 为什么Uber的底层存储从Postgres换成MySQL了呢?
为什么Uber的底层存储从Postgres换成MySQL了呢?
来源:www.infoq.cn/article/underlying -storage-of-uber-change-from-mysql -to-postgres
背景
早期的 Uber 后台软件由 Python 写成,数据存储使用 Postgres。后期随着业务的飞速发展后台架构也变化巨大,演进成了微服务加数据平台。数据存储也由 Postgres 变成了 Schemalesshttps://eng.uber.com/schemaless-part-one/——Uber 自主研发的以 MySQL 做为底层的高可用数据库。Uber 的数据库主要存储的是 Trip 数据,就是一个叫车订单从下单起,到上车、下车、付费等的全过程跟踪及处理。从 2014 年初起,由于业务增长迅猛,Uber 的原有基础架构已经无法继续支撑业务。改进的项目花了将近一年时间。
对于新的数据库存储系统,Uber 的主要关键需求是:
要有能力通过增加服务器而线性地增加容量。增加服务器不但要增加可用的硬盘容量,还要减少系统的响应时间。
需要有写缓冲能力,万一持久化到数据库失败时,仍可以稍后重试。
需要通知下游依赖关系的方式,数据变更要能无损的通知出去。
需要二级索引。
系统要足够健壮,可以支持 7*24 服务。
在调查对比了 Cassandra、Riak 和 MongoDB 等等之后,Uber 技术团队没有发现能完全满足需求的现成解决方案。而再考虑到数据可靠性、对技术的把握能力等因素,他们决定自己开发一套数据库管理系统——Schemaless,一个键值型存储库,可以存放 JSON 数据而无需严格的模式验证,是完全的无模式风格。用 MySQL 作底层存储,其中只有顺序写入,在 MySQL 主库故障时支持写入缓冲。并有一个数据变更通知的发布 - 订阅功能(命名为 trigger),支持数据的全局索引。
Schemaless 的强大与简单更多是因为我们在存储节点中使用了 MySQL。Schemaless 本身是在 MySQL 之上相对较薄的一层,负责将路由请求发送给正确的数据库。借助于 MySQL 第二索引及 InnoDB 的 BufferPool,Schemaless 的查询性能很高。
写入效率不高
数据主从复制效率不高
表损坏问题
难于升级到新版本
在 Postgres 的底层设计中,它的行数据是不可修改的,每个不可修改的行都叫做“元组”,每个唯一的元组都由一个唯一的 标志,ctid 也就实际指出了这个元组在磁盘上的物理偏移量。这样对于一行修改过的数据来说,就会对应着在物理上有多个元组。表是有索引的,主键索引和第二索引都以 B 树组织,都直接指向 ctid。
除了 ctid 之外还有一个关键字段 prev,它的默认值为 null,但对于有数据修改的记录,新的元组里面的 prev 字段里存储的就是旧元组的 ctid 值。
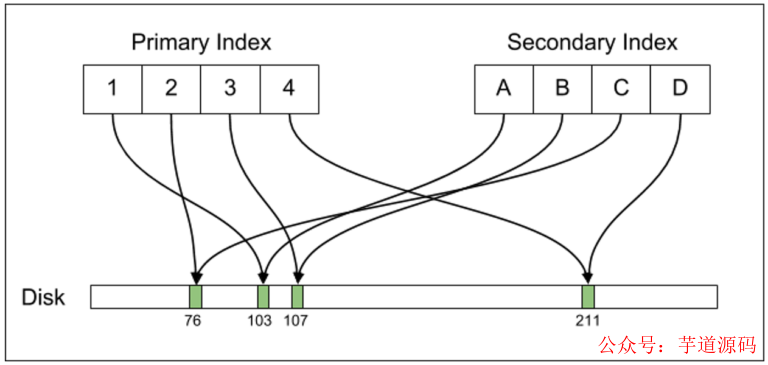
与 Postgres 相对应的是,MySQL 的 InnoDB 引擎主键索引和第二也都以 B 树组织,但是索引指向的是主键,而主键才真正指向数据记录。而且,InnoDB 的数据是可以修改的。两者实现 MVCC 的机制不同,MySQL 依靠 UNDO 空间中的回滚段,而不是象Postgres 依靠在数据表空间对同一条数据保持多份。
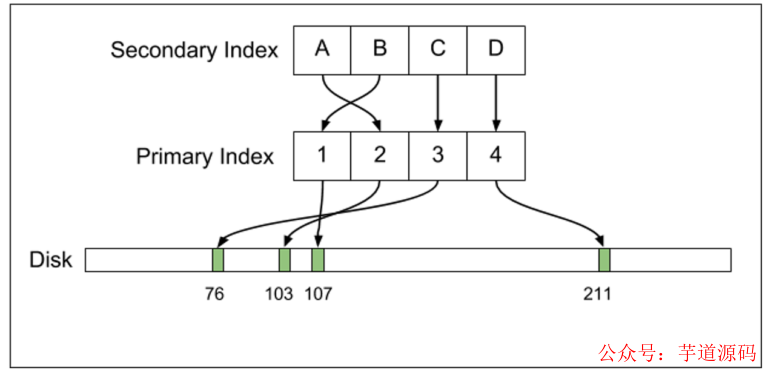
Postgres 和 InnoDB 都通过 WAL来保证数据可以在数据库上安全写入,但对于主从库的数据复制实现原理并不同。Postgres 会直接把 WAL 发送到从库上,让从库也执行 WAL 来复制数据。而 MySQL 则是发送 Binlog,在从库上应用 Binlog。
由此,再来看看 Uber 对于 Postgres 有哪些不满意:
写放大
