 使用 Vision Transformer 和 NVIDIA TAO,提高视觉 AI 应用的准确性和鲁棒性
使用 Vision Transformer 和 NVIDIA TAO,提高视觉 AI 应用的准确性和鲁棒性
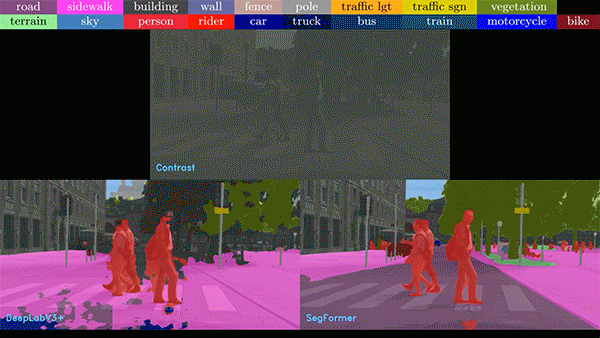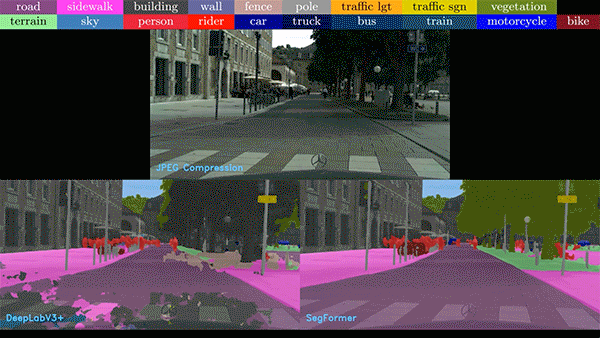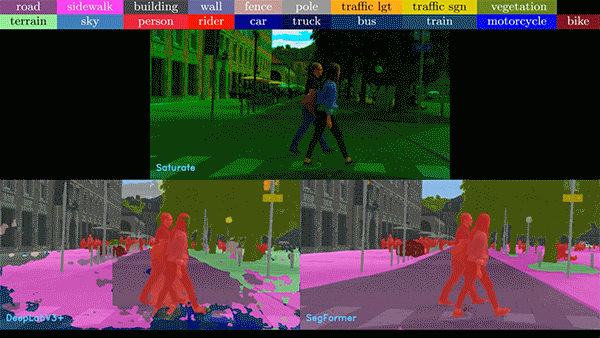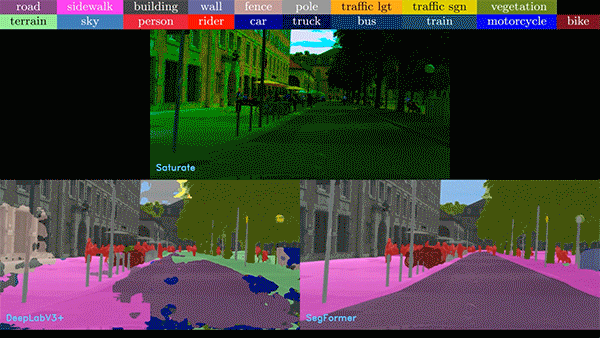
Vision Transformer(ViT)正在席卷计算机视觉领域,提供令人难以置信的准确性、复杂现实场景下强大的解决方案,以及显著提升的泛化能力。这些算法对于推动计算机视觉应用的发展发挥了关键作用,而 NVIDIA 则通过 NVIDIA TAO Toolkit 和 NVIDIA L4 GPU,使应用集成ViT 变得轻而易举。
ViT 的不同之处
ViT 是一种将原本用于自然语言处理的 Transformer 架构应用于视觉数据的机器学习模型。相比基于 CNN 的同类模型具有一些优势,并能够并行处理大规模输入的数据。CNN 采用的是局部操作,因而缺乏对图像的全局理解;而 ViT 则以并行和基于自注意的方式来有效地处理图像,使得所有图像块之间能够相交互,从而提供了长程依赖和全局上下文的能力。
图 1 展示了 ViT 模型中的图像处理流程。输入图像被分为较小的固定尺寸的图块,之后这些图块被展平并转换为一系列的标记 (tokens) 。这些标记连同位置编码一起被输入到 Transformer 编码器中,该编码器由多个自注意力和前馈神经网络组成。
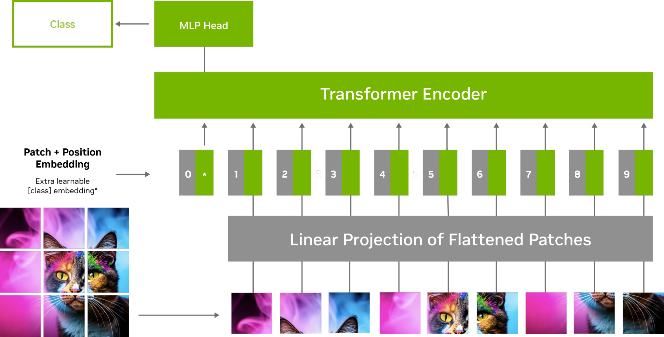
图 1. 包含位置编码器和编码器的 ViT 模型处理图像
通过自注意力机制,每个标记或图块与其他标记进行交互,以决定哪些标记是重要的。这有助于模型捕捉标记之间的关系和依赖,并学习哪些标记是更重要的。
例如在有一只鸟的图像中,模型会更关注重要的特征,比如眼睛、鸟嘴和羽毛等,而不是背景。这使得训练更加高效,增强了对图像损坏和噪声情况的鲁棒性,并在未见过的物体上表现出更优越的泛化能力。
为何 ViT 对计算机
视觉应用至关重要
真实世界的环境具有多样且复杂的视觉模式。与 CNN 不同,ViT 凭借自身的可扩展性和适应性,能够处理各种任务,而且无需针对具体的任务调整架构。

