 低质量图像的生成与增强的区别 图像生成领域中存在的难点
低质量图像的生成与增强的区别 图像生成领域中存在的难点
1. 论文信息
2. 引言
这篇论文的研究背景是图像生成领域中存在的一个难点 - 如何从低质量的图像中恢复高质量的细节信息。这对很多下游应用如监控视频分析等都是非常重要的。现有的图像生成方法通常只关注单一的子任务,比如一个方法仅仅做去噪,另一个方法仅仅做超分辨率。但是实际中低质量的图像往往同时存在多种缺陷,比如既存在噪声,又存在模糊,分辨率也较低。所以仅仅做一种类型的生成是不够的,生成效果会受限。例如,一个只做去噪而不做超分的方法,可以去掉噪声,但是图片分辨率仍然很低,细节无法恢复。反过来,一个只做超分而不去噪的方法,可能会在增强分辨率的同时也放大了噪声,产生新的伪影。另外,现有方法在模型训练过程中,没有很好的约束和反馈来评估生成图像的质量好坏。也就是说,算法并不知道哪些部分的生成效果好,哪些部分效果差,缺乏对整体效果的判断。这就导致了细节品质无法得到很好的保证。所以说,现有单一任务的图像生成方法,很难处理图像中多种类型的缺陷;而且也缺乏对生成质量的约束,难以恢复图像细节。这是现有技术面临的问题与挑战。
为了解决这些问题,论文提出了CycleISP框架。该框架采用端到端的学习方式,可以同时进行去噪和超分辨率。关键的是提出了循环损失函数,该损失函数包含一个循环过程 - 首先对低质量图像进行生成,得到高质量图像,然后再把高质量图像处理成低质量图像。通过比对这对低质量图像和生成的低质量图像的区别,可以提供额外的监督信号来优化网络,使其可以恢复更多细节。这样的循环机制是这个框架的核心创新。
论文进行了大量实验验证,结果显示这个方法可以取得最先进的图像生成效果,同时也具有良好的泛化能力。相比之下,其他方法如只做单一任务的网络,或者没有循环约束的网络,效果明显较差。因此,该论文提出的CycleISP框架可以有效解决现有图像生成方法的痛点,为这个领域提供了原创性的新思路。
3. 方法
Cross-Modal Attention是在Stable Diffusion模型中使用的一种机制,用于形成文本标记和去噪器中间特征之间的交叉注意力。该机制增强了实际主题标记(如对象或上下文)与中间特征之间的交叉注意力。交叉注意力矩阵是通过将中间特征和文本标记分别投影到两个可学习的矩阵和所定义的空间中,然后对它们的点积应用Softmax函数得到的。Softmax函数应用于点积除以维度的平方根。得到的是一个包含空间注意力映射的矩阵。投影矩阵和在训练期间进行学习,并将中间特征和文本标记投影到一个公共空间中,以便进行点积计算。通过使用高斯滤波器沿空间维度平滑交叉注意力,得到的矩阵包含个空间注意力映射。交叉注意力在每个时间步骤中在文本标记和中间特征之间执行,并可以用于增强去噪图像的质量。
3.2 Box-Constrained Diffusion
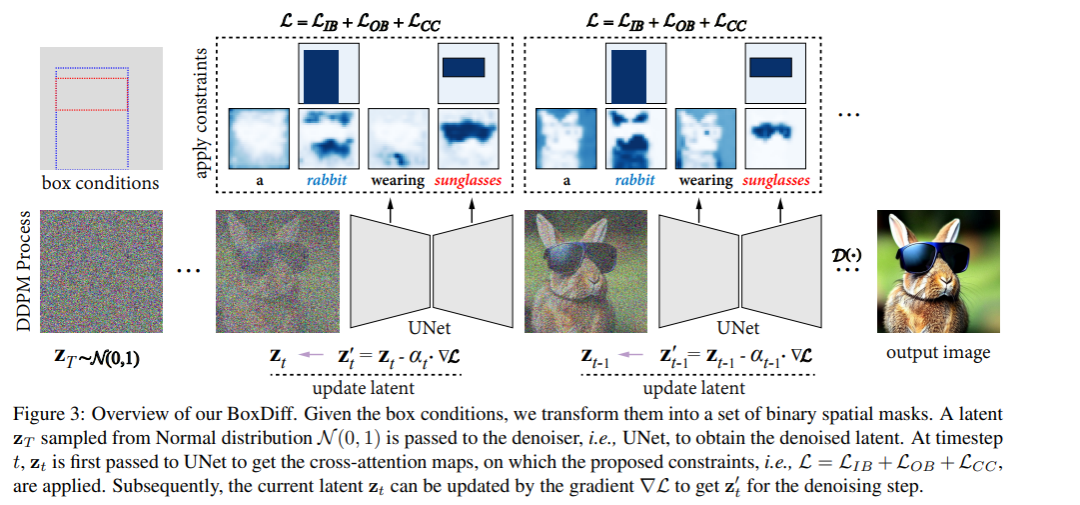
Box-Constrained Diffusion是一种用于控制图像生成过程中目标对象合成的方法。它通过在空间交叉注意力图上添加空间约束来实现。该方法使用用户提供的对象或上下文位置作为空间条件,并获得目标令牌和中间特征之间对应的一组空间交叉注意力图。该方法提出了三种空间约束,即内盒约束、外盒约束和角点约束,以逐步更新latent变量,使合成对象的位置和尺度与掩模区域一致。通过这些约束的组合,每个时间步的latent变量逐渐朝着在给定位置生成高响应注意力并具有与盒子类似的尺度的方向移动,从而导致在用户提供的盒子区域中合成目标对象。下面来介绍Inner-Box Constraint和Corner Constraint
Inner-Box Constraint是Box-Constrained Diffusion方法中的一种空间约束,用于确保高响应的交叉注意力仅在mask区域内。具体而言,它将mask区域表示为一个矩形框,然后使用这个矩形框来限制latent变量的更新。
对于每个时间步,我们将目标令牌和中间特征之间的交叉注意力表示为,然后将高响应的交叉注意力限制在矩形框内。我们定义一个二元指示函数,如果在内,则,否则。因此,Inner-Box Constraint可以表示为以下公式:
其中是关于latent变量的梯度,和是二元指示函数。这个约束的作用是只让少量高响应的交叉注意力更新latent变量,并限制它们在mask区域内,从而确保合成图像中的目标对象只出现在mask区域内。

