 UDP有发送缓存区吗?如何解决UDP丢包的问题呢?
UDP有发送缓存区吗?如何解决UDP丢包的问题呢?
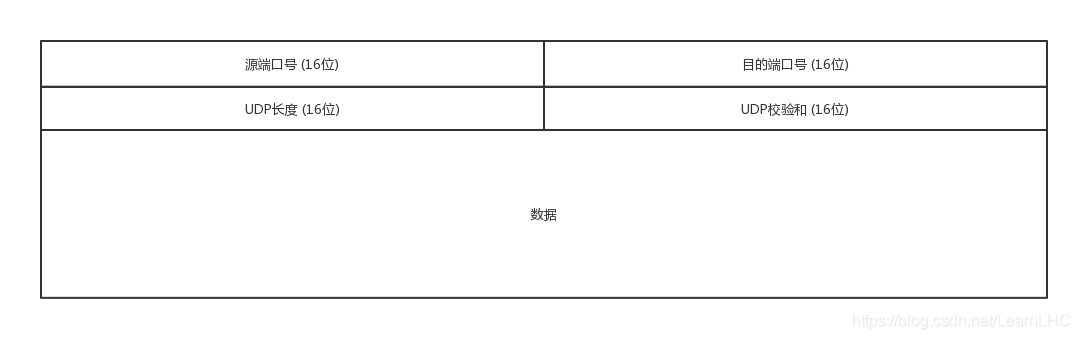
一、UDP 报文格式
每个 UDP 报文分为 UDP 报头和 UDP 数据区两部分。报头由 4 个 16 位长(2 字节)字段组成,分别说明该报文的源端口、目的端口、报文长度和校验值。
UDP 报文格式如图所示。
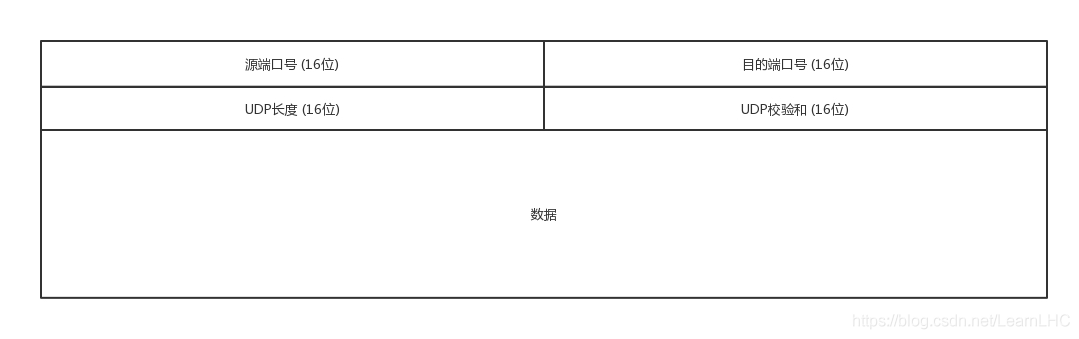
UDP 报文中每个字段的含义如下:
源端口: 16bits,发送端的端口。
目的端口:16bits,即接收端的端口
长度: 16bits,UDP 数据包总的大小:包头+数据,单位:字节。
校验值: 16bits,错误检查码,基于算法,计算此 UDP 数据包是否损坏
二、UDP 分片
1、UDP 有发送缓存区吗?
TCP 有 发送/接收 缓存区,那 UDP 有么?
