 打破端到端自动驾驶感知和规划的耦合障碍!
打破端到端自动驾驶感知和规划的耦合障碍!
0. 笔者个人体会
端到端自动驾驶一直是研究的重点和热点,输入RGB图像或雷达点云,输出自车的控制信号或运动规划。但目前很多工作都是只做感知或者只做规划,很重要的一个原因是端到端模型训练时间太长了,而且最终学习到的控制信号也未见得多好。现有的教师-学生范式还可能产生很严重的Causal Confusion问题。
今天要为大家介绍的就是ICCV 2023开源的工作DriveAdapter,解决了自动驾驶感知和规划的耦合障碍,来源于上交和上海AI Lab,这里不得不慨叹AI Lab实在高产,刚刚用UniAD拿了CVPR的Best Paper就又产出了新成果。
DriveAdapter的做法是,用学生模型来感知,用教师模型来规划,并且引入新的适配器和特征对齐损失来打破感知和规划的耦合障碍!想法很新颖!
1. 问题引出
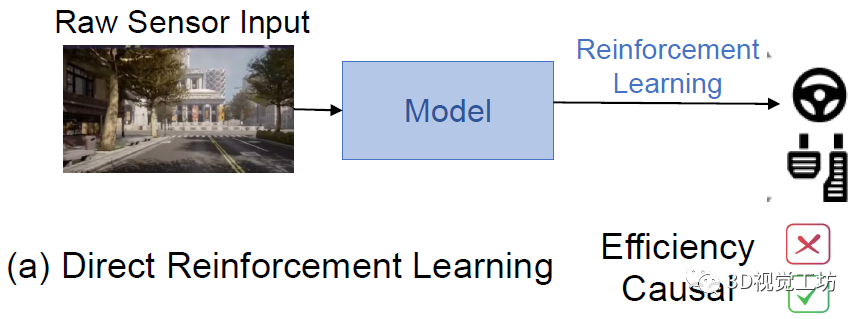
最直接的端到端自动驾驶框架,就是输入RGB图,利用强化学习直接输出控制信号(a)。但这样做效率太低了,在使用预训练模型的情况下甚至都需要20天才能收敛!
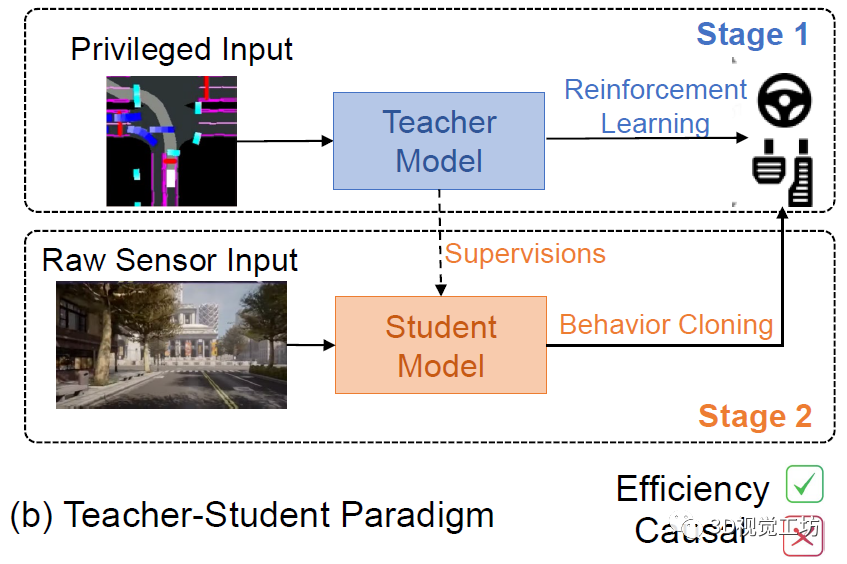
现在主流框架基本都是教师-学生模型,也就是说首先用强化学习训练一个复杂的教师模型,然后用原始的传感器数据让小模型去模仿教师模型的行为(Behavior Cloning)。这种范式的效率非常高!但是仍然有很大的问题,也就是由行为克隆引发的因果混淆问题(Causal Confusion)。这里也推荐「3D视觉工坊」新课程《深度剖析面向自动驾驶领域的车载传感器空间同步(标定)》。
听起来很绕口,那么这到底是个啥?