一般来说大家介意写放大https://en.wikipedia.org/wiki/Write_amplification的问题是由于对SSD 磁盘的使用。SSD 磁盘是有寿命的,它的写入次数是有限的(虽然数字很大)。这样如果应用层只是想写入少量数据而已,但数据落入磁盘时却变大了许多倍,那大家就会比较介意了。比如你只是想写入1K 的数据,可是最终却有10K 数据落盘。
Postgres 的写放大问题主要表现在对有索引的表进行数据更新上。因为 Postgres 的索引都是指向元组的 ctid,而元组又是不可更新的,所以当你更新一条记录时,它会创建一个新的元组存入磁盘,并且要针对所有的索引,为每个索引都创建一条新记录来指向新的元组,不管你更改的字段和这个索引有没有关系。这样对于 WAL 来说,Postgres 更改一条记录操作会写入新的完整记录,再加上多条索引记录。
「作者注」 :不过 MySQL 的 InnoDB 其实也是有写放大问题的。InnoDB 是以数据页的形式组织数据的,Linux 上默认数据页的大小是 16K。这样当你更改了一条记录时,最终会把这条记录所在的数据页整页刷回磁盘,设想一下你可能只是改了一个小字段,也许只有 4 个字节,可是最终却会导致 16K 字节的写入。
另外,Postgres 的这个设计也是有其好处的,它的第二索引直接指向元组的 ctid,这样在读取数据时效率就非常高。相对应地,通过 MySQL 的第二索引去读数据会经历“第二索引——主键——数据”的过程,MySQL 的读效率不如 Postgres。这是一个经典的读写性能权衡问题,在此 Evan 没有给出具体的数字让我们体会他们的业务特征。
主从复制
Postgres 的写放大问题最终也反应在了主从复制的日志传输上,变成了流量放大问题。Postgres 的主从复制传输的是 WAL 日志,所以对于一条数据更新来说,它要传输新的数据,还要传输这张表上每一条索引修改的日志。这样的流量放大在同一机房内还稍可接受,但对于跨机房的情况,传输速度和价格等问题让 Uber 产生了顾虑。Uber 是有跨机房从库的,一方面是容灾,另一方面是 WAL 的备份,以备有时需要靠它来搭建新的从库。
MySQL 的确没有引起流量放大。MySQL 的主从复制依靠的是 Binlog,它只是记录这条数据的修改,而不在乎这张表上到底有多少索引,所以可以认为与 Postgres 相比,它的 Binlog 是一种对数据修改的“逻辑”描述。MySQL 从库上应用 Binlog 日志时,如果有第二索引涉及了改动的字段,那就更新第二索引,否则第二索引压根不需要修改。而且,MySQL 有三种不同的 Binlog 格式,包含了不同数量的信息来供使用者选择:
Statement:只传输 DML 的 SQL 语句,如:UPDATE users SET birth_year=770 WHERE id = 4。这种模式日志量最小,但在某些场景下和对某些字段来说容易出错。
Row:对于更改了的数据,会把修改前和修改后的所有字段值都打印在 Binlog 中。这种模式日志量最大,但也最严谨,越来越多的公司在转向这种日志格式。很多日志解析工具更是只工作在这种模式下。
Mixed:上面两种的结合体,MySQL 会根据不同的语句来自行判断。这种模式日志量居中。
数据损坏
Uber 使用 Postgres 9.2 时曾经因为一个 BUG 导致了很大的故障。当时由于硬件升级的原因他们做了主从切换,结果就引发了这个 BUG 导致各个从库的数据全都乱掉了,而且还没有办法判断哪个从库的哪些数据是正确的或者乱的。最终他们确认了新的主库上的数据全部正确后,用新主库的数据把所有从库数据全覆盖了一遍,才算过了这一关。可是一朝被蛇咬十年怕井绳,他们最后用的版本仍是 Postgres 9.2,原因之一是不想再去踩别的版本的坑了。
「作者注」 :以这个作为抛弃 Postgres 的理由就太容易引起争议、令人质疑 Uber 技术团队的技术水平了。在社区的口碑中,Postgres 的稳定性恰恰是高于 MySQL 的,如果因为害怕碰上 Postgres 的 BUG 而转用 MySQL,那……我们只好祝福 Uber 了。
从库上的 MVCC 支持不好