1>、先说结论:
每个 UDP socket 都有一个接收缓冲区,****没有发送缓冲区****,从概念上来说就是只要有数据就发,不管对方是否可以正确接收,所以不缓冲,不需要发送缓冲区。
UDP:当套接口接收缓冲区满时,新来的数据报无法进入接收缓冲区,此数据报就被丢弃。UDP是没有流量控制的;快的发送者可以很容易地就淹没慢的接收者,导致接收方的 UDP 丢弃数据报。
且,如果在传输过程中,一次传输被分成多个分片,传输中有一个小分片丢失,那接收端最终会舍弃整个文件,导致传输失败,这就是 UDP 不可靠的原因。
2>、逐步分析:
linux手册中有设置 UDP 发送缓冲区相关属性,也明确提到了send buffer的概念:
那这是否意味着 UDP 是有发送缓冲区的吗?我们再看一下《UNIX Network Programming》书中所述,这本书的作者权威性我就不多说了吧,在国内高校此书都是当做教材使用的。书中有下面两幅图:
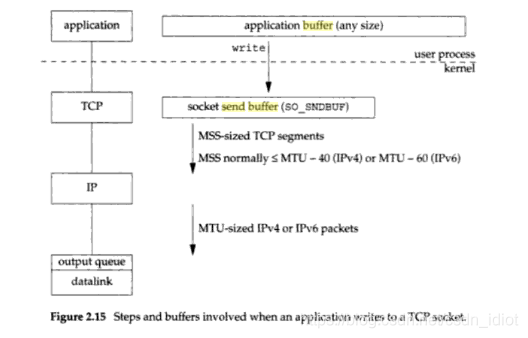
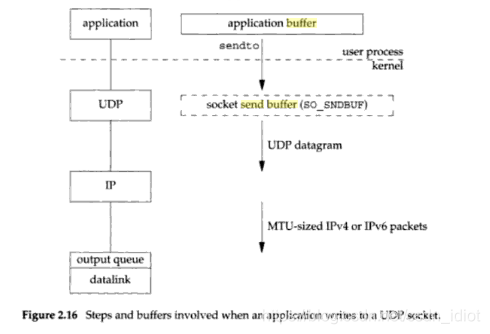
一张是 TCP 发送过程协议栈简化图,另一张是 UDP 的。UDP 中的 send buffer 是用虚线框圈起来的,具体的叙述我直接引用书中原文:

书中的描述很清楚了,UDP 是没有发送缓冲区的,因为 UDP 是不可靠的,他不必像 TCP 一样需要一个实质的发送buffer,而且真正 UDP 写成功返回其实是传递到了链路层的 output queue 中。
2、UDP 分片
1>、UDP 包最佳传输大小
数据链路层 最大传输单元是 1500 字节 (MTU) ,要想 IP 层不分包,那么 UDP 数据包的最大大小应该是1500字节 – IP头(20字节) – UDP头(8字节) = 1472字节。
但,理论上 UDP 报文最大长度是 65507 字节,那:实际上发送这么大的数据包效果最好吗?
我们来看分析一下 “分片问题”
2>、分片问题
我们知道 UDP 是不可靠的传输协议,为了减少 UDP 包丢失的风险,我们最好能控制 UDP 包在 IP层协议的传输过程中不要被切割。
这是为什么呢?
如果 MTU 是1500,Client 发送一个 8000字节大小的 UDP 包,那么 Server 端阻塞模式下接包,在不丢包的情况下,recvfrom(9000) 是收到 1500,还是 8000。如果某个 IP 分片丢失了,recvfrom(9000),又返回什么呢?
根据 UDP 通信的有界性,在 buf 足够大的情况下,接收到的一定是一个完整的数据包,UDP 数据在下层的分片和组片问题由 IP 层来处理,提交到 UDP 传输层一定是一个完整的 UDP 包,那么 recvfrom(9000) 将返回 8000。如果某个 IP 分片丢失,udp 里有个 CRC 检验,如果包不完整就会丢弃,也不会通知是否接收成功,所以 UDP 是不可靠的传输协议,那么 recvfrom(9000) 将阻塞。
分片分的越多,虽然在传输层都是一次 send,一次 recv ,但在传输过程中,会传输多次,那么丢包的概论就越大,如何解决丢包问题呢?