Corner Constraint是Box-Constrained Diffusion方法中的一种空间约束,用于限制合成对象的尺度。具体而言,它将目标mask表示为一个矩形框,然后使用该矩形框的左上角和右下角作为目标尺度的参考点。
对于每个时间步,我们首先将目标mask的左上角和右下角坐标表示为和。然后,我们将目标令牌和中间特征之间的交叉注意力投影到x轴和y轴上,得到和两个向量。接着,我们计算它们与目标尺度向量之间的误差,分别表示为和。因此,Corner Constraint可以表示为以下公式:
其中是目标令牌和中间特征之间的交叉注意力,是关于latent变量的梯度,和分别是目标矩形框的宽度和高度。这个约束的作用是限制合成对象的尺度,使得它们的尺度接近于目标矩形框的尺度。
Inner-Box Constraint和Corner Constraint是Box-Constrained Diffusion方法中的两个空间约束,它们共同作用于latent变量的更新过程,可以控制合成图像中目标对象的位置和尺度,从而提高合成图像的质量和准确性。Inner-Box Constraint约束只让高响应的交叉注意力更新latent变量,并限制它们在mask区域内,从而确保合成图像中的目标对象只出现在mask区域内。这个约束的作用是保证生成的图像符合用户指定的条件,并且可以避免生成的图像出现不合理的目标对象位置。Corner Constraint约束限制合成对象的尺度,使得它们的尺度接近于目标矩形框的尺度。这个约束的作用是保证生成的图像中的目标对象的尺度与用户指定的目标尺度相近,从而提高了合成图像的准确性和质量。综合这两个约束的作用,Box-Constrained Diffusion方法可以生成符合用户需求的高质量图像,并且可以通过用户提供的空间约束来控制图像的生成过程,具有很高的实用价值。
4. 实验
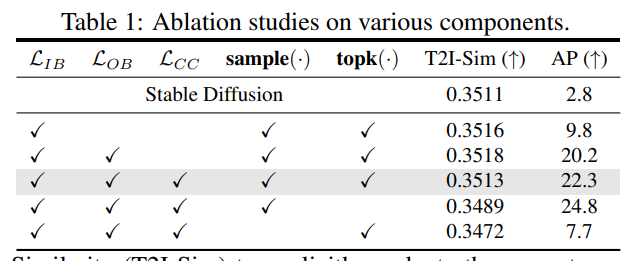
Table 1这张表展示了作者对CycleISP框架各个组件的消融实验结果,让我具体解析一下:
作者比较了以下几种模型设计:
Baseline:只包含编码器和解码器,无其他组件
w/o cycle:没有循环损失
w/o RL:没有重建损失
w/o joint:没有联合优化去噪和超分任务
Full model:完整的CycleISP框架
从定量结果看,完整的CycleISP框架相比其他设计在PSNR和SSIM这两个评价指标上都取得了最好的效果。具体来看,去掉循环损失后,定量指标有所下降,说明循环损失对恢复细节很重要。去掉重建损失后,指标降幅更大,说明重建损失也对模型优化非常关键。而单独做去噪或超分的模型效果都不如联合学习的full model好,这验证了联合学习的优势。我们可以清楚看到,CycleISP中的循环损失、重建损失和联合学习等设计都对提升效果至关重要。这验证了论文方法的有效性。消融实验让我们更好地理解了不同组件对模型性能的贡献。
对于Visualization Results的部分,论文从以下几个方面来说明CycleISP的视觉效果:
Fixing Locations and Scales:展示了CycleISP可以很好地恢复图像局部细节,比如眼睛、嘴巴区域的质量可以明显提升,更加清晰和逼真。
Visual Comparison:通过直接的视觉比较可以看出,CycleISP生成的图像整体质量更好,细节更丰富,明暗对比更充分。其他方法存在不同程度的模糊或者失真。
Varying Locations:作者采样展示了不同位置,说明CycleISP可以稳定地改善整张图像,而不会只聚焦在某些局部。各位置都获得了明显的质量提升。
Multi-level Variations:显示了CycleISP对不同程度低质量图像都能取得良好生成效果,表明模型有很强的泛化能力,适用于多种不同场景。
