 重内存、可拆分,暴力堆机器……Calibre技术向攻略
重内存、可拆分,暴力堆机器……Calibre技术向攻略
Siemens的Calibre是业内权威的版图验证软件,被各大Foundry厂广泛认可。用户可以直接在Virtuoso界面集成Calibre接口,调用版图验证结果数据,使用起来极为方便。
今天,我们就来聊聊这款软件。
版图验证是芯片设计中非常重要的一环,一共包括三个环节。
DRC(Design Rule Check):检查版图是否符合Foundry厂的制造工艺规则,确保芯片能被正确生产出来;
LVS(Layout Versus Schematic):版图工程师需要将画好的版图与原理图对比,确保两者所有连接保持一致;
寄生参数提取(Parasitic Extraction):将版图中的寄生参数提取出来,在Virtuoso中反馈结果,前端工程师会进行后仿验证,重新评估电路特性并进行修改,保证流片正确。

这三个环节分别由Calibre的DRC、LVS、PEX三种工具来完成。
Calibre任务典型特性
重内存,可拆分,适合暴力堆机器
Calibre任务有两大特性:
1、重内存需求,2T或4T的超大型内存机器都有可能登场
版图文件很大,需要处理的数据量非常大,但本身的逻辑判断并不复杂,所以通常不刚需高主频机型,但要求多核、大内存的机器。CPU与内存的比例通常能达到1:4或1:8,极端情况下这个比例会更高,2T或4T的超大型内存机器都有可能登场。
2、可拆分,无关联,适合暴力堆机器
我们在模拟这篇文里写过版图验证就像是一个“大家来找茬“的游戏。
在运行任务的时候,Calibre会把版图切分成相互没有逻辑关系的块状分区,这些分区之间彼此没有相关性,互不干扰,所以可以同时进行。
切得越细,同时检查的人更多,效率就越高。