三、UDP 丢包的原因
前提:
在不考虑 IP 层的分片丢失,CRC 检验包不完整的情况下
1、UDP 缓冲区满,造成的丢包
如果 socke t缓冲区满了,应用程序没来得及处理在缓冲区中的 UDP 包,那么后续来的 UDP 包会被内核丢弃,造成丢包。
在 socket 缓冲区满造成丢包的情况下,可以通过增大缓冲区的方法来缓解UDP丢包问题。但是,如果服务已经过载了,简单的增大缓冲区并不能解决问题,反而会造成滚雪球效应,造成请求全部超时,服务不可用。
2、UDP 缓冲区过小或文件过大,造成的丢包:
如 果Client 发送的 UDP 报文很大,而 socket 缓冲区过小无法容下该 UDP 报文,那么该报文就会丢失。
以前遇到过这种问题,我把接收缓冲设置成 64K 就解决了。
int nRecvBuf=32*1024;//设置为32K
setsockopt(s,SOL_SOCKET,SO_RCVBUF,(const char*)&nRecvBuf,sizeof(int));
3、ARP 缓存过期,导致丢包:
ARP 的缓存时间约 10 分钟,APR 缓存列表没有对方的 MAC 地址或缓存过期的时候,会发送 ARP 请求获取 MAC 地址,
在没有获取到 MAC 地址之前,用户发送出去的 UDP 数据包会被内核缓存到 arp_queue 这个队列中,默认最多缓存 3 个包,多余的 UDP 包会被丢弃。
4、接收端处理时间过长导致丢包:
调用 recv 方法接收端收到数据后,处理数据花了一些时间,处理完后再次调用 recv 方法,在这二次调用间隔里,发过来的包可能丢失。
对于这种情况可以修改接收端,将包接收后存入一个缓冲区,然后迅速返回继续 recv。
5、发送的包巨大丢包:
虽然 send 方法会帮你做大包切割成小包发送的事情,但包太大也不行。
例如超过 50K 的一个 udp 包,不切割直接通过send 方法发送也会导致这个包丢失。这种情况需要切割成小包再逐个 send。
6、发送的包频率太快:
虽然每个包的大小都小于 mtu size 但是频率太快,例如 40 多个 mut size 的包连续发送中间不 sleep,也有可能导致丢包。
这种情况也有时可以通过设置 socket 接收缓冲解决,但有时解决不了。
所以在发送频率过快的时候还是考虑 sleep一下吧。
7、局域网内不丢包,公网上丢包。
这个问题我也是通过切割小包并 slee p发送解决的。如果流量太大,这个办法也不灵了。
总之 udp 丢包总是会有的,如果出现了用我的方法解决不了,还有这个几个方法:要么减小流量,要么换 tcp 协议传输,要么做丢包重传的工作。
四、UDP 丢包的解决方案
1. 从发送端解决 - 延迟发送
适用条件:
①发送端是可以控制的.
②微秒数量级的延迟可以接受.
解决方法:
发送时使用 usleep(1) 延迟 1 微秒发送,即发送频率不要过快
延迟1微妙发送,可以很好的解决这个问题.
2.从接收端解决:数据接收 与 数据处理相分离
适用条件:
①无法控制发送端发送数据的频率
解决方法:
用 recvfrom 函数收到数据之后尽快返回,进行下一次 recvfrom,可以通过 多线程+队列 来解决。
收到数据之后将数据放入队列中,另起一个线程去处理收到的数据.
3.从接收端解决:修改接收缓存大小
适用条件:
使用方法 2 依然出现大规模丢包的情况,需要进一步优化
解决方法:
使用 setsockopt 修改接收端的缓冲区大小
intrcv_size=1024*1024;//1M intoptlen=sizeof(rcv_size); //设置好缓冲区大小 interr=setsockopt(sock,SOL_SOCKET,SO_RCVBUF,(char*)&rcv_size,optlen);
设置完毕可以通过下列函数,来查看当前 sock 的缓冲区大小
setsockopt(sock,SOL_SOCKET,SO_RCVBUF,(char*)&rcv_size,(socklen_t*)&optlen);
但是,会发现查到的大小并不是1M而是256kb,后来发现原来是 linux 系统默认缓冲区大小为 128kb,设置最大是这个的 2倍,所以需要通过修改系统默认缓冲区大小来解决
使用root账户在命令行下输入:
vi/etc/sysctl.conf
添加一行记录(1049576=1024*1024=1M)
net.core.rmem_max=1048576
保存之后输入
/sbin/sysctl-p
使修改的配置生效
此时可以通过 sysctl -a|grep rmem_max 来看配置是否生效.
