原文:https://mp.weixin.qq.com/s/Qov9c1oTKv0zPiTTm2IG-Q
最近,高通与恩智浦等5家巨头宣布:
联合组建一家新公司,专攻RISC-V芯片技术开发。

消息一出,不少观点都认为这是要挑战ARM的行业地位。彭博社表示,5家公司拧成一股劲儿的背后,反映的是全球芯片制造商对ARM技术过度依赖的担忧。据了解,同样是在这两天,ARM被曝最快将于下个月进行首次公开募股,目标估值高达600亿至700亿美元。从汽车业务开始首先,简单看一下这5家公司的来头:高通不用多说,它在全球智能手机市场的出货量仅次于联发科,是高端智能手机芯片市场的霸主。恩智浦,则是全球第二大电动汽车芯片生产商。剩下3位也都来头不小,分别是专攻物联网市场的Nordic半导体、全球知名Tier1供应商博世以及德国芯片巨头英飞凌(其中一大业务为汽车电子)。

我们可以看到,5家公司里面的“汽车含量”着实不算少。正如公告所说,这家联合RISC-V公司的首要切入点,正是汽车领域,其总部就落址于德国。随着技术的成熟,他们最终再转移到移动和物联网领域——而这正是高通目前最大的市场。事实上,作为ARM最大的客户之一,高通对其早有摆脱之心。早在2019年,高通就开始投资知名RISC-V芯片设计厂商SiFive,去年,它更是领投了其1.75亿美元F轮融资,该轮之后,SiFive估值超过25亿美元,成为RISC-V芯片阵营首支独角兽。除此之外,2021年之时,高通还斥资14亿美元收购了苹果前SoC工程师创立的Nuvia。有消息称,最快在骁龙8Gen4时代,我们就会看到自研Nuvia架构和ARM架构的双版本情况。有观点认为,如果Nuvia版本能够发挥其潜力,有望让高通追赶苹果手机芯片。值得一提的是,高通因为这笔收购,吃到了ARM的官司。ARM认为,Nuvia使用ARM许可证开发芯片设计,而高通在未经ARM同意的情况下获得Nuvia许可,有违合同,侵犯ARM商标权。这差点让高通和Nuvia的交易告吹。由此,这把官司也被不少人认为是高通与ARM之间的重大决裂。但高通此次和众多巨头一起继续加码RISC-V的真正原因,并不止如此。外媒Arstechnica分析,ARM作为全世界绝大多数移动设备芯片的核心,却并没有从其授权业务中赚到很多钱(跟其他芯片商相比简直就是相形见绌的程度)。这导致其母公司软银很上火,一度想套现跑路以660亿美元的价格卖给英伟达,结果被英国监管机构叫停。找不到好出路的ARM只好寻求单独上市。为此,ARM也告知广大客户,预计其商业模式将发生“彻底改变”,并表示要收紧授权,资费涨幅可达数倍。于是在大家眼中,ARM已经变成一个“越来越不稳定的合作伙伴”,都想另谋出路。除了高通,还有无数人都想要挑战ARM的垄断地位。不过,到目前为止,还没有一家公司能够推出与ARM产品相媲美的高端RISC-V芯片。究其原因,ARM在各种生态尤其是软件生态上已是行业内的标准。彭博社表示,ARM花了几十年的时间才达到目前的水平,这些竞争对手在短时间内肯定是无法撼动其地位的。有保守估计,RISC-V要想ARM的垄断至少也得个7-8年吧。而有网友表示:
从历史上看,仅仅因为产品更便宜并不意味着它会成功,因为单位成本在大批量生产中并不重要。RISC-V必须在某些方面比ARM做得更好才能超越它。当然,还是希望RISC-V取得成功。
2. 直接用GPT-4控制空调,微软免训练方法让LLM迈向工业控制
原文:https://mp.weixin.qq.com/s/iZKXZmBrEs-i-aG0NoGEYA
随着大型语言模型(LLM)技术的日渐成熟,其应用范围正在不断扩大。从智能写作到搜索引擎,LLM 的应用潜力正在一点点被挖掘。
