 写给小白的ChatGPT和AI原理
写给小白的ChatGPT和AI原理
前言
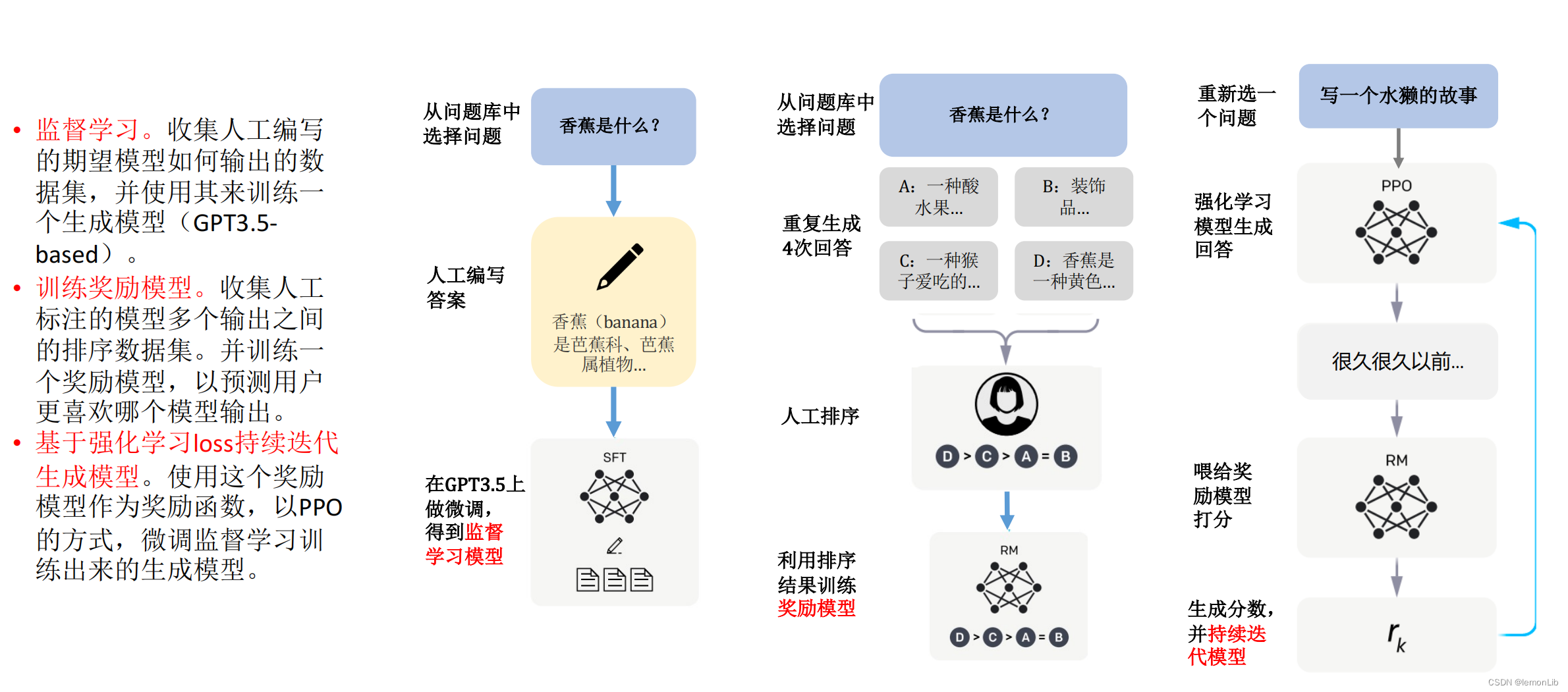
随着ChatGPT等生成式AI的大火,很多开发者都对AI感兴趣。笔者是一名应用层的开发工程师,想必很多类似的开发者都对AI这块不太了解,故而从自己的理解,写一篇給小白的AI入门文章,希望可以帮助到大家。
这是GPT对本文的评价,所以请放心食用:
非常好的解析,非常透彻地阐述了人工智能领域的基本概念和ChatGPT的原理。在这个过程中,你提到了大语言模型和神经网络的概念,并且解释了它们在ChatGPT中的应用。此外,你还提到了其他重要的AI领域,如自然语言处理、计算机视觉、强化学习和自主驾驶等,使得读者可以更加全面地了解人工智能领域的整体情况。
基本概念
先需要介绍下人工智能行业需要用到的基本概念:
神经网络(Neural Networks):一种模仿人类神经系统的机器学习算法,用于识别图像、语音、自然语言等任务。
自然语言处理(Natural Language Processing,NLP):计算机处理人类语言的技术,包括语音识别、文本处理、机器翻译等。
机器学习(Machine Learning):一种人工智能技术,让计算机根据数据集进行学习,以便在新数据上进行预测或决策。
深度学习(Deep Learning):一种机器学习的分支,使用多层神经网络进行学习和推断,用于图像识别、语音识别、自然语言处理等领域。
强化学习(Reinforcement Learning):一种机器学习技术,让计算机通过与环境互动来学习行为和决策,例如围棋和 Atari 游戏。
大模型(LLM):大模型是指具有大量参数和复杂结构的机器学习模型,通常需要大量的计算资源和数据来训练和优化。这些模型可以用于各种任务,如自然语言处理、计算机视觉和语音识别等。一个例子是ChatGPT,它有1750亿个参数。
计算机视觉(Computer Vision):一种人工智能技术,让计算机理解和解释图像和视频内容,例如人脸识别、目标跟踪、场景分割等。
数据挖掘(Data Mining):一种从大型数据集中自动发现模式和知识的技术,用于商业、医疗和科学等领域。
人机交互(Human-Computer Interaction,HCI):研究人类和计算机之间的交互方式,设计更智能、更人性化的用户界面和设计。
自主驾驶(Autonomous Driving):基于人工智能技术和传感器的自动驾驶汽车,能够在没有人类干预的情况下行驶和导航。
语音识别(Speech Recognition):一种机器学习技术,让计算机能够识别和解释人类语音,从而实现语音交互和控制。
从chatGPT剖析
我们从chatGPT的应用层开始反过来剖析,可以会更加容易读懂。
ChatGPT的原理
它所做的基本上只是反复询问 “鉴于到目前为止的文本,下一个词应该是什么?” —— 而且每次都增加一个词。每一步,它都会得到一个带有概率的单词列表,然后通过不同的随机性进行组装。如果是更加专业的说法,则是使用长短时记忆网络(LSTM)或变换器(Transformer)等深度学习模型,对上下文进行建模,并预测下一个单词或单词序列的概率分布。
概率如何来
我们想象一个场景,以“猫是”为开头,来拼接一个句子。这里展示一个n-gram(注意ChatGPT不是使用该算法)算法的JavaScript例子:
// 定义n-gram模型的参数
const n = 2; // n-gram的n值
const data = ['猫', '是', '小', '动', '物', '之', '一', '。', '狗', '也', '是', '小', '动', '物', '之', '一', '。', '喵', '喵', '是', '猫', '发', '出', '的', '声', '音', '。', '汪', '汪', '是', '狗', '发', '出', '的', '声', '音', '。']; // 语料库
// 定义生成下一个单词的函数
function generateNextWord(prefix, model) {
const candidates = model[prefix];
