 eBPF的前世今生?eBPF在使用中遇到的问题有哪些?
eBPF的前世今生?eBPF在使用中遇到的问题有哪些?
前世BPF
在介绍eBPF (Extended Berkeley Packet Filter)之前,我们先来了解一下它的前身-BPF (Berkeley Packet Filter)伯克利数据包过滤器。
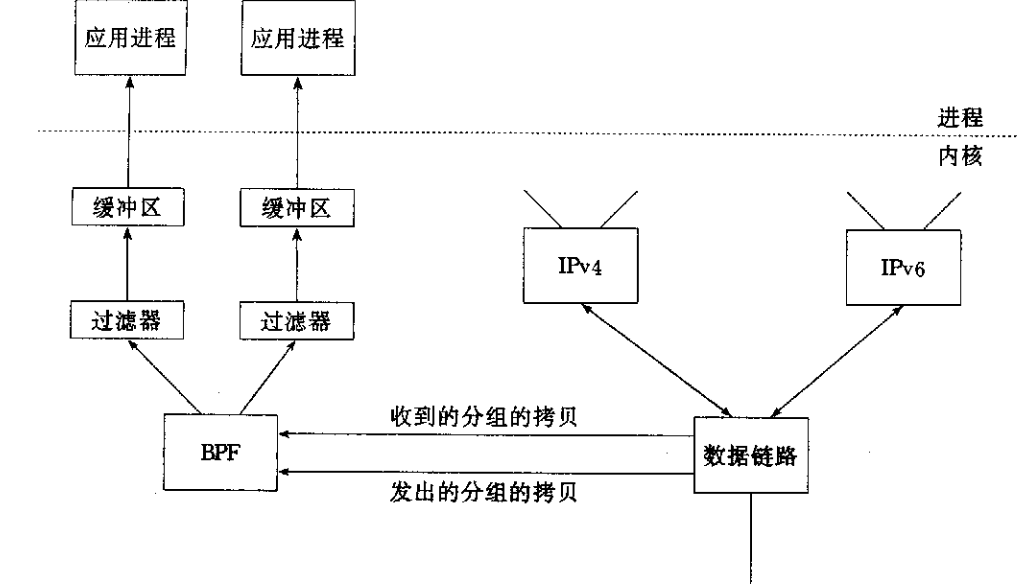
BPF最早由Van Jacobson在1992年开发,用于在Unix操作系统中过滤和捕获网络数据包。它运行在内核中,通过提供一个简单而强大的虚拟机,可以在网络协议层上进行高效的数据包处理操作。BPF通过把过程转换成指令序列来实现,这些指令直接在内核中执行,从而避免了用户空间和内核空间之间频繁的切换。
基于BPF开发的工具库有libpcap、tcpdump等工具。
BPF在网络性能监测和安全策略实施方面具有广泛的应用。然而,由于其指令集的限制和功能的局限性,它无法支持更加复杂和灵活的数据包处理需求。
今生eBPF
正是为了克服BPF的限制,eBPF应运而生。eBPF于2014年(3.18版本)年首次引入Linux内核,并在此后的几年中经历了快速的发展和完善。
eBPF是一个高度可扩展的、运行在内核中的虚拟机,具备与传统BPF相似的指令集,但功能更加强大且更加灵活。eBPF可以在运行时即时编译,从而能够处理更加复杂和动态的数据包处理任务,如网络流量分析、安全检测和性能优化等。

eBPF的灵活性和可扩展性体现在它可以与各种用户空间程序(如tcpdump、Wireshark、Suricata等)和工具(如网络监控、调试器等)无缝集成。eBPF还可以与系统的其他组件(如网络协议栈、调度器等)交互,从而实现更加细粒度的性能优化和安全策略。
此外,eBPF的开发和使用也得到了广泛的支持和推动。社区中有许多致力于eBPF的开发者和贡献者,他们不断改进和扩展eBPF的功能。同时,一些知名的大型技术公司,如Facebook、Netflix和Google等,也在其产品和基础设施中广泛使用eBPF。
eBPF的发展史