最近,微软亚洲研究院提出可以将 LLM 用于工业控制,而且仅需少量示例样本就能达成优于传统强化学习方法的效果。该研究尝试使用 GPT-4 来控制空气调节系统(HVAC),得到了相当积极的结果。

论文地址:http://export.arxiv.org/abs/2308.03028在智能控制领域,强化学习(RL)是最流行的决策方法之一,但却存在样本低效问题以及由此导致的训练成本高问题。当智能体从头开始学习一个任务时。传统的强化学习范式从根本上讲就难以解决这些问题。毕竟就算是人类,通常也需要数千小时的学习才能成为领域专家,这大概对应于数百万次交互。但是,对于工业场景的许多控制任务,比如库存管理、量化交易和 HVAC 控制,人们更倾向于使用高性能控制器来低成本地处理不同任务,这对传统控制方法而言是巨大的挑战。举个例子,我们可能希望只需极少量的微调和有限数量的参考演示就能控制不同建筑的 HVAC。HVAC 控制可能在不同任务上的基本原理都类似,但是场景迁移的动态情况甚至状态 / 动作空间可能会不一样。不仅如此,用于从头开始训练强化学习智能体的演示通常也不够多。因此,我们很难使用强化学习或其它传统控制方法训练出普遍适用于这类场景的智能体。使用基础模型的先验知识是一种颇具潜力的方法。这些基础模型使用了互联网规模的多样化数据集进行预训练,因此可作为丰富先验知识的来源而被用于各种工业控制任务。基础模型已经展现出了强大的涌现能力以及对多种下游任务的快速适应能力,具体的案例包括 GPT-4、Bard、DALL-E、CLIP。其中前两者是大型语言模型(LLM)的代表,后两者则能处理文本和图像。基础模型近来取得的巨大成功已经催生出了一些利用 LLM 执行决策的方法。这些方法大致上可分为三类:针对具体下游任务对 LLM 进行微调、将 LLM 与可训练组件组合使用、直接使用预训练的 LLM。之前的研究在使用基础模型进行控制实验时,通常选用的任务是机器人操控、家庭助理或游戏环境,而微软亚洲研院的这个团队则专注于工业控制任务。对传统强化学习方法而言,该任务有三大难点:1) 决策智能体通常面对的是一系列异构的任务,比如具有不同的状态和动作空间或迁移动态情况。强化学习方法需要为异构的任务训练不同的模型,这样做的成本很高。2) 决策智能体的开发过程需要很低的技术债(technical debt),这说明所提供的样本数量不够(甚至可能没有),而传统的强化学习算法需要大数据才能训练,因此可能无法设计针对特定任务的模型。3) 决策智能体需要以在线方式快速适应新场景或不断变化的动态情况,比如完全依靠新的在线交互经验而无需训练。为了解决这些难题,微软亚洲研究院的 Lei Song 等研究者提出直接使用预训练 LLM 来控制 HVAC。该方法只需少量样本就能解决异构的任务,其过程不涉及到任何训练,仅使用样本作为少样本学习的示例来进行上下文学习。据介绍,这项研究的目标是探索直接使用预训练 LLM 来执行工业控制任务的潜力。具体来说,他们设计了一种机制来从专家演示和历史交互挑选示例,还设计了一种可将目标、指示、演示和当前状态转换为 prompt 的 prompt 生成器。然后,再使用生成的 prompt,通过 LLM 来给出控制。研究者表示,其目的是探究不同的设计方式会如何影响 LLM 在工业控制任务上的表现,而该方法的很多方面都难以把控。-
第一,尽管该方法的概念很简单,但相比于传统的决策方法,其性能表现还不明朗。
-
第二,基础模型向不同任务的泛化能力(比如对于不同的上下文、动作空间等)仍然有待研究。
-
第三,该方法对语言包装器不同设计的敏感性也值得研究(例如,prompt 中哪一部分对性能影响最大)。
研究者希望通过解答这些问题凸显出这些方法的潜力以及展现可以如何为技术债较低的工业控制任务设计解决方法。这篇论文的主要贡献包括:-
