 Alluxio是如何助力AI大模型训练的呢?
Alluxio是如何助力AI大模型训练的呢?
一、背景
随着云原生技术的飞速发展,各大公有云厂商提供的云服务也变得越来越标准、可靠和易用。凭借着云原生技术,用户不仅可以在不同的云上低成本部署自己的业务,而且还可以享受到每一个云厂商在特定技术领域上的优势服务,因此多云架构备受青睐。
知乎目前采用了多云架构,主要是基于以下考虑:
服务多活:将同一个服务部署到不同的数据中心,防止单一数据中心因不可抗力不能正常提供服务,导致业务被 “一锅端”;
容量扩展:一般而言,在公司的服务器规模达到万台时,单一数据中心就很难支撑业务后续的扩容需求了;
降本增效:对于同一服务,不同云厂商对同一服务的定价和运维的能力也不尽相同,我们期望能够达到比较理想的状态,在云服务满足我们需求的前提下,尽量享受到低廉的价格。
知乎目前有多个数据中心,主要的机房有以下两个:
在线机房:主要是部署知乎主站上直接面向用户的服务(如评论、回答等),这部分服务对时延敏感
离线机房:主要是部署一些离线存储,计算相关的服务,对时延不敏感,但是对吞吐要求高。
两个数据中心之间通过专线连接,许多重要服务都依赖于专线进行跨机房调用,所以维持专线的稳定十分重要。专线流量是衡量专线是否稳定的重要指标之一,如果专线流量达到专线的额定带宽,就会导致跨专线服务之间的调用出现大量的超时或失败。
一般而言,服务的吞吐都不会特别高,还远远达不到专线带宽的流量上限,甚至连专线带宽的一半都达不到,但是在我们的算法场景中有一些比较特殊的情况:算法模型的训练在离线机房,依赖 HDFS 上的海量数据集,以及 Spark 集群和机器学习平台进行大规模分布式训练,训练的模型结果存储在 HDFS 上,一个模型甚至能达到数十上百 GB;在模型上线时,算法服务会从在线机房跨专线读取离线 HDFS 上的模型文件,而算法服务一般有数十上百个容器,这些容器在并发读取 HDFS 上的文件时,很轻易就能将专线带宽打满,从而影响其他跨专线服务。

二、多 HDFS 集群
在早期,我们解决算法模型跨机房读取的方式非常简单粗暴,部署一套新的 HDFS 集群到在线机房供算法业务使用,业务使用模型的流程如下:
1) 产出模型:模型由 Spark 集群或机器学习平台训练产出,存储到离线 HDFS 集群;
2) 拷贝模型:模型产出后,由离线调度任务定时拷贝需要上线的模型至在线 HDFS 集群;
3) 读取模型:算法容器从在线 HDFS 集群读取模型上线。
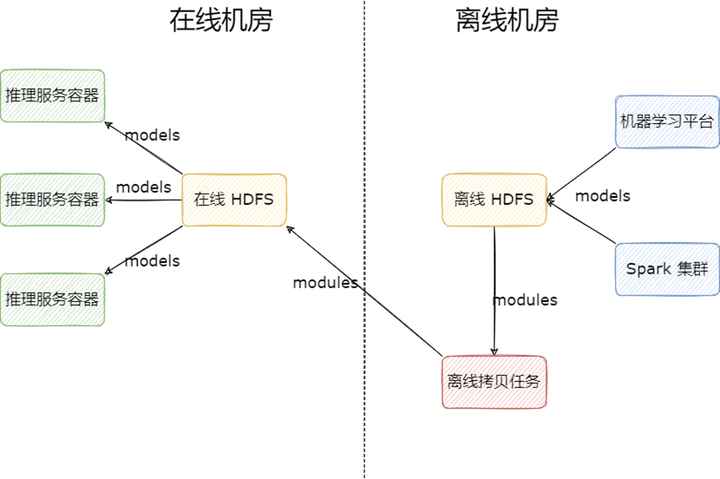
多 HDFS 集群的架构虽然解决了专线流量的问题,但是依然存在一些问题:
多个 HDFS 集群不便于维护,增加运维人员负担;
拷贝脚本需要业务自己实现,每次新上线模型时,都要同步修改拷贝脚本,不便维护;
在线 HDFS 集群的文件需要业务定期手动删除以降低成本,操作风险高;
在线 HDFS 与离线 HDFS 之间文件视图不一致,用户在使用 HDFS 时,需要明确知道自己使用的是哪个 HDFS,需要保存多个地址,心智负担高;
在超高并发读取时,比如算法一次性起上百个容器来读取某个模型文件时,会导致 DataNode 负载过高,虽然可以通过增加副本解决,但是也会带来较高的存储成本。
基于以上痛点,我们自研了多云缓存服务 —UnionStore。
三、自研组件 UnionStore
3.1 简介
UnionStore 顾名思义,就是联合存储的意思,它提供了标准的 S3 协议来访问 HDFS 上的数据,并且以对象存储来作为跨机房缓存。UnionStore 目前在知乎有两种使用场景:
模型上线场景:部署到在线机房,作为跨机房缓存使用:
用户在向 UnionStore 请求读取文件时,会先检查文件是否已经上传到对象存储上:
如果对象存储已经存在该文件,则直接从对象存储读取文件返回给用户;
如果对象存储不存在该文件,UnionStore 会先将离线 HDFS 上的文件上传到在线机房的对象存储上,再从对象存储上读取文件,返回给用户,缓存期间用户的请求是被 block 住的。这里相当于是利用对象存储做了一层跨机房缓存。
模型训练场景:部署到离线机房,作为 HDFS 代理使用,目的是为业务提供 S3 协议的 HDFS 访问方式,通过 s3fs-fuse,业务就能挂载 HDFS 到本地目录,读取训练数据进行模型的训练。
模型训练场景是我们 UnionStore 上线后的扩展场景,之前我们尝试过很多 HDFS 挂载 POSIX 的方式,但是效果都不太理想,主要体现在重试方面,而 UnionStore 正好提供了 S3 协议,s3fs-fuse 重试做的不错,所以我们最后选择了 UnionStore + s3fs-fuse 对 HDFS 进行本地目录的挂载。
其工作流程如下:
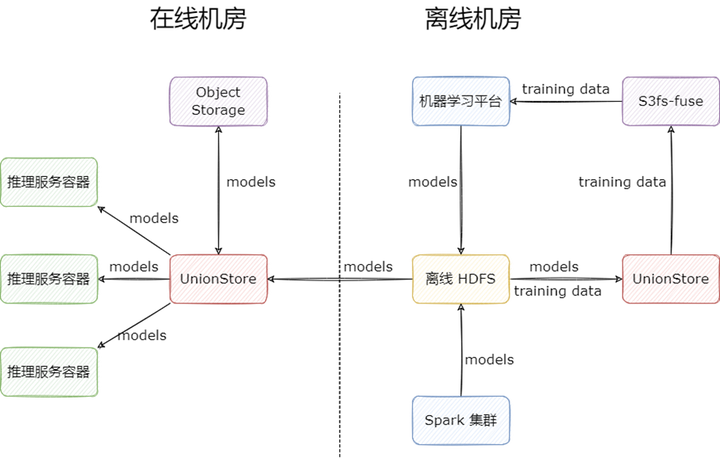
相比于之前多 HDFS 集群方案,UnionStore 的优势如下:
1) UnionStore 提供了 S3 协议,各编程语言对 S3 协议的支持要比 HDFS 协议好,工具也相对来说也更丰富;
2) UnionStore 会自动缓存文件,无需用户手动拷贝模型,省去了拷贝脚本的开发与维护;
3) 提供统一的文件视图,因为元数据是实时请求 HDFS 的,所以文件视图与 HDFS 强一致;
4) 下线了一个 HDFS 集群,文件储存能力由对象存储提供,节省了大量的服务器成本;
5) 文件过期可依赖对象存储本身提供的能力,无需自己实现;
6) UnionStore 以云原生的方式提供服务,部署在 k8s 上,每一个容器都是无状态节点,可以很轻易的扩缩容,在高并发的场景下,由于存储能力转移到对象存储,在对象存储性能足够的情况下,不会遇到类似 DataNode 负载过高的问题。
3.2 实现细节
UnionStore 的完整架构图如下:
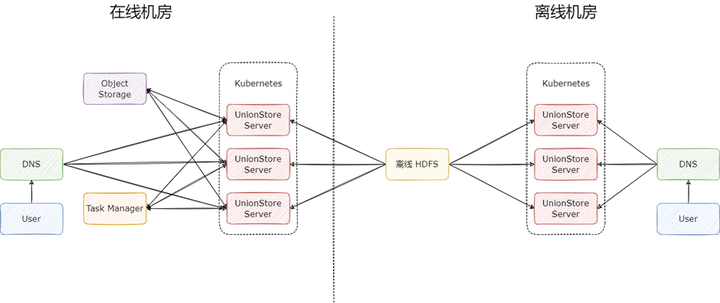
在使用对象存储作为缓存时,UnionStore 有三个核心组件:
UnionStore Server:无状态节点,每一个节点都能单独提供服务,一般会部署多个,用于分摊流量
Object Storage:对象存储,用于缓存 HDFS 上的数据,一般是在哪个云厂商就使用对应云厂商提供的对象存储,流量费用几乎可忽略;
Task Manager:任务管理器,用于存储缓存任务,可用 MySQL 和 Redis 实现。
基于这三个组件我们在 UnionStore 上实现了一系列有用的功能。
文件校验:文件被缓存至对象存储后,如果 HDFS 上的文件做了修改,UnionStore 需要检查到文件的变更,确保用户不会读取到错误的文件。这里我们在将 HDFS 文件上传至对象存储时,会将 HDFS 文件的大小,最后修改时间,checksum 等元信息存储到对象存储文件的 UserMetadata 上,用户在读取文件时,会检查这部分的信息,只有当信息校验通过时,才会返回对象存储上的文件,如果校验未通过,则会重新缓存这个文件,更新对象存储上的缓存。
读写加速:对象存储的单线程读写速度大约在 30-60MB/sec,远远小于 HDFS 的吞吐,如果不做特殊处理,是很难满足业务的读写需求的。
在读方面,我们利用对象存储的 RangeRead 接口,多线程读取对象存储上的数据返回给用户,达到了与 HDFS 相同的读取速度。在写方面,我们利用对象存储的 MultiPartUpload 接口,多线程上传 HDFS 上的文件,也能达到与 HDFS 相同的写入速度。
文件仅缓存一次:因为 UnionStore Server 被设计成了无状态节点,所以它们之间是无法互相感知的。如果有多个请求同时打到不同的 Server 节点上来请求未缓存的文件,这个文件可能会被不同的 Server 多次缓存,对专线造成较大的压力。我们引入了 Task Manager 这个组件来解决这个问题:
Server 节点在接受到读取未缓存文件的请求时,会先将用户的请求异步卡住,生成缓存任务,提交到 Task Manager 的等待队列中;
所有 Server 节点会不断竞争等待队列里的任务,只会有一个节点竞争成功,此时该节点会将缓存任务放入运行队列,开始执行,执行期间向任务队列汇报心跳;
每个 Server 节点会定期检查自己卡住的用户请求,来检查 Task Manager 里对应的任务,如果任务执行成功,就会唤醒用户请求,返回给用户缓存后的文件;同时,每个 Server 都会定期检查 Task Manager 里正在运行的任务,如果任务长时间没有更新心跳,则会将任务从运行队列里取出,重新放回等待队列,再次执行。
这里所有的状态变更操作都发生在 Server 节点,Task Manager 只负责存储任务信息以及提供队列的原子操作。
3.3 局限
UnionStore 项目在知乎运行了两年,早期并没有出现任何问题,但是随着算法业务规模的不断扩大,出现了以下问题:
1) 没有元数据缓存,元数据强依赖 HDFS,在 HDFS 抖动的时候,有些需要频繁更新的模型文件会受影响,无法更新,在线服务不应强依赖离线 HDFS;
2) 读写加速因为用到了多线程技术,对 CPU 的消耗比较大,在早期业务量不大的时候,UnionStore 只需要几百 Core 就能支撑整个公司的算法团队读取数据,但是随着业务量不断上涨,需要的 CPU 数也涨到了上千;
3) 对象存储能力有上限,单文件上千并发读取时,也会面临性能瓶颈;
4) UnionStore 只做到了缓存,而没有做到高性能缓存,业务方的大模型往往需要读取十多分钟,极大影响模型的更新速度,制约业务的发展;
5) 无法做到边缓存边返回文件,导致第一次读取文件的时间过长。