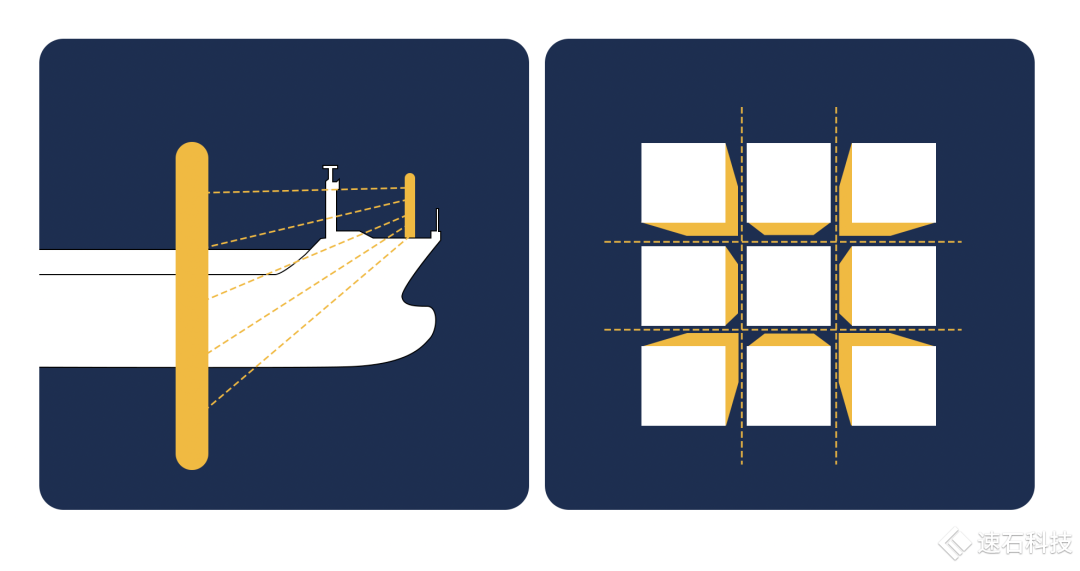
三体里的切法大家还记得吧,一字横切。
而芯片只能竖着切,可以十字切法。横切会影响到芯片层与层之间的连接关系。
暴力堆机器也是有技术含量的
1、 首先,要有光,你得有大内存的机器
我们的全球资源池可以根据用户需求在全球范围内调度海量云端异构资源。GPU、TPU、FPGA,要啥都有。
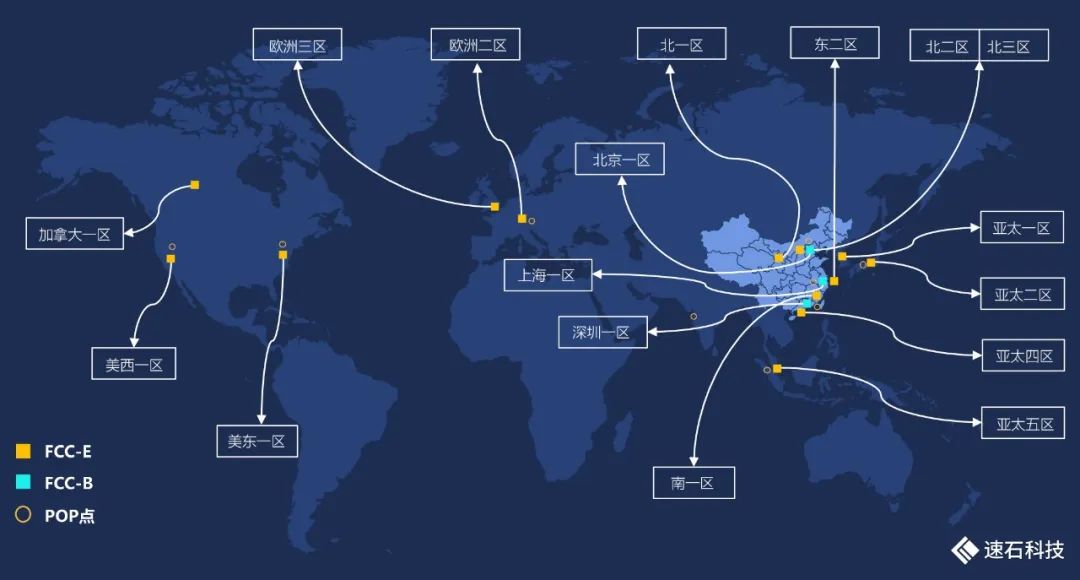
其中,FCC-B产品提供准动态资源池,拥有行业特需的大内存机型,具有较低的整体拥有成本。而且,可以扩展到FCC-E使用弹性资源。
总之,大内存的机器,没有问题。
那么,万一不是一直不够,是偶尔不够怎么办呢?
我们有一个小技巧,专门应用这种内存峰值场景。
Swap,交换分区,就是在内存不够的情况下,操作系统先把内存中暂时不用的数据,存到硬盘的交换空间,腾出内存来让别的程序运行。
比如跑一组Calibre任务需要10小时,其中9个小时的内存使用量都在200G左右,只有1个小时达到了260G。
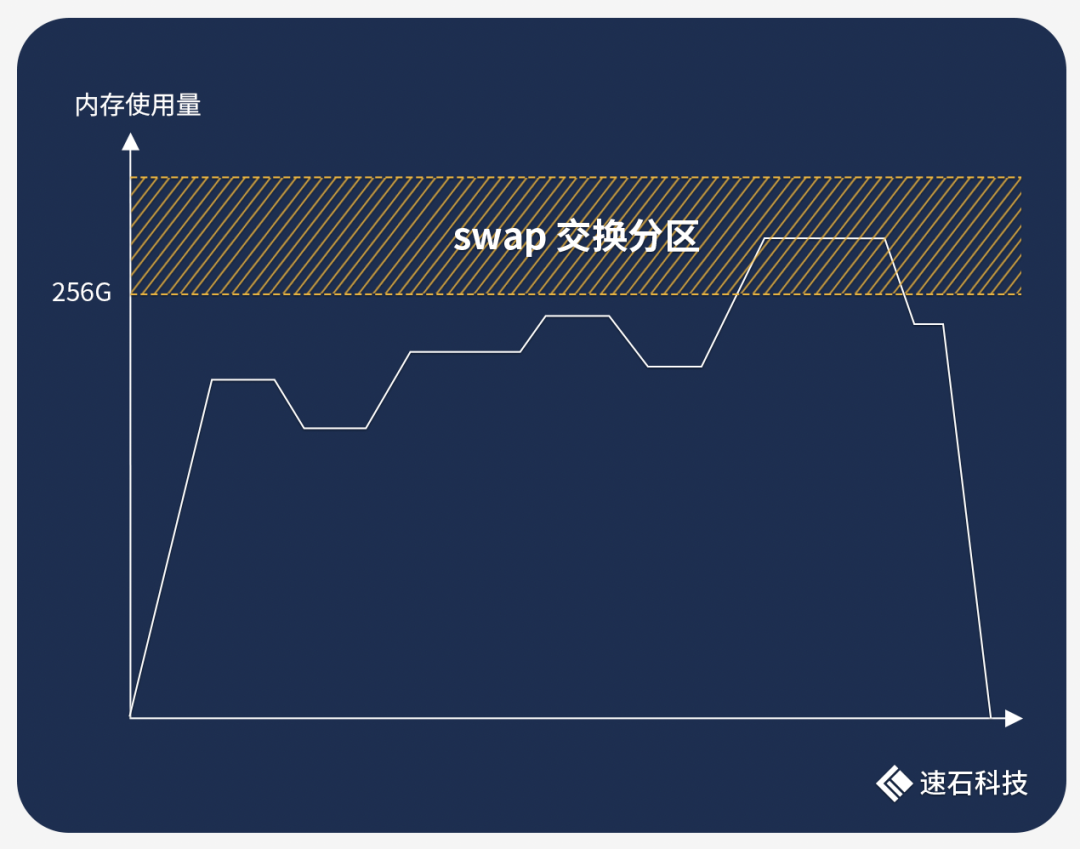
如果选择256G内存的机型配置,任务必崩无疑。
但要是为了这1小时不到10G的内存溢出而全程使用512G的配置,成本翻倍,未免有点太不划算了。
使用Swap交换分区就可以无缝填补这一空缺,非常匹配这种内存峰值场景。
2、 怎么把这些机器组队管理起来?
有了机器,下一步当然是要把它们利用起来。
Calibre默认支持单机多核并行跑任务,这意味着只要机器足够大,就可以同时处理很多任务。
但是,当你的大机器不够多,或者根本拿不到大机器的时候,就很苦恼了。
我们的方法是:将所有机器组成一个集群——多机多核的方式同时跑多个任务。