开发了一种可将基础模型用于工业控制但无需训练的方法,其能以较低的技术债用于多种异构的任务。
-
研究者通过 GPT-4 控制 HVAC 进行了实验,得到了积极的实验结果,展现了这些方法的潜力。
-
研究者进行了广泛的消融研究(涉及泛化能力、示例选取和 prompt 设计),阐明了该方向的未来发展。
方法该研究使用 GPT-4 来优化对 HVAC 设备的控制,工作流程如下图 1 所示:
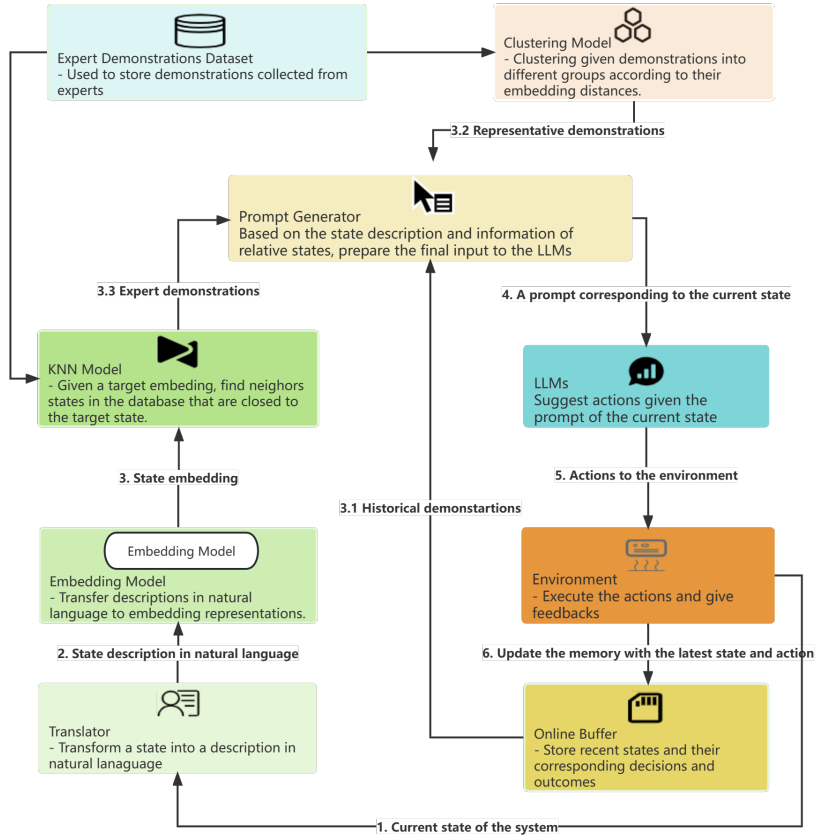
该工作流程中的 LLM 和环境组件如下:LLM:一个预训练大型语言模型,用作决策器。它会根据给出的 prompt 生成对应的响应。其 prompt 中应包含对当前状态的描述、简单的 HVAC 控制指令、相关状态的演示等。环境:一个交互式环境或模拟器,可以执行 LLM 建议的动作并提供反馈。实验中所使用的具体评估环境为 BEAR (Zhang et al., 2022a)。为了在 BEAR 中创建环境,必须提供两个参数:建筑类型(如大型办公室、小型办公室、医院等)和天气条件(如炎热干燥、炎热潮湿、温暖干燥等)。此外,值得注意的是,每种天气状况都对应于特定的城市。例如,炎热干燥的天气状况与水牛城有关。在 BEAR 中,每个状态都由一个数值向量表示,其中除了最后四个维度外,每个维度都对应于建筑物中一个房间的当前温度。最后四个维度分别代表室外温度、全局水平辐射(GHI)、地面温度和居住者功率。在所有环境中,首要目标是保持室温在 22 ℃ 附近,同时尽可能减少能耗。BEAR 中的操作被编码为范围从 -1 到 1 的实数。负值表示制冷模式,正值表示加热模式。这些动作的绝对值对应于阀门打开程度,这能说明能耗情况。如果绝对值更大,那么能耗也就更大。在兼顾舒适度和能耗的条件下,研究者在实验中使用了以下奖励函数:
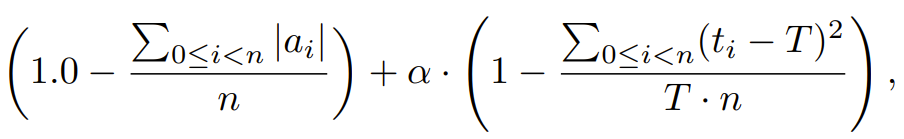
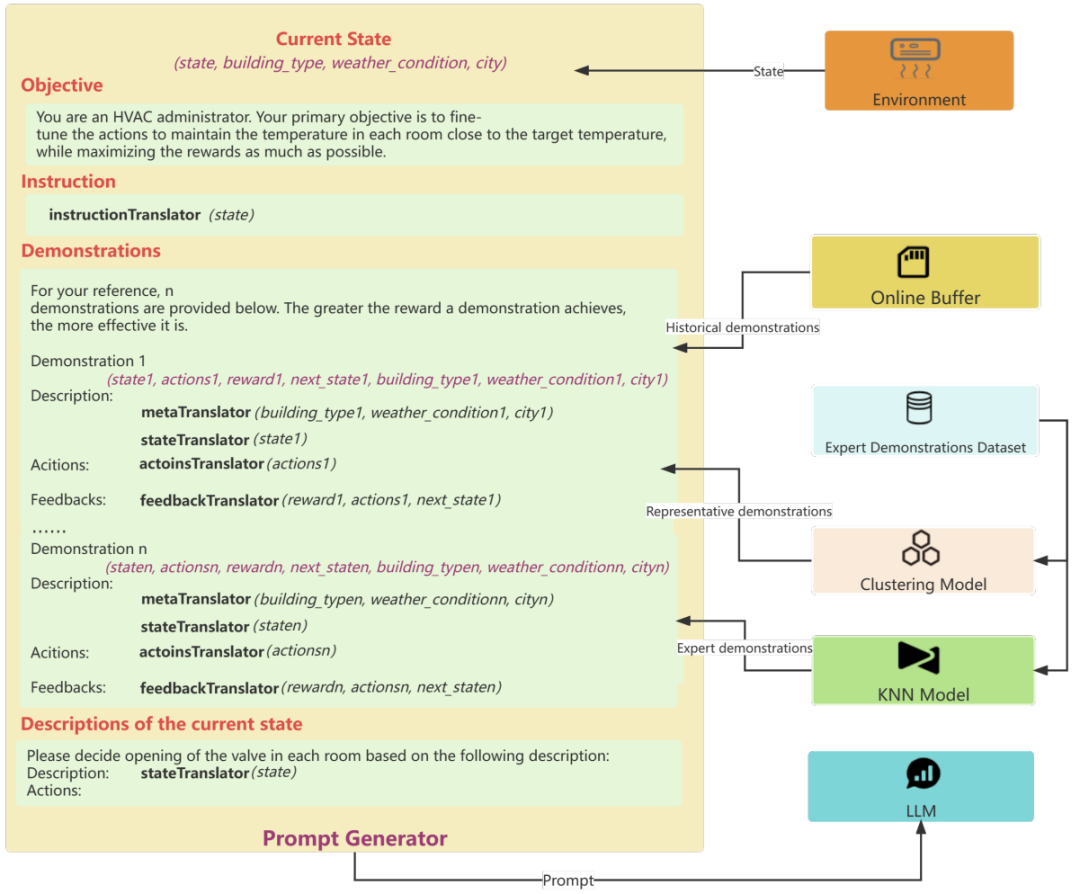
其中 n 表示房间数,T=22℃ 是目标温度,t_i 表示第 i 个房间的温度。超参数 α 用于实现能耗和舒适度的平衡。此外,该工作流程中还包含在线缓冲器、转译器、嵌入模型、专家演示数据集、KNN 模型、聚类模型、prompt 生成器等组件。其中 prompt 生成器的执行过程如图 2 所示,其中紫色的文本仅用于说明,而非 prompt 的一部分。
实验该研究通过实验展示了 GPT-4 控制 HVAC 设备的效果,其中涉及不同的建筑物和天气条件。只要能提供适当的指示和演示(不一定与目标建筑和天气条件相关),GPT-4 的表现就能超过专门为特定建筑和天气条件精心训练的强化学习策略。此外,研究者还进行了全面的消融研究,以确定 prompt 中每个部分的贡献。
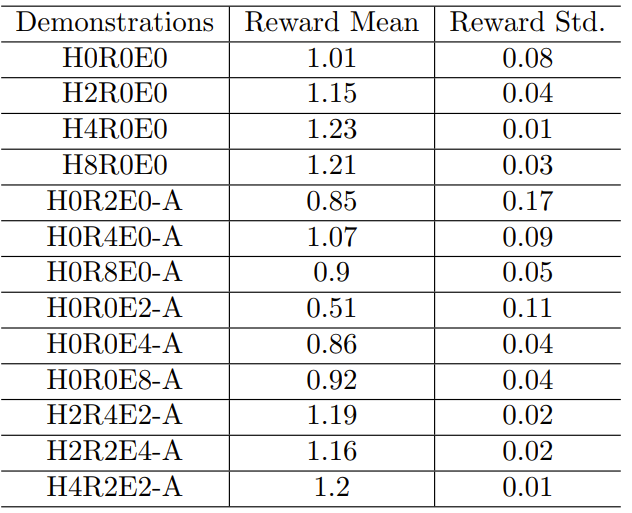
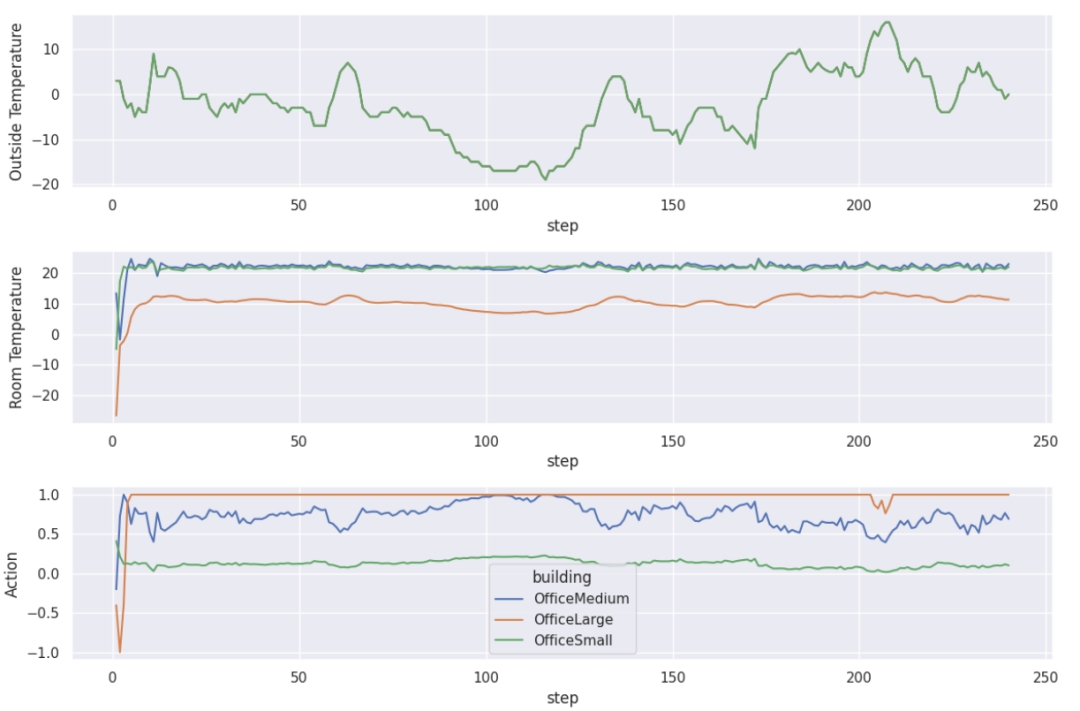
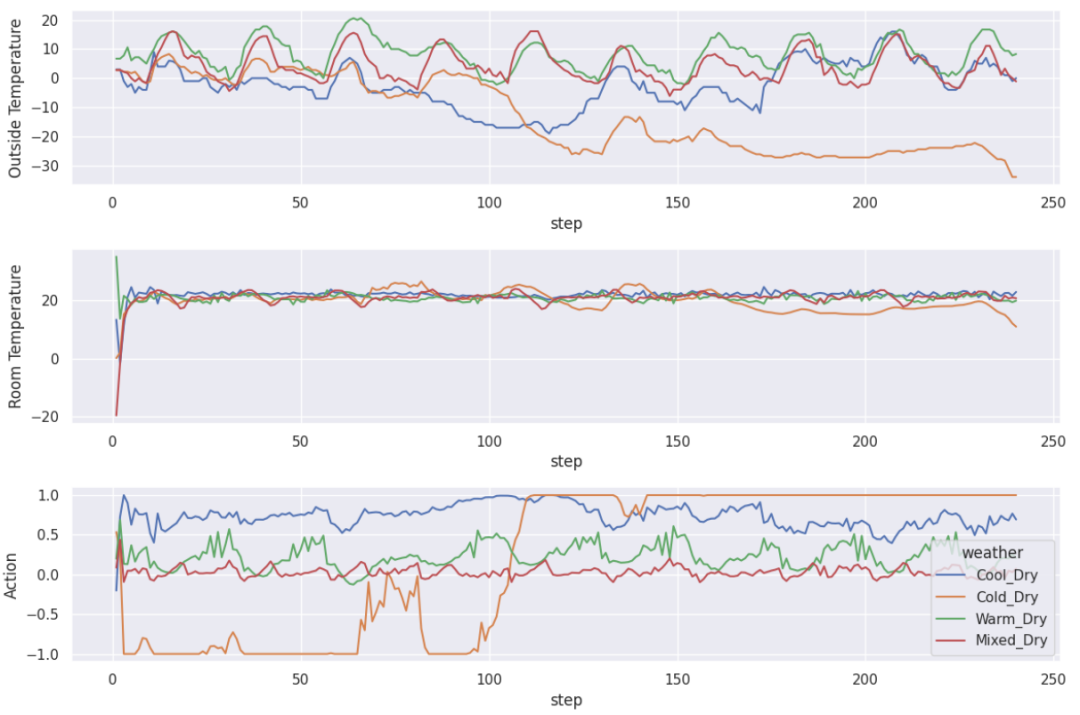
3. A卡跑大模型,性能达到4090的80%,价格只有一半:陈天奇TVM团队出品
原文:https://mp.weixin.qq.com/s/PxZ3ZYwGKTlii1nPka8EWg
英伟达 GPU 买不到的问题,就这样解决了?
最近,科技领域有很多人都在为算力发愁。