2014 年初,Alexei Starovoitov 实现了eBPF。新的设计针对现代硬件进行了优化,所以eBPF生成的指令集比旧的 BPF 解释器生成的机器码执行得更快。扩展版本也增加了虚拟机中的寄存器数量,将原有的 2 个 32 位寄存器增加到10 个 64 位寄存器。由于寄存器数量和宽度的增加,开发人员可以使用函数参数自由交换更多的信息,编写更复杂的程序。总之,这些改进使eBPF版本的速度比原来的 BPF 提高了 4 倍。
eBPF是一项具有革命性的技术,源自于Linux内核,可以在特权环境中运行受沙盒保护的程序,例如操作系统内核。它被用于安全有效地扩展内核的功能,而无需更改内核源代码或加载内核模块。
在历史上,操作系统一直是实现可观察性、安全性和网络功能的理想场所,这是因为内核具有特权能力,可以监督和控制整个系统。与此同时,由于内核在系统中的核心地位以及对稳定性和安全性的高要求,操作系统内核的演进往往很困难。因此,与操作系统外部实现的功能相比,操作系统层面的创新速度传统上较低。
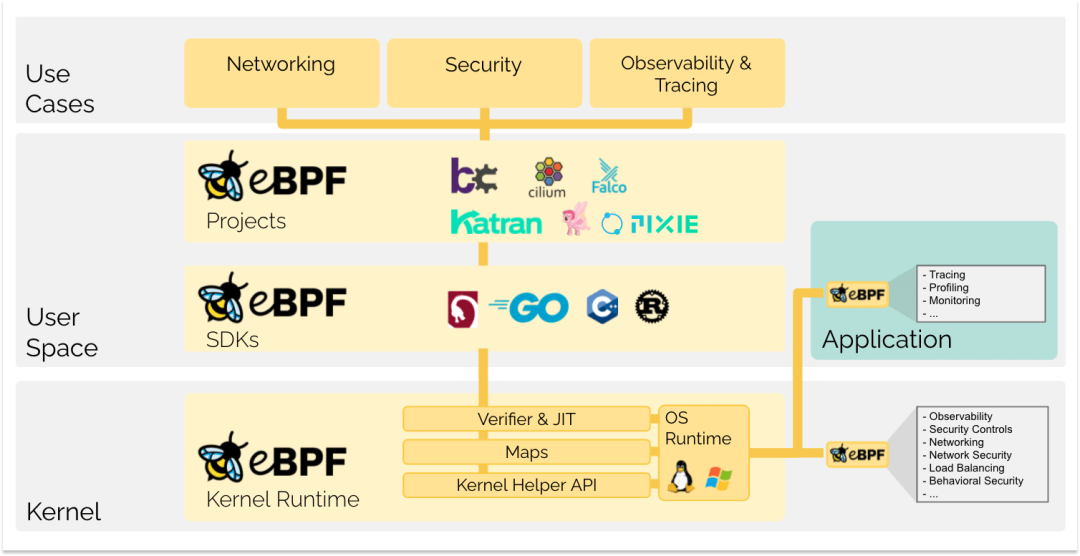
eBPF从根本上改变了这个共识。通过在操作系统内运行受沙盒保护的程序,应用开发人员可以在运行时运行eBPF程序,为操作系统添加额外的功能。操作系统会利用即时编译器和验证引擎的帮助来保证安全性和执行效率,就像本地编译一样。这导致了一系列基于eBPF的项目的涌现,涵盖了各种用例,包括下一代网络、可观测性和安全功能。
如今,eBPF被广泛应用于驱动各种用例:在现代数据中心和云原生环境中提供高性能的网络和负载均衡,以低开销提取细粒度的安全可观测性数据,帮助应用开发人员追踪应用程序、提供性能故障排除的见解,进行预防性应用程序和容器运行时安全执行等等。可能性是无限的,eBPF正在释放出的创新力量才刚刚开始。
Hook Overview
eBPF程序是事件驱动的,当内核或应用程序通过某个挂钩点时运行。预定义的挂钩点包括系统调用、函数入口/退出、内核追踪点、网络事件等等。
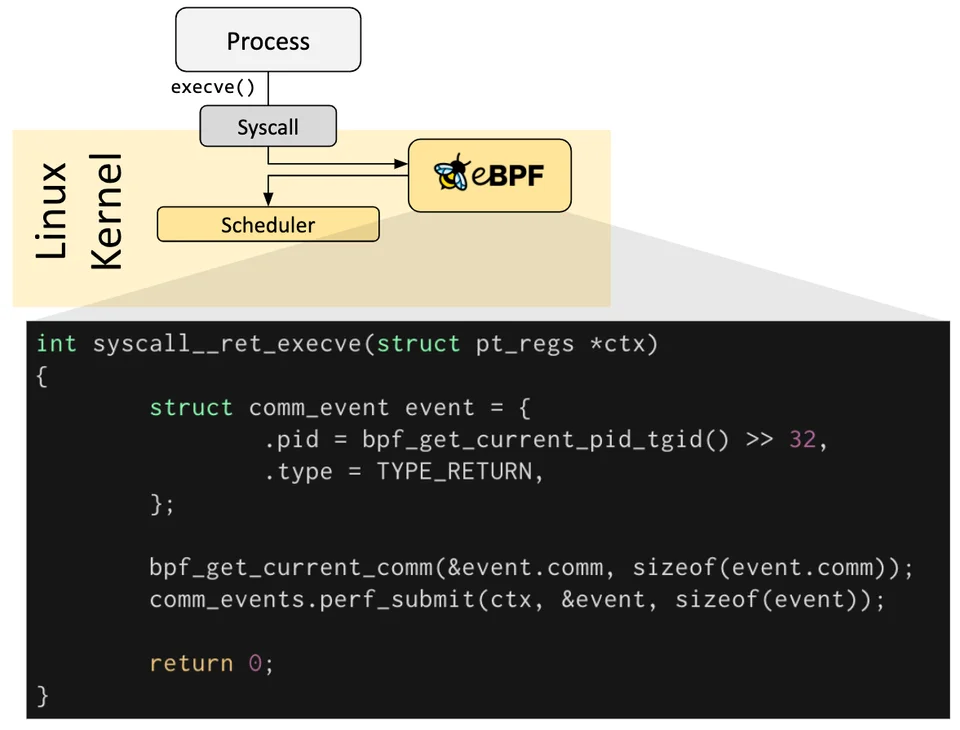
eBPF使用中遇到的问题
1
内核适应性,老版本是否某些功能不可用?
eBPF 最低要求版本为LInux 4.1,eBPF的最低内核版本要求是 Linux 4.1,这是在 2015 年发布的内核版本。在这个版本之前的内核不支持 eBPF。