另外还有一个关键点,机器学习平台为保证多活,也采用了多云架构,支持了多机房部署,在读取训练数据时,走的是 UnionStore 对 HDFS 的直接代理,没走缓存流程,因为训练数据大部分都是小文件,而且数量特别巨大,小文件都过一遍缓存会导致缓存任务在任务队列里排队时间过长,很难保证读取的时效性,因此我们直接代理了 HDFS。按照这种使用方式,专线带宽在训练数据规模扩大时,依然会成为瓶颈。
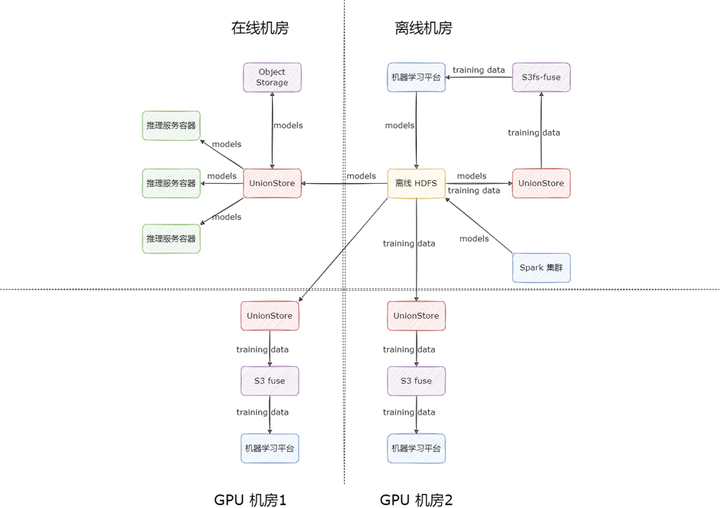
以上痛点使我们面临两个选择:一是继续迭代 UnionStore,让 UnionStore 具备高性能缓存能力,比如支持本地 SSD 以及内存缓存;二是寻找合适的开源解决方案,完美替代 UnionStore 的使用场景。基于人力资源的宝贵,我们选择了其二。
四、利用 Alluxio 替代 UnionStore
1. 调研
我们调研了业内主流的文件系统,发现 Alluxio 比较适合我们的场景,原因有以下几点:
1) 透明缓存:相较于其他文件系统,Alluxio 可仅作为缓存使用,用于编排数据,业务方无需将模型文件写入到其他的文件系统,只需要维持现状,写入 HDFS 即可;
2) 元数据与数据缓存:Alluxio 支持自定义缓存元数据与数据,这样在读取已缓存文件时,可完全不受 HDFS 影响;目前我们 UnionStore 的 QPS 大约在 20K-30K,缓存元数据可极大降低 NameNode 的压力,反哺离线场景;
3) 丰富的 UFS 支持:支持除 HDFS 外的多种 UFS,比如对象存储,对我们的数据湖场景也提供了强有力的支撑;
4) 即席查询加速:知乎 Adhoc 引擎采用的是 Spark 与 Presto,Alluxio 对这两个引擎都有较好的支持;
5) 访问接口丰富:Alluxio 提供的 S3 Proxy 组件完全兼容 S3 协议,我们的模型上线场景从 UnionStore 迁移至 Alluxio 付出的成本几乎可忽略不计;另外 Alluxio 提供的 Alluxio fuse 具备本地元数据缓存与数据缓存,比业务之前使用的 S3 fuse 具有更好的性能,正好能满足我们的模型训练场景。
6) 社区活跃:Alluxio 社区十分活跃,在我们调研期间交流群基本上都会有热心的网友及时答复, issue 很少有超过半天不回复的情况。
对 Alluxio 的调研让我们非常惊喜,它不仅满足了我们的需求,还给我们 “额外赠送” 了不少附加功能。我们在内部对 Alluxio 进行了测试,以 100G 的文件做单线程读取测试,多次测试取平均值,结果如下
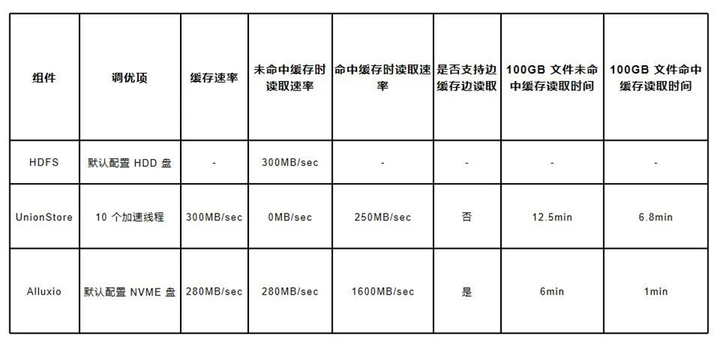
其中 HDFS 因为涉及到 OS 层面的缓存,波动是最大的,从 200MB/sec - 500MB/sec 都有,而 UnionStore 与 Alluxio 在命中缓存时表现十分稳定。
2. 集群规划
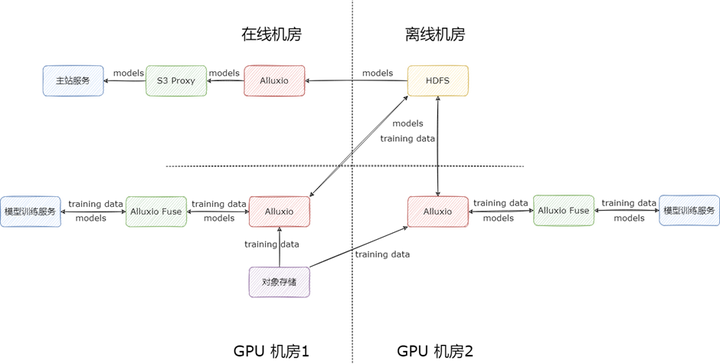
Alluxio 在我们的规划中是每个机房部署一套,利用高性能 NVME 磁盘对 HDFS 和对象存储上的数据进行缓存,为业务提供海量数据的加速服务。
依据业务的使用场景,我们将 Alluxio 集群分为两类。
模型上线加速集群:Alluxio 集群缓存模型本身,利用 S3 Proxy 对外提供只读服务,加速模型的上线
模型训练加速集群:Alluxio 集群缓存模型训练数据,利用 Alluxio fuse 对 HDFS 上数据与元数据再做本地缓存,加速模型的训练;产出的模型直接通过 Alluxio fuse 写入 HDFS 进行持久化存储。
3. 模型上线场景适配
3.1 场景特点
我们的模型上线场景有以下特点:
1) 用户利用 S3 协议读取模型文件;
2) 用户将模型数据写入到 HDFS 上后,需要立即读取,数据产出与读取的间隔在秒级,几乎无法提前预热,存在缓存穿透的问题;
3) 一份模型文件将由上百甚至上千个容器同时读取,流量放大明显,最大的单个模型读取时,峰值流量甚至能达到 1Tb/sec;
4) 模型文件只会在短时间内使用,高并发读取完毕后可视为过期;
5) 数万容器分散在上千个 K8s 节点上,单个容器可用资源量较少。
针对模型上线场景,我们选择了 S3 Proxy 来为业务提供缓存服务,不使用 Alluxio Client 以及 Alluxio fuse 主要是基于以下考虑:
用户原本就是利用 S3 协议读取文件,换成 S3 Proxy 几乎无成本;
业务方使用的语言有 Python,Golang,Java 三种,Alluxio Client 是基于 Java 实现的,其他语言使用起来比较麻烦;
受限于单个容器的资源限制,不适合在容器内利用 CSI 等方式启动 Alluxio fuse,因为 fuse 的性能比较依赖磁盘和内存的缓存。
3.2 集群部署
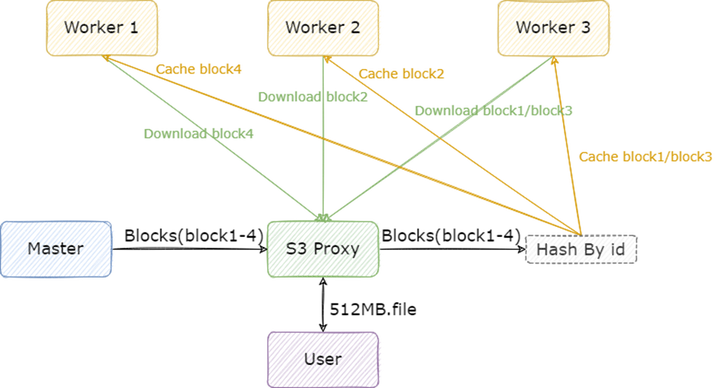
首先是集群的部署方式,在这个场景下,我们的 Alluxio 集群采取了 “大集群轻客户端” 的方式来部署,也就是提供足够数量的 Worker 与 S3 Proxy 来支撑业务以 S3 协议发起的高并发请求,架构图如下
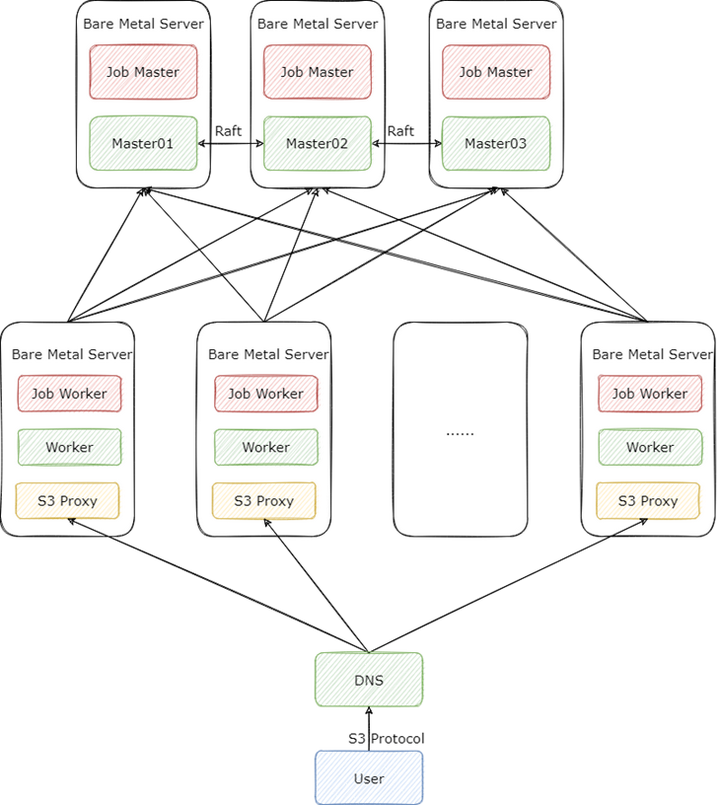
我们的集群版本是 2.9.2,在这个版本,S3 Proxy 有 v1 v2 两种实现,可通过配置 alluxio.proxy.s3.v2.version.enabled 进行切换。v2 版本有一个很重要的功能,就是将 IO 操作与元数据操作进行了分类,分别交给不同的线程池去处理。这样做的好处是,让元数据操作能够快速执行,不被 IO 线程卡住,因为一般情况下,元数据请求的 QPS 远远大于读写文件的 QPS。这个功能对我们非常有用,我们 UnionStore 的 QPS 在 25K 左右,其中 90% 的操作都是元数据访问。
整个 Alluxio 集群我们采取了裸金属机部署,Alluxio 也提供了 k8s 的部署方式,但是在我们的权衡之下,还是选择了裸金属机部署,原因如下:
1) 从我们的测试结果来看,Alluxio Worker 在” 火力全开 “的情况下是可以轻易打满双万兆网卡的,这个时候网卡是瓶颈;如果选择 k8s 部署,当有容器与 Alluxio Worker 调度到同一台 k8s 的节点时,该容器容易受到 Alluxio Worker 的影响,无法抢占到足够的网卡资源;
2) Alluxio Worker 依赖高性能磁盘做本地缓存,与其他服务混布容易收到其他进程的磁盘 IO 影响,无法达到最佳性能;
3) 因为 Alluxio Worker 强依赖网卡,磁盘等物理资源,这些资源不适合与其他服务共享。强行以 k8s 部署,可能就是一个 k8s 节点启一个 Alluxio Worker 的 DaemonSet,这其实也没必要用 k8s 部署,因为基于我们过往的经验,容器内搞存储,可能会遇到各类奇奇怪怪的问题,这些问题解决起来比较浪费时间,影响正常的上线进度。
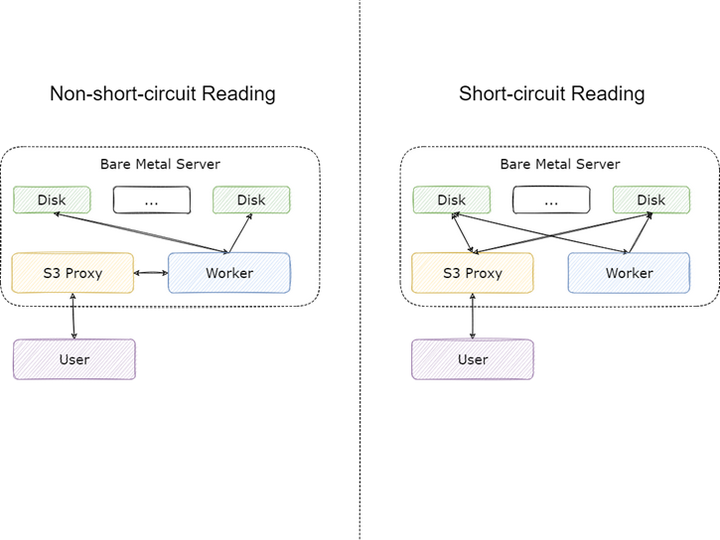
我们除了按照社区文档的推荐将 Master 与 Job Master,Worker 与 Job Worker 部署到同一台机器上,还另外将 S3 Proxy 与 Worker 进行了混布。S3 Proxy 在用户看起来虽然是服务端,但是对 Alluxio 集群来说它还是客户端,而 Alluxio 对于客户端有一个非常重要的优化:
当 Client 与 Worker 在同一节点时,就可以使用短路读的功能,在短路读开启的情况下,Client 将不再利用网络请求调用 Worker 上的 RPC 接口读取数据,而是直接读本地磁盘上的数据,能够极大节省网卡资源。通过 S3 Porxy 访问 Alluxio 时,流量主要分为以下几个部分:
文件未缓存至 Alluxio:Worker 从 UFS 读取数据,任一 Worker 只要缓存了 UFS 的文件,这部分流量将不存在;
文件在远端 Worker 缓存:本地 Worker 从其他 Worker 读取数据缓存到本地,S3 Proxy 暂时从远端 Worker 读取,本地 Worker 缓存完毕后这部分流量将不存在;
文件在本地 Worker 缓存:S3 Proxy 从本地 Worker 读取的流量,这部分流量在开启短路读后将不存在;
业务方从 S3 Proxy 读取的流量,这部分流量无法避免。
其中 1,2 中的流量远小于 3,4 中的流量,短路读能够将 3 的流量省下,节省约 30%-50% 的流量。
其次是集群的部署规模,在模型读取这个场景,尽管每天的读取总量可达数 PB,但是因为模型文件很快就会过期,所以 Worker 的容量并不需要很大,Worker 网卡的总带宽能够支持读取流量即可。Worker 的数量可按照 流量峰值 /(2/3* 网卡带宽) 来计算,这里网卡需要预留 1/3 的 buffer 来供 Worker 读取 UFS 以及 Worker 互相同步数据使用。
最后是 Alluxio Master 的 HA 方式,我们选择了 Raft,在我们的测试过程中,在上亿的元数据以及数百 GB 堆的情况下,Master 主从切换基本上在 10 秒以内完成,效率极高,业务近乎无感。
3.3 上线与调优
我们的上线过程也是我们调优的一个过程。
在初期,我们只将一个小模型的读取请求从 UnionStore 切换到了 Alluxio S3 Proxy,效果如下:
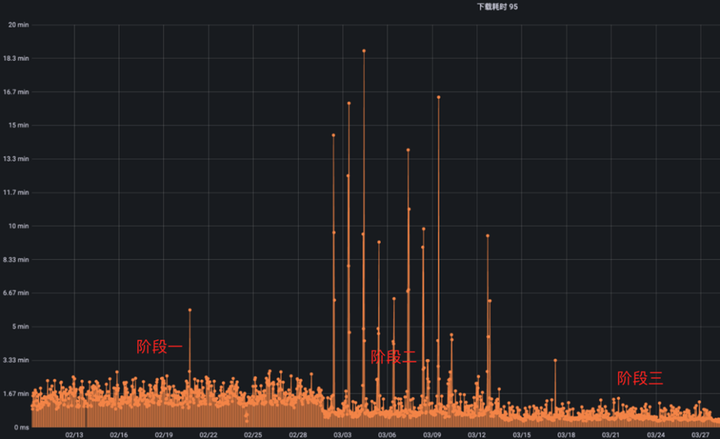
里面的每一条线段都代表着一个模型的读取请求,线段的长短代表读取数据的花费的时间。