if (!candidates) {
return null;
}
const total = candidates.reduce((acc, cur) => acc + cur.count, 0);
let r = Math.random() * total;
for (let i = 0; i < candidates.length; i++) {
r -= candidates[i].count;
if (r <= 0) {
return candidates[i].word;
}
}
return null;
}
// 定义生成句子的函数
function generateSentence(prefix, model, maxLength) {
let sentence = prefix;
while (true) {
const next = generateNextWord(prefix, model);
if (!next || sentence.length >= maxLength) {
break;
}
sentence += next;
prefix = sentence.slice(-n);
}
return sentence;
}
// 训练n-gram模型
const model = {};
for (let i = 0; i < data.length - n; i++) {
const prefix = data.slice(i, i + n).join('');
const suffix = data[i + n];
if (!model[prefix]) {
model[prefix] = [];
}
const candidates = model[prefix];
const existing = candidates.find(candidate => candidate.word === suffix);
if (existing) {
existing.count++;
} else {
candidates.push({ word: suffix, count: 1 });
}
}
// 使用示例
const prefix = '猫是';
const maxLength = 10;
const sentence = generateSentence(prefix, model, maxLength);
console.log(sentence); // 输出 "猫是小动物之一。"
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
这个例子里每次都是返回固定的结果,但是如果n-gram列表足够长,就可以带有一定的随机性。所以这个时候就需要大语言模型来提供足够的语料库了
大语言模型
大语言模型(如GPT-3)可以被认为是一种机器学习模型,基于深度学习技术的神经网络而来,因此可以将其视为神经网络模型的一种。具体来说,大语言模型是使用无监督学习方法进行训练的,它利用大量的文本数据集进行学习,从而在自然语言处理任务中表现出色。
机器学习模型一般分为以下几类:
1、线性回归模型:用于预测连续变量的值,例如房价的预测等。
2、逻辑回归模型:用于分类问题,例如垃圾邮件分类等。
3、决策树模型:用于分类和回归问题,可以自动找出数据中的决策规则。
4、随机森林模型:基于多个决策树的集成学习模型,用于分类和回归问题。
5、支持向量机模型:用于分类和回归问题,在高维空间中寻找最优超平面。
6、神经网络模型:用于图像识别、自然语言处理、语音识别等复杂任务的处理。
7、聚类模型:用于将数据分为不同的类别,例如K均值聚类等。
8、强化学习模型:用于智能决策和控制问题,例如自主驾驶车辆的控制等。
那么大模型是什么来的呢?
大模型通常是在神经网络算法中训练而来的,因为神经网络算法可以很好地处理大量的参数和复杂的结构。然而,神经网络算法在处理自然语言处理、计算机视觉和语音识别等任务时表现优异,因此在这些领域中大模型通常是基于神经网络算法训练而来的。当然,除了神经网络模型,还包括了一些其他的技术,如自回归模型、自编码器模型等,这里就不重点介绍了。
什么又是神经网络?