自预训练大模型兴起以来,人们面临的算力挑战就变得越来越大。为此,人们为大语言模型(LLM)提出了许多训练和推理的解决方案。显然,大多数高性能推理解决方案都基于 CUDA 并针对英伟达 GPU 进行了优化。但在动辄千亿参数的模型体量,多家科技公司激烈竞争,以及单一供应商的合力作用下,想抢到 GPU 又变成了一件难事。最近,微软、OpenAI 等公司都表示正在采取必要措施来缓解用于 AI 任务的 H100、A100 专用 GPU 的短缺问题。微软正在限制员工访问 GPU 的时间,Quora 首席执行官表示,硬件短缺掩盖了人工智能应用程序的真正潜力。伊隆・马斯克还开玩笑说,企业级 GPU 比买「药」还难。
旺盛的需求除了推动英伟达的股价,使其改变生产计划之外,也让人们不得不去寻求其他替代方式。好消息是,图形芯片市场上并不只有 N 卡一家。昨天,卡耐基梅隆大学博士生侯博涵(Bohan Hou)放出了使用 AMD 显卡进行大模型推理的新方案,立刻获得了机器学习社区的关注。
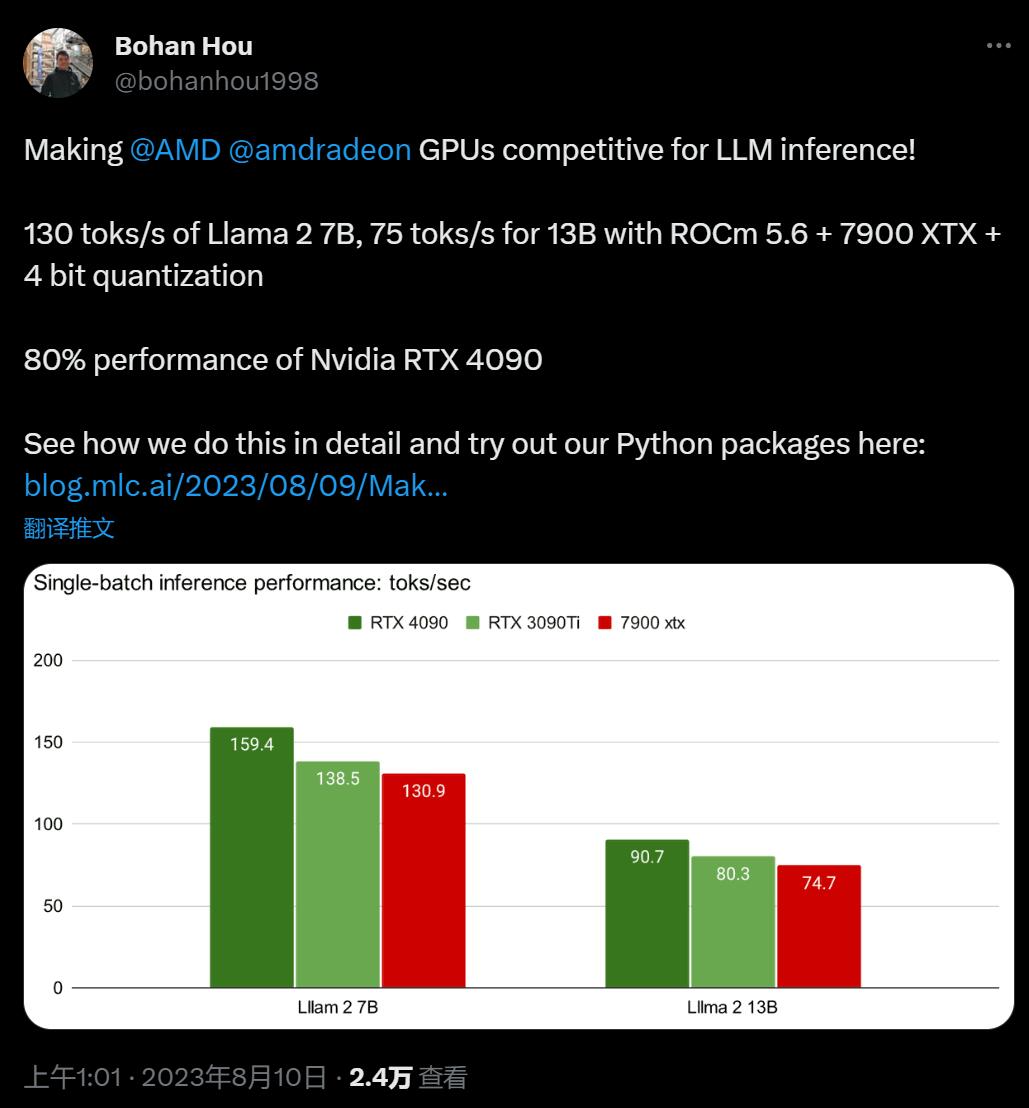
在 CMU,侯博涵的导师是 TVM、MXNET、XGBoost 的作者陈天奇。对于这项新实践,陈天奇表示,解决 AI 硬件短缺问题的方法还是要看软件,让我们带来高性能、通用部署的开源大模型吧。

在知乎上,作者对于实现高性能 LLM 推理进行了详细介绍:
通过这种优化方法,在最新的 Llama2 的 7B 和 13B 模型中,如果用一块 AMD Radeon RX 7900 XTX 速度可以达到英伟达 RTX 4090 的 80%,或是 3090Ti 的 94%。除了 ROCm 之外,这种 Vulkan 支持还允许我们把大模型的部署推广到其他 AMD 芯片类型上,例如具有 AMD APU 的 SteamDeck。如果粗略的比较一下规格,我们可以看到 AMD 的 RX 7900 XTX 与英伟达的 RTX 4090 和 RTX 3090 Ti 处于相近级别。它们的显存都在 24GB,这意味着它们可以容纳相同尺寸的模型,它们都具有相似的内存带宽。
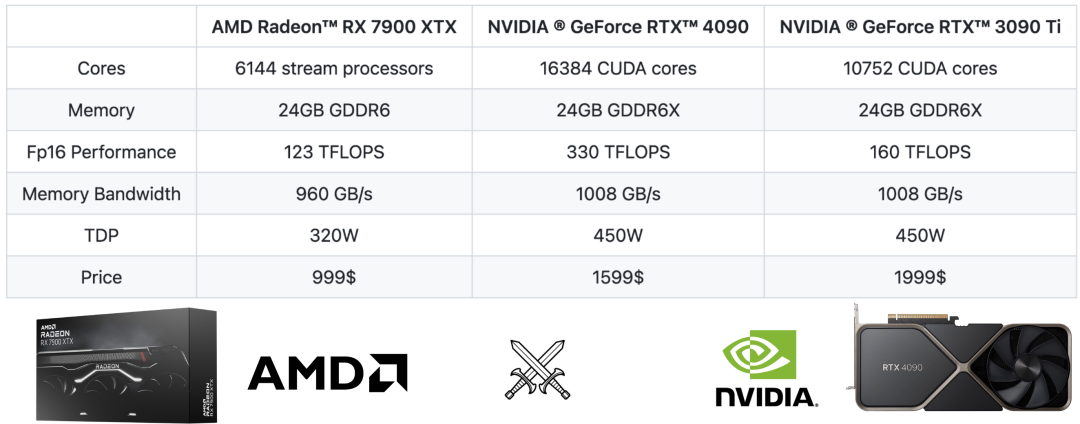
但是在算力上,RTX 4090 的 FP16 性能比 7900 XTX 高两倍,而 3090 Ti 的 FP16 性能比 7900 XTX 高 1.3 倍。如果只考虑延迟敏感的大模型推理,其性能主要受内存限制,因此 FP16 性能不是这里的瓶颈。而看价格的话,RX 7900 XTX 比 RTX 4090 便宜 40% 还多(京东上看甚至有 50%),在消费级领域里前者几乎是和 RTX 4080 对标的。3090Ti 的价格则很难比较,毕竟那是上一代产品。但从纯硬件规格的角度来看,AMD 7900 XTX 似乎与 RTX 3090 Ti 相当。我们知道,硬件层的算力并不一定是 AMD 长期以来在机器学习上落后的原因 —— 主要差距在于缺乏相关模型的软件支持和优化。从生态角度来看,有两个因素已开始改变现状:-
AMD 正在努力在 ROCm 平台上增加投入。
-
机器学习编译等新兴技术现在有助于降低跨后端的,更通用软件支持的总体成本。
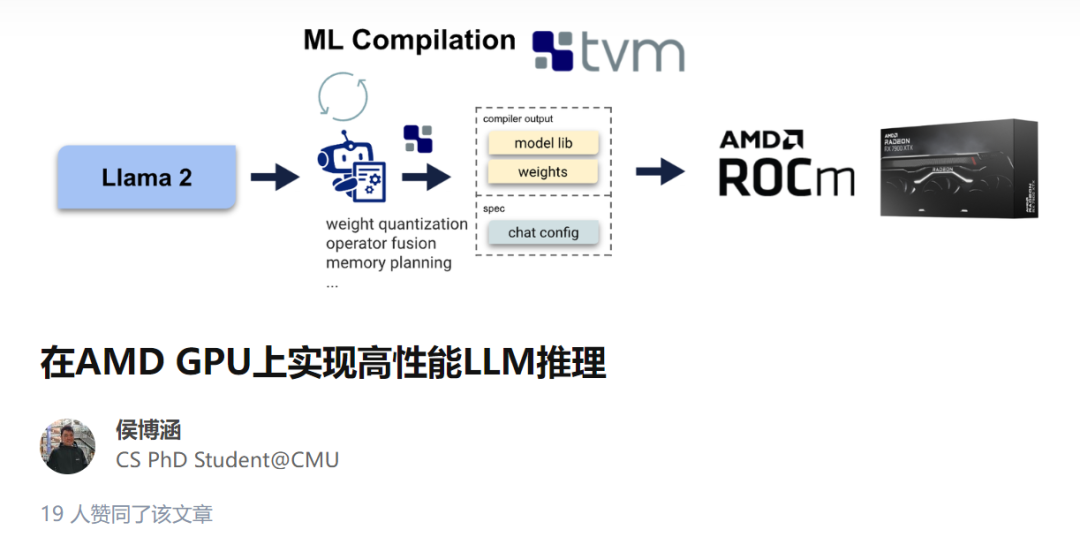
研究人员深入讨论了 AMD GPU 体系与目前流行的英伟达 GPU 上高性能 CUDA 解决方案相比的表现如何。用 ROCm 进行机器学习编译机器学习编译机器学习编译是一种用于编译和自动优化机器学习模型的新兴技术。MLC 解决方案不是为每个后端(如 ROCm 或 CUDA)编写特定的算子 ,而是自动生成适用于不同后端的代码。在这里,作者利用 MLC-LLM,一种基于机器学习编译的解决方案,提供了 LLM 的高性能通用部署。MLC-LLM 建立在 Apache TVM Unity 之上,后者是一个机器学习编译软件栈,提供了基于 Python 的高效开发和通用部署。MLC-LLM 为各种后端(包括 CUDA、Metal、ROCm、Vulkan 和 OpenCL)提供了最先进的性能,涵盖了从服务器级别 GPU 到移动设备(iPhone 和 Android)。整体而言,MLC-LLM 允许用户使用基于 Python 的工作流程获取开源的大语言模型,并在包括转换计算图、优化 GPU 算子的张量 layout 和 schedule 以及在感兴趣的平台上本地部署时进行编译。