举个简单例子:
当车辆位于十字路口时,自车的路径实际上应该是根据信号灯来决定的。但是在图像上信号灯很小,周围车辆很大。所以学生模型从教师学习到的实际情况很可能是:根据其他车辆的行为来规划自车。那么如果自车处在路口第一辆车的位置,很有可能自车会永远不动!
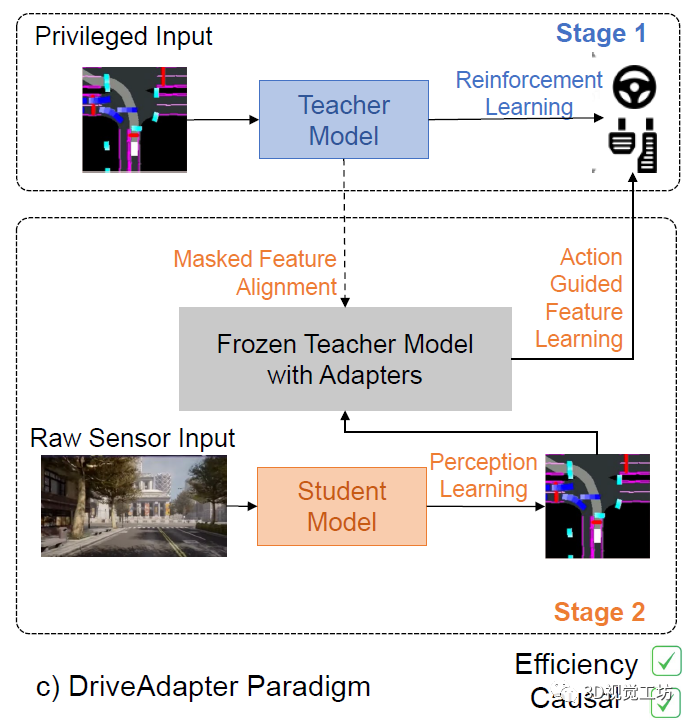
那么DriveAdapter这个方案打算怎么做呢?
简单来说,它是解耦了学生和教师模型。学生负责进行感知,输入RGB图像,输出BEV分割图。然后BEV分割图输送给教师,进行自车的路径规划!
当然里面还有特别多的细节,下面我们一起来看具体的论文信息。
2. 论文信息
标题:DriveAdapter: Breaking the Coupling Barrier of Perception and Planning in End-to-End Autonomous Driving
作者:Xiaosong Jia, Yulu Gao, Li Chen, Junchi Yan, Patrick Langechuan Liu, Hongyang Li
机构:上海交通大学、上海AI Lab、北航、安克创新
原文链接:https://arxiv.org/abs/2308.00398
代码链接:https://github.com/OpenDriveLab/DriveAdapter
3. 摘要
端到端的自动驾驶旨在构建一个以原始传感器数据为输入,直接输出自车的规划轨迹或控制信号的完全可微系统。最先进的方法通常遵循"教师-学生"范式。该模型使用权限信息(周围智能体和地图要素的真实情况)来学习驾驶策略。学生模型只具有获取原始传感器数据的权限,并对教师模型采集的数据进行行为克隆。通过在规划学习过程中消除感知部分的噪声,与那些耦合的工作相比,最先进的工作可以用更少的数据获得更好的性能。