对于Linux4.1版本之前的监控
擎创对于Linux 4.1.0 之前的版本采用BPF采集HTTP 1数据以及DNS解析请求,进行可观测统计。
对于Linux4.1版本之后的监控
为了保证eBPF程序在各个linux内核版本之间的可移植性,我们编写eBPF程序的时候采用了CORE技术,CORE技术目前只有在 Linux 4.9.0 之后才会支持。
如果用户内核版本低于4.9.0或者内核未开启CO-RE, 我们能够提供linux内核升级包。
2
权限、安全要求
eBPF权限
需要具备root权限或CAP_SYS_ADMIN能力,这意味着只有能够加载内核模块的用户才能加载eBPF程序。
eBPF执行安全
在执行安全方面,eBPF 在加载之前会通过eBPF验证器对要执行的字节码文件进行校验,包括但不限于以下方面:
(1)程序不包含控制循环
(2)程序不会执行超过内核允许的最大指令数
(3)程序不包含任何无法到达的指令
(4)程序不会跳转到程序界限之外
3
uprobe 和 kprobe 差异
kprobe的优劣分析
优势:
(1)更简单实现和更易维护。它不依赖于其他库的具体实现细节
劣势:
(1)用户程序可能会将单个请求分割成多个系统调用,重新组装这些请求会带来一些复杂性
(2)与TLS不兼容, 无法解包TLS
uprobe的优劣分析
优势:
(1)我们可以访问和捕获应用程序上下文,如堆栈跟踪
(2)我们可以构建uprobes以在解析完成后捕获数据,避免在跟踪器中重复工作
(3)可以比较容易捕获https 请求,对TLS兼容性较好
劣势:
(1)对于使用的底层库版本敏感。无法在剥离了符号的二进制文件上运行
(2)需要为每个库实现不同的探针(每种编程语言可能都有自己的一组库)
(3)会导致额外的调用性能开销
4
性能消耗
虽然内核社区已经对 eBPF 做了很多的性能调优,跟踪用户态函数(特别是锁争用、内存分配之类的高频函数)还是有可能带来很大的性能开销。因此,我们在使用 uprobe,kprobe 时,应该尽量避免长时间跟踪高频函数。
我们以监控一个Golang 程序HTTP 1通信过程为例子,在分别开启uprobe和kprobe时候对该程序进行压力测试:
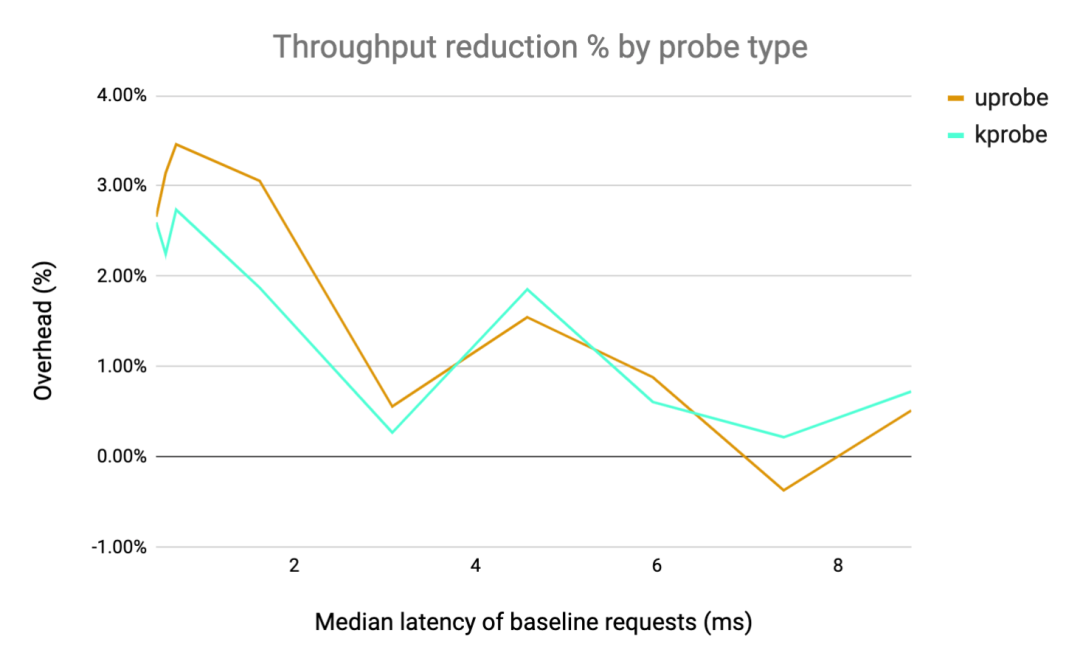
从结果可以看出,如果HTTP延迟大于1毫秒,引入的开销可以忽略不计,在大多数情况下只是噪音。这对于kprobes和uprobes都是类似的,尽管我们重新解析了所有数据,但kprobes的性能稍微好一些。请注意,开销有时是负值,这很可能只是测量中的噪音。在这里的关键要点是,如果您的HTTP处理程序正在进行任何实际的工作(大约1毫秒计算时间),引入的开销基本上可以忽略不计。
5
能否追踪所有用户态/内核态函数
调用的入参和返回值
用户态
eBPF可以追踪指定函数调用入参和返回值。hook点可以为指定函数名称或者地址。如果可执行文件的符号被优化,则需要使用一些逆向手段定位指定函数的地址。
内核态
我们可以使用bpftrace -l了解可以hook的钩子点。
bpftrace是通过读取(下方代码)获取kernel层所有的可跟踪点。
/sys/kernel/debug/tracing/available_filter_functions
6
是否有丢失事件的风险
kprobe和uprobe本身的事件触发并不会丢失
kprobe是一种内核探测机制,它允许用户在内核函数执行前或执行后插入代码。uprobe是一种对用户空间函数进行探测的机制,它允许用户在用户空间函数的入口或出口处插入代码。
eBPF通过将用户编写的处理逻辑加载到内核中,在事件发生时执行此逻辑,以实现用户级的观察和处理。由于eBPF的虚拟机技术提供了一种安全可隔离的方式来在内核中执行用户代码,因此kprobe和uprobe事件不会丢失。
bpf_perf_event会有丢失事件的风险
内核态的eBPF代码将收集到的事件写入 bpf_perf_event 环形缓冲区,用户态程序进行收集上报。当读写速度不匹配时,就会丢失事件:
(1)写速度过快:例如每个HTTP transaction都作为一个event写入缓冲区,这样比批量写的风险更高。
(2)读速度过慢:例如用户态代码没有在专门线程中读取缓冲区,或者系统负载过高。
bpf_map会有丢失事件的风险
eBPF map有大小限制,当map被写满的时,将无法写入新的数据
(1)丢失数据:由于map已满,新的写入操作将无法成功,导致数据丢失。这可能会影响到程序的正确性和完整性。