图 2. 各种不完美和嘈杂的
现实数据给图像分析带来了难题
在下面的视频中,我们比较了基于 CNN 和 ViT 的模型的噪声视频。在任何情况下,ViT 模型表现都优于 CNN 模型。
视频 1. 了解 SegFormer,这是一个
结合高效率和稳健语义分割能力的 ViT 模型
将 ViT 与 TAO Toolkit 5.0 集成
TAO 是一个低代码 AI 工具包,用于构建和加速视觉 AI 模型,可用于轻松地构建和集成 ViT 到应用和 AI 工作流程中。用户可以通过简单的界面和配置文件快速开始训练 ViT,无需深入了解模型架构。
TAO Toolkit 5.0 提供几种常用于计算机视觉任务的先进 ViT,包括:
全注意力网络(FAN)
FAN 是由 NVIDIA 研究团队开发的一系列基于 Transformer 架构的神经网络主干模型。该系列模型在对抗各种干扰方面达到了当前技术水平的最佳程度,如表格 1 所示。这些主干模型能够轻松适应新的领域,对抗噪声和模糊。表格 1 展示了所有 FAN 模型在 ImageNet-1K 数据集上所达到的准确率,无论是干净版本还是经过干扰处理后的版本。
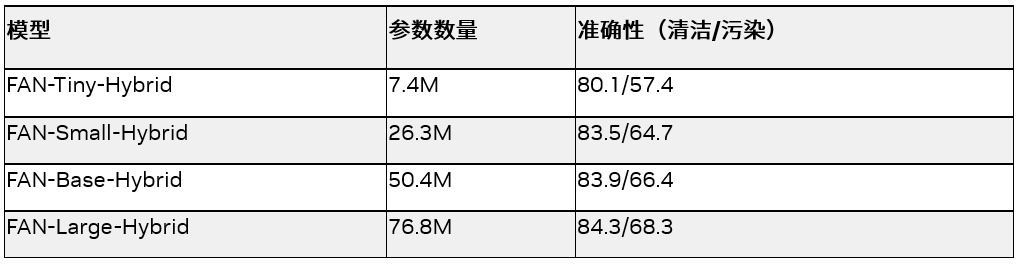
表 1. FAN 模型的大小和准确性
全局上下文 Vision Transformer (GC-ViT)
GC-ViT 是 NVIDIA 研究部门开发的一种具有极高准确性和计算效率的新型架构。该架构解决了 Vision Transformer 中缺乏归纳偏置的问题。通过使用局部自注意力机制,GC-ViT 在参数较少的情况下在 ImageNet 上取得更好的结果,同时结合全局自注意力,可以实现更好的局部和全局空间交互。
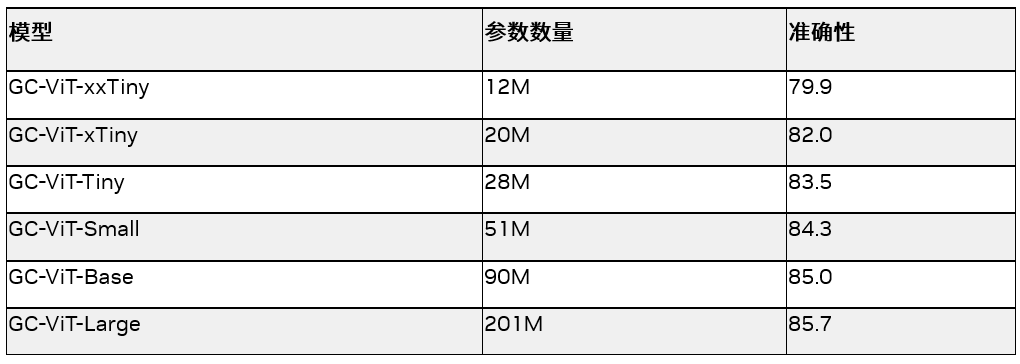
表 2. GC-ViT 模型的大小和准确性
带有改进后去噪锚框的检测 Transformer(DINO)
DINO 是最新一代的检测变换器(DETR),其训练收敛速度比其他 ViT 和 CNN 更快。在 TAO 工具套件中,DINO 十分灵活,可以与传统 CNN(例如 ResNets)和基于 Transformer 的骨干网络(如 FAN)和 GC-ViT 等相结合。
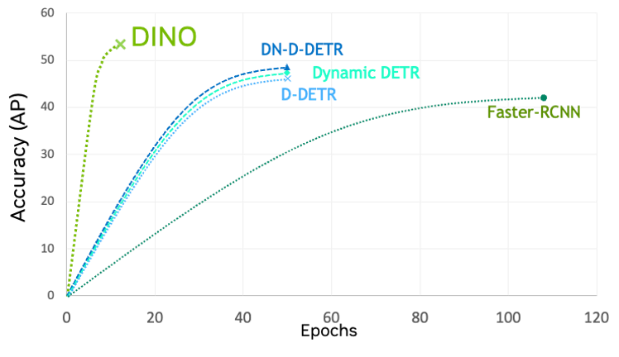