生效之后可以再次运行程序来 getsockopt 看缓冲区是否变大了,是否还会出现丢包现象了
楼主使用的是 方法2+方法3 双管齐下,已经不会出现丢包现象了,如果还有不同程度的丢包 可以通过方法三种继续增加缓冲区大小的方式来解决。
五、UDP 实现对方百分百收到数据
1、UDP 致命性缺点:
UDP 是无连接的,面向消息的数据传输协议,与TCP相比,有两个致命的缺点
一是:数据包容易丢失
二是:数据包无序
2、解决方案 - 回复 + 重发 + 编号 机制:
1>、分析:
要实现文件的可靠传输,就必须在上层对数据丢包和乱序作特殊处理,必须要有要有 丢包重发机制 和 超时机制。
常见的可靠传输算法有模拟 TC P协议,重发请求(ARQ)协议,它又可分为连续 ARQ 协议、选择重发 ARQ 协议、滑动窗口协议等等。
如果只是小规模程序,也可以自己实现丢包处理,原理基本上就是给文件分块,每个数据包的头部添加一个唯一标识序号的 ID 值,当接收的包头部 ID 不是期望中的 ID 号,则判定丢包,将丢包 ID 发回服务端,服务器端接到丢包响应则重发丢失的数据包。
模拟 TCP 协议也相对简单,3 次握手的思想对丢包处理很有帮助
2>、回复 + 重发 + 编号 机制
1)接收方收到数据后,回复一个确认包
如果你不回复,那么发送端是不会知道接收方是否成功收到数据的。
比如:A 要发数据 “{data}” 到 B,那 B 收到后,可以回复一个特定的确认包 “{OK}”,表示成功收到。
但是如果只做上面的回复处理,还是有问题:
比如 B 收到数据后回复给 A 的数据 "{OK}" 的包,A 没收到,怎么办呢???
2)当 A 没有收到B的 "{OK}" 包后,要做定时重发数据
定时重发,直到成功接收到确认包为止,再发下面的数据,当然,重发了一定数量后还是没能收到确认包,可以执行一下 ARP 的流程,防止对方网卡更换或别的原因。
但是这样的话,B 会收到很多重复的数据,假如每次都是 B 回复确认包 A 收不到的话。
3)发送数据的包中加个标识符 - 编号
比如 A 要发送的数据 "标识符data" 到 B,B 收到后,先回复 “{OK}" 确认包,再根据原有的标识符进行比较,如果标识符相同,则数据丢失,如果不相同,则原有的标识符 = 接收标识符,且处理数据。
当 A 发送数据包后,没有收到确认包,则每隔 x 秒,把数据重发一次,直到收到确认包后,更新一下标识符,再进行后一包的数据发送。
经过上面1),2),3)点的做法,则可以保证数据百分百到达对方,当然,标识符用 ID 号来代替更好。
3、解决方案 - 冗余传输方案:
在外网通信链路不稳定的情况下,有什么办法可以降低UDP的丢包率呢?
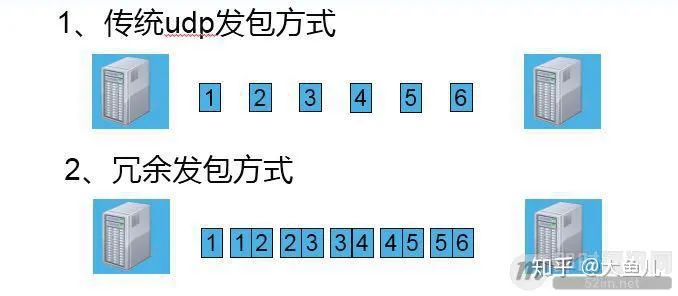
一个简单的办法来采用冗余传输的方式。
如下图,一般采用较多的是延时双发,双发指的是将原本单发的前后连续的两个包合并成一个大包发送,这样发送的数据量是原来的两倍。
这种方式提高丢包率的原理比较简单,例如本例的冗余发包方式,在偶数包全丢的情况下,依然能够还原出完整的数据,也就是在这种情况下,50%的丢包率,依然能够达到100%的数据接收。
4、解决方案 - RUDP:
文章摘录:
UDP 实现可靠性既然那么麻烦,那直接用 TCP 好了!