集群自动化管理,少量大机器需要,大量小机器就更需要了。
为啥?
理由一,能方便地自动化运维整个集群
比如软件安装配置、资源监控、集群管理等工作,是需要IT一台台机器去逐一手动操作,还是鼠标点几下就可以完成?
理由二,能快速方便地分配业务,提高资源利用率
比如,临时需要将一批机器从团队A划拨给团队B使用,有没有什么办法可以让IT快速方便地进行配置?
比如,因为资源使用的不透明和缺乏有序管理,会出现不同人对同一资源的争抢,任务排队等现象。同时,你会发现资源利用率还是不高。
3、怎么让机器自动化干活,不用人操心?
自动化干活可太有必要了。
否则,那么多任务,那么多机器,需要多少双手和眼睛才能忙得过来?
来,我们给你“手”和“眼睛”。
首先是我们的“手”——Auto-Scale功能。
来看一下本地手动跑任务与Auto-Scale自动化跑任务的区别:
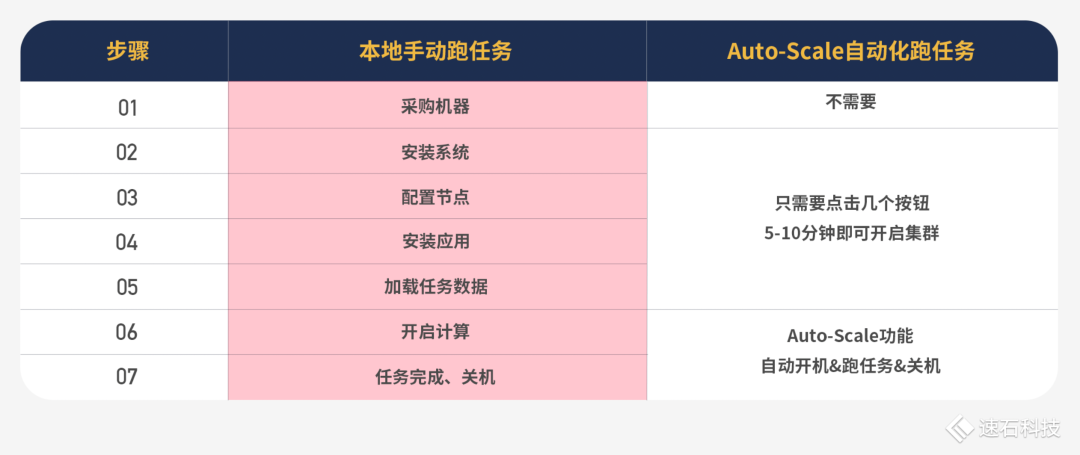
基于我们自主研发的调度器——Fsched,Auto-Scale自动伸缩功能自动化创建集群,自动监控用户提交的任务数量和资源需求,动态按需地开启与关闭所需算力资源,做到分钟级弹性伸缩,在提升效率的同时有效降低成本。
有了“手”干活,还得有“眼睛”盯着防止出错。
我们能多维度监控任务状态,提供基于EDA任务层的监控、告警、数据统计分析功能与服务。

你看,不仅可以自动化跑任务,还能时刻帮你盯着任务是否出错。
来,我们小暴力一下
先说结论:
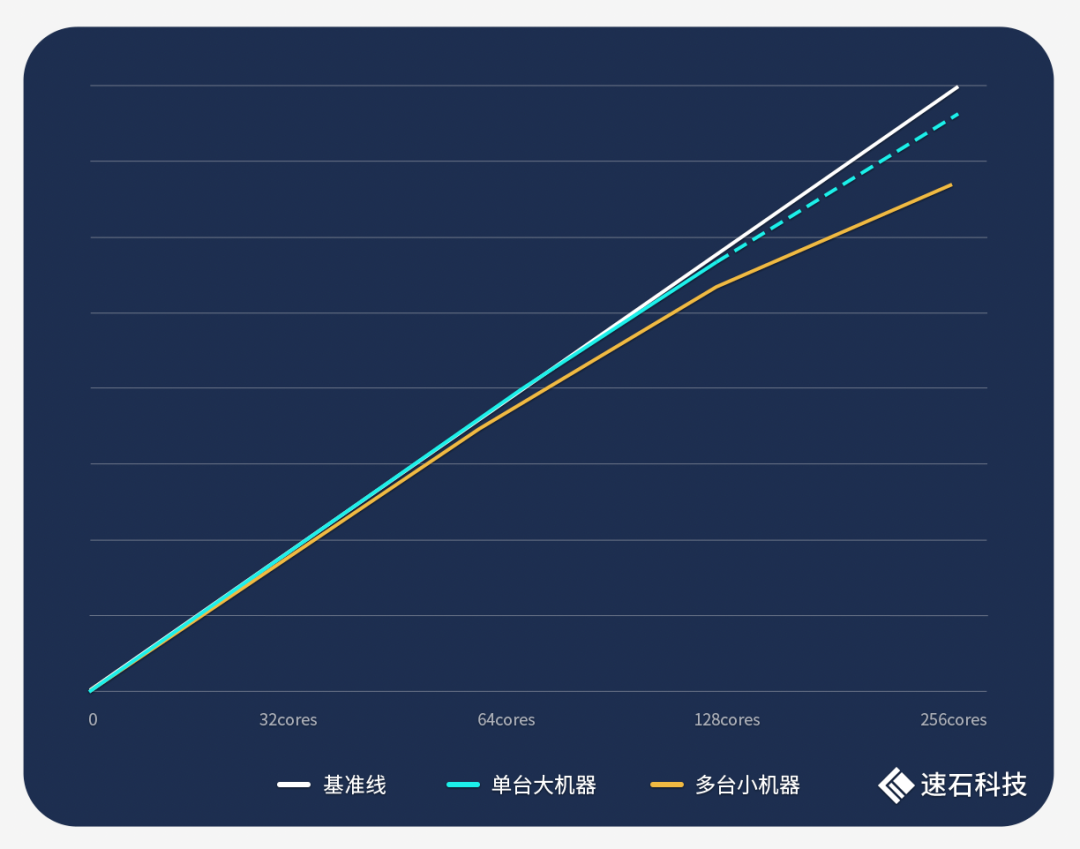
我们在单台大机器和多台小机器组合场景下分别跑了同一组Calibre任务。