其中阶段一是我们内部的 UnionStore 服务,阶段二是我们直接切换到 S3 Proxy 时的状态,可以很明显的看到换成 S3 Proxy 了以后,模型读取的平均速度有所上升,但是出现了尖刺,也就是偶尔有请求读取的很慢。问题出在模型读取时,总是冷读,也就是模型数据没有经过预热,在文件未预热的情况下,从 Alluxio 读数据最多只能达到与 HDFS 相同的速度,不能充分发挥缓存的能力。
而且通过测试,我们发现 Alluxio 在并发请求同一个没有经过预热的文件时,性能会下降的十分严重,甚至达不到直接读 HDFS 的速度。因此我们需要想办法预热文件。
预热文件的手段一般有以下两种:
1) 用户在写完文件后,手动调用 Alluxio load 命令,提前将数据缓存,确保在读取的时候,需要的文件已经被缓存了;
2) 根据 HDFS 的 audit log 或者利用 HDFS 的 inotify 来订阅文件的变更,只要发现算法目录下有文件变动就加载缓存进 Alluxio。
方式 1 的问题在于需要用户深度参与,有额外的心智负担和开发成本,其次是用户调用 load 命令不可控,如果对一个超大目录进行 load,将会使所有缓存失效。
方式 2 也需要用户提供监听的路径,如果路径是文件比较方便,只需要监听 close 请求即可,但是路径是目录的情况下,涉及到临时文件,rename 等,十分复杂;每次用户新增模型时,都需要我们把路径新加入监控,有额外的沟通成本;另外由于我们这个场景,数据产出与读取的间隔在秒级,监控文件变更链路太长,可能出现一些延迟,从而导致预热方案失效。
基于以上缺点,我们自己设计了一套缓存策略:
冷读文件慢的本质在于通过 Alluxio 读取未缓存文件时,读到哪一个 block 才会去缓存这个 block,没有做到并发缓存 block。因此我们在 S3 Proxy 上添加了一个逻辑,在读取文件时,会将文件按 block 进行分段生成 cache block 任务,平均提交到每一个 Worker 来异步缓存。这样的好处是,客户端在读取前面少量几个未缓存的 block 后,后面的 block 都是已经缓存完毕的,读取速度十分快。此外,由于提前缓存了 block,缓存穿透的问题也能有所缓解,HDFS 流量能够下降 2 倍以上。
此缓存策略需要注意以下几点:
1) 缓存 block 需要异步,并且所有的异常都要处理掉,不要影响正常的读取请求;
2) 缓存 block 时,最好将 block id 与 Worker id 以某种方式(如 hash)进行绑定,这样能保证在对同一个文件进行并发请求时,对某一个 block 的缓存请求都只打到同一个 Worker 上,避免不同的 Worker 从 UFS 读取同一个 block,放大 UFS 流量;
3) S3 Proxy 需要对提交的 cache block 任务计数,避免提交过多任务影响 Worker 正常的缓存逻辑,最好不要超过配置 alluxio.worker.network.async.cache.manager.threads.max 的一半,这个配置代表 Worker 处理异步缓存请求的最大线程数,默认值是两倍的 CPU 数;
4) S3 Proxy 需要对已经提交缓存的 block 进行去重,防止在高并发读取同一个文件的情况下,多次提交同一个 block 的缓存请求到 Worker,占满 Worker 的异步缓存队列。Worker 的异步缓存队列大小由配置 alluxio.worker.network.async.cache.manager.queue.max 控制,默认是 512。去重比较推荐使用 bitmap 按照 block id 做;
5) 在 Worker 异步缓存队列没满的情况下,异步缓存的线程数将永远保持在 4 个,需要修改代码提高 Worker 异步缓存的最小线程数,防止效率过低,可参考 #17179。
在上线了这个缓存策略后,我们进入了阶段三,可以看到,阶段三的尖刺全部消失了,整体的速度略微有所提升。因为我们是对小文件(1GB 左右)进行的缓存,所以提升效果不明显。经过我们测试,此缓存策略能够提升读取大文件(10GB 及以上)3-5 倍的速度,而且文件越大越明显。
解决了缓存的问题后,我们继续切换更多模型的读取到 S3 Proxy,效果如下:
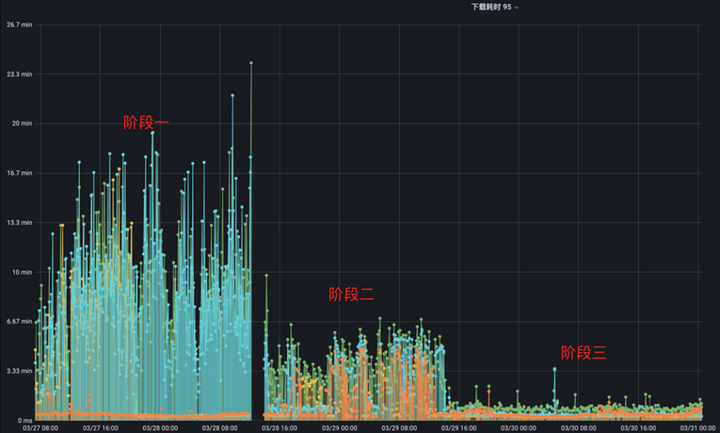
本次我们另外切换了三个模型的读取请求到 S3 Proxy,其中橙色模型是我们之前已经切换到 S3 Proxy 的模型,本次新增的模型最大达到了 10G,读取流量峰值为 500Gb/sec。
这次我们同样分为三个阶段,阶段一是橙色模型已经切换到 S3 Proxy,其他模型都使用 UnionStore,因为橙色模型的数据量小,并且还用了 Alluxio 加速,所以它的读取速度能够比其他模型的读取速度快上数十倍。
阶段二是我们将其他模型也切换至 S3 Proxy 后的状态,可以看到其他模型读取速度明显变快了,但是橙色模型读取速度受到其他模型的影响反而变慢了,这是一个非常奇怪的现象。最后我们定位到是元数据缓存没有开启的原因,在元数据缓存没有开启的情况下,Alluxio 会将客户端的每一次请求都打到 HDFS 上,加上 S3 Proxy 也会频繁对一些系统目录做检查,这样就导致 Master 同步元数据的负担非常重,性能甚至能下降上千倍。
在这个场景,我们本来是不打算开启元数据缓存的,主要是担心业务对已缓存修改文件进行修改,导致读取到错误的文件,从而影响模型的上线。但是从实践的结果来看,元数据缓存必须要开启来提升 Master 的性能。
与业务方沟通过后,我们制定了元数据一致性的规范:
1) 元数据缓存设置为 1min;
2) 新增文件尽量写入新目录,以版本号的方式管理,不要在旧文件上修改或覆盖;
3) 对于历史遗留,需要覆盖新文件的任务,以及对元数据一致性要求比较高的任务,我们在 S3 Proxy 上提供特殊命令进行元数据的同步,数据更新后,业务方自己调用命令同步元数据。
在开启元数据缓存过后,我们来到了图中的阶段三,可以很明显的看到所有模型数据的读取速度有了飞跃式提升,相比于最开始没有使用 S3 Proxy 读取速度提升了 10+ 倍。这里需要注意的是,10+ 倍是指在 Alluxio 机器数量足够多,网卡足够充足的情况下能达到的效果,我们在实际使用过程中,用了 UnionStore 一半的资源达到了与 UnionStore 同样的效果。
3.4 S3 Proxy 限速
我们在模型读取场景上线 Alluxio 的本意是为了提高业务方读取模型的速度,但是因为通过 Alluxio 读数据实在是太快了,反而需要我们给它限速,非常的具有戏剧性。不限速将会面临一个很严重的问题:算法容器在读取模型时,如果文件较大,不仅会影响 S3 Proxy 所在物理机的网卡,也会导致该容器所在的 k8s 宿主机的网卡长时间处于被占满状态,从而影响这一节点上的其他容器。
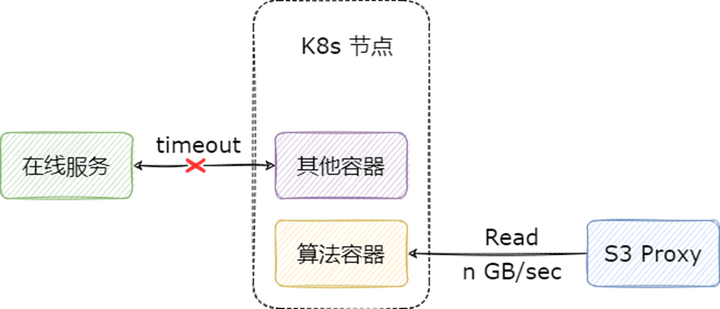
目前限速的实现主要有以下几种方案:
Worker 端限速:优点是对所有客户端生效,缺点是对同节点客户端短路读不生效,在我们的场景,S3 Proxy 会走短路读,不能满足我们的需求。
客户端限速:优点是能够同时对 Alluxio fuse 和 S3 Proxy 生效,缺点是客户端可以自己改配置绕过限制,同时服务端版本和客户端版本可能存在不一致的情况,导致限速失效。
S3 Proxy 限速:只能对 S3 Proxy 生效,对其他的客户端以及 Worker 都不能生效。
因为我们当前的目标就是替代 UnionStore,业务方访问 Alluxio 的入口只有 S3 Proxy,因此客户端限速和 S3 Proxy 限速都能满足我们的需求,但是从实现的难易角度上考虑,我们最后选择了从 S3 Proxy 层面限速。
我们支持了两种限速策略,一方面是 S3 Proxy 进程全局限速,用于保护 Worker 网卡不被打满;另一方面是单连接限速,用于保护业务容器所在 k8s 节点。限速策略我们已经贡献给了社区,如果感兴趣可以参考:#16866。
4. 模型训练场景适配
4.1 场景特点
我们的模型训练场景有以下特点:
1) 因为大部分开源的模型训练框架对本地目录支持最好,所以我们最好是为业务提供 POSIX 访问的方式;
2) 模型训练时,主要瓶颈在 GPU,而内存,磁盘,网卡,CPU 等物理资源比较充足;
3) GPU 机器不会运行训练任务以外的任务,不存在服务混布的情况;
4) 数据以快照形式管理,对元数据没有一致性要求,但是需要有手段能够感知 HDFS 上产生的新快照。
针对模型训练场景,毫无疑问我们应该选择 Alluxio fuse 来提供缓存服务:
1. Alluxio fuse 提供了 POSIX 访问方式;
2. Alluxio fuse 能够利用内存和磁盘做元数据缓存与数据缓存,能够最大程度利用 GPU 机器上闲置的物理资源。
4.2 性能测试
在上线前,我们对 fuse 用 fio 进行了压测。
Alluxio fuse 配置:

测试结果如下:
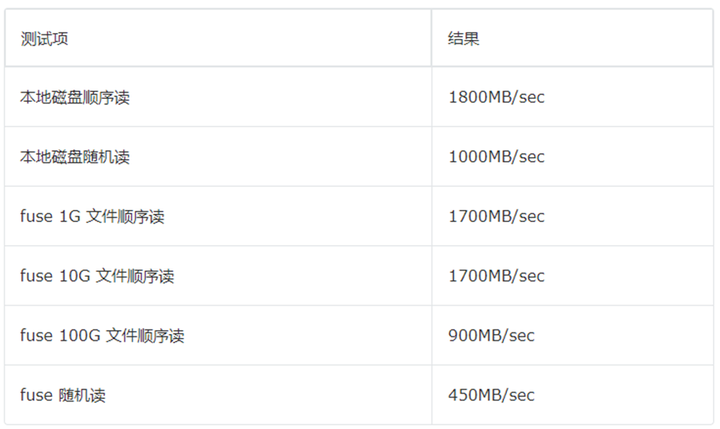
以上结果均针对数据已缓存至 fuse 本地磁盘的情况,1G 文件与 10G 文件读取时,速度是 100G 文件的两倍,这是因为容器的内存为 40G,有充足的 pagecache 来缓存 1G 与 10G 的文件,但是 100G 的文件没有充足的 pagecache,所以性能会下降,但是也能达到不错的速度,整体行为符合预期。
4.3 集群部署
Alluxio fuse 的部署方式我们选择了以 DaemonSet 部署,通过 host path 进行映射,没有选择 CSI 部署,主要是基于以下考虑:
1) Alluxio fuse 高性能的核心在于数据缓存与元数据缓存,数据缓存需要消耗大量的磁盘,元数据缓存需要消耗大量的内存,如果以 CSI 的形式进行部署,每个容器只能分配到少量的磁盘与内存给 Alluxio fuse 进程;
2) 在模型进行训练的时候,读取的训练数据重复程度很高,如果每个容器起一个 fuse 进程,可能会导致同一机器缓存多份相同的文件,浪费磁盘;
3) GPU 机器只跑训练任务,所以 fuse 进程可以 long running,无需考虑资源释放的问题;
4) host path 的部署方式可以很容易实现挂载点恢复。
这里对挂载点恢复做一个说明,一般情况下,如果 Alluxio fuse 容器因为各种异常挂了,哪怕 fuse 进程重新启动起来,将目录重新进行挂载,但是在业务容器里的挂载点也是坏掉的,业务也读不了数据;但是如果做了挂载点恢复,Alluxio fuse 容器启动起来以后,业务容器里的挂载点就会自动恢复,此时如果业务自身有重试逻辑,就能不受影响。
Alluxio fuse 进程的挂载点恢复包括两个部分,一部分是挂载点本身的恢复,也就是 fuse 进程每次重启后要挂到同一个挂载点;另一部分是客户端缓存数据的恢复,也就是 fuse 进程每次重启后缓存数据目录要与原先保持一致,避免从 Alluxio 集群重复拉取已经缓存到本地的文件。挂载点恢复在 CSI 里需要做一些额外的开发来支持,但是如果是以 host path 的方式映射,只要在业务容器里配置了 HostToContainer 即可,不需要额外的开发。
我们 fuse 进程的部署架构图如下:
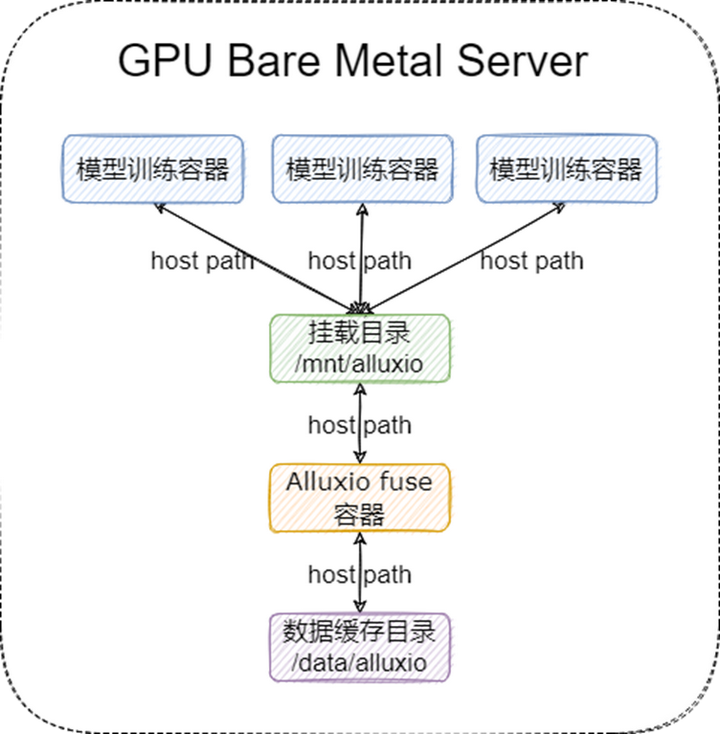
在这个场景下,我们的 Alluxio 集群采取了 “小集群重客户端” 的方式来部署,即提供一个规模较小的 Alluxio 集群,只用来做数据的分发,性能和缓存由 Alluxio fuse 自身保证。Alluxio 集群只需要提供高配置的 Master 和少量的 Worker 即可,集群整体的部署架构如下:
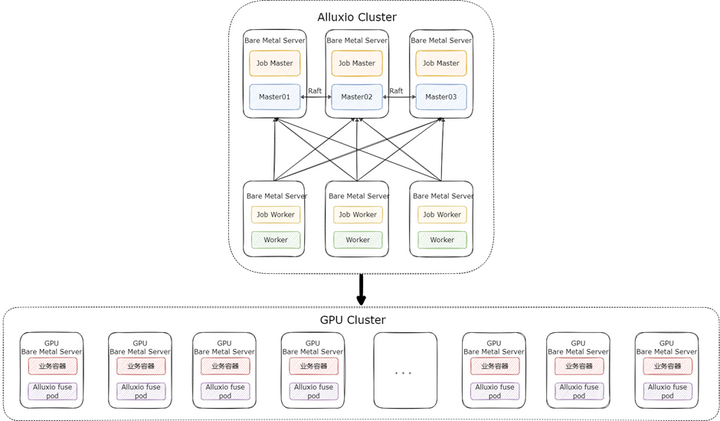
按照这种部署模式,3 台 Raft HA 的 Master 与 少量 Worker 就可支撑起 fuse 进程大规模的部署。
4.4 Alluxio fuse 调优
首先是元数据缓存,Alluxio fuse 可开启元数据缓存,这里容易与 Master 对 UFS 元数据的缓存弄混淆,我们简单做个说明:
1) Alluxio Master 会缓存 UFS 的元数据,决定是否更新元数据由客户端配置的 alluxio.user.file.metadata.sync.interval 决定。假如这个值设置为 10min,客户端在请求 Master 时,如果 Master 在之前的 10min 内已经更新过元数据,则 Master 会直接返回缓存的元数据,而不会请求 UFS 拿最新的元数据;否则将会返回 UFS 的最新的元数据,并且更新 Master 的元数据
2) 用户在用 Alluxio fuse 访问 Alluxio 时,会先看内核缓存元数据是否失效(配置为 fuse 启动参数 attr_timeout,entry_timeout),再看用户空间元数据缓存是否失效(配置为 alluxio.user.metadata.cache.expiration.time),再看 Master 缓存是否失效(配置为 alluxio.user.file.metadata.sync.interval),只要有一层没失效,都不能拿到 HDFS 的最新元数据。
所以建议在开启 fuse 元数据缓存后,设置 alluxio.user.file.metadata.sync.interval=0 以便每次 fuse 在本地元数据缓存失效后,都能拿到 UFS 最新的元数据。
另外 fuse 的元数据缓存可以通过一些特殊的命令来更新(需要配置 alluxio.fuse.special.command.enabled=true):
元数据缓存可通过以下命令进行强制刷新,假设我们的 mount 目录为 /mnt/alluxio,利用以下命令可以刷新所有元数据缓存:
ls -l /mnt/alluxio/.alluxiocli.metadatacache.dropAll
利用以下命令可以刷新指定目录(这里以 /user/test 为例)的元数据缓存
ls -l /mnt/alluxio/user/test/.alluxiocli.metadatacache.drop
在代码中(以 python 为例),可以这样清理元数据:
import os print(os.path.getsize("/mnt/alluxio/user/test/.alluxiocli.metadatacache.drop"))
但是需要注意,内核元数据缓存是清理不掉的,所以这里推荐内核元数据缓存设置一个较小的值,比如一分钟,用户空间元数据缓存设置一个较大的值,比如一小时,在对元数据有一致性要求的时候,手动刷新用户空间元数据缓存后,等待内核元数据缓存失效即可。
元数据缓存和数据缓存同时开启的情况下,清理元数据缓存的命令在使用上会有一些问题,我们进行了修复,参考:#17029。
其次就是数据缓存,我们的 Alluxio fuse 因为是用 DeamonSet 的方式进行的部署,所以数据缓存我们基本上可以用满整台物理机的磁盘,极大降低了 Alluxio Worker 的流量。
最后就是资源配置,因为每个机器只起一个 fuse 进程,所以可以适当给 fuse 进程多分配给一些 CPU 和内存,CPU 可以适当超卖,以处理突然激增的请求。 内存方面,首先是堆内存的配置,如果开启了用户空间元数据缓存,按照 缓存路径量数 * 2KB * 2 来设置 Xmx。另外 DirectoryMemory 可设置大一点,一般 8G 够用。
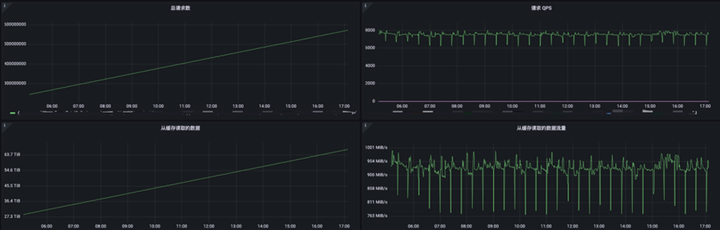
如果开启了内核数据缓存,还需要给容器留存一些空间来存放 pagecache,因为 kubernetes 计算容器内存使用量会包含 pagecache 的使用量。关于 pagecache 是否会引起容器 OOM,我们查找了很多文档都没有得到准确的结论,但是我们用如下配置进行了压测,发现容器并不会 OOM,并且 fuse 的表现十分稳定:

4.5 上线结果
我们的算法模型训练切换至 Alluxio fuse 后,模型训练的效率达到了本地磁盘 90% 的性能,相比于原来 UnionStore 的 s3fs-fuse 的挂载,性能提升了约 250%。
五、S3 Proxy 在大数据场景的应用
回顾模型上线场景,我们不仅为算法业务提供了模型加速读取的能力,还沉淀下来了一个与对象存储协议兼容,但是下载速度远超普通对象存储的组件,那就是 Alluxio S3 Proxy,所以我们现在完全可以做一些” 拿着锤子找钉子 “的一些事情。 这里介绍一下我们大数据组件的发布与上线流程,流程图大致如下:
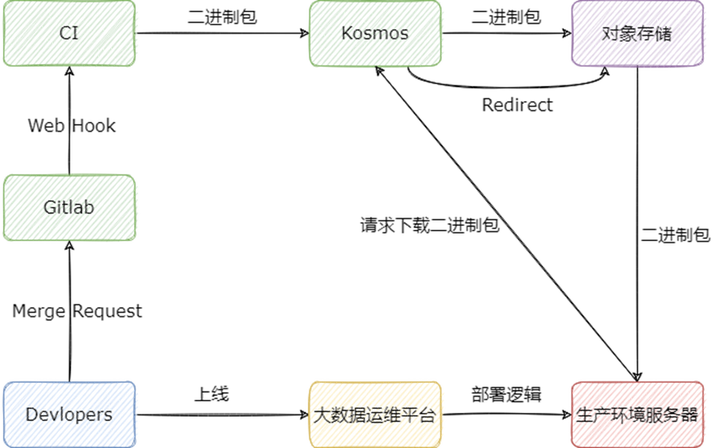
下面用文字简单描述:
1) 开发者修改代码以后,将代码合入对应组件的 master 分支,此时 Gitlab 将调用 CI 的 Web Hook,CI 会运行对应组件的打包编译逻辑;
2) 组件打包成二进制包后,CI 会向 Kosmos 注册二进制包的元信息,以及将二进制包上传至 Kosmos,Kosmos 在接受到二进制包后,会上传至对象存储;
3) 开发者在大数据运维平台选择要上线的组件,以及组件的版本,大数据组件会自动在生产环境的服务器上运行部署逻辑;
4) 在部署逻辑运行的过程中,会向 Kosmos 请求下载组件的二进制包,Kosmos 将会直接返回对象存储的只读链接,供生产环境服务器进行下载。
其中 Kosmos 是我们自研的包管理系统,其诞生的背景可以参考:Flink 实时计算平台在知乎的演进;另外我们的大数据运维平台也有相应的专栏,感兴趣可以查看:Ansible 在知乎大数据的实践。
一方面,这个流程最大的问题在于大规模上线节点时,从对象存储下载二进制包速度过慢。比如我们要对所有的 DataNode 节点以及 NodeManager 节点做变更时,每台机器都需要下载数百 MB 甚至上 GB 的二进制包,按照对象存储 20-30MB/sec 的下载速度,每台机器需要花费约 30 秒的时间来进行下载,占了整个部署逻辑约 2/3 的时间。如果按照 10000 台 DataNode 来计算,每两台滚动重启(保证三副本一个副本可用),仅仅花费在下载二进制包上的时间就达到了 40+ 小时,及其影响部署效率。
另一方面,对象存储在不同的机房使用时,也会面临外网流量的问题,造成比较高的费用;所以这里对 Kosmos 做了多机房改造,支持向不同的对象存储上传二进制包,用户在请求 Kosmos 时,需要在请求上加上机房参数,以便从 Kosmos 获取同机房对象存储的下载链接,如果用户选错了机房,依然会使用外网流量。
上述问题其实可以通过改造大数据运维平台来解决,比如将下载与部署逻辑解耦,在节点上以较高的并发下载二进制包后再进行滚动部署,但是改造起来比较费时费力,更何况我们现在有了更高效下载文件的方式 — Alluxio S3 Proxy,所以更没有动力来做这个改造了。
我们将 Kosmos 的对象存储挂载到 Alluxio 上,Kosmos 在被请求下载时,返回 Alluxio S3 Proxy 的只读链接,让用户从 S3 Proxy 读取数据,改造后的流程图如下:

经过我们的改造,Kosmos 几乎所有的下载请求都能在 1-2 秒内完成,相比于从对象存储下载,快了 90% 以上,下图是我们的生产环境中,Kosmos 分别对接对象存储与 Alluxio 的下载速度对比,其中 Alluxio S3 Proxy 被我们限速至 600MB/sec:
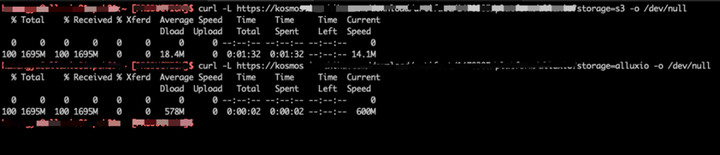
此外 Alluxio 我们也进行了多机房部署,支持了 Kosmos 的多机房方案,哪怕是用户选错了机房,也不会造成额外的外网流量,仅仅只是会请求其他机房的 Alluxio 集群,消耗一定的专线带宽。
六、权限相关
Alluxio 在与 HDFS 对接时,会继承 HDFS 的文件权限系统,而 HDFS 与 Alluxio 的用户可能不一致,容易造成权限问题。权限问题比较重要,所以我们单独用一个章节来做介绍。
我们通过研究代码与测试,总结了基于 Alluxio 2.9.2 版本(HDFS 与 Alluxio 的认证方式都是 SIMPLE),用户与权限的映射关系,总览图如下:
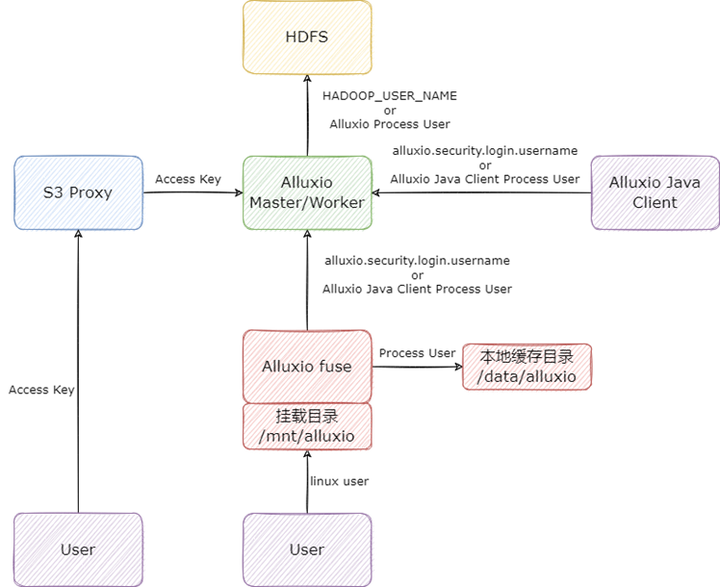
首先是 Alluxio Java Client 的用户:Alluxio Java Client 与 Alluxio 交互时,如果配置了 alluxio.security.login.username,Alluxio 客户端将会以配置的用户访问 Alluxio 集群,否则将会以 Alluxio Java Client 的启动用户访问 Alluxio。
Alluxio Master/Worker 在与 HDFS 交互时,如果 Master/Worker 在启动时配置了环境变量 HADOOP_USER_NAME(可在 alluxio-env.sh 配置),则 Master/Worker 将会以配置的用户访问 HDFS,否则将会以 Master/Worker 的进程启动用户访问 HDFS。这里需要注意,Master 和 Worker 尽量配置一样的 HDFS 用户,否则一定会造成权限问题。
在向 HDFS 写入文件时,Alluxio 会先以 Master/Worker 配置的 HDFS 用户写入文件,写完以后会调用 HDFS 的 chown 命令,将文件的 owner 修改为 Alluxio Java Client 的用户,这里我们举例说明:假设 Alluxio 启动用户为 alluxio,Alluxio Java Client 用户为 test,在向 HDFS 写入文件时,Alluxio 会先将文件以 alluxio 账号写到 HDFS 上,再将文件 chown 变成 test 用户,这时如果 alluxio 用户不是 HDFS 超级用户,在 chown 时会发生错误(比较坑的一点是这个错误 alluxio 不会抛出给客户端),导致 Alluxio 上看到的文件 owner 是 test,但是 HDFS 上的文件 owner 时 alluxio,造成元数据不一致。
其次是 S3 Proxy 的用户,S3 Proxy 它也是一个比较特殊的 Alluxio Java Client,但同时它也是一个 Server 端,这里主要是用户请求 S3 Proxy 的 AK SK 与 HDFS 用户的映射。S3 Proxy 默认会将用户的 AK 映射成访问 Alluxio 集群的用户,这里也可以自己实现映射关系,比如将 AK 映射成特定的用户,S3 Proxy 里有相关插件。
最后是 Alluxio fuse 的用户,Alluxio fuse 因为涉及到 linux 文件系统,而且有多种与 linux 本地文件系统相关的实现,所以比前面的更加复杂,这里我们只讨论默认情况,也就是 alluxio.fuse.auth.policy.class=alluxio.fuse.auth.LaunchUserGroupAuthPolicy 时的情况。用户在访问挂载目录时,用的是当前 linux 用户,用户看到挂载目录里所有文件的 owner 都是 fuse 进程启动用户;fuse 在写本地缓存目录时,用的是 fuse 进程的启动用户,此外 fuse 进程与 Alluxio 集群交互时又完全遵循 Alluxio Java Client 的逻辑。
综上所述,比较推荐的用户设置方式为:
1) Alluxio 集群使用 alluxio 账号启动,并且将 alluxio 账号设置为 HDFS 超级用户;
2) S3 Proxy 用 alluxio 账号启动,用户访问时,AK 为 HDFS 账号;
3) Alluxio fuse 以 root 用户启动,防止写本地数据没有权限,并且加上 allow_other 参数,配置 alluxio.security.login.username 为 HDFS 用户。
七、其他问题
在上线过程中,我们遇到了很多问题,其中大部分都跟配置项调优有关。遇到这些问题的原因主要还是因为 Alluxio 是面相通用设计的缓存系统,而用户的场景各式各样,很难通过默认配置完美适配,比如我们有多套 Alluxio 集群,每套集群用来解决不同的问题,所以这些集群的配置都有些许差异。多亏 Alluxio 提供了许多灵活的配置,大部分问题都能通过修改配置解决,所以这里只介绍一些让我们印象深刻的 “代表”。
最大副本数:在模型上线场景,缓存副本数我们不设上限,因为在算法模型在读取时,往往是一个大模型同时几十个甚至上百个容器去读,占用的存储不多,但是读取次数多,并且仅高并发读取这一次,很少有再读第二次的情况。所以这里对每一个缓存文件副本数不做限制,可以让每个 Worker 都缓存一份,这样能够达到最大的吞吐,拥有最好的性能。在模型训练场景,我们将缓存副本数设置为 3,一方面是因为训练数据量很大,需要节省存储,另一方面是 Alluxio fuse 的本地缓存会承担大部分流量,所以对于 Worker 的吞吐要求相对较低。
S3 Proxy ListObjects 问题:我们发现 S3 Proxy 在实现 ListObjects 请求时,会忽略 maxkeys 参数,列出大量不需要的目录。比如我们请求的 prefix 是 /tmp/b, maxkeys 是 1,S3 Proxy 会递归列出 /tmp 下所有文件,再从所有文件里挑选出满足 prefix /tmp/b 的第一条数据,这样不仅性能差,也会导致可能出现 OOM 的情况,我们采用临时方案进行的修复,感兴趣可以参考 #16926。这个问题比较复杂,需要 Master 与 S3 Proxy 联合去解决,可以期待 #16132 的进展。
监控地址冲突:我们监控采用的是 Prometheus 方案,Alluxio 暴露了一部分指标,但是 JVM 指标需要额外在 Master 或者 Worker 的启动参数中添加 agent 与端口暴露出来,添加 agent 以后,因为 monitor 会继承 Master 与 Worker 的启动参数,所以 monitor 也会尝试使用与 Master 和 Worker 同样的指标端口,这会出现 ”Address already in use“ 的错误,从而导致 monitor 启动失败。具体可查看 #16657。
Master 异常加载 UFS 全量元数据:如果一个路径下有 UFS mount 路径,在对这个路径调用 getStatus 方法时,Alluxio master 会递归同步这个路径下的所有文件的元信息。比如 /a 路径下的 /a/b 路径是 UFS 的 mount 路径,在调用 getStatus ("/a") 的时候,会导致 /a 下面的元数据被全量加载。如果 /a 是一个大路径,可能会导致 Master 因为加载了过多的元数据而频繁 GC 甚至卡死。具体可查看 #16922。
Master 频繁更新 access time:我们在使用过程中,发现 Master 偶尔会很卡,通过 Alluxio 社区同学的帮助,定位到问题来自 Master 频繁更新文件的最后访问时间,通过合入 #16981,我们解决了这个问题。
八、总结与展望
其实从 2022 年的下半年我们就开始调研 Alluxio 了,但是因为种种原因,中途搁置了一段时间,导致 Alluxio 推迟到今年才上线。在我们调研与上线的过程中,Alluxio 社区是我们最强大的外援,为我们提供了海量的帮助。
本次我们在算法场景对 Alluxio 小试牛刀,取得的结果令人十分惊喜。
从性能上讲,在算法模型上线的场景,我们将 UnionStore 用 Alluxio 替换后,最高能够获得数十倍的性能提升;在模型训练场景,我们配合 Alluxio fuse 的本地数据缓存,能够达到近似本地 NVME 磁盘的速度,相比于 UnionStore + s3fs-fuse 的方案,性能提升了 2-3 倍。
从稳定性上讲,在 HDFS 抖动或者升级切主的时候,因为有数据缓存和元数据缓存,Alluxio 能够在一定时间内不受影响,正常提供服务。 从成本上讲,Alluxio 相比于 UnionStore 每年为我们节省了数十万真金白银,而且性能上还有盈余。
从长远的发展来看,Alluxio 具有强大的可扩展性,尤其是 Alluxio 的新一代架构 Dora ,能够支持我们对海量小文件缓存的需求,这让我们更有信心支撑算法团队,面对即将到来的人工智能浪潮。 最后再次感谢 Alluxio 团队,在我们上线的过程中为我们提供了大量的帮助与建议,也希望我们后续能够在大数据 OLAP 查询加速场景以及分布式数据集编排领域继续深入合作与交流。
【案例二:蚂蚁】Alluxio 在蚂蚁集团大规模训练中的应用
一、背景介绍
首先是我们为什么要引入 Alluxio,其实我们面临的问题和业界基本上是相同的:
第一个是存储 IO 的性能问题,目前 gpu 的模型训练速度越来越快,势必会对底层存储造成一定的压力,如果底层存储难以支持目前 gpu 的训练速度,就会严重制约模型训练的效率。
第二个是单机存储容量问题,目前我们的模型集合越来越大,那么势必会造成单机无法存放的问题。那么对于这种大模型训练,我们是如何支持的?