然而,在当前的教师-学生范式下,学生模型仍然需要从头开始学习一个规划头,由于原始传感器输入的冗余和噪声性质以及行为克隆的偶然混淆问题,这可能具有挑战性。在这项工作中,我们旨在探索在让学生模型更专注于感知部分的同时,直接采用强教师模型进行规划的可能性。我们发现,即使配备了SOTA感知模型,直接让学生模型学习教师模型所需的输入也会导致较差的驾驶性能,这来自于预测的特权输入与真实值之间的较大分布差距。
为此,我们提出了DriveAdapter,它在学生(感知)和教师(规划)模块之间使用具有特征对齐目标函数的适配器。此外,由于基于纯学习的教师模型本身是不完美的,偶尔会破坏安全规则,我们针对那些不完美的教师特征提出了一种带有掩码的引导特征学习的方法,进一步将手工规则的先验注入到学习过程中。DriveAdapter在多个基于CARLA的闭环仿真测试集上实现了SOTA性能。
4. 算法解析
DriveAdapter整体的思路非常清晰,学生模型将原始传感器数据作为输入,并提取BEV特征以供BEV分割和适配器模块使用。之后,预测的BEV分割图被馈送到冻结的教师模型和适配器模块中。最后,适配器模块接收来自具有GT教师特征的监督,以及学生模型提供的BEV特征。对于教师模型引入规则的情况,对"对齐损失"应用掩码,并且所有适配器模块的监督来自动作损失的反向传播。
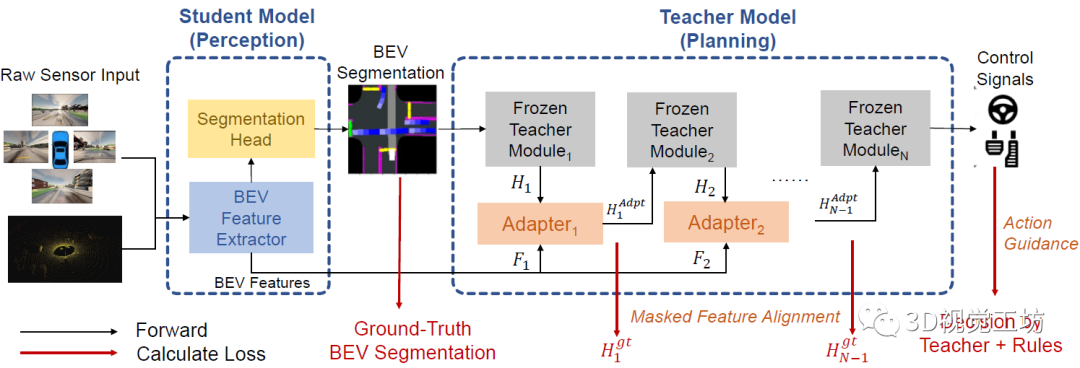
4.1 感知学习的学生模型
学生模型将4个相机图像和1个雷达点云作为输入,目的是生成BEV的语义分割图。具体流程是,首先使用BEVFusion将原始传感器数据转换成2D的BEV特征,然后使用Mask2former执行语义分割。
但关键问题是,即使使用SOTA感知模块,如果直接将预测的BEV分割馈送给教师模型,也并不会产生多好的预测和规划效果。
这是因为啥呢?
