 Cerebras推出2 Exaflops人工智能超级计算机
Cerebras推出2 Exaflops人工智能超级计算机
“人工智能正在吞噬世界。”
硅谷人工智能计算机制造商Cerebras的首席执行官Andrew Feldman就是这样开始介绍他的公司的最新成就的:一台每秒能够进行20亿次运算(2亿次浮点运算)的人工智能超级计算机。该系统名为“Condor Galaxy 1”,有望在12周内将其规模扩大一倍。2024年初,将有另外两个规模加倍的系统加入。这家硅谷公司计划明年继续增加Condor Galaxy的安装,直到它运行一个由9台超级计算机组成的网络,总运算能力为36亿次。
如果大型语言模型和其他生成人工智能正在吞噬世界,Cerebras的计划是帮助他们消化它。加州森尼维尔的这家公司并不是唯一一家。其他专注于人工智能的计算机制造商正在围绕自己的专用处理器或英伟达最新的GPU H100构建大规模系统。虽然很难判断大多数系统的大小和功能,但Feldman声称Condor Galaxy 1已经是最大的系统之一。
Condor Galaxy 1在短短10天内组装并启动,由32台Cerebras CS-2计算机组成,并将扩展到64台。接下来的两个系统将在德克萨斯州奥斯汀和北卡罗来纳州阿什维尔建造,每个系统还将容纳64个CS-2。每台CS-2的核心是Waferscale Engine-2,这是一款人工智能专用处理器,由2.6万亿个晶体管和85万个全硅晶圆制成的人工智能核心。
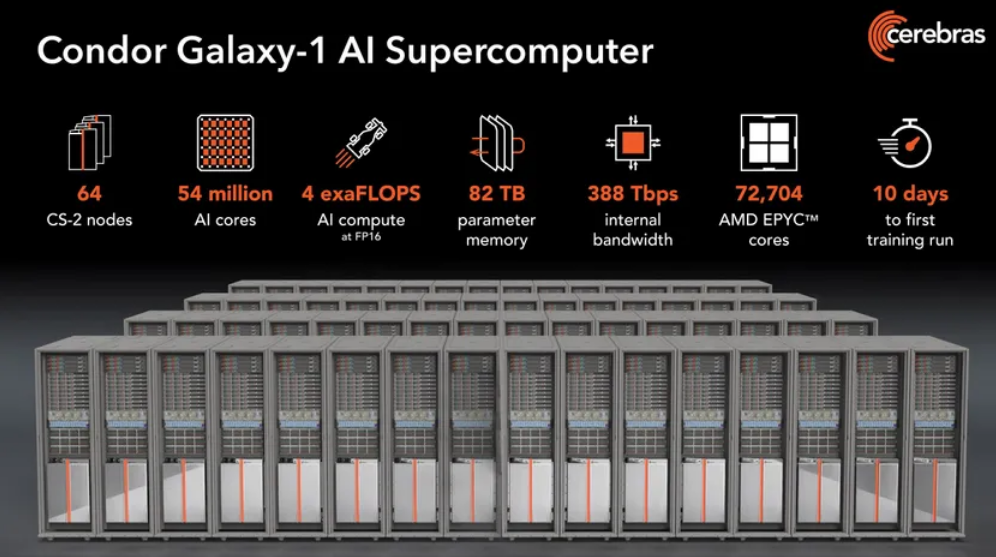
CEREBRAS
Feldman说,Cerebras在建造大型人工智能超级计算机方面的最大优势之一是它能够简单地扩大资源规模。例如,如果你投入40倍以上的硬件资源,400亿参数网络可以在与10亿参数网络大致相同的时间内进行训练。重要的是,这种放大不需要额外的代码行。他说:“我们通过按键从1到32(CS-2s)线性缩放。”
Condor Galaxy系列由总部位于阿布扎比的G42公司所有,G42是一家控股公司,拥有九家基于人工智能的企业,其中包括中东最大的云计算提供商之一G42 Cloud。Feldman将这种关系描述为“深度战略伙伴关系”,他说,这是在短短18个月内完成36次EB失败所需要的。Feldman计划在今年晚些时候搬到阿联酋几个月,以帮助管理合作,他说,这将“大大增加人工智能计算的global inventory”。 Cerebras将为G42操作超级计算机,并可以租用其合作伙伴未用于内部工作的资源。
Feldman表示,对训练大型神经网络的需求激增。他说,用500亿或更多参数训练神经网络模型的公司数量从2021年的2家增加到今年的100多家。
显然,Cerebras并不是唯一一家追求需要训练真正大型神经网络的企业。亚马逊、谷歌、Meta和微软等大公司都有自己的产品。围绕英伟达GPU构建的计算机集群主导了这项业务的大部分,但其中一些公司已经为人工智能开发了自己的硅,例如谷歌的TPU系列和亚马逊的Trainium。Cerebras也有初创公司的竞争对手,他们生产自己的人工智能加速器和计算机,包括Habana(现在是英特尔的一部分)、Graphcore和Samba Nova。
例如,Meta使用6000多个Nvidia A100 GPU构建了其AI研究超级集群。计划中的第二阶段将使集群达到5个EB。谷歌构建了一个包含4096个TPU v4加速器的系统,总共1.1亿次。该系统在短短10多秒内就突破了比今天的LLM小得多的BERT自然语言处理器神经网络。谷歌还运行Compute Engine A3,该引擎围绕英伟达H100 GPU和英特尔制造的定制基础设施处理单元构建。云提供商CoreWeave与英伟达合作,测试了一个由3584个H100 GPU组成的系统,该系统在10多分钟内训练出了代表大型语言模型GPT-3的基准。2024年,Graphcore计划建造一个名为Good Computer的10 exaflop系统,该系统由8000多个Bow处理器组成。
-
神经网络
+关注
关注
42文章
4771浏览量
100745 -
超级计算机
+关注
关注
2文章
462浏览量
41945 -
人工智能
+关注
关注
1791文章
47244浏览量
238378
原文标题:Cerebras推出2 Exaflops人工智能超级计算机
文章出处:【微信号:IEEE_China,微信公众号:IEEE电气电子工程师】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论