 你知道TinyML运行效能谁说了算吗?
你知道TinyML运行效能谁说了算吗?

在AI芯片或神经加速处理器(Neural Network Processing Unit, NPU或Deep Learning Accelerator, DLA)领域中,大家也都说自家的芯片世界最棒,对手看不到车尾灯,难道没有一个较为公正衡量芯片运行(推论)效能,就像手机跑分软件一样,让大家比较信服的基准吗?
其实在AI芯片领域中所谓的「效能」,可能因关心的重点不同而会有不同定义和解读。分别可从硬件每秒可执行乘加的次数(又可细分FP32,FP16及INT8等)、对于特定模型在指定推论精度下每秒可执行次数或推论一次所需时间(包含有无模型优化处理)、特定模型推论功耗(推论一次耗费焦耳数)、每瓦特可执行乘加指令次数及其它特定规范时的表现,甚至有用每块美金获得算力来当成基准。所以常会遇到谁也不服谁,老王卖瓜自卖自夸的现象。
目前较被大家接受的就是ML Commons所提出的MLPerf规范,其中包含训练及推论两大项,而推论部份又可细分为数据中心(Datacenter)、边缘(Edge)、行动(Mobile)及微型(Tiny,大多为MCU)。前不久(2023/6/27)才刚公布了Tiny v1.1测试结果报告,接下来就帮大家解读一下这份报告,让大家能更了解未来单芯片运行AI的方向及可行性。
评测场景及项目
目前ML Commons在Tiny部份先前已经过三轮(v0.5, v0.7, v1.0)测试,此次公布的是v1.1结果。测试时分为封闭(Closed)及开放(Open)型式,前者依官方规范测,而后者厂商可提出依自己规范测试更优的结果,不过不是每轮评测都会有开放型式。
目前主要评测项目如Fig.1 所示,共有四个项目,包含关键词侦测(Keyword Spoting, KS)、视觉唤醒字(Visual Wake Words, VW)、影像分类(Image Classification, IC)及异常侦测(Anomaly Detection, AD)。而每个项目都是采单串流数据(Single Stream)方式进行,即推论完一笔再取下一笔进行推论。依照不同项目,分别使用对应的数据集和模型,并在指定的推论质量下进行评量。
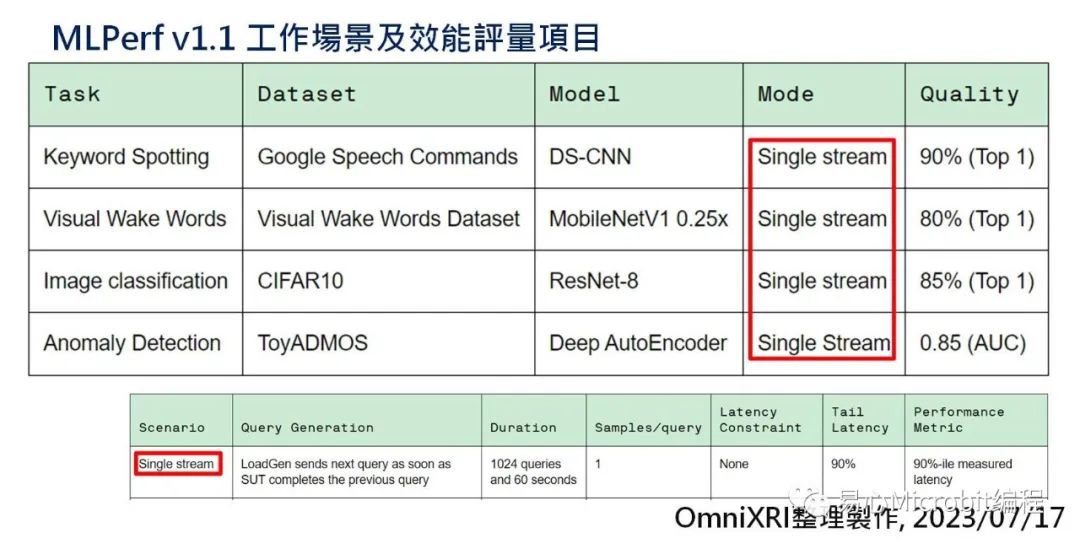
Fig.1 MLPerf v1.1 工作场景及效能评量项目
参与评测公司、硬件及软件
本次参与评测的项目共有32项,以下依不同项目分别介绍。
