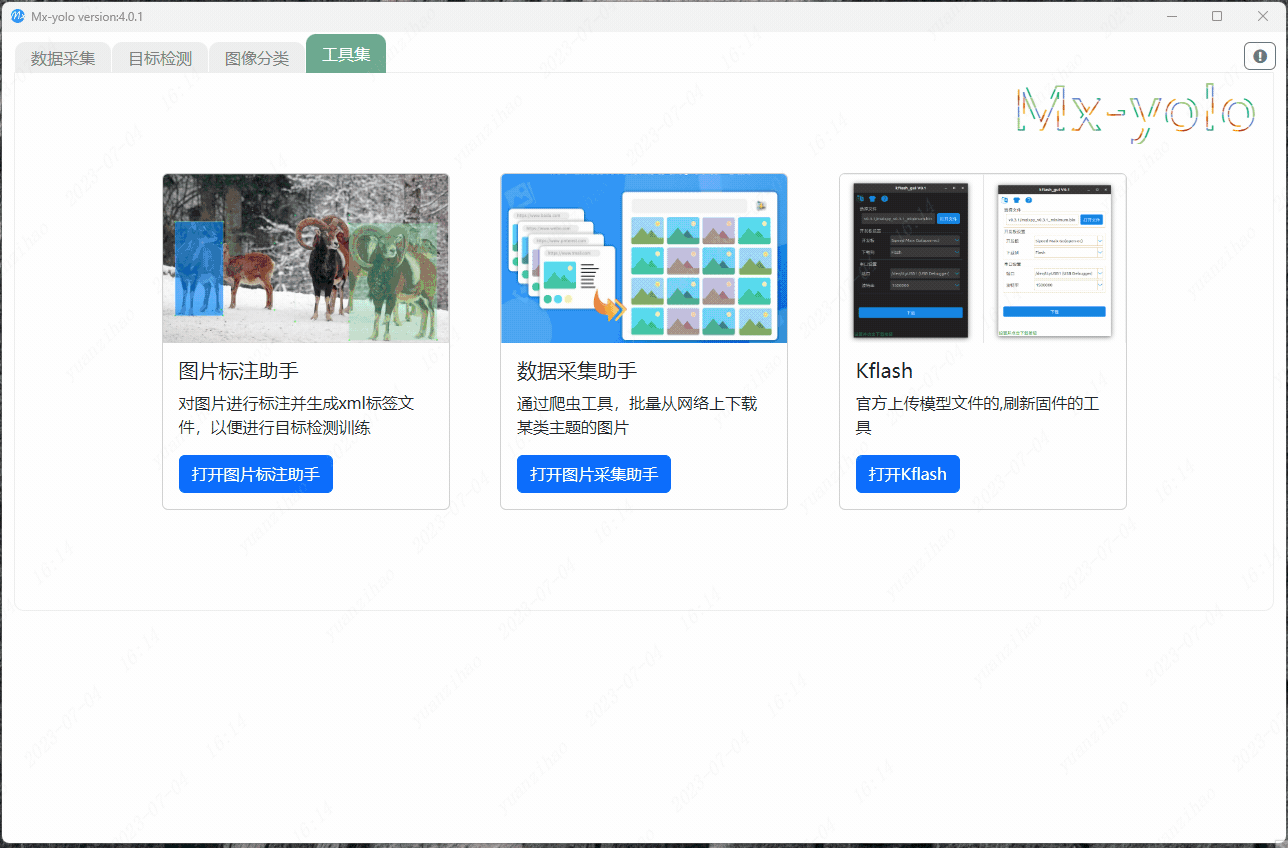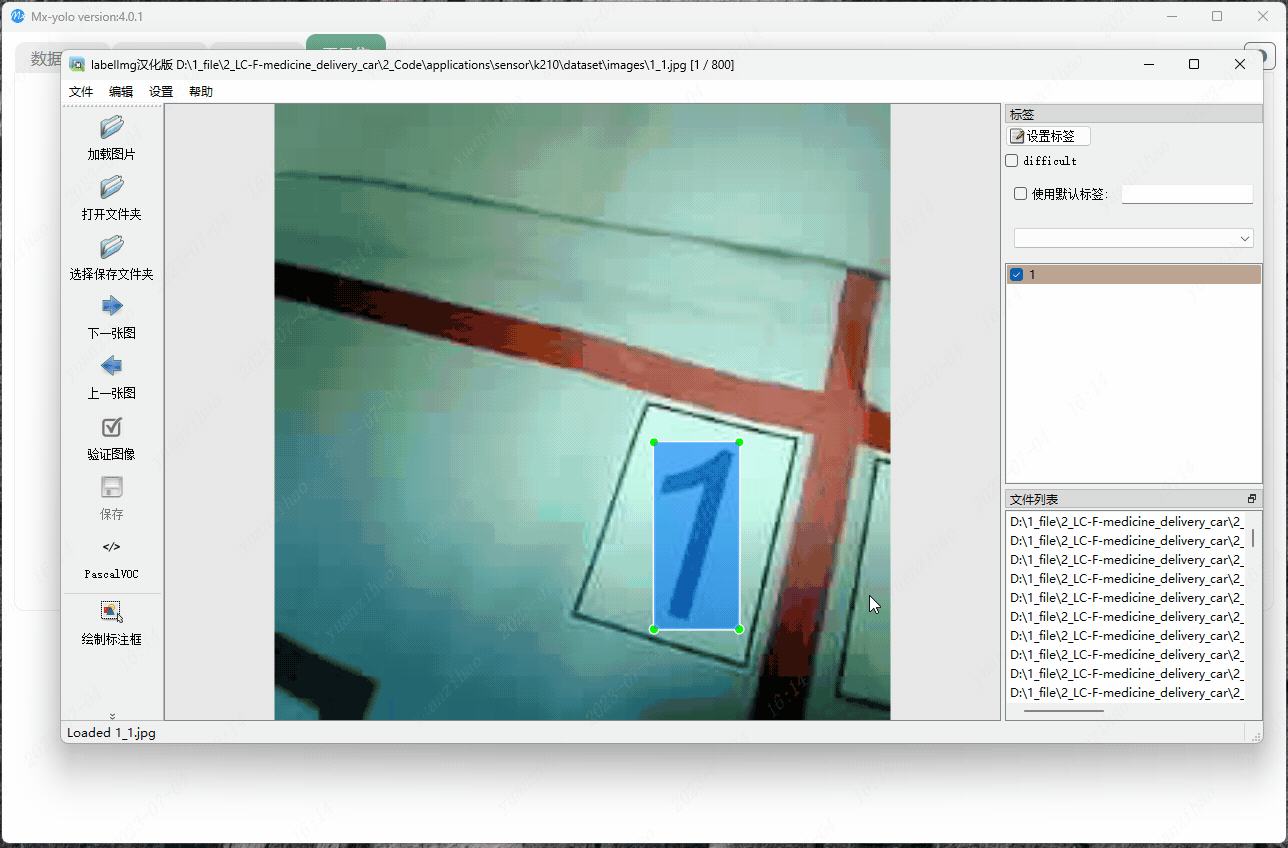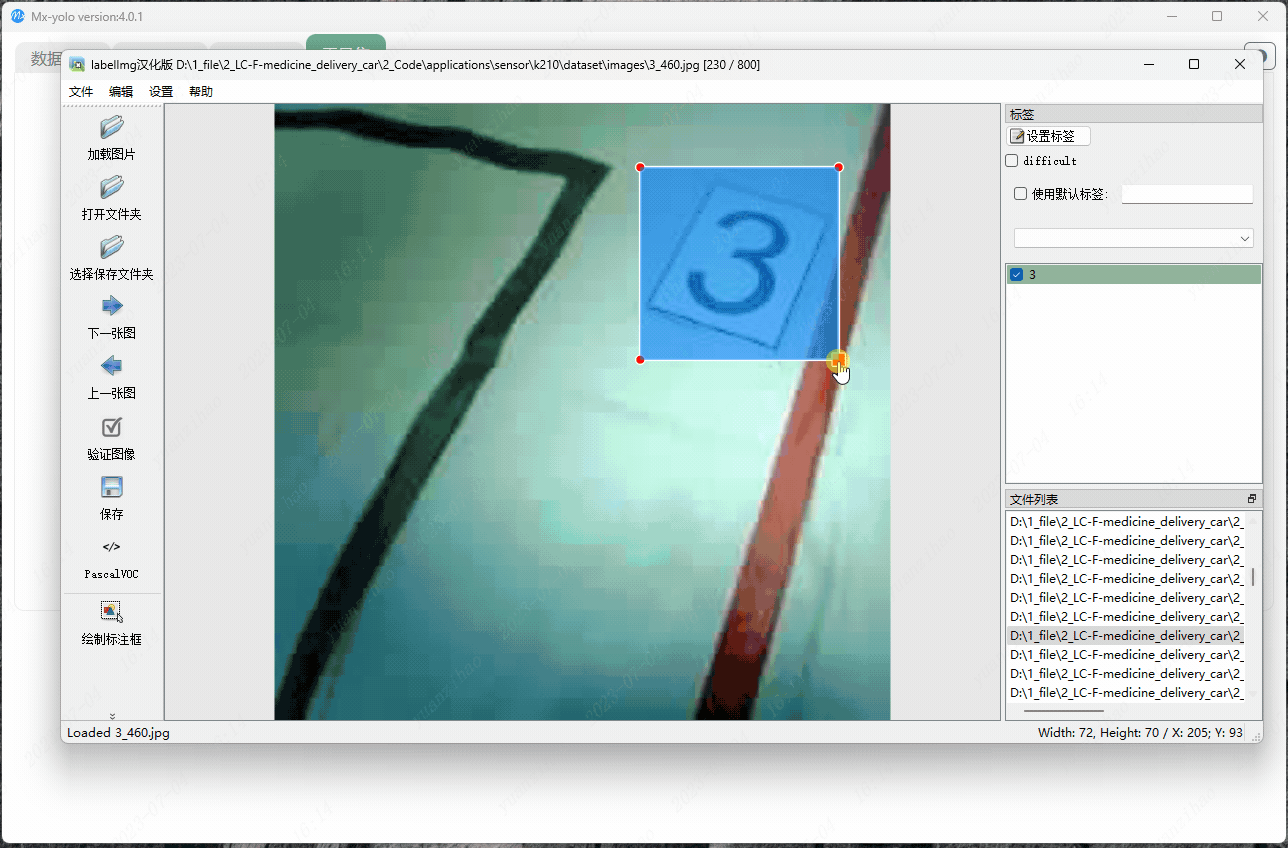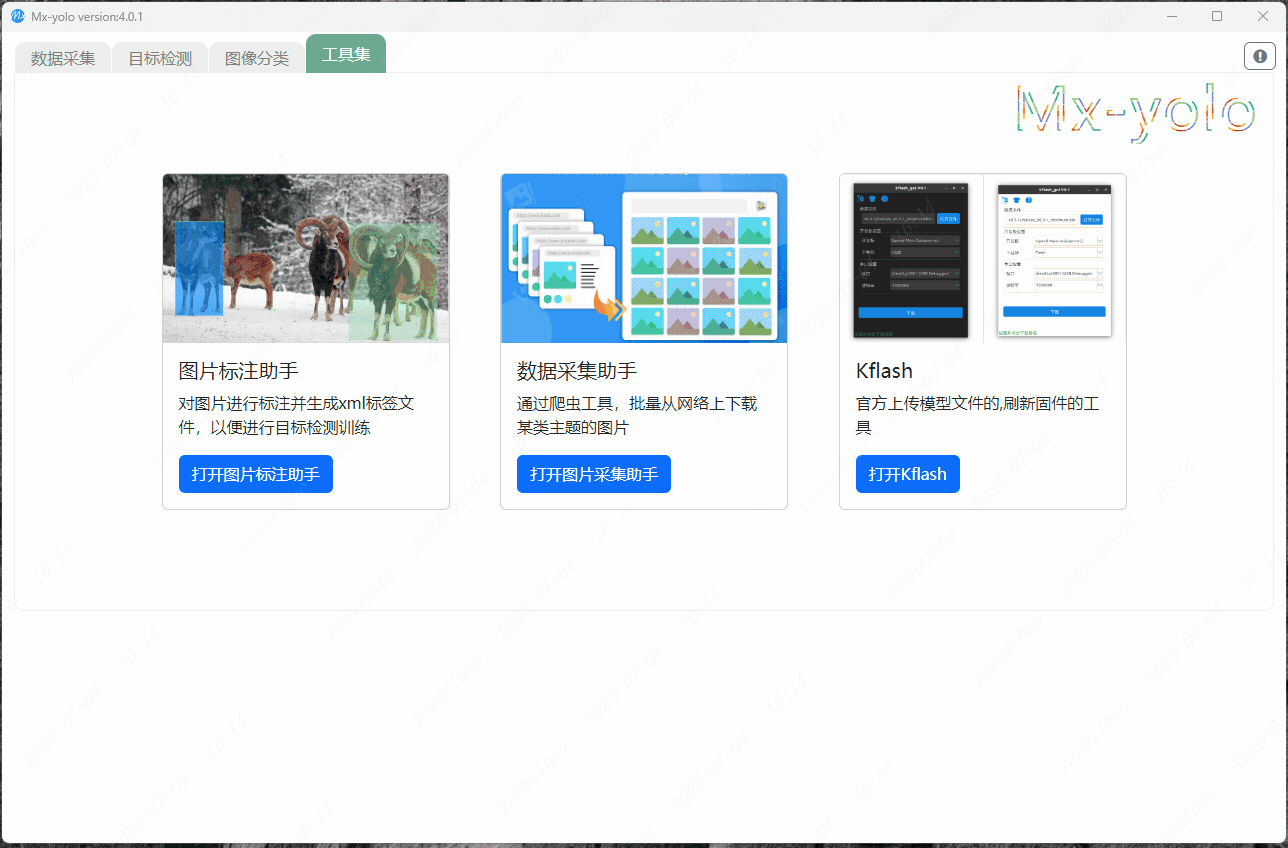
打开Mx-yolo里面工具集中的图片标注助手,打开保存采集数据的文件夹。详细教程请查看这个链接。
开始训练
训练可以选在线的也可以用本地的,但是如果像是电赛这种时间很紧张的比赛,为了防止到时候千军万马过独木桥,导致你的训练任务一直在排队,最好先设置好自己的本地环境。按照上面的介绍安装mx-yolo。
模型训练的次数需要在保证模型收敛的前提下进行合理的选择。如果训练次数过少,可能会导致模型欠拟合,无法很好地拟合训练数据。