 对DMA的理解和认识
对DMA的理解和认识
本文选自极术专栏“IC设计”,作者芯工阿文,授权转自微信公众号芯工阿文,本篇主要讲述对DMA的理解和认识。
这些天有个想法,在数字芯片设计中,很多模块都可以近似为DMA模型,包括CPU。基于该想法进行扩展,一些复杂的模块可以变得稍微容易理解。
首先描述一下什么是DMA,Direct Memory Access,字面意思就是直接内存访问。个人认为这个名词应该是从软件视角进行定义的。实际上,DMA完成的工作,无非就是从一个接口读取数据,再发送至另外一个接口,也就是对应着一读一写。从硬件角度来看,这个是很常规的操作,但在软件看来,可以将大量的操作卸载到DMA,从而将CPU释放出来做更多的事情。所以DMA实际完成的工作也就是数据的转移,基于转移的两个方向之间的差异和特征,从而带来各种收益。
数据转移,简单来说有3个要素,源地址、目的地址和数据长度。一般来说,DMA的实现有两种方式,一是Direct DMA,另一个是链表DMA。Direct DMA就是通过寄存器读写的方式直接配置上述的3个要素;链表DMA就是将保存上述3要素的描述符存放于内存,再将其地址信息配置至DMA,启动DMA后,解析描述符后做数据转移。
链表DMA的处理流程近似如下:
1)根据配置信息启动描述符读取操作,解析描述符;
2)基于描述信息,获取源地址和数据长度,启动数据读取操作;
3)读取数据返回后,再将数据发送至目的地址,完成后告知状态。
以此进行扩展,比如读取数据返回后,做各种运算,再将结果发送至目的地址,不少加速计算模块均是基于该思路进行处理的。再比如描述符读取做一些处理,支持多样化的描述符,或者描述符再嵌套描述符,等等。
个人认为,在SOC芯片内的几乎所有计算模块,均可以基于DMA的模型进行理解,再以此进行扩展开发,包括CPU。
再来看一下CPU是如何工作的,没有深入了解CPU的结构,仅仅知道大概,如有错误,请轻喷。首先,CPU基于起始地址,从该地址读取指令,再执行。一般来说,执行指令会伴随着数据读取,也就是LOAD,将数据搬运过来之后,再对数据做各种运算,完成后再将数据放回去,对应着STORE。这个过程是否跟DMA搬运数据非常类似?如下是对应关系。

图1
两者之间有非常近似的对应关系,基本原理是一样的,只是在具体实现过程中,存在较大的差异。如描述符,对于DMA,仅有有限的几个格式,不同实现有不同的指令格式,对于CPU,指令集就相当于描述符,类型很多,不同架构有不同的指令集,由此也会引入很多问题,其复杂度是DMA的很多很多倍,如CPU需要Cache,但是从没听说过DMA需要使用Cache。
还有一个明显差别,CPU有计算逻辑ALU,通常来说,DMA将数据从源地址搬回来后,就直接写到目的地址。这里再换个思路,如果在这两者中间,加入一点计算逻辑,比如压缩解压缩、编解码等等,是否与很多硬件加速器的架构基本是一致的?
可以看到,CPU和DMA之间,差不多就是两个极端。CPU是属于general purpose,DMA是目的性非常强的设计。在这中间取一个点,是否就可以对应GPU、AI、DSA等等场景?
前一段时间想做点事情,设计一个DMA,但在数据读取和写入之间开放一个接口,在这接口之内做一些计算逻辑,以此针对各种具体的数据计算场景,基于需求进行设计。也就是说,将这个DMA作为一个平台,基于该平台做后续的二次开发。但是,在梳理上述的概念之后,发现其实现在已经有类似的东西,也就是RISC-V。该指令集是完全开放的,当前也有各种各样的开源代码,有Verilog实现的,还有chisel,也有spinalHDL,完全可以基于这些代码做针对需求场景的二次开发,而且可以从更小的数据粒度进行操控。
-
cpu
+关注
关注
68文章
10829浏览量
211182 -
接口
+关注
关注
33文章
8526浏览量
150861 -
IC设计
+关注
关注
37文章
1292浏览量
103780 -
dma
+关注
关注
3文章
559浏览量
100446 -
数字芯片
+关注
关注
1文章
108浏览量
18374
原文标题:把DMA当作一个模型
文章出处:【微信号:Ithingedu,微信公众号:安芯教育科技】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
DMA 串口传输原理解析
F28335 DMA设置代码的理解
K60的UART模块带DMA接口怎么理解
DMA与DMA控制器
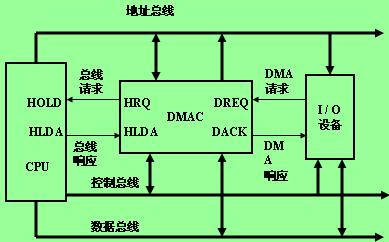
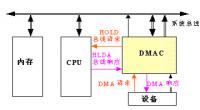
dma是什么意思? 什么是dma?
单片机的RAM和FLASH认识理解
16、STM32——DMA详解

STM32使用DMA控制器试验总结
STM32F1 ADC和DMA的简单理解
STM32学习笔记(串口+DMA)





 工商网监
工商网监
评论