图 3. DINO 与其他模型的准确性比较
Segformer
Segformer 是一个轻量级且具有鲁棒性的基于 Transformer 的语义分割模型。其解码器由轻量级的多头感知层组成。它避免使用大多 Transformer 使用的位置编码,可在不同分辨率下进行高效推理。
使用 NVIDIA L4 GPU
高效驱动 Transformer
NVIDIA L4 GPU 是为未来的视觉 AI 工作负载而打造的。它们采用 NVIDIA Ada Lovelace 架构,旨在加速具有变革性的 AI 技术。
L4 GPU 拥有高达 FP8 485 TFLOPs 的计算能力,适于运行 ViT 工作负载。相较更高精度的计算方式,FP8 的低精度计算可以减轻内存压力,还可以显著提升 AI 的处理速度。
L4 是一款多功能、节能高效的设备,具有单槽、低调的外形,非常适合用于视觉 AI 部署(包括在边缘位置)。
您可以观看Metropolis Developer Meetup(https://info.nvidia.com/metropolis-meetup-june2023.html),了解有关 ViT、NVIDIA TAO Toolkit 5.0 以及 L4 GPU 的更多信息。
点击“阅读原文”,或扫描下方海报二维码,在 8 月 8日聆听NVIDIA 创始人兼 CEO 黄仁勋在 SIGGRAPH 现场发表的 NVIDIA 主题演讲,了解 NVIDIA 的新技术,包括屡获殊荣的研究,OpenUSD 开发,以及最新的 AI 内容创作解决方案。
原文标题:使用 Vision Transformer 和 NVIDIA TAO,提高视觉 AI 应用的准确性和鲁棒性
文章出处:【微信公众号:NVIDIA英伟达】欢迎添加关注!文章转载请注明出处。
-
英伟达
+关注
关注
22文章
3894浏览量
92713
原文标题:使用 Vision Transformer 和 NVIDIA TAO,提高视觉 AI 应用的准确性和鲁棒性
文章出处:【微信号:NVIDIA_China,微信公众号:NVIDIA英伟达】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
如何使用POT准确性检查器?
VirtualLab Fusion应用:光栅的鲁棒性分析与优化
自动驾驶中常提的鲁棒性是个啥?





 工商网监
工商网监
评论