单台大机器场景下,随着核数的增加,任务耗时呈现明显的线性下降关系,整体性能曲线非常贴近基准线(单机核数有上限,本次实证中,我们使用的最大单机为128核,并根据32核、64核、128核的耗时规律预估了256核单机的耗时数据,仅供参考)。
多台小机器组合场景下,随着机器数量的翻倍,任务耗时同样线性下降,但在后期倍数关系上有所损耗,多机性能曲线略低于基准线和单机性能曲线。
实证过程:
1、使用fastone云平台调度32核、64核、128核单机分别运行一组Calibre任务,耗时分别为14小时57分49秒、7小时30分28秒、3小时50分11秒;
2、按上条实证数据,预估使用fastone云平台调度256核单机运行一组Calibre任务的耗时为1小时58分6秒;
3、使用fastone云平台调度2、4、8台32核机器分别运行一组Calibre任务,耗时分别7小时43分51秒、4小时6分14秒、2小时15分34秒。
还有大家关心的Intel第四代机器
我们也搞来跑了一下
在上一节中,我们使用的均为第三代英特尔至强可扩展处理器,而在2023年1月11日,英特尔正式推出了第四代至强可扩展处理器。
我们立马搞来跑了一遍,为了对比参照,我们还拉上了第二代和第三代,并且把核数都按比例换算为48核。
实证过程:
1、使用fastone云平台调度48核第二代英特尔处理器运行一组Calibre任务,耗时10小时46分26秒;
2、使用fastone云平台调度48核第三代英特尔处理器运行一组Calibre任务,耗时9小时56分13秒,相比第二代提升7.77%;
3、使用fastone云平台调度48核第四代英特尔处理器运行一组Calibre任务,耗时8小时18分43秒,相比第三代提升16.35%,比第二代提升22.85%。
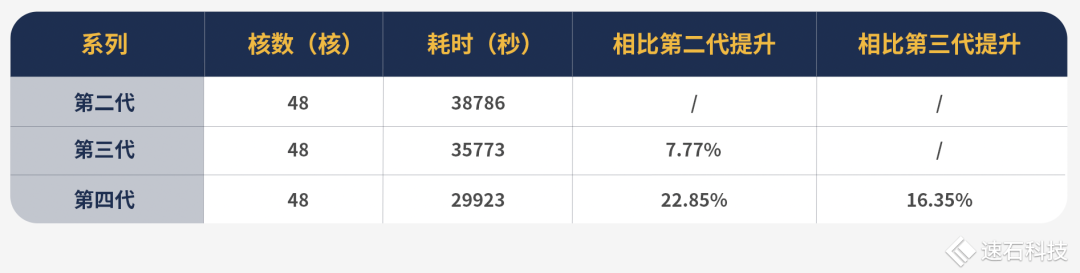