首先就是语义分割的不准确问题。搞过语义分割的小伙伴肯定清楚,模型直接输出的分割图其实效果并不是太好,很多甚至需要经过复杂的后处理才可以使用,分割的路线、车辆和信号灯非常不准,直接用的话噪声非常大。毕竟教师模型是用BEV分割的Ground Truth来训练的,直接用学生模型输出的BEV分割肯定是效果非常差。
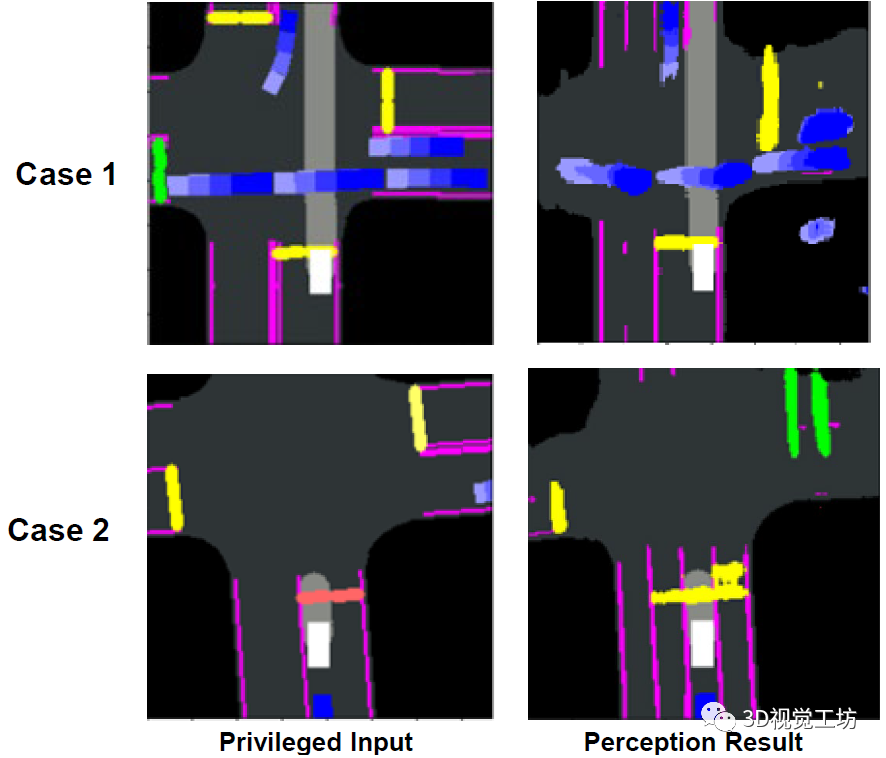
另一个原因就是教师模式的不完善。其实单独使用教师模型来输出运动规划,其结果也是非常不准的,所以学术界很多做法都是加入一些手工设计的规则来进行二次约束,这样来提高性能。
解耦教师和学生模型的思路确实很棒,但是这两个问题也确实很尖锐。那么怎么解决这两个问题呢?这就要涉及到DriveAdapter的另一个关键模块:适配器。
4.2 适配器模块
为了获得更低的成本和更好的适应性,作者在学生和教师模型之间添加适配器。虽然感觉这个适配器长得有点像很多论文里提到的"即插即用"模块?
适配器是分级插入的,第一层输入是原始的BEV分割图和学生模型的底层特征。之后,一方面不断编码BEV分割图,另一方面使用卷积层来对BEV特征进行降采样,来对其不同特征层之间的分辨率。
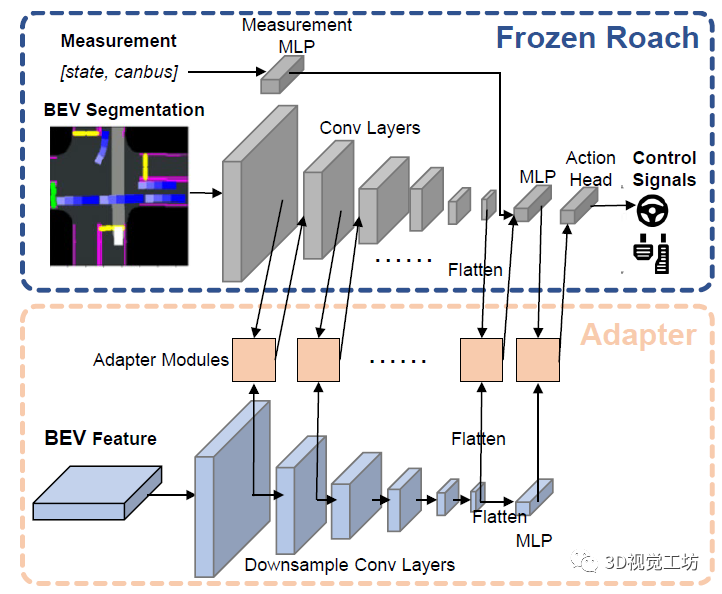
那么,具体怎么弥补BEV分割图和GT之间的差距呢?这里是为每个适配器都设计了一个特征对齐目标函数。实际上,相当于每个适配器模块都使用了一个额外的信息源,并且用原始BEV特征来恢复教师模型所需的GT特征。通过这种方式,可以以逐层监督的方式逐步缩小预测与真实特征之间的分布差距:
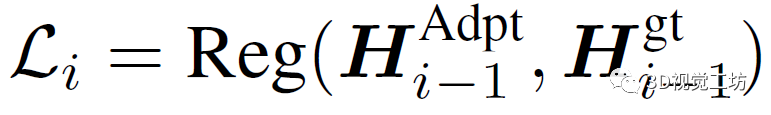