参与评测公司:共有10家,Krai, Nuvoton(新唐科技), STMicroelectronics(简称STM), Skymizer(台湾发展软件科技), cTuning, fpgaconvnet, Plumerai, Syntiant, Robert Bosh GmbH, kai-jiang(个人)。
参与评测开发板:共有14种,规格下如下所示。
STM NUCLEO-H7A3ZI-Q, Arm Cortex-M7(DSP+FPU) @280MHz
STM NUCLEO-L4R5ZI, Arm Cortex-M4(DSP+FPU) @120MHz
STM NUCLEO-U575ZI-Q, Arm Cortex-M33(DSP+FPU) @160MHz
STM NUCLEO-G0B1RE, Arm Cortex-M0+ @64MHz
STM DISCO-F746NG, Arm Cortex-M7(DSP+FPU) @216MHz
Nordic nRF5340 DK, Arm Cortex-M33(DSP+FPU) @128MHz
Nuvoton NUMAKER-M467HJ, Arm Cortex-M4F @200MHz
DIGILENT Cora Z7, Arm Cortex-A9 @667MHz
DIGILENT ZC706, Arm Cortex-A9 @650MHz
DIGILENT ZedBoard, Arm Cortex-A9 @650MHz
DIGILENT ZyBo, Arm Cortex-A9 @650MHz
Infineon CY8CPROTO-062-4343W, Arm Cortex-M4 (DSP + FPU) @150MHz
Syntiant NDP9120, HiFi3+M0 @30.7MHz/98.7MHz
ZCU106, RISC-V @20MHz
主要CPU规格:共有7大类。只有1项使用RISC-V,1项为MCU+NPU,其余皆是Arm Based。Cortex-M为单芯片(MCU)等级,Cortex-A为微处理器(MPU)等级芯片,用于手机或单板微电脑。
Arm Cortex-M0+ (1项)
Arm Cortex-M33 (4项)
Arm Cortex-M4/M4F (13项)
Arm Cortex-M7 (7项)
Arm Cortex-A9 (4项)
Syntiant HiFi3+M0 (2项)
RISC-V (1项)
主要软件及函式库:共有9种。
Skymizer ONNC
MicroTVM
Plumerai Inference Engine
Bosch Hardware-Aware Lowering Engine(HALE)
STM X-CUBE-AI
fpgaConvNet(Model+Optimiser)