第三个是网络延迟问题,目前我们有很多存储解决方案,但都没办法把一个高吞吐、高并发以及低延时的性能融合到一起,而 Alluxio 为我们提供了一套解决方案,Alluxio 比较小型化,随搭随用,可以和计算机型部署在同一个机房,这样可以把网络延时、性能损耗降到最低,主要出于这个原因我们决定把 Alluxio 引入蚂蚁集团。
以下是分享的核心内容:总共分为 3 个部分,也就是 Alluxio 引入蚂蚁集团之后,我们主要从以下三个方面进行了性能优化:第一部分是稳定性建设、 第二部分是性能优化、第三部分是规模提升。
二、稳定性建设
首先介绍为什么要做稳定性的建设,如果我们的资源是受 k8s 调度的,然后我们频繁的做资源重启或者迁移,那么我们就需要面临集群频繁的做 FO,FO 的性能会直接反映到用户的体验上,如果我们的 FO 时间两分钟不可用,那么用户可能就会看到有大量的报错,如果几个小时不可用,那用户的模型训练可能就会直接 kill 掉,所以稳定性建设是至关重要的,我们做的优化主要是从两块进行:一个是 worker register follower,另外一个是 master 迁移。
1.Worker Register Follower
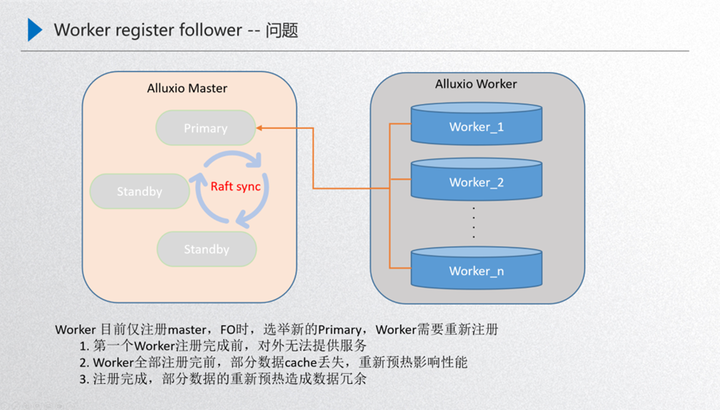
先介绍下这个问题的背景:上图是我们 Alluxio 运行的稳定状态,由 master 进行元数据服务,然后内部通过 raft 的进行元数据一致性的同步,通过 primary 对外提供元数据的服务,然后通过 worker 节点对外提供 data 数据的服务,这两者之间是通过 worker 注册 primary 进行一个发现,也就是 worker 节点的发现,这样就可以保证在稳定状态下运行。那如果这时候对 primary 进行了重启,就需要做一次 FO 的迁移,也就是接下来这个过程,比如这时候对 primary 进行了重启,那么内部的 standby 就需要通过 raft 进行重新选举,选举出来之前,其实 primary 的元数据和 worker 是断联的,断连的状态下就需要进行 raft 的一致性选举,进行一次故障的转移,接下来如果这台机器选举出来一个新的 primary,这个时候 work 就需要重新进行一次发现,发现之后注册到 primary 里面,这时新的 primary 就对外提供元数据的服务,而 worker 对外提供 data 数据的服务,这样就完成了一次故障的转移,那么问题点就发生在故障发生在做 FO 的时候,worker 发现新的 primary 后需要重新进行一次注册,这个部分主要面临三个问题:
第一个就是首个 worker 注册前集群是不可用的,因为刚开始首个 worker 恢复了新的 primary 领导能力,如果这个时候没有 worker,其实整个 primary 是没有 data 节点的,也就是只能访问元数据而不能访问 data 数据。
第二个是所有 worker 注册过程中,冷数据对性能的影响。如果首个 worker 注册进来了,这时就可以对外提供服务,因为有 data 节点了,而在陆续的注册的过程当中如果首个节点注册进来了,然后后续的节点在注册的过程当中,用户访问 worker2 的缓存 block 的时候,worker2 处于一种 miss 的状态,这时候 data 数据是丢失的,会从现存的 worker 中选举出来到底层去读文件,把文件读进来后重新对外提供服务,但是读的过程当中,比如说 worker1 去 ufs 里面读的时候,这就牵扯了一个预热的过程,会把性能拖慢,这就是注册当中的问题。
第三个是 worker 注册完成之后的数据冗余清理问题。注册完成之后,其实还有一个问题就是在注册的过程当中不断有少量数据进行了重新预热,worker 全部注册之后,注册过程中重新缓存的这部分数据就会造成冗余, 那就需要进行事后清理,按照这个严重等级其实就是第一个 worker 注册前,这个集群不可用,如果 worker 规格比较小,可能注册的时间 2-5 分钟,这 2-5 分钟这个集群可能就不可用,那用户看到的就是大量报错,如果 worker 规格比较大,例如一个磁盘有几 tb 的体量,完全注册上来需要几个小时。那这几个小时整个集群就不可对外提供服务,这样在用户看来这个集群是不稳定的,所以这个部分是必须要进行优化的。
我们目前的优化方案是:把所有的 worker 向所有的 master 进行注册,提前进行注册,只要 worker 起来了 那就向所有的 master 重新注册一遍,然后中间通过这种实时的心跳保持 worker 状态的更新。那么这个优化到底产生了怎样效果?可以看下图:
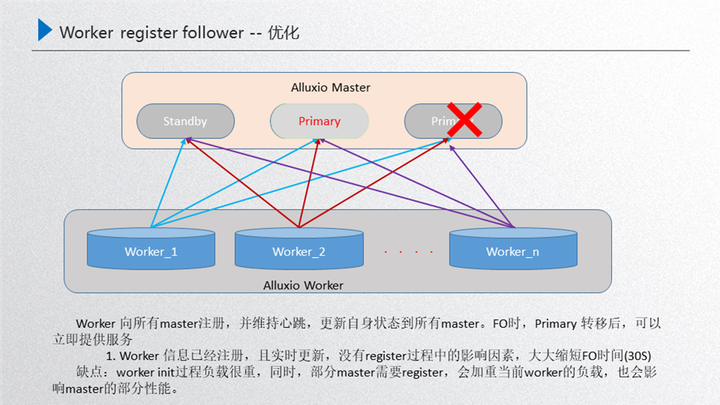
这个时候如果 primary 被重启了,内部通过 raft 进行选举,选举出来的这个新的 primary 对外提供服务,primary 的选举需要经历几部分:第一部分就是 primary 被重启之后,raft 进行自发现,自发现之后两者之间进行重新选举,选举出来之后这个新的 primary 经过 catch up 后就可以对外提供服务了,就不需要重新去获取 worker 进行一个 register,所以这就可以把时间完全节省下来,只需要三步:自发现、选举、catch up。 这个方案的效率非常高,只需要 30 秒以内就可以完成,这就大大缩短了 FO 的时间。另一个层面来说,这里也有一些负面的影响,主要是其中一个 master 如果进行了重启,那么对外来说这个 primary 是可以提供正常服务的,然后这个 standby 重启的话,在对外提供服务的同时,worker 又需要重新注册这个 block 的元数据信息,这个 block 元数据信息其实流量是非常大的,这时会对当前的 worker 有一定影响,而且对部分注册上来的 master 性能也有影响,如果这个时候集群的负载不是很重的话,是完全可以忽略的,所以做了这样的优化。
2.Master 的迁移问题
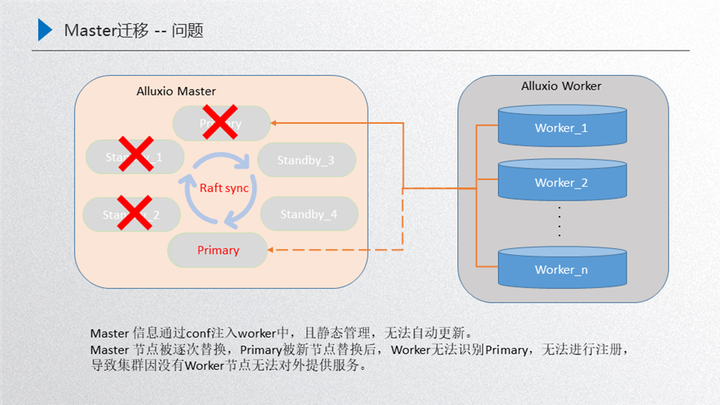
如图所示,其实刚开始是由这三者 master 对外提供服务, 这三者达到一个稳定的状态,然后 worker 注册到 primary 对外提供服务,这个时候如果对机器做了一些腾挪,比如 standby3 把 standby1 替换掉,然后 standby4 把 standby2 替换掉,然后新的 primary 把老的 primary 替换掉,这个时候新的这个 master 的集群节点就是由这三者组成:standby3、standby4、新的 primary,按照正常的流程来说,这个 worker 是需要跟当前这个新的集群进行建联的,维持一个正常的心跳,然后对外提供服务,但是这时候并没有,主要原因就是 worker 识别的 master 信息其实是一开始由 configer 进行静态注入的,在初始化的时候就已经写进去了,而且后台是静态管理的,没有动态的更新,所以永远都不能识别这三个节点, 识别的永远是三个老节点,相当于是说这种场景直接把整个集群搞挂了,对外没有 data 节点就不可提供服务了,恢复手段主要是需要手动把这三个新节点注册到 configer 当中,重新把这个 worker 重启一遍,然后进行识别,如果这个时候集群规模比较大,worker 节点数量比较多,那这时的运维成本就会非常大,这是我们面临的 master 迁移问题,接下来看一下怎么应对这种稳定性:
我们的解决方案是在 primary 和 worker 之间维持了一个主心跳,如果 master 节点变更了就会通过主心跳同步当前的 worker,实现实时更新 master 节点,比如 standby3 把 standby1 替换掉了,这个时候 primary 会把当前的这三个节点:primary、standby2、standby3 通过主心跳同步过来给当前的 worker,这个时候 worker 就是最新的,如果再把 standby4、standby2 替换,这时候又会把这三者之间的状态同步过来,让他保持是最新的,如果接下来把新的 primary 加进来,就把这四者之间同步过来,重启之后进行选举,选举出来之后 这就是新的 primary,由于 worker 节点最后的一步是存着这四个节点,在这四个节点当中便利寻找当前的 leader,然后就可以识别新的 primary,再把这三个新的 master 同步过来 这样就达到一个安全的迭代过程,这样的情况下再受资源调度腾挪的时候,就可以稳定的腾挪下去。以上两部分就是稳定性建设的内容。
三、性能优化
性能优化我们主要进行了 follower read only 的过程,首先给大家介绍一下背景,如图所示:
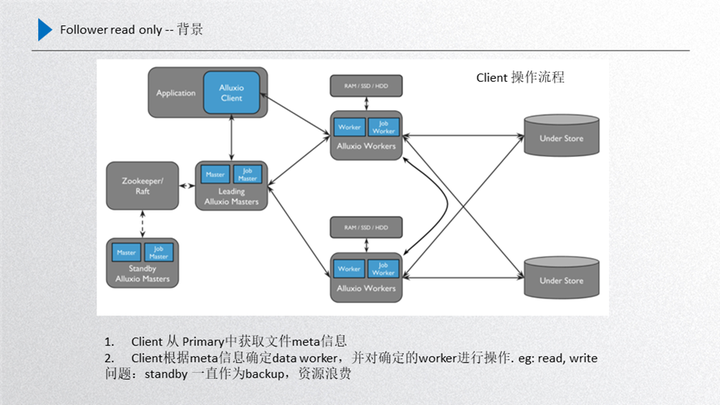
这个是当前 Alluxio 的整体框架,首先 client 端从 leader 拿取到元数据,根据元数据去访问正常的 worker,leader 和 standby 之间通过 raft 进行与元数据一致性的同步,leader 进行元数据的同步只能通过 leader 发起然后同步到 standby,所以说他是有先后顺序的。而 standby 不能通过发起新的信息同步到 leader,这是一个违背数据一致性原则的问题。
另一部分就是当前的这个 standby 经过前面的 worker register follower 的优化之后,其实 standby 和 worker 之间也是有一定联系的,而且数据都会收集上来,这样就是 standby 在数据的完整性上已经具备了 leader 的属性,也就是数据基本上和 leader 是保持一致的。
而这一部分如果再把它作为 backup,即作为一种稳定性备份的话,其实就是一种资源的浪费,想利用起来但又不能打破 raft 数据一致性的规则,这种情况下我们就尝试是不是可以提供只读服务, 因为只读服务不需要更新 raft 的 journal entry,对一致性没有任何的影响,这样 standby 的性能就可以充分利用起来,所以说这里想了一些优化的方案,而且还牵扯了一个业务场景,就是如果我们的场景适用于模型训练或者文件的 cache 加速的,那只有第一次预热的时候数据才会有写入,后面是只读的,针对大量只读场景应用 standby 对整个集群的性能取胜是非常可观的。
下面是详细的优化方案,如图所示:
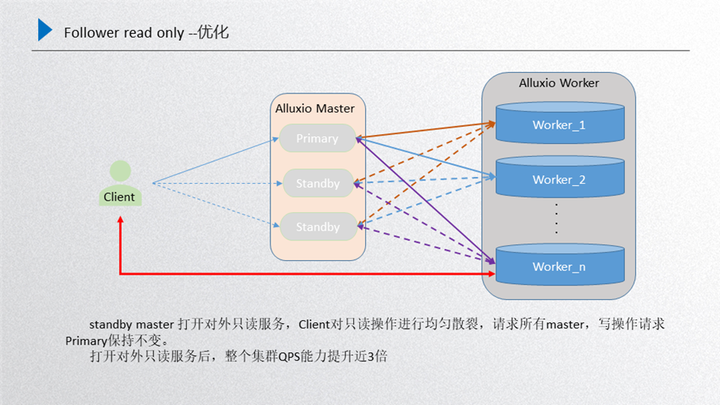
主要是针对前面进行的总结,所有的 worker 向所有的 standby 进行注册,这时候 standby 的数据和 primary 的数据基本上是一致的,另一部分还是 primary 和 worker 之间维护的主心跳,这个时候如果 client 端再发起只读请求的时候,就会随机散列到当前所有的 master 上由他们进行处理,处理完成之后返回 client 端,对于写的请求还是会发放到 primary 上去。然后在不打破 raft 一致性的前提下,又可以把只读的性能提升,这个机器扩展出来,按照正常推理来说,只读性能能够达到三倍以上的扩展,通过 follower read 实际测验下来效果也是比较明显的。这是我们引入 Alluxio 之后对性能的优化。
四、规模提升
规模提升主要是横向扩展,首先看一下这个问题的背景:如图所示:
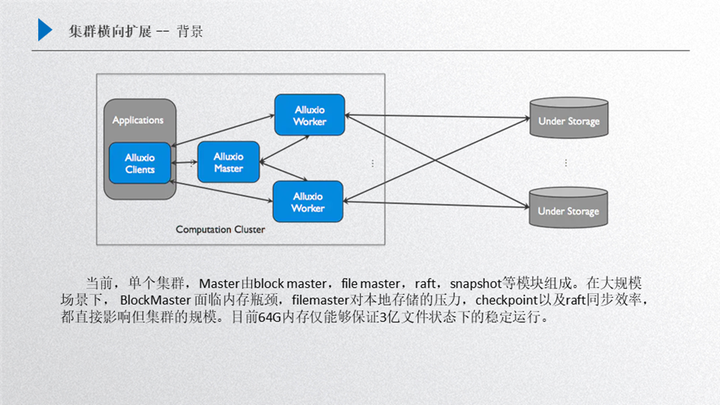
还是 Alluxio 的框架,master 里面主要包含了很多构件元素,第一个就是 block master,第二个是 file master,另外还有 raft 和 snapshot,这个部分的主要影响因素就是在这四个方面:
Bblock master,如果我们是大规模集群创建下,block master 面临的瓶颈就是内存,它会侵占掉大量 master 的内存,主要是保存的 worker 的 block 信息;
File master,主要是保存了 inode 信息,如果是大规模场景下,对本地存储的压力是非常大的
Raft 面临的同步效率问题;
snapshot 的效率,如果 snapshot 的效率跟不上,可以发现后台会积压非常多 journal entry,这对性能提升也有一定影响;
做了一些测试之后,在大规模场景下,其实机器规格不是很大的话,也就支持 3-6 个亿这样的规模,如果想支持 10 亿甚至上百亿这样的规模,全部靠扩大存储机器的规格是不现实的,因为模型训练的规模可以无限增长,但是机器的规格不可以无限扩充,那么针对这个问题我们是如何优化的呢?
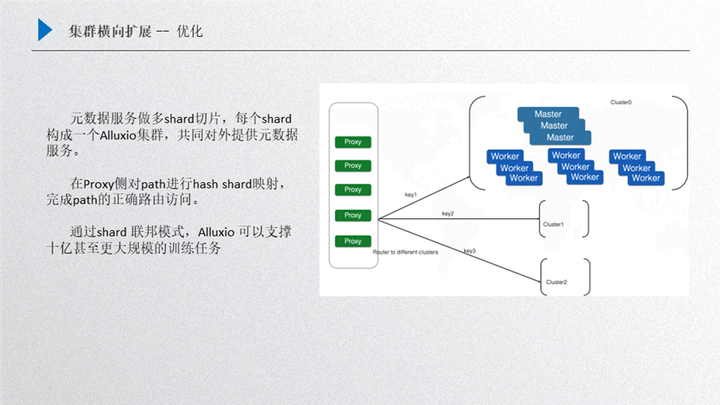
这个优化我们主要借鉴了 Redis 的实现方案,就是可以在底层对元数据进行分片,然后由多个 cluster 集群对外提供服务,这样做的一个好处就是对外可以提供一个整体,当然也可以采取不同的优化策略,比如多个集群完全由用户自己去掌控,把不同的数据分配到每一个集群上,但这样对用户的使用压力就会比较大。先来介绍一下这个框架,首先我们把这个元数据进行一个分片,比如用户拿到的整体数据规模集合比较大,单集群放不下了,这时候会把大规模的数据集合进行一个分片,把元数据进行一些哈希(Hash)映射,把一定 hash 的值映射到其中某一个 shard 上,这样 cluster 这个小集群就只需要去缓存对应部分 key 对应的文件,这样就可以在集群上面有目标性的进行选择。
那么接下来其他的数据就会留给其他 cluster,把全量的 hash 分配到一个设定的集群规模上,这样就可以通过几个 shard 把整个大的模型训练文件数量 cache 下来,对外提供大规模的模型训练,然后我们的前端是增加了 proxy,proxy 其实内部是维护一张 hash 映射表的,用户过来的请求其实是通过 proxy 进行 hash 的映射查找,然后分配到固定的某一个集群上进行处理,比如过来的一个文件请求通过计算它的 hash 映射可以判定 hash 映射路由到 cluster1 上面去,这样其实就可以由 cluster1 负责,其他 key 的映射分配到其他 cluster 上,把数据打散,这样的好处有很多方面:
第一个就是元数据承载能力变大了;
第二个就把请求的压力分配到多个集群上去,整体的 qps 能力、集群的吞吐能力都会得到相应的提升;
第三个就是通过这种方案,理论上可以扩展出很多的 cluster 集群,如果单个集群支持的规模是 3-6 个亿,那三个集群支持的规模就是 9-18 亿,如果扩展的更多,对百亿这种规模也可以提供一种支持的解决方案。
以上是我们对模型进行的一些优化。整个的框架包括稳定性的建设、性能的优化和规模的提升。
在稳定建设方面:我们可以把整个集群做 FO 的时间控制在 30 秒以内,如果再配合一些其他机制,比如 client 端有一些元数据缓存机制,就可以达到一种用户无感知的条件下进行 FO,这种效果其实也是用户最想要的,在他们无感知的情况下,底层做的任何东西都可以恢复,他们的业务训练也不会中断,也不会有感到任何的错误,所以这种方式对用户来说是比较友好的。
在性能优化方面:单个集群的吞吐已经形成了三倍以上提升,整个性能也会提升上来,可以支持更大并发的模型训练任务。
在模型规模提升方面:模型训练集合越来越大,可以把这种模型训练引入进来,对外提供支持。
在 Alluxio 引入蚂蚁适配这些优化之后,目前运行下来对各个方向业务的支持效果都是比较明显的。另外目前我们跟开源社区也有很多的合作,社区也给我们提供很多帮助,比如在一些比较着急的问题上,可以给我们提供一些解决方案和帮助,在此我们表示感谢!