如果训练次数过多,可能会导致模型过拟合,无法很好地泛化到新的数据。因此,需要根据具体的问题和数据集进行调整。一般来说,可以通过观察模型在训练集和验证集上的表现来确定合适的训练次数。当模型在验证集上的表现不再提升时,可以停止训练,以避免过拟合。
Alpha 主要影响所生成模型的大小,选 0.25 模型大小约 219k,选 0.5 模型大小约 831k,选 0.75 模型大小约 1.85M,选 1.0 模型大小约 3.24M。当运行 maixpy 的最大固件时,k210 最大只能加载约 2MB 左右的模型,所以选 0.75 就行了。
Batch Size 一般选 8 就行了。这个参数是指每次迭代训练时,所选取的样本数。Batch Size 的大小会影响模型训练的速度和稳定性。较大的 Batch Size 可以加快模型训练的速度,因为每次迭代处理的样本数量更多。但是,如果 Batch Size 过大,可能会导致内存不足或显存不足的问题。此外,较大的 Batch Size 还可能导致模型过度拟合训练数据。较小的 Batch Size 可以提高模型训练的稳定性,因为每次迭代处理的样本数量较少,可以更好地避免过拟合。但是,较小的 Batch Size 也会导致训练时间变长,因为需要更多次迭代才能处理完所有样本。
数据增强建议开启,他主要是做了一些随机裁剪,随机旋转,缩放,翻转等。
训练结束后他会自动把模型转换为K210能使用的模型,主要文件都在result_root_dirdetector_result目录下面,它还会给一张测试报告,确保模型损失已经到了0.1以下。在测试报告中,epoch代表训练次数,model loss是模型损失,train代表训练集,是用来训练模型的数据集。