(2)性能下降:当map写满时,写入操作将被阻塞,导致系统的性能下降。这会影响到整体的系统响应时间和吞吐量。
展望
随着eBPF的不断发展和壮大,我们可以看到它在网络和系统领域的巨大潜力。eBPF已经被证明是一种强大且高效的工具,可以用于实现各种高级网络和系统功能。
在未来,我们有理由相信eBPF将继续发展,并被越来越多的开发者和组织使用。随着eBPF功能的不断扩展和完善,我们可以期待更多创新的网络应用和系统工具的出现,从而推动整个行业向前发展。
总之,eBPF的前世今生令人振奋,它不仅继承了BPF的优点,还拥有更强大和灵活的功能。我们期待看到eBPF为网络和系统带来更多的创新和改进,为我们的数字化世界带来更强大的支撑。
审核编辑:刘清
-
UNIX操作系统
+关注
关注
0文章
13浏览量
15299 -
虚拟机
+关注
关注
1文章
908浏览量
28066 -
过滤器
+关注
关注
1文章
427浏览量
19550 -
LINUX内核
+关注
关注
1文章
316浏览量
21614 -
调度器
+关注
关注
0文章
98浏览量
5237
原文标题:聊聊eBPF的前世今生
文章出处:【微信号:magedu-Linux,微信公众号:马哥Linux运维】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
实战eBPF kprobe函数插桩
解构内核源码eBPF样例编译过程
基于ebpf的性能工具-bpftrace脚本语法
关于 eBPF 安全可观测性,你需要知道的那些事儿
openEuler 倡议建立 eBPF 软件发布标准
eBPF是什么以及eBPF能干什么

介绍eBPF针对可观测场景的应用
openEuler倡议建立eBPF软件发布标准
Linux 内核:eBPF优势和eBPF潜力总结
Linux内核观测技术eBPF中文入门指南
什么是eBPF,eBPF为何备受追捧?
基于ebpf的性能工具-bpftrace

ebpf的快速开发工具--libbpf-bootstrap
eBPF动手实践系列三:基于原生libbpf库的eBPF编程改进方案简析






 工商网监
工商网监
评论