Postgres 的从库上并没有真正的 MVCC,它的数据表空间、表空间文件内容和主库是完全一样的,在从库上就是依次应用 WAL。可如果从库上有一个正在进行中的事务的话,它就会挡住 WAL 的应用,从而导致看起来主从同步延迟很大。Postgres 实现了一个机制,如果某个业务程序的事务挡住同步线程太久的话,就直接将那个事务杀掉。所以如果在从库上有一些比较大的事务在运行的话,你可能就会经常看见莫名其妙的主从同步就延迟了,也会看见自己的操作运行了一段时间就不知被谁杀掉了。并不是每个程序员都很熟悉数据库的底层工作机制,所以这些现象会让大家觉得很诡异。
「作者注」 :这一点的确是的。相比来说对于这个 Postgres 的复制过程,MySQL 的主从复制并不会杀死从库上的事务。
Postgres 数据库的升级
Postgres 的数据复制是物理级的,主从数据文件完全一致,所以不能支持不同版本之间的主从复制,比如主库使用 9.2 从库使用 9.3,或者相反,等等。Uber 最初使用的是 Postgres 9.1,他们成功的升级成了 9.2,但升级耗费了相当长的时间,再加上后来业务爆发式增长,让他们再也没能安排下一次升级。而且 Postgres 直到 9.4 之后才有了工具 pglogical来帮助减少升级耗时,可是 pglogical 又不在 Postgres 主分支里,让使用旧版本的人无所适从。
「作者注」 :有消息 Postgres 的 WAL 日志也将变成逻辑型了,在这样的功能推出之后,就可以支持不同版本间的数据复制了。
MySQL 的其他优点
除了上文所述的几点,MySQL 还有几个其他 Postgres 不具备的优点:
BufferPoolhttps://dev.mysql.com/doc/refman/5.7/en/innodb-buffer-pool.html:虽然 Postgres 在内部有比较小的缓存,但和现在动辄几百 G 的服务器内存比起来,它的缓存还是太小,对硬件利用率太低了。InnoDB 则有 BufferPool,可以同时用于写缓冲和读缓存,用 LRU 管理,大小可配,这样就把硬件资源充分合理的利用起来了。
连接管理:MySQL 的连接管理是每个连接一个线程,每个线程消耗的资源都很有限,所以 MySQL 可以轻松支持 10000 个以上的连接。可是 Postgres 是每个连接一个进程的,进程之间通信和共享资源复杂,消耗资源严重,而且对多连接支持不好。Uber 的业务已经需要极大的增加数据库连接数,Postgres 已经无法满足需要。
Evan Klitzke 总结说:
在初期 Postgres 还是工作得很好的,但业务扩展时我们就碰上了非常严重的问题。现在我们还是在用着一些 Postgres 数据库,但是主要的数据已经挪到了 Schemaless 上,有些特别的业务也用了 Cassandra 等 NoSQL 数据库。我们现在用 MySQL 用得很好,我们也会写更多的博客来分享更多关于 MySQL 在 Uber 的使用内容。
审核编辑:刘清
-
存储器
+关注
关注
38文章
7493浏览量
163873 -
缓冲器
+关注
关注
6文章
1922浏览量
45499 -
python
+关注
关注
56文章
4797浏览量
84720 -
MYSQL数据库
+关注
关注
0文章
96浏览量
9393 -
MVCC
+关注
关注
0文章
13浏览量
1476
原文标题:为什么Uber的底层存储从Postgres换成MySQL了?
文章出处:【微信号:芋道源码,微信公众号:芋道源码】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
MySQL数据库索引的底层是怎么实现的
什么是Postgres?Postgres是什么意思
Uber为什么从Postgres迁移到MySQL
怎样选择存储引擎?MySQL存储引擎怎么样?
MySQL数据库:理解MySQL的性能优化、优化查询

MySQL的底层原理和技术学习
如何使用WINDAQ MySQL存储数据
Neon--AWS Aurora Postgres的无服务器开源替代品
GitHub底层数据库无缝升级到MySQL 8.0的经验





 工商网监
工商网监
评论