valid代表验证集,是用来评估模型性能和调整超参数的数据集。这两条线越来越往下就是越来越好了。
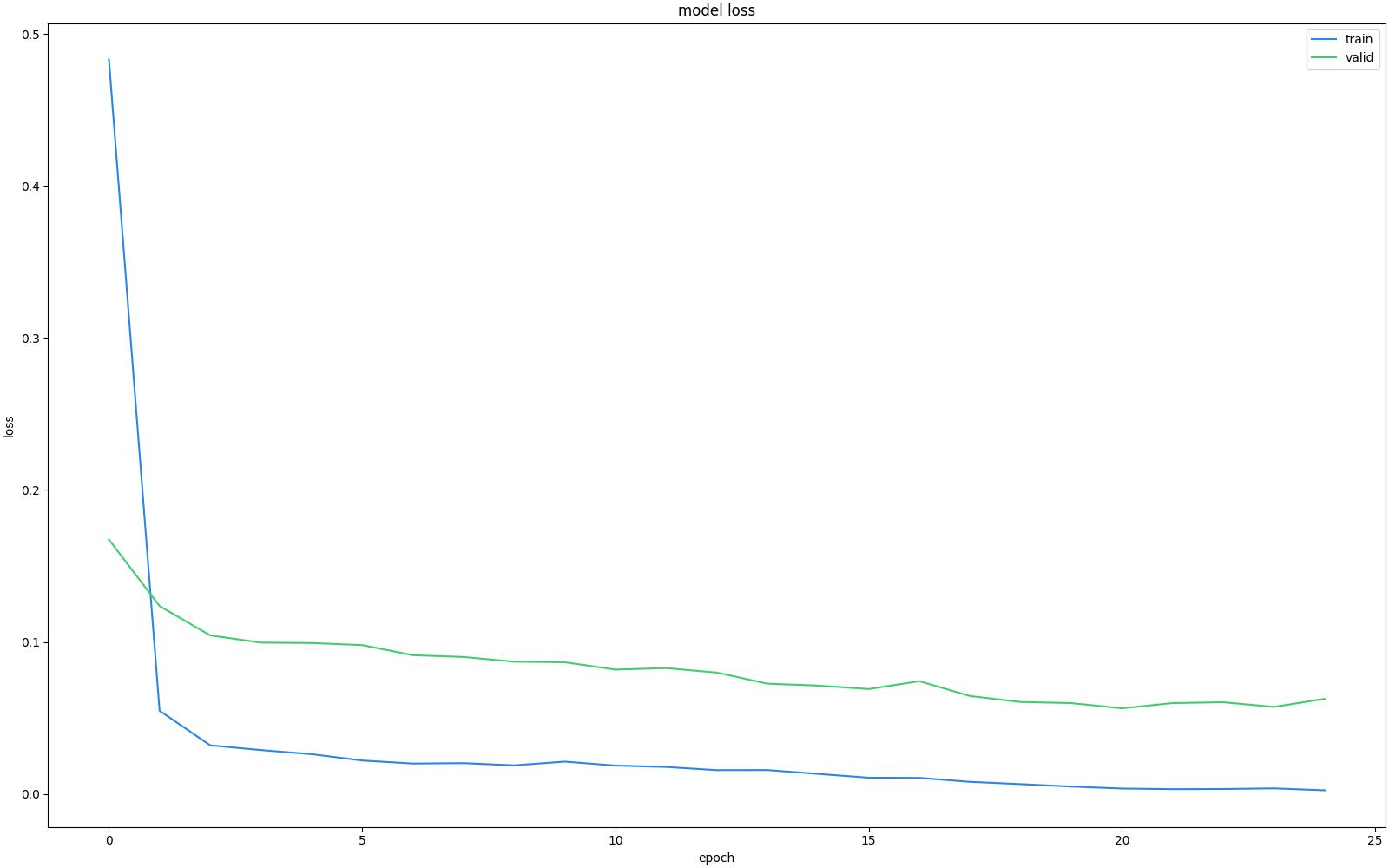
文件下的boot.py是他给的测试程序,labels.txt是标签顺序,mx.kmodel是K210实际要用的模型文件(这个文件在使用的时候需要保存到K210要使用的TF卡里面)。简单来说,把boot.py,lables.txt,mx.kmodel一起放到K210的sd卡里,重新上电就可以运行了。
审核编辑 黄宇
-
开发板
+关注
关注
26文章
6431浏览量
121018 -
数字识别
+关注
关注
2文章
22浏览量
10378
发布评论请先 登录
立创·梁山派开发板-21年电赛F题-送药小车-K210更换固件-运行基础颜色识别例程

立创·梁山派开发板-21年电赛F题-送药小车-K210功能实现代码讲解
开发板-21年电赛F题-送药小车-小车寻红线环的调试与实现
立创·梁山派开发板-21年电赛F题-送药小车实现思路
如何去实现基于K210的MNIST手写数字识别
K210开发板部署到开发板上后,会提示“Out of Memory”无法完成检测任务如何解决?
Kendryte K210开发板使用说明书
基于K210的MNIST手写数字识别

使用K210和Arduino IDE/Micropython进行图像识别

立创梁山派开发板-21年电赛F题-送药小车-小车角度环的调试与实现

立创·梁山派开发板-21年电赛F题-送药小车-与K210串口通信协议框架搭建
立创·梁山派开发板-21年电赛F题-送药小车数据的发布与订阅




评论