确实很多人也都是这样做的,TCP 是个基于公平性的可靠通信协议,但是在一些苛刻的网络条件下 TCP 要么不能提供正常的通信质量保证,要么成本过高。为什么要在 UDP 之上做可靠保证,究其原因就是在保证通信的时延和质量的条件下尽量降低成本。
RUDP 主要解决以下相关问题:
端对端连通性问题:一般终端直接和终端通信都会涉及到 NAT 穿越,TCP 在 NAT 穿越实现非常困难,相对来说 UDP 穿越 NAT 却简单很多,如果是端到端的可靠通信一般用 RUDP 方式来解决,场景有:端到端的文件传输、实时音视频传输、交互指令传输等等。【UDP NAT穿越简单很多】
弱网环境传输问题:在一些 Wi-Fi 或者 3G/4G 移动网下,需要做低延迟可靠通信,如果用 TCP 通信延迟可能会非常大,这会影响用户体验。例如:实时的操作类网游通信、语音对话、多方白板书写等,这些场景可以采用特殊的 RUDP 方式来解决这类问题;【弱网传输UDP延长会低很多】
带宽竞争问题:有时候客户端数据上传需要突破本身 TCP 公平性的限制来达到高速低延时和稳定,也就是说要用特殊的流控算法来压榨客户端上传带宽,例如:直播音视频推流,这类场景用 RUDP 来实现不仅能压榨带宽,也能更好地增加通信的稳定性,避免类似 TCP 的频繁断开重连;
传输路径优化问题:在一些对延时要求很高的场景下,会用应用层 relay 的方式来做传输路由优化,也就是动态智能选路,这时双方采用 RUDP 方式来传输,中间的延迟进行 relay 选路优化延时。还有一类基于传输吞吐量的场景,例如:服务与服务之间数据分发、数据备份等,这类场景一般会采用多点并联 relay 来提高传输的速度,也是要建立在 RUDP 上的(这两点在后面着重来描述);
资源优化问题:某些场景为了避免 TCP 的三次握手和四次挥手的过程,会采用 RUDP 来优化资源的占用率和响应时间,提高系统的并发能力,例如 QUIC。
六、UDP 真的比 TCP 要高效吗
相信很多同学都认为 UDP 无连接,无需重传和处理确认,UDP 比较高效。
然而 UDP 在大多情况下并不一定比 TCP 高效,TCP 发展至今天,为了适应各种复杂的网络环境,其算法已经非常丰富,协议本身经过了很多优化,如果能够合理配置 TCP 的各种参数选项,那么在多数的网络环境下 TCP 是要比 UDP 更高效的。
影响 UDP 高效因素有以下3点:
**1、 无法智能利用空闲带宽导致*资源利用率低*:
一个简单的事实是 UDP 并不会受到 MTU 的影响,MTU 只会影响下层的 IP 分片,对此 UDP 一无所知。
在极端情况下,UDP 每次都是发小包,包是 MTU 的几百分之一,这样就造成 UDP 包的有效数据占比较小 (UDP 头的封装成本);
或者,UDP 每次都是发巨大的 UDP 包,包大小是 MTU 的几百倍,这样会造成下层 IP 层的大量分片,大量分片的情况下,其中某个分片丢失了,就会导致整个 UDP 包的无效。
由于网络情况是动态变化的,UDP 无法根据变化进行调整,发包过大或过小,从而导致带宽利用率低下,有效吞吐量较低。
****而 TCP 有一套智能算法****,当发现数据必须积攒的时候,就说明此时不积攒也不行,TCP 的复杂算法会在延迟和吞吐量之间达到一个很好的平衡。
2、无法动态调整发包:
由于 UDP 没有确认机制,没有流量控制和拥塞控制,这样在网络出现拥塞 或 通信两端处理能力不匹配的时候,UDP 并不会进行调整发送速率,从而导致大量丢包。
在丢包的时候,不合理的简单重传策略会导致重传风暴,进一步加剧网络的拥塞,从而导致丢包率雪上加霜。
更加严重的是,UDP 的 无秩序性和自私性,一个疯狂的 UDP 程序可能会导致这个网络的拥塞,挤压其他程序的流量带宽,导致所有业务质量都下降。
3、改进 UDP 的成本较高:
可能有同学想到针对 UDP 的一些缺点,在用户态做些调整改进,添加上简单的重传和动态发包大小优化。
然而,这样的改进并比简单的,UDP 编程可是比 TCP 要难不少的,考虑到改造成本,为什么不直接用TCP呢?