针对教师模型不完善的问题,作者是通过两种方式将手工规则的先验注入训练过程:(1)特征对齐Mask:对于教师模型错误并被规则检测的情况,由于教师模型中的原始特征导致错误的决策,就不让适配器模块恢复。(2)行动引导特征学习:计算模型预测和实际决策之间的损失,并通过冻结的教师模型和适配器模块进行反向传播。这里也推荐「3D视觉工坊」新课程《深度剖析面向自动驾驶领域的车载传感器空间同步(标定)》。
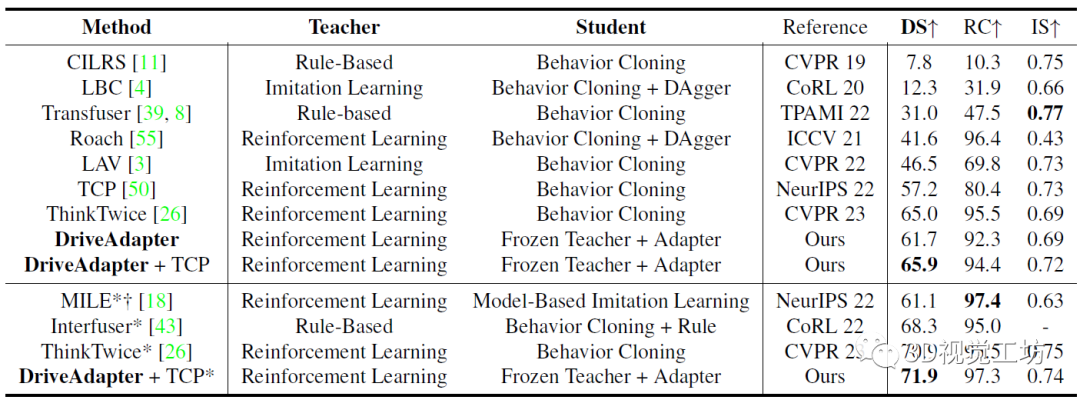
5. 实验结果
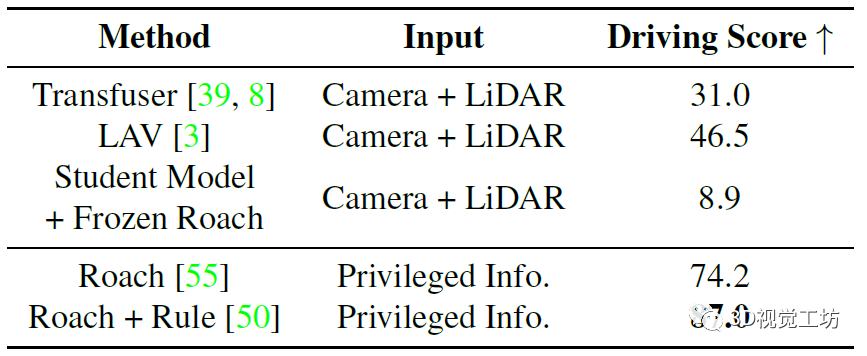
作者使用CARLA模拟器进行数据收集和闭环驾驶性能评估,每帧采集4台相机和1台激光雷达的原始数据。训练是在Town01、Town03、Town04和Town06进行,总共189K帧。评估指标方面,用的是CARLA的官方指标,包括:**违规指数( IS )衡量沿途发生的违规行为数量,路径完成度( RC )评估车辆完成路径的百分比。驾驶得分( DS )**表示路线完成度和违规得分的乘积。
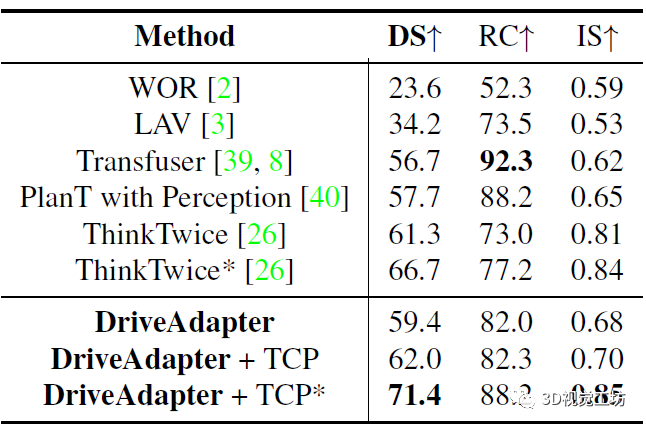
和其他SOTA方法的对比是在Town05 Long和Longest6序列上进行。可以发现,DriveAdapter甚至可以与经过10倍数据量训练的模型相媲美,而在DriveAdapter也使用10倍数据以后,性能进一步提升,这其实是因为训练更好得感知了红灯。
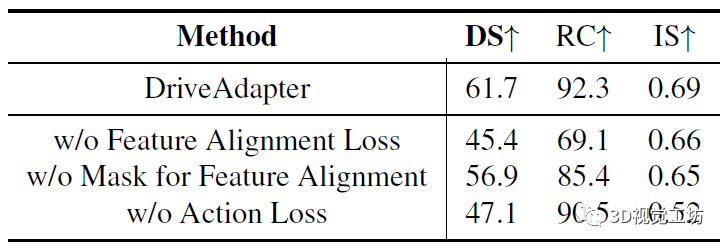
两个消融实验,一方面对比了特征对齐损失、特征对齐Mask、行为引导损失,一方面对比了适配器的各个阶段:
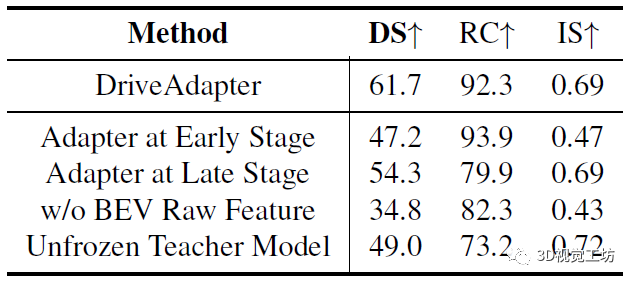
最后这个实验很有意思,不知道读者有没有这样的想法:"学生模型能不能不生成BEV分割,而是直接生成教师模型的中间特征图,那么性能会不会不一样?"。