可以看到每一代都有提升,且型号越新,提升幅度越大,三代比二代提升了7.77%,四代比三代提升了16.35%。
而在价格上,目前四代和三代的类似机型换算一下,几乎是相同的。
实证小结
1、Calibre DRC/LVS/PEX不刚需高主频机型,但要求多核、大内存的机器,任务可拆分,适合暴力堆机器;
2、fastone云平台的全球动态资源池、集群自动化管理能力、自动化跑任务并监控告警的功能可完美匹配Calibre的需求;
3、随着计算资源的提升,Calibre的任务耗时呈现明显的线性关系,其中单机整体性能曲线非常贴近基准线,多机效果后期会略有折损;
4、最新型号的处理器可以大幅提升Calibre的效率,可根据项目周期与实际预算综合考量机型配置。
-
cpu
+关注
关注
68文章
10855浏览量
211615 -
Calibre
+关注
关注
0文章
18浏览量
9746 -
寄生参数
+关注
关注
0文章
15浏览量
2067
原文标题:重内存、可拆分,暴力堆机器……Calibre技术向攻略
文章出处:【微信号:MoShangFengQiLv,微信公众号:陌上风骑驴看IC】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
堆栈内存和堆内存之间的区别
Mentor工具简介Calibre物理验证系列
堆和栈的区别是什么
Laker & Calibre Bandgap 实例教程
Java开发者必须了解的堆外内存技术

Calibre加冕暴力堆机器之王!秘密都在这个平台

实战演练:Calibre如何成为暴力堆机器之王

EDA云实证Vol.13:暴力堆机器之王——Calibre

内存向Calibre使用秘诀:大内存+Swap交换分区






 工商网监
工商网监
评论