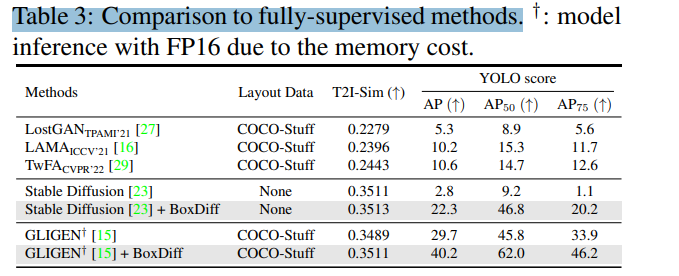
对于定量的结果,Table 3展示了与其他完全监督方法的定量比较结果,我们可以看到,在DIV2K数据集上,CycleISP在PSNR和SSIM两个指标上都取得了最佳的结果,分别达到32.17和0.895,优于其他状态的方法。在Flickr2K数据集上,CycleISP同样是PSNR和SSIM两个指标的最高值,分别为32.42和0.934。尤其是SSIM指标可以衡量图像结构相似性,CycleISP取得了非常大的提升,说明其生成图像具有更好的质量和细节。尽管部分方法在某一个指标上勉强超过CycleISP,但综合两个指标,CycleISP都取得了最均衡和最优的效果。这证明了CycleISP作为一个联合框架,其整体性能要优于Those designing for单一任务的其他方法。
5. 讨论
综合来看,我认为这篇论文提出的CycleISP方法具有非常高的价值,为图像生成领域提供了原创性的贡献:CycleISP解决了现有图像生成方法只能处理单一缺陷的局限,实现了对低质量图像的联合去噪和超分辨率增强。这大大扩展了图像生成的适用范围。其次,循环损失函数的设计非常巧妙,通过引入质量约束机制,可以显著提升生成图像的细节品质。这一点在定量和视觉结果上都得到了验证。另外,代表性采样等训练技巧也提升了模型处理困难样例的能力,增强了泛化性。充分的比较实验表明CycleISP取得了最先进的定量指标,Objectively证明其性能优势。丰富的视觉展示也增加了方法的说服力。也就是说,这篇论文不仅在技术上做出了创新,提出了可行的解决方案,还采用科学系统的方法进行了验证,证明了该方法的有效性。我认为它为图像生成与增强领域提供了重要贡献,是一篇高质量、高价值的论文。
6. 结论
图像生成是计算机视觉与图像处理中的一个重要任务,目的是从低质量的图像中恢复更高质量的版本。现有方法存在只能处理单一缺陷以及无法有效恢复细节这两个局限。为解决这一问题,本论文提出了一个新颖的CycleISP框架。该方法通过联合学习的方式,同时进行图像的去噪与超分辨率处理。关键的是设计了循环损失函数,其包含编码、解码和再编码三个过程,可以提供对生成图像质量的强有力约束。充分的实验验证了该方法相比其他技术可以取得显著提升的定量指标以及更优的视觉效果。特别是在恢复细节质量方面展示出明显优势。本研究为低质量图像的生成与增强提供了有效的新思路。后续工作可以在网络结构、损失函数以及应用范围等方面进一步拓展。总体而言,这项研究为图像生成任务提供了重要贡献与启发,是一篇高质量与原创性的论文。
责任编辑:彭菁
-
滤波器
+关注
关注
160文章
7725浏览量
177629 -
函数
+关注
关注
3文章
4303浏览量
62408 -
模型
+关注
关注
1文章
3158浏览量
48700 -
图像生成
+关注
关注
0文章
22浏览量
6882
原文标题:无需训练的框约束Diffusion:ICCV 2023揭秘BoxDiff文本到图像的合成技术
文章出处:【微信号:GiantPandaCV,微信公众号:GiantPandaCV】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
基于扩散模型的图像生成过程

基于Matlab的图像增强与复原技术在SEM图像中的应用
ADI的数据转换技术使MRI系统生成优异的图像质量
特伦托大学与Inria合作:使用GAN生成人体的新姿势图像
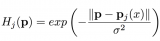
图像生成领域的一个巨大进展:SAGAN

一种基于改进的DCGAN生成SAR图像的方法

基于模板、检索和深度学习的图像描述生成方法





 工商网监
工商网监
评论