Arm CMSIS-5
TVM
评测结果:
由于芯片等级落差颇大,单从推论时间(毫秒ms)及能耗(微焦耳uJ 比较可能会有点不公平,所以这里依CPU等级及工作频率来分会更清楚些。Fig. 2分别列出各等级中推论速度表现最好的。
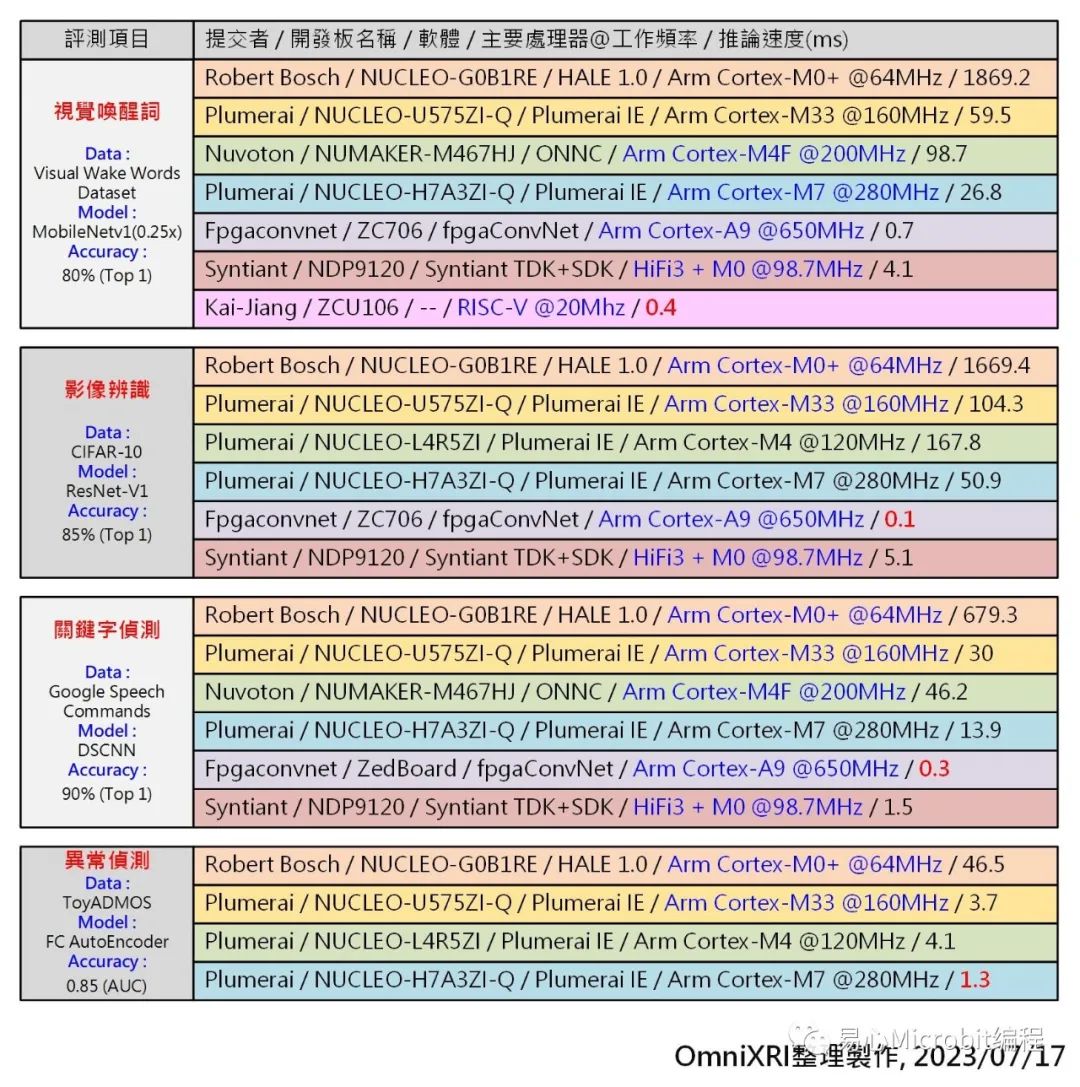
Fig.2 MLPerf Tiny v1.1各等级CPU及不同应用表现最佳清单。
另外从此次提交的项目亦可看出Arm Cortex-M4已成为TinyML的主流,若推论仍不够快时,则可再提升到Cortex-M7。而新上市的Cortex-M33效能已高过Cortex-M4,略低于Cortex-M7,让使用者有多一点性价比的选择空间。
小结
在边缘智能(Edge AI)装置及智能物联网(AIoT)应用中使用单芯片(MCU)来运行AI(TinyML)已是现在进行式,透过此次的评比结果,可让大家更了解各家芯片性能及模型优化工具的进展,未来随着MCU+NPU的普及,相信下一次的评比结果可能就有更大跃升,就让大家一起期待吧!
审核编辑:刘清
-
ARM处理器
+关注
关注
6文章
361浏览量
43416 -
MPU
+关注
关注
0文章
465浏览量
51629 -
Cortex-M4
+关注
关注
6文章
100浏览量
48723 -
加速处理器
+关注
关注
0文章
8浏览量
6556 -
AI芯片
+关注
关注
17文章
2181浏览量
36883
原文标题:TinyML (MCU AI) 运行效能谁说了算?
文章出处:【微信号:易心Microbit编程,微信公众号:易心Microbit编程】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
你知道电子工程师,到底分几种吗?

工商业光伏储能并网防逆流,安科瑞一站式解决方案来了!

【迅为iTOP-Hi3403开发板】一站式启动Hi3403 NPU开发:从运行例程开始,快速验证AI效能

[工具讨论] 如果有一款国产图形化配置工具STM32Cube,支持所有内核和厂商MCU,你会用吗?
具身机器人走得稳不稳?它可以说了算!


从CPU、GPU到NPU,美格智能持续优化异构算力计算效能

钙钛矿电池稳定性评估谁说了算?实验室间比对表明:测量方法是关键

低功耗蓝牙定位模块

基于米尔瑞芯微RK3576开发板部署运行TinyMaix:超轻量级推理框架
高能工控主板:算力强、运行快、多扩展、场景广
这次你说了算!先楫半导体开发者生态技术日
这次你说了算!先楫半导体开发者生态技术日规划中,调查问卷等你来填
你知道船用变压器有哪些吗?




评论