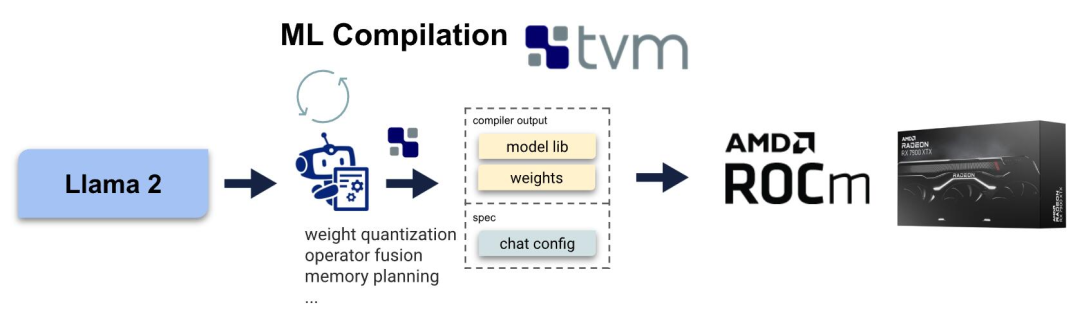
针对 AMD GPU 和 APU 的 MLC人们对于 A 卡用于机器学习的探索其实并不鲜见,支持 AMD GPU 有几种可能的技术路线:ROCm、OpenCL、Vulkan 和 WebGPU。ROCm 技术栈是 AMD 最近推出的,与 CUDA 技术栈有许多相应的相似之处。Vulkan 是最新的图形渲染标准,为各种 GPU 设备提供了广泛的支持。WebGPU 是最新的 Web 标准,允许在 Web 浏览器上运行计算。虽然有这么多可能的路线,但很少有解决方案支持除了 CUDA 之外的方法,这在很大程度上是因为复制新硬件或 GPU 编程模型的技术栈的工程成本过高。MLC-LLM 支持自动代码生成,无需为每个 GPU 算子重新定制,从而为以上所有方法提供支持。但是,最终性能仍然取决于 GPU 运行时的质量以及在每个平台上的可用性。在这个案例中,作者选择 Radeon 7900 XTX 的 ROCm 和 Steamdeck 的 APU 的 Vulkan,可以发现 ROCm 技术栈是开箱即用的。由于 TVM unity 中具有高效的基于 Python 的开发流程,花费了若干小时来进一步提供 ROCm 的性能优化。具体来说,研究人员采取了以下措施来提供 ROCm 支持:-
重用现有后端(如 CUDA 和 Metal)的整个 MLC 流水线,包括内存规划、算子融合等。
-
重用 TVM TensorIR 中的通用 GPU 算子优化空间,并将其后端选为 AMD GPU
-
重用 TVM 的 ROCm 代码生成流程,通过 LLVM 生成 ROCm 代码。
-
最后,将生成的代码导出为可以由 CLI、Python 和 REST API 调用的共享或静态库。
使用 MLC Python 包进行性能测试作者使用 4 bit 量化对 Llama 2 7B 和 13B 进行了性能测试。通过设置 prompt 长度为 1 个 token 并生成 512 个 token 来测量 decoding 的性能。所有结果都是在 batch size=1 的情况下测试。

基于 ROCm5.6,AMD 7900 XTX 可以达到 NVIDIA 4090 速度的 80%。关于 CUDA 性能说明:在这里 CUDA baseline 的性能如何?据我们所知,MLC-LLM 是 CUDA 上大语言模型推理的最优解决方案。但作者相信它仍然有改进的空间,例如通过更好的 attention 算子优化。一旦这些优化在 MLC 中实现,预计 AMD 和 NVIDIA 的数据都会有所改善。如果这些优化仅在 N 卡那里实施,将使差距从 20% 增加到 30%。因此,在查看这些数字时,作者建议放置 10% 的误差。自行尝试该项目提供了预构建的安装包和使用说明,以便用户在自己的设备上复现新的结果。要运行这些性能测试,请确保你的 Linux 上有安装了 ROCm 5.6 或更高版本的 AMD GPU。
4. 英伟达生成式AI超级芯片GH200,两倍H100算力,黄仁勋:它会疯狂推理
原文:https://mp.weixin.qq.com/s/B0agIPkI9R8Qee9s9x7BRA
等不及架构革新,英伟达「提前」发布了生成式 AI 专用的芯片。