当然可以拿开源的一些实现来抄一下(例如:libjingle),或者拥抱一下 Google 的 QUIC 协议,然而,这些都需要不少成本的。
上面说了这么多,难道真的不该用UDP了吗?
其实也不是的,在某些场景下,我们还是必须 UDP 才行的。那么 UDP 的较为合适的使用场景是哪些呢?
七、UDP 协议的正确使用场合
1、高通信 实时性要求 和 低持续性要求 的场景下
**在分组交换通信当中,*协议栈的成本*主要表现在以下两方面:
[1] 封装带来的空间复杂度;
[2] 缓存带来的时间复杂度。
以上两者是对立影响的,如果想减少封装消耗,那么就必须缓存用户数据到一定量在一次性封装发送出去,这样每个协议包的有效载荷将达到最大化,这无疑是节省了带宽空间,带宽利用率较高,但是延时增大了。
如果想降低延时,那么就需要将用户数据立马封装发出去,这样显然会造成消耗更多的协议头等消耗,浪费带宽空间。
因此,我们进行协议选择的时候,需要重点考虑一下空间复杂度 和 时间复杂度间 的 平衡。
**通信的持续性对两者的影响比较大,根据*通信的持续性*有两种通信类型:
[1] 短连接通信;
[2] 长连接通信。
对于短连接通信:
一方面如果业务只需要发一两个包并且对丢包有一定的容忍度,同时业务自己有简单的轮询或重复机制,那么采用 UDP 会较为好些。
在这样的场景下,如果用 TCP,仅仅握手就需要 3 个包,这样显然有点不划算,一个典型的例子是 DNS 查询。
另一方面,如果业务实时性要求非常高,并且不能忍受重传,那么首先就是 UDP 了或者只能用 UDP 了,例如 NTP 协议,重传 NTP 消息纯属添乱(为什么呢?重传一个过期的时间包过来,还不如发一个新的 UDP 包同步新的时间过来)。
如果 NTP 协议采用 TCP,撇开握手消耗较多数据包交互的问题,由于 TCP 受 Nagel 算法等影响,用户数据会在一定情况下会被内核缓存延后发送出去,这样时间同步就会出现比较大的偏差,协议将不可用。
2、多点通信的场景下
对于一些多点通信的场景,如果采用有连接的 TCP,那么就需要和多个通信节点建立其双向连接,然后有时在 NAT 环境下,两个通信节点建立其直接的 TCP 连接不是一个容易的事情,在涉及 NAT 穿越的时候,UDP 协议的无连接性使得穿透成功率更高.
(原因详见:由于 UDP 的无连接性,那么其完全可以向一个组播地址发送数据或者轮转地向多个目的地持续发送相同的数据,从而更为容易实现多点通信。)
一个典型的场景是:
****多人实时音视频通信****,这种场景下实时性要求比较高,可以容忍一定的丢包率。
比如:对于音频,对端连续发送 p1、p2、p3 三个包,另一端收到了 p1 和 p3,在没收到 p2 的保持 p1 的最后一个音(也是为什么有时候网络丢包就会听到嗞嗞嗞嗞嗞嗞…或者卟卟卟卟卟卟卟卟…重音的原因),等到到 p3 就接着播 p3 了,不需要也不能补帧,一补就越来越大的延时。
对于这样的场景就比较合适用 UDP 了,如果采用 TCP,那么在出现丢包的时候,就可能会出现比较大的延时。
3、UDP应用举例
通常情况下,UDP 的使用范围是较小的,在以下的场景下,使用 UDP 才是明智的。
[1] 实时性要求很高,并且几乎不能容忍重传:例子:NTP 协议,实时音视频通信,直播、实时游戏、多人动作类游戏中人物动作、位置。
[2] TCP 实在不方便实现多点传输的情况;
[3] 需要进行 NAT 穿越;
[4] 对网络状态很熟悉,确保 udp 网络中没有氓流行为,疯狂抢带宽;
[5] 熟悉 UDP 编程。
UDP本身是不可靠,现在需要保证可靠,在不改变 UDP 协议的情况下能够想到的是在应用层做可靠性设计,但是应用层做可能通用性会差一些,那么在传输层和应用层之间加一层实现UDP的可靠性呢?
