 日增320TB数据,从ClickHouse迁移至ByConity后,查询性能十分稳定!
日增320TB数据,从ClickHouse迁移至ByConity后,查询性能十分稳定!
背景介绍
ByConity适合多种业务场景,在实时数据接入、大宽表聚合查询、海量数据下复杂分析计算、多表关联查询场景下有非常好的性能。我们用一个实际的业务场景来介绍下,这套行为分析系统是基于用户多维度行为分析平台,提供事件分析、留存分析、转化分析、用户分群、用户留存等多种分析方式和场景。本文将介绍下该用户多维度行为分析平台在使用原ClickHouse集群遇到的问题和挑战,以及通过迁移ByConity后如何解决这些问题并给业务带来的收益。
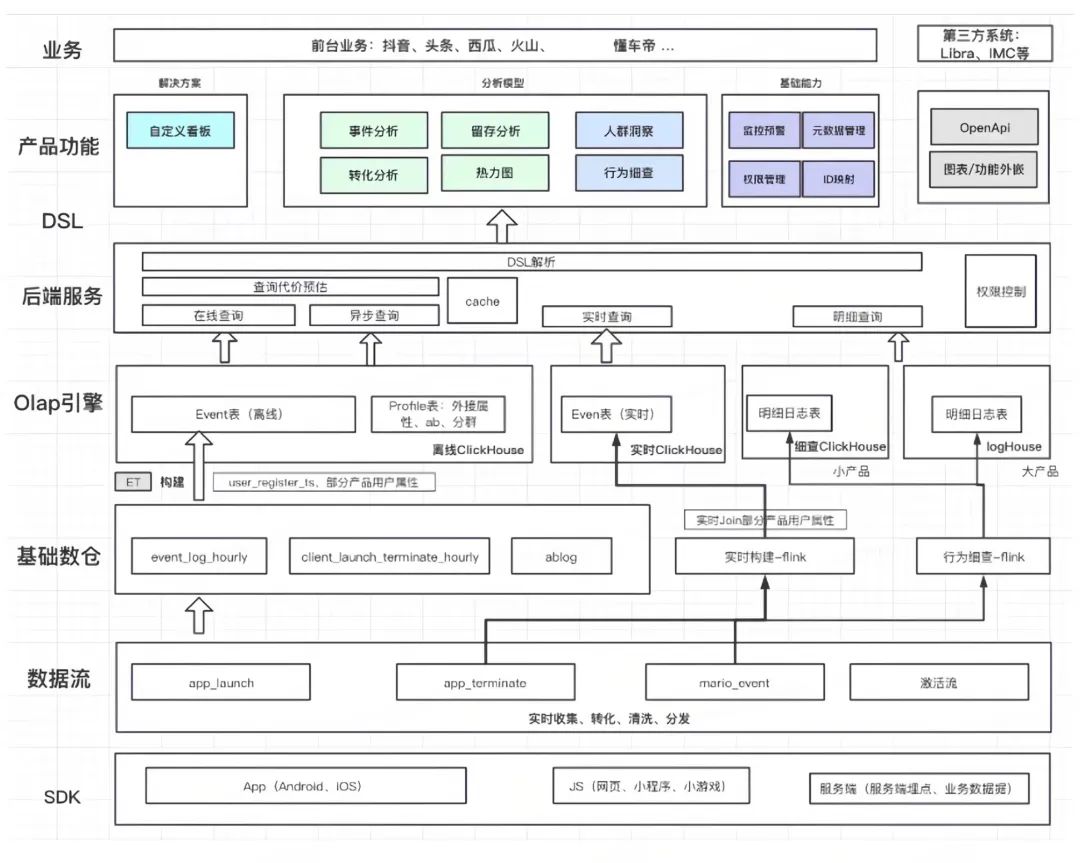
图1 行为分析系统架构设计
问题和挑战
早期这套系统部署在ClickHouse集群,一方面,由于业务的高速发展导致数据量日益膨胀,每日最大新增数据超过320TB,每日新增行数超过2.3万亿条,用户数据维度超过2万多个;另一方面,用户查询需求更加灵活和多样化,需要同时支持明细查询、聚合查询以及交互式分析查询,并快速给出响应结果。此外,在数据量不断增加的情况下(年增长35%),我们既要能支撑这么大的数据增量带来的挑战,又要把成本增速控制在一定范围内。
但是在已有的ClickHouse集群上我们很难做到。原因是ClickHouse是基于Shared-Nothing的架构,每个节点是独立的,不会共享存储资源,因而计算资源和存储资源是紧耦合的,会导致如下问题:
扩缩容成本变高,且会涉及到数据迁移,使我们不能实时按需的扩缩容,而且会导致资源的浪费,成本不可控
紧耦合的架构会导致多租户在共享集群环境相互影响,造成用户查询相互影响
由于集群上节点的读写在同一个节点完成,导致读写相互影响
在复杂查询上例如多表Join等操作的性能支持并不是很好,无法满足用户查询多样化的需求
技术选型
因此在2022年初业务开始使用计算存储分离架构的ByConity来作为主要的OLAP引擎。ByConity是一个开源的云原生数据仓库,它采用计算存储分离的架构,支持多个关键功能特性,如计算存储分离、弹性扩缩容、多租户资源隔离和数据读写的强一致性等。通过利用主流的OLAP引擎优化,如列存储、向量化执行、MPP执行、查询优化等,ByConity可以提供优异的读写性能。
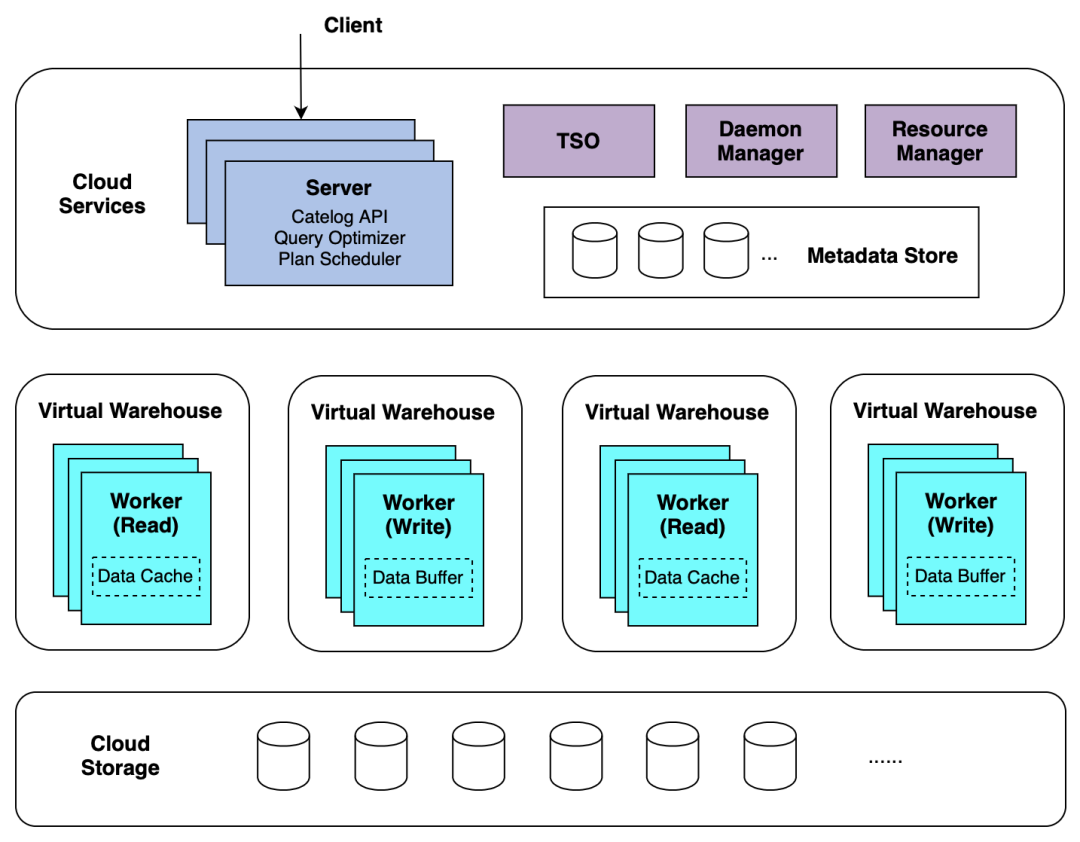
图2 ByConity三层技术架构图
ByConity是在开源的ClickHouse架构基础上进行了升级,引入了计算与存储分离的架构,将原本计算和存储分别在每个节点本地管理的架构,转换为在分布式存储上统一管理整个集群内所有数据的架构,使得每个计算节点成为一个无状态的单纯计算节点,并利用分布式存储的扩展能力和计算节点的无状态特性实现动态的扩缩容。正是由于这种改进,使得ByConity具有以下重要特性:
资源隔离:对不同的租户进行资源的隔离,租户之间不会受到相互影响。
读写分离:计算资源和存储资源解耦,确保读操作和写操作不会相互影响。
弹性扩缩容:支持弹性的扩缩容,能够实时、按需的对计算资源进行扩缩容,保证资源的高效利用。
数据强一致:数据读写的强一致性,确保数据始终是最新的,读写之间没有不一致。
高性能:采用了主流的OLAP引擎优化,例如列存、向量化执行、MPP执行、查询优化等提供优异的读写性能
业务收益
在我们引入了ByConity后,整体性能可以达到91%用户查询都可以在10秒内完成,通过来自用户的反馈调研,这个性能指标也是在用户可接受的范围内。这里总结下我们迁移ByConity带来的总体收益和经验:
避免资源抢占,查询性能百分百稳定:
在原来ClickHouse的集群上,我们经常会遇到资源挤占的问题,由于ClickHouse并没有做到资源隔离和租户隔离,在多个用户共用集群进行查询时,当一个用户查询资源开销非常大,会涉及资源的抢占,导致这个集群上所有共用的用户查询都不稳定,服务质量达不到满足。但在迁移到ByConity后,由于计算组是完全物理隔离,可以达到天然的资源隔离和租户隔离,不同用户的查询相互不受到影响,整体查询性能可以达到91%用户查询都可以在10秒内完成。再者ByConity提供了自研的复杂查询链路,自研 Disk Cache以减少冷数据读取,并对于高频使用的Array 建立索引等,而且热读效率也优于原ClickHouse集群,相比在原Clickhouse集群上性能折损在10%以内。
运维成本低,故障节点秒级替换:
原本在Clickhouse集群上,如果发现集群中某个节点坏掉,需要先下掉整台机器维修,这是因为ClickHouse的计算资源、存储资源、以及元数据信息都在这个节点上,相当于集群少了一个计算资源,也少了一个存储副本,在替换新的节点之前,需要把对坏掉节点的本地磁盘进行备份迁移到新的节点上,维护成本比较高,且数据一致性很难得到保障。而对于ByConity来讲,如果发生计算组坏掉的情况,由于计算组不存储数据,只包含无状态的计算节点,因此只需要替换新的计算组即可,数据的可靠性和一致性由HDFS来保障,且本地热读数据缓存的丢失对业务查询性能是可控的,这部分也主要得益于了ByConity存储和计算分离架构实现。
无感扩缩容,节约资源成本:
ByConity是可以实现无感扩缩容,它是一个模块化和容器化的部署,基于Kubernetes的弹性伸缩能力,如果有足够的机器可以无限的扩容,同时如果服务器发生故障,我们也不用担心,因为ByConity的节点只一个无状态的计算节点,直接下掉对整个集群影响不大。而且通过自适应调度回避慢节点,提升吞吐能力,提高节点资源利用率。同时ByConity的压缩率极高,以其中一个业务为例,每日新增460TB数据,压缩后达到100TB,压缩比达到65%,并支持低基数编码 & ZSTD等等压缩方式,极端情况下存储占用小于parquet。