当地时间 8 月 8 日,英伟达 CEO 黄仁勋在计算机图形学顶会 SIGGRAPH 2023 上发布了专为生成式 AI 打造的下一代 GH200 Grace Hopper 平台,并推出了 OVX 服务器、AI Workbench 等一系列重磅更新。
五年前,也是在 SIGGRAPH 大会的演讲中,英伟达宣布将 AI 和实时光线追踪引入 GPU ,可以说,当时的这个决定重塑了计算图形学。
「我们意识到光栅化已经达到了极限,」黄仁勋表示:「这要求我们重塑硬件、软件和算法。在我们用 AI 重塑 CG 的同时,也在为 AI 重塑 GPU。」
预言应验了:几年来,计算系统变得越来越强大,例如 NVIDIA HGX H100,它利用 8 个 GPU 和总共 1 万亿个晶体管,与基于 CPU 的系统相比,提供了显著的加速。
「这就是世界数据中心迅速转向加速计算的原因,」在今年的 SIGGRAPH 大会,黄仁勋重申:「The more you buy, the more you save.」

如今,训练越来越大的生成式 AI 模型所需的计算未必由具有一定 GPU 能力的传统数据中心来完成,而是要依靠像 H100 这样从一开始就为大规模运算而设计的系统。可以说,AI 的发展在某种程度上只受限于这些计算资源的可用性。但黄仁勋断言,这仅仅是个开始。新模型不仅需要训练时的计算能力,还需要实现由数百万甚至数十亿用户实时运行的计算能力。
「未来,LLM 将出现在几乎所有事物的前端:人类就是新的编程语言。从视觉效果到快速数字化的制造市场、工厂设计和重工业,一切都将采用自然语言界面。」黄仁勋表示。在这场一个多小时的演讲中,黄仁勋带来了一系列新发布,全部面向「生成式 AI」。更强的 GH200 Grace Hopper 超级芯片平台英伟达的 Grace Hopper 超级芯片 NVIDIA GH200 结合了 72 核 Grace CPU 和 Hopper GPU,并已在 5 月全面投入生产。现在,黄任勋又宣布 Grace Hopper 超级芯片将配备 HBM3e 高带宽内存(HBM3e 比当前的 HBM3 快 50%),下一代 GH200 Grace Hopper 平台将大幅提升生成式 AI 的计算速度。

全新的 GH200 内存容量将增加至原有的 3.5 倍,带宽增加至 3 倍,包含一台具有 144 个 Arm Neoverse 核心、282GB HBM3e 内存的服务器,提供 8 petaflops 的 AI 算力。为了提升大模型的实际应用效率,生成式 AI 模型的工作负载通常涵盖大型语言模型、推荐系统和向量数据库。GH200 平台旨在全面处理这些工作负载,并提供多种配置。英伟达表示,这款名为 GH200 的超级芯片将于 2024 年第二季度投产。全新的 RTX 工作站和 Omniverse老黄还宣布,英伟达与 BOXX、戴尔科技、惠普和联想等工作站制造商合作,打造了一系列全新的高性能 RTX 工作站。最新发布的 RTX 工作站提供多达四个英伟达 RTX 6000 Ada GPU,每个 GPU 配备 48GB 内存。单个桌面工作站可提供高达 5828 TFLOPS 的性能和 192GB 的 GPU 内存。