基于这个想法提出了RUDP(Reliable UDP),实际上,已经有项目在这么做了,比如 Google 的 QUIC 和 WebRTC。
*据了解,目前国内厂商做**实时传输**一般都会考虑 RUDP。*
4、QQ udp 浅析
1>、用 tcp 长连接,对服务器的负担很大
首先每一个 QQ 客户端实际上都适合服务器交互,再由服务器转发给正在通信的用户,如果每一个 QQ 从一上线到下线的这段时间全部采用 tcp 长连接,这对服务器的负担很大,而如果采用 tcp 短连接,频繁的连接断开也会造成网络负担,而采用 udp 则可以避开上述麻烦,减少服务器的负担。
不管 udp 还是 tcp,最终登陆成功之后,QQ 都会有一个 tcp 连接来保持在线状态。这个 tcp 连接的远程端口一般是80,采用 udp 方式登陆的时候,端口是8000。
udp 协议是无连接方式的协议,它的效率高,速度快,占资源少,但是其传输机制为不可靠传送,必须依靠辅助的算法来完成传输控制。
QQ 采用的通信协议以 udp 为主,辅以 tcp 协议。由于 QQ 的服务器设计容量是海量级的应用,一台服务器要同时容纳十几万的并发连接,因此服务器端只有采用 udp 协议与客户端进行通讯才能保证这种超大规模的服务。
2>、tcp 较难实现 NAT 穿越
QQ 客户端之间的消息传送也采用了 udp 模式,因为国内的网络环境非常复杂,而且很多用户采用的方式是通过代理服务器共享一条线路上网的方式
在这些复杂的情况下,客户端之间能彼此建立起来 tcp 连接的概率较小,严重影响传送信息的效率。
而 udp 包能够穿透大部分的代理服务器,因此 QQ 选择了 udp 作为客户之间的主要通信协议。采用 udp 协议,通过服务器中转方式。因此,现在的 IP 侦探在你仅仅跟对方发送聊天消息的时候是无法获取到IP的。
3>、让 UDP 变得可靠
大家都知道,udp 协议是不可靠协议,它只管发送,不管对方是否收到的,但它的传输很高效。
但是作为聊天软件,怎么可以采用这样的不可靠方式来传输消息呢?
于是,腾讯采用了上层协议来保证可靠传输:如果客户端使用 udp 协议发出消息后,服务器收到该包,需要使用 udp 协议发回一个应答包,如此来保证消息可以无遗漏传输。
之所以会发生在客户端明明看到"消息发送失败"但对方又收到了这个消息的情况,就是因为客户端发出的消息服务器已经收到并转发成功,但客户端由于网络原因没有收到服务器的应答包引起的。
QQ 并不是端对端的聊天软件,是得经过服务器转发消息的,通过 QQ 聊天,数据是 A 发到服务器,服务器再转发到 B。
审核编辑:刘清
-
控制器
+关注
关注
112文章
16444浏览量
179339 -
缓冲器
+关注
关注
6文章
1930浏览量
45626 -
CRC校验
+关注
关注
0文章
84浏览量
15273 -
WebRTC
+关注
关注
0文章
57浏览量
11289 -
UDP通信
+关注
关注
0文章
21浏览量
1956
原文标题:学习UDP会调个函数、发个报文就完事了?
文章出处:【微信号:最后一个bug,微信公众号:最后一个bug】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
NONOS如何检查是否实际发送了UDP数据包?
lwip协议中udp包的接收与发送
LabView UDP如何设置Socket接收缓冲区?
UDP协议,UDP协议是什么意思
什么是udp攻击?udp攻击的基本原理是什么
Linux内核网络数据包发送在UDP协议层的处理

UDP分片与丢包,UDP真的比TCP高效吗?
TCP和UDP的原理以及区别
UDP分片和丢包与TCP效果对比
udp是什么协议?udp协议介绍
UDP丢包的原因和解决方案





 工商网监
工商网监
评论