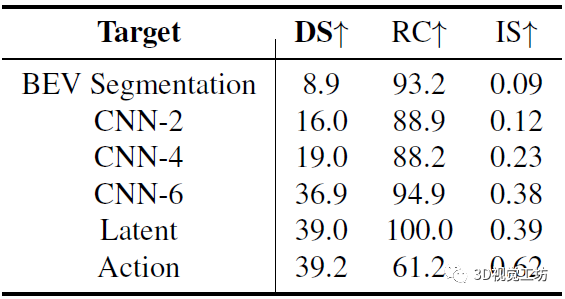
实际上,随着学生模型的学习目标变深,整个驾驶性能是增加的。作者认为,将特征直接输入到教师模型的更深层会遇到更少的累积误差。但有个极端例外,就是只做行为克隆,也就相当于完全不使用教师模型,这样会遇到严重的惯性问题,导致路径完成度( RC )较低。
那既然学习目标变深以后,性能会变好,为啥还要生成BEV分割呢?作者主要是考虑到,早期阶段的特征包含更多关于场景的详细信息,可能会对教师模型决策很重要,并且适配器可以缓解累积误差。另一方面,语义分割可以直观得调试学生模型的感知情况。
6. 总结
今天给大家介绍的是ICCV 2023的开源工作DriveAdapter,它很好得解耦了自动驾驶感知和规划的行为克隆,提出了一种新的端到端范式。直接利用通过RL学习的教师模型中的驾驶知识,并且克服了感知不完善和教师模型不完善的问题。笔者觉得更重要的是整篇文章分析问题的思路很通顺,读起来很舒服。算法刚刚开源,感兴趣的小伙伴赶快试试吧。
-
传感器
+关注
关注
2554文章
51607浏览量
757968 -
模型
+关注
关注
1文章
3397浏览量
49402 -
自动驾驶
+关注
关注
786文章
13976浏览量
167465
原文标题:ICCV 2023开源!打破端到端自动驾驶感知和规划的耦合障碍!
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
未来已来,多传感器融合感知是自动驾驶破局的关键
细说关于自动驾驶那些事儿
自动驾驶的到来
即插即用的自动驾驶LiDAR感知算法盒子 RS-Box
自动驾驶技术的实现
自动驾驶综述之定位、感知、规划常见算法汇总

端到端自动驾驶到底是什么?
基于矢量化场景表征的端到端自动驾驶算法框架

理想汽车自动驾驶端到端模型实现









 工商网监
工商网监
评论