根据用户需求,这些系统可配置 Nvidia AI Enterprise 或 Omniverse Enterprise 软件,为各种要求苛刻的生成式 AI 和图形密集型工作负载提供必要的动力。这些新发布预计将于秋季推出。新发布的 Nvidia AI Enterprise 4.0 引入了 Nvidia NeMo,这是一个用于构建和定制生成式 AI 基础模型的端到端框架。它还包括用于数据科学的 Nvidia Rapids 库,并为常见企业 AI 用例(例如推荐器、虚拟助理和网络安全解决方案)提供框架、预训练模型和工具。工业数字化平台 Omniverse Enterprise 是 Nvidia 生态系统的另一个组成部分,让团队能够开发可互操作的 3D 工作流程和 OpenUSD 应用程序。Omniverse 利用其 OpenUSD 原生平台,使全球分布的团队能够协作处理来自数百个 3D 应用程序的完整设计保真度数据集。此次英伟达主要升级了 Omniverse Kit(用于开发原生 OpenUSD 应用和扩展程序的引擎),以及 NVIDIA Omniverse Audio2Face 基础应用和空间计算功能。开发者可以轻松地利用英伟达提供的 600 多个核心 Omniverse 扩展程序来构建自定义应用。作为发布的一部分,英伟达还推出了三款全新的桌面工作站 Ada Generation GPU:Nvidia RTX 5000、RTX 4500 和 RTX 4000。全新 NVIDIA RTX 5000、RTX 4500 和 RTX 4000 桌面 GPU 采用最新的 NVIDIA Ada Lovelace 架构技术。其中包括增强的 NVIDIA CUDA 核心(用于增强单精度浮点吞吐量)、第三代 RT 核心(用于改进光线追踪功能)以及第四代 Tensor 核心(用于更快的 AI 训练性能)。
5. 贾佳亚团队提出LISA大模型:理解人话「分割一切」,在线可玩
原文:https://mp.weixin.qq.com/s/ia7_55hfI-cs2wWalmk8yA
分割一切这事,又有一项重磅研究入局。
香港中文大学终身教授贾佳亚团队,最新提出LISA大模型——理解人话,精准分割。

例如让AI看一张早餐图,要识别“哪个是橙子”是比较容易的,但若是问一句“哪个食物维他命C最高”呢?毕竟这不是一个简单分割的任务了,而是需要先认清图中的每个食物,还要对它们的成分有所了解。但现在,对于这种人类复杂的自然语言指令,AI已经是没有在怕的了,来看下LISA的表现:
不难看出,LISA精准无误的将橘子分割了出来。再“投喂”LISA一张图并提问:
是什么让这位女士站的更高?请把它分割出来并解释原因。
从结果上来看,LISA不仅识别出来了“梯子”,而且也对问题做出了解释。还有一个更有意思的例子。许多朋友在看到这个大模型的名字,或许会联想到女子组合BLACK PINK里的Lisa。贾佳亚团队还真拿她们的照片做了个测试——让LISA找Lisa:
不得不说,会玩!基于LISA,复杂分割任务拿下SOTA根据发布的论文来看,LISA是一个多模态大模型,它在这次研究中主攻的任务便是推理分割(Reasoning Segmentation)。这个任务要求模型能够处理复杂的自然语言指令,并给出精细的分割结果。
如上图所示,推理分割任务具有很大的挑战性,可能需要借鉴世界知识(例如,左图需要了解“短镜头更适合拍摄近物体”),或进行复杂图文推理(如右图需要分析图像和文本语义,才能理解图中“栅栏保护婴儿”的含义),才能获得最终理想的分割结果。尽管当前多模态大模型(例如Flamingo[1], BLIP-2[2], LLaVA[3], miniGPT-4[4], Otter[5])使得AI能够根据图像内容推理用户的复杂问题,并给出相应的文本分析和回答,但仍无法像视觉感知系统那样在图像上精确定位指令对应的目标区域。因此,LISA通过引入一个标记来扩展初始大型模型的词汇表,并采用Embedding-as-Mask的方式赋予现有多模态大型模型分割功能,最终展现出强大的零样本泛化能力。同时,这项工作还创建了ReasonSeg数据集,其中包含上千张高质量图像及相应的推理指令和分割标注。那么LISA这种精准理解人话的分割能力,具体是如何实现的呢?