数据一致性强保障,维护复杂度接近为零:
在迁移到ByConity后,我们完全解决了数据一致性问题,因为ByConity不存在本地的主备同步问题,数据一致性问题直接交给底层的对象存储解决,例如HDFS/S3等。这样对一致性维护的复杂度大大降低,错误概率也更低,目前也少有用户再反馈数据一致性问题。但在之前是经常遇到,因为ClickHouse集群是多个副本通过节点间通信去维护的,通过一致性队列去维护一致性问题,实现上也很复杂,容易出错。另外,ByConity可以通过HDFS直接访问到数据文件,不同计算引擎适配不同连接器,即可读入数据,具备通用能力。
未来展望
通过长达一年半的实践摸索,ByConity已经成为内部使用的主要OLAP引擎,后期会有大量的用户和数据迁入,最终取代原本的ClickHouse集群。可以看出ByConity作为一款计算存储分离的OLAP引擎,具有高性能、高可扩展性和高稳定性等优点,能够满足大规模体量的数据处理和分析的需求。
通过在社区的交流以及社区发布的 Roadmap 讨论
https://github.com/ByConity/ByConity/issues/26
未来阶段ByConity会主要聚焦在以下几个方向:
支持执行层的多Stage执行、ETL能力等
支持数据湖联邦查询如Hudi、Iceberg等
ByConity社区拥有大量的用户,同时是一个非常开放的社区,我们邀请大家和我们一起在Github上讨论共建,也可以加入我们的微信群、飞书群或者Discord参与交流。
-
数据
+关注
关注
8文章
7217浏览量
89915 -
存储
+关注
关注
13文章
4382浏览量
86289 -
计算
+关注
关注
2文章
452浏览量
38904
原文标题:日增320TB数据,从ClickHouse迁移至ByConity后,查询性能十分稳定!
文章出处:【微信号:AI前线,微信公众号:AI前线】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
云数据库SQL Server 2008 R2版推出OSS版本数据上云
Centos7下如何搭建ClickHouse列式存储数据库
轻松上云系列之二:其他云数据迁移至阿里云
火山引擎:ClickHouse增强计划之“多表关联查询”
如何将器件库迁移至DigiPCBA
如何使用原生ClickHouse函数和表引擎在两个数据库之间迁移数据
资深开发者眼中的开源云原生数仓 ByConity
ClickHouse内幕(3)基于索引的查询优化
从TMS320DM6467迁移到TMS320DM6467T

从TMS320DM642迁移至TMS320DM648/DM6437
从TMS320VC5509迁移到TMS320VC5509A





 工商网监
工商网监
评论