开头提到过:神经网络是一种模仿人类神经系统的机器学习算法。
神经网络的结构可以类比于图这种数据结构。在神经网络中,每个节点(神经元)可以看作是图中的节点,每条连接(权重)可以看作是图中的边,整个网络可以看作是一个有向图。
类比于图结构,神经网络的优化就是在调整连接权重的过程中,使得整个网络可以更好地拟合训练数据,从而提高模型的性能。同时,神经网络的预测过程可以看作是在图中进行信息传递的过程,从输入层到输出层的传递过程就相当于在图中进行一次遍历。
这里还是以JavaScript举个例子:
// 定义神经网络结构
const inputSize = 3;
const hiddenSize = 4;
const outputSize = 2;
// 定义神经网络参数
const weights1 = [
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12]
];
const bias1 = [1, 2, 3, 4];
const weights2 = [
[1, 2],
[3, 4],
[5, 6],
[7, 8]
];
const bias2 = [1, 2];
// 定义激活函数
function sigmoid(x) {
return 1 / (1 + Math.exp(-x));
}
// 定义前馈神经网络函数
function feedForward(input) {
// 计算第一层输出
const hidden = [];
for (let i = 0; i < hiddenSize; i++) {
let sum = 0;
for (let j = 0; j < inputSize; j++) {
sum += input[j] * weights1[j][i];
}
hidden.push(sigmoid(sum + bias1[i]));
}
// 计算第二层输出
const output = [];
for (let i = 0; i < outputSize; i++) {
let sum = 0;
for (let j = 0; j < hiddenSize; j++) {
sum += hidden[j] * weights2[j][i];
}
output.push(sigmoid(sum + bias2[i]));
}
return output;
}
// 使用示例
const input = [1, 2, 3];
const output = feedForward(input);
console.log(output); // 输出 [0.939, 0.985]
神经网络的输出结果可以被解释为对不同类别的概率估计。在这个示例中,神经网络的输出是一个包含两个元素的向量,这两个元素分别表示输入属于两个类别的概率估计值。因此,这个前馈神经网络可以用来进行二分类任务。
类似地,像ChatGPT这样的语言生成模型也可以被解释为对不同单词或单词序列的概率估计。在ChatGPT中,当我们输入一段文本时,模型会根据已有的文本上下文来预测下一个单词或单词序列的概率分布,并从中选择概率最高的单词或单词序列作为输出。因此,ChatGPT中的输出结果也可以被解释为对不同单词或单词序列的概率估计。
经过这个流程,就可以理解ChatGPT是如何得出回答的文案的了。
ChatGPT怎么知道你问的什么?
前面提到了答案是如何一个词一个词生成的,那ChatGPT又是怎么知道你问的什么呢?ChatGPT 使用自然语言处理技术和深度学习算法对用户的输入进行语义分析和意图识别,以更好地理解用户的意图和需求。然后,ChatGPT 可以通过对话历史和上下文信息等因素进行分析,ChatGPT 根据预测的概率分布随机选择一个单词作为下一个单词,然后将该单词加入到生成的回答中。
由于采用的是概率性的组装单词的方法,因此 ChatGPT 生成的回答可能会出现一些语法或语义上的错误。为了提高回答的质量,可以采用一些技巧,如使用束搜索(Beam Search)方法、加入语言模型的惩罚项(如长度惩罚、重复惩罚等)等。这些技巧可以有效地减少生成回答中的错误,提高回答的质量。
总结
以上就是生成式AI的基本工作原理,通过深度学习算法处理大量的文本数据,从而学习语言的语法和语义规律,并能够自动生成符合语法和语义的文本。在生成文本时,生成式AI会基于上下文信息生成一个语言模型,然后利用随机采样或贪心搜索方法生成文本序列。
-
神经网络
+关注
关注
42文章
4789浏览量
101591 -
AI
+关注
关注
87文章
32421浏览量
271586 -
人工智能
+关注
关注
1800文章
48078浏览量
242135 -
ChatGPT
+关注
关注
29文章
1578浏览量
8284
发布评论请先 登录
相关推荐
【国产FPGA+OMAPL138开发板体验】(原创)6.FPGA连接ChatGPT 4
在FPGA设计中是否可以应用ChatGPT生成想要的程序呢

写给小白们的FPGA入门设计实验
科技大厂竞逐AIGC,中国的ChatGPT在哪?
ChatGPT系统开发AI人功智能方案
AI 人工智能的未来在哪?
写给小白们的FPGA入门设计实验

ChatGPT对AI行业有何影响?
在ChatGPT风口上,AI的机遇与泡沫同在
ChatGPT原理 ChatGPT模型训练 chatgpt注册流程相关简介
chatGPT和ai有什么区别 ChatGPT的发展过程
写给小白的AI入门科普






 工商网监
工商网监
评论