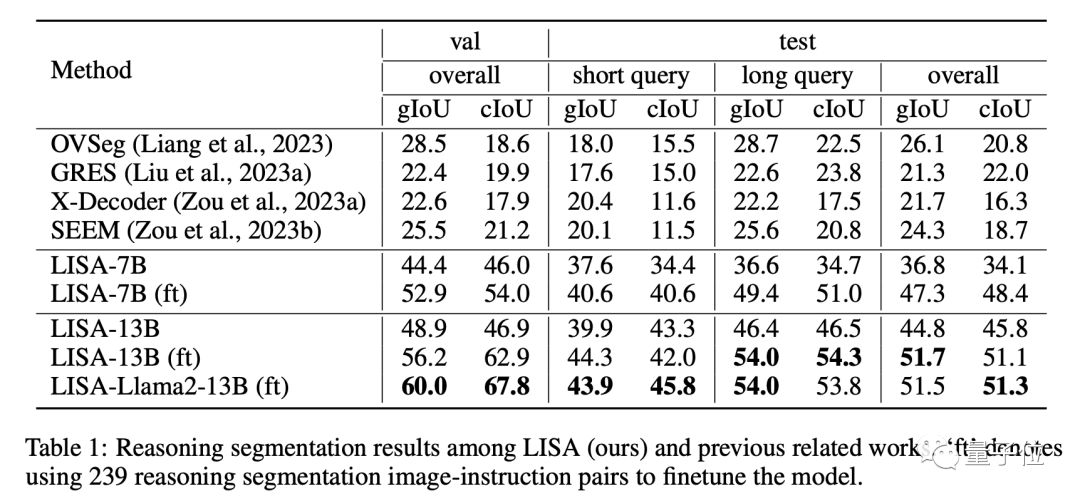
首先将图像ximg和文本xtxt送到多模态-大语言模型F(在实验中即LLaVA),得到输出的文本结果,如果此时文本结果包含标记,则表示需要通过输出分割预测来解决当前问题。反之,若不包含标记,则无分割结果输出。如果存在标记,则将标记在多模态大模型F最后一层对应的embedding经过一个MLP层得到hseg,并将其与分割视觉特征f一起传递给解码器Fdec(其中分割视觉特征f由输入编码器Fenc对图像ximg进行编码得到)。最终,Fdec根据生成最终的分割结果M。LISA在训练过程中使用了自回归交叉熵损失函数,以及对分割结果监督的BCE和DICE损失函数。实验证明,在训练过程中仅使用不包含复杂推理的分割数据(通过将现有的语义分割数据如ADE20K[6],COCO-Stuff[7]以及现有指代分割数据refCOCO系列[8]中的每条数据转换成“图像-指令-分割Mask”三元组) ,LISA能在推理分割任务上展现出优异的零样本泛化能力。此外,进一步使用239个推理分割数据进行微调训练还能显著提升LISA在推理分割任务上的性能。而且LISA还表现出高效的训练特性,只需在8张具有24GB显存的3090显卡上进行10,000次训练迭代,即可完成7B模型的训练。最终,LISA不仅在传统的语言-图像分割指标(refCOCO、refCOCO+和refCOCOg)上展现出优异性能,还能处理以下分割任务情景:⑴复杂推理;⑵联系世界知识;⑶解释分割结果以及⑷多轮对话。
在有复杂情景的ReasonSeg数据集上,LISA显著领先于其他相关工作,进一步证明其出色的推理分割能力。
在线可玩值得一提的是,LISA的推理分割能力已经出了demo,可以在线体验的那种。操作也极其简单,只需填写“指令”,然后上传要处理的图像即可。若是不会描述指令,Demo下方也给出了一些示例,小伙伴们也可以参照一下。
6. 吴恩达来信:LLMs能否理解世界?
原文:https://mp.weixin.qq.com/s/jcy8MdsYFQXVF4MLZIzrmw
亲爱的朋友们,
大型语言模型 (LLMs) 能理解世界吗?作为一名科学家和工程师,我会避免询问人工智能系统是否“理解”某件事情。对于一个系统是否能真正理解——而不是看起来理解——目前还没有得到广泛认可的科学测试,就像我在此前一封来信中讨论的,目前对于“意识”或“感知”也没有这样的测试。这使得“理解”问题成为了哲学问题,而非科学问题。这一警示的出现让我相信LLMs已经建立了足够复杂的世界模型,我有把握说,它们在某种程度上确实了解这个世界。
对我来说,对Othello-GPT的研究是一个令人信服的证明——LLMs建立了世界模型。也就是说,它们确实了解世界的真实面貌,而不是盲目地鹦鹉学舌。Kenneth Li和他的同事们训练了一种GPT语言模型的变体,该模型是根据Othello的移动序列运行的。Othello是一种棋盘游戏,两名玩家轮流在8x8的网格上放置棋子。例如,一个移动序列可能是d3 c5 f6 f5 e6 e3…,其中每对字符(如d3)对应在棋盘的某个位置放置棋子。
在训练过程中,神经网络只会看到一系列的移动,但这些动作是在正方形、8x8棋盘上的移动的,或游戏规则是什么并未明确告知。在对这类棋的大量数据集进行训练后,神经网络在预测下一步棋可能怎么走方面做得不错。
关键问题是:这个网络是通过建立一个世界模型来做出这些预测的吗?也就是说,它是否发现了一个8x8的棋盘,以及一套特定的棋子放置规则,是这些规则支撑着这些移动吗?开发人员们令人信服地给出了证明。具体来说,给定一个移动序列,网络的隐藏单元激活似乎捕捉到当前棋盘位置的表达以及可用的合法走法。这表明,该网络确实建立了一个世界模型,而不是试图模仿其训练数据的统计数据的“随机鹦鹉”。
尽管这项研究使用了Othello,但我毫不怀疑在人类文本上训练的LLMs也建立了世界模型。LLMs的许多“突发”行为——例如,一个经过微调以遵循英语指令的模型也可以遵循用其他语言编写的指令——似乎很难解释,除非我们将其视为“理解世界”。长期以来,人工智能一直在与“理解”这个概念作斗争。哲学家John Searle在1980年发表了“中文房间论”。他提出了一个思想实验:想象一下,一个说英语的人独自呆在一个房间里,手里拿着一本操纵符号的规则手册,他能把从门缝里塞进来的纸上写的中文翻译成英文(尽管他自己并不懂中文)。Searle认为电脑就像这个人。它看起来懂中文,但其实不懂。一个被当做系统回复的反驳观点是,即使“中文房间”场景中没有一个部分能理解中文,但这个人、规则手册、纸张等整个系统都理解中文。同样,我的大脑中没有一个神经元能理解机器学习,但我大脑中包含所有神经元的系统就有可能理解机器学习。在我最近与Geoff Hinton的谈话中,LLMs理解世界的概念是我们双方都同意的一点。虽然哲学很重要,但我很少撰写关于它的文章,因为类似的争论可能会无休止地爆发,我宁愿把时间花在编程上。我不清楚当代哲学家对LLMs理解世界的看法,但我确信我们生活在一个充满奇迹的时代!好了,我们还是回归编程吧。
请不断学习,吴恩达
———————End———————
点击阅读原文进入官网
原文标题:【AI简报20230811期】LLM终于迈向工业控制,但它能否理解世界?
文章出处:【微信公众号:RTThread物联网操作系统】欢迎添加关注!文章转载请注明出处。
 【AI简报20230811期】LLM终于迈向工业控制,但它能否理解世界?
【AI简报20230811期】LLM终于迈向工业控制,但它能否理解世界?






 工商网监
工商网监
评论