【案例三:微软】面向大规模深度学习训练的缓存优化实践
分享嘉宾:张虔熙 - 微软高级研发工程师
导读
近些年,随着深度学习的崛起, Alluxio 分布式缓存技术逐步成为业界解决云上 IO 性能问题的主流方案。不仅如此,Alluxio 还天然具备数据湖所需的统一管理和访问的能力。本文将分享面向大规模深度学习训练的缓存优化,主要分析如今大规模深度学习训练的存储现状与挑战,说明缓存数据编排在深度学习训练中的应用,并介绍大规模缓存系统的资源分配与调度。
一、项目背景和缓存策略
首先来分享一下相关背景。
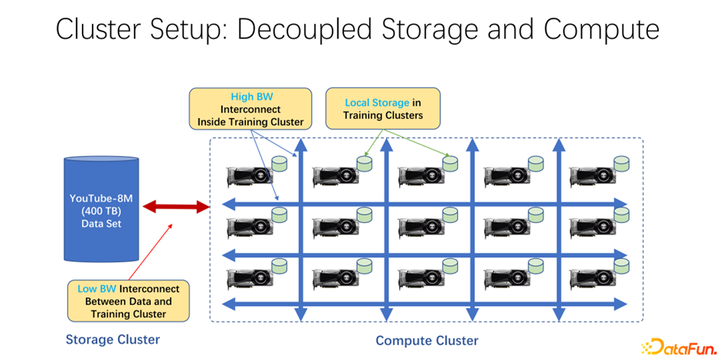
近年来,AI 训练应用越来越广泛。从基础架构角度来看,无论是大数据还是 AI 训练集群中,大多使用存储与计算分离的架构。比如很多 GPU 的阵列放到一个很大的计算集群中,另外一个集群是存储。也可能是使用的一些云存储,像微软的 Azure 或者是亚马逊的 S3 等。这样的基础架构的特点是,首先,计算集群中有很多非常昂贵的 GPU,每台 GPU 往往有一定的本地存储,比如 SSD 这样的几十 TB 的存储。这样一个机器组成的阵列中,往往是用高速网络去连接远端,比如 Coco、 image net、YouTube 8M 之类的非常大规模的训练数据是以网络进行连接的。
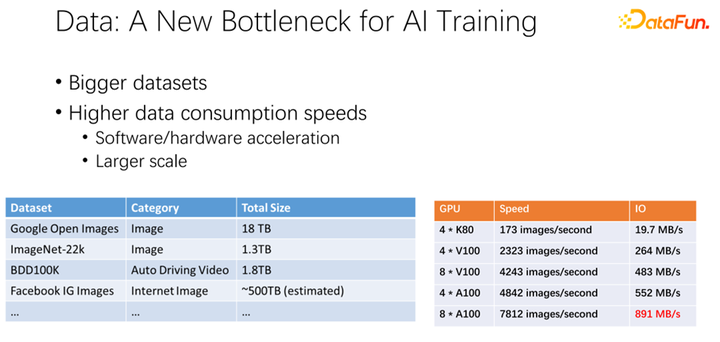
如上图所示,数据有可能会成为下一个 AI 训练的瓶颈。我们观察到数据集越来越大,随着 AI 应用更加广泛,也在积累更多的训练数据。同时 GPU 赛道是非常卷的。比如 AMD、TPU 等厂商,花费了大量精力去优化硬件和软件,使得加速器,类似 GPU、TPU 这些硬件越来越快。随着公司内加速器的应用非常广泛之后,集群部署也越来越大。这里的两个表呈现了关于数据集以及 GPU 速度的一些变化。之前的 K80 到 V100、 P100、 A100,速度是非常迅速的。但是,随着速度越来越快,GPU 变得越来越昂贵。我们的数据,比如 IO 速度能否跟上 GPU 的速度,是一个很大的挑战。
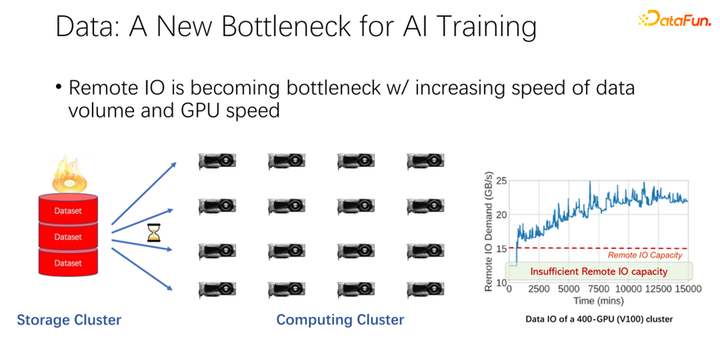
如上图所示,在很多大公司的应用中,我们观察到这样一个现象:在读取远程数据的时候,GPU 是空闲的。因为 GPU 是在等待远程数据读取,这也就意味着 IO 成为了一个瓶颈,造成了昂贵的 GPU 被浪费。有很多工作在进行优化来缓解这一瓶颈,缓存就是其中很重要的一个优化方向。这里介绍两种方式。

第一种,在很多应用场景中,尤其是以 K8s 加 Docker 这样的基础 AI 训练架构中,用了很多本地磁盘。前文中提到 GPU 机器是有一定的本地存储的,可以用本地磁盘去做一些缓存,把数据先缓存起来。启动了一个 GPU 的 Docker 之后,不是马上启动 GPU 的 AI 训练,而是先去下载数据,把数据从远端下载到 Docker 内部,也可以是挂载等方式。下载到 Docker 内部之后再开始训练。这样尽可能的把后边的训练的数据读取都变成本地的数据读取。本地 IO 的性能目前来看是足够支撑 GPU 的训练的。VLDB 2020 上面,有一篇 paper,CoorDL,是基于 DALI 进行数据缓存。这一方式也带来了很多问题。首先,本地的空间是有限的,意味着缓存的数据也是有限的,当数据集越来越大的时候,很难缓存到所有数据。另外,AI 场景与大数据场景有一个很大的区别是,AI 场景中的数据集是比较有限的。不像大数据场景中有很多的表,有各种各样的业务,每个业务的数据表的内容差距是非常大的。在 AI 场景中,数据集的规模、数据集的数量远远小于大数据场景。所以常常会发现,公司中提交的任务很多都是读取同一个数据。如果每个人下载数据到自己本地,其实是不能共享的,会有非常多份数据被重复存储到本地机器上。这种方式显然存在很多问题,也不够高效。
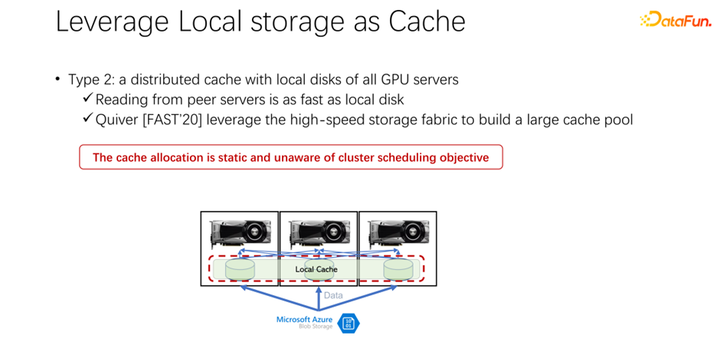
接下来介绍第二种方式。既然本地的存储不太好,那么,是否可以使用像 Alluxio 这样一个分布式缓存来缓解刚才的问题,分布式缓存有非常大的容量来装载数据。另外,Alluxio 作为一个分布式缓存,很容易进行共享。数据下载到 Alluxio 中,其他的客户端,也可以从缓存中读取这份数据。这样看来,使用 Alluxio 可以很容易地解决上面提到的问题,为 AI 训练性能带来很大的提升。微软印度研究院在 FAST2020 发表的名为 Quiver 的一篇论文,就提到了这样的解决思路。但是我们分析发现,这样一个看似完美的分配方案,还是比较静态的,并不高效。同时,采用什么样的 cache 淘汰算法,也是一个很值得讨论的问题。
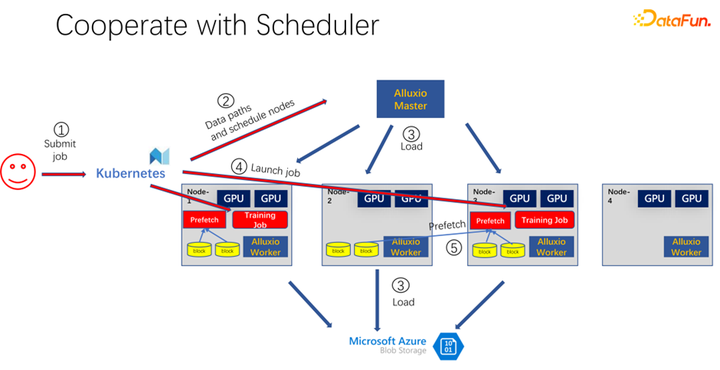
如上图所示,是使用 Alluxio 作为 AI 训练的缓存的一个应用。使用 K8s 做整个集群任务的调度和对 GPU、CPU、内存等资源的管理。当有用户提交一个任务到 K8s 时,K8s 首先会做一个插件,通知 Alluxio 的 master,让它去下载这部分数据。也就是先进行一些热身,把作业可能需要的任务,尽量先缓存一些。当然不一定非得缓存完,因为 Alluxio 是有多少数据,就使用多少数据。剩下的,如果还没有来得及缓存,就从远端读取。另外,Alluxio master 得到这样的命令之后,就可以让调度它的 worker 去远端。可能是云存储,也可能是 Hadoop 集群把数据下载下来。这个时候,K8s 也会把作业调度到 GPU 集群中。比如上图中,在这样一个集群中,它选择第一个节点和第三个节点启动训练任务。启动训练任务之后,需要进行数据的读取。在现在主流的像 PyTorch、Tensorflow 等框架中,也内置了 Prefetch,也就是会进行数据预读取。它会读取已经提前缓存的 Alluxio 中的缓存数据,为训练数据 IO 提供支持。当然,如果发现有一些数据是没有读到的,Alluxio 也可以通过远端进行读取。Alluxio 作为一个统一的接口是非常好的。同时它也可以进行数据的跨作业间的共享。
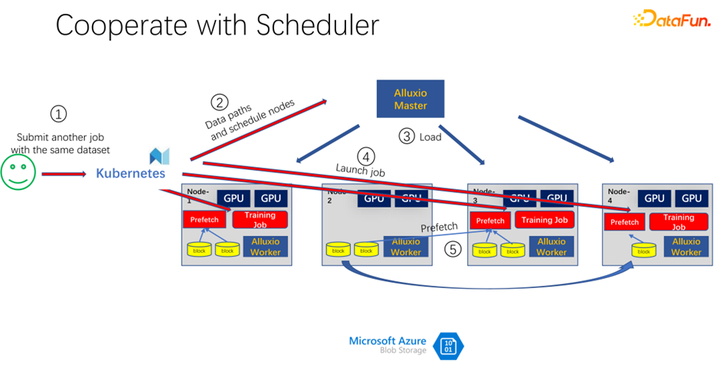
如上图所示,比如又有一个人提交了同样数据的另一个作业,消耗的是同一个数据集,这个时候,当提交作业到 K8s 的时候,Alluxio 就知道已经有这部分数据了。如果 Alluxio 想做的更好,甚至是可以知道,数据即将会被调度到哪台机器上。比如这个时候调度到 node 1、node 3 和 node 4 上。node 4 的数据,甚至可以做一些副本进行拷贝。这样所有的数据,即使是 Alluxio 内部,都不用跨机器读,都是本地的读取。所以看起来 Alluxio 对 AI 训练中的 IO 问题有了很大的缓解和优化。但是如果仔细观察,就会发现两个问题。

第一个问题就是缓存的淘汰算法非常低效,因为在 AI 场景中,访问数据的模式跟以往有很大区别。第二个问题是,缓存作为一种资源,与带宽(即远程存储的读取速度)是一个对立的关系。如果缓存大,那么从远端读取数据的机会就小。如果缓存很小,则很多数据都得从远端读取。如何很好地调度分配这些资源也是一个需要考虑的问题。
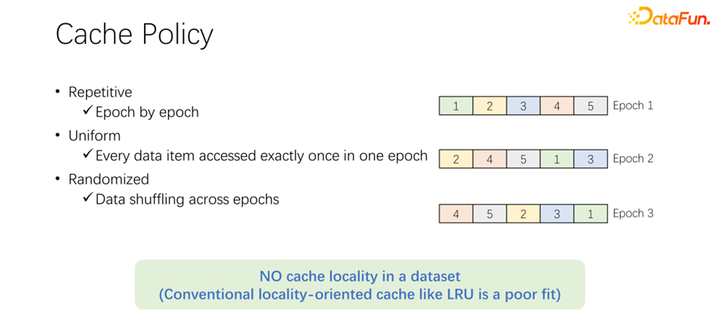
在讨论缓存的淘汰算法之前,先来看一下 AI 训练中数据访问的过程。在 AI 训练中,会分为很多个 epoch,不断迭代地去训练。每一个训练 epoch,都会读取每一条数据,并且仅读一次。为了防止训练的过拟合,在每一次 epoch 结束之后,下一个 epoch 的时候,读取顺序会变化,会进行一个 shuffle。也就是每次每个 epoch 都会把所有数据都读取一次,但是顺序却不一样。Alluxio 中默认的 LRU 淘汰算法,显然不能很好地应用到 AI 训练场景中。因为 LRU 是利用缓存的本地性。本地性分为两方面,首先是时间本地性,也就是现在访问的数据,马上可能还会即将访问。这一点,在 AI 训练中并不存在。因为现在访问的数据,在下一轮的时候才会访问,而且下一轮的时候都会访问。没有一个特殊的概率,一定是比其他数据更容易被访问。另一方面是数据本地性,还有空间本地性。也就是,为什么 Alluxio 用比较大的 block 缓存数据,是因为某条数据读取了,可能周围的数据也会被读取。比如大数据场景中,OLAP 的应用,经常会进行表的扫描,意味着周围的数据马上也会被访问。但是在 AI 训练场景中是不能应用的。因为每次都会 shuffle,每次读取的顺序都是不一样的。因此 LRU 这种淘汰算法并不适用于 AI 训练场景。

不仅是 LRU,像 LFU 等主流的淘汰算法,都存在这样一个问题。因为整个 AI 训练对数据的访问是非常均等的。所以,可以采用最简单的缓存算法,只要缓存一部分数据就可以,永远不用动。在一个作业来了以后,永远都只缓存一部分数据。永远都不要淘汰它。不需要任何的淘汰算法。这可能是目前最好的淘汰机制。如上图中的例子。上面是 LRU 算法,下面是均等方法。在开始只能缓存两条数据。我们把问题简单一些,它的容量只有两条,缓存 D 和 B 这两条数据,中间就是访问的序列。比如命中第一个访问的是 B,如果是 LRU,B 存在的缓存中命中了。下一条访问的是 C,C 并不在 D 和 B,LRU 的缓存中,所以基于 LRU 策略,会把 D 替换掉,C 保留下来。也就是这个时候缓存是 C 和 B。下一个访问的是 A,A 也不在 C 和 B 中。所以会把 B 淘汰掉,换成 C 和 A。下一个就是 D,D 也不在缓存中,所以换成 D 和 A。以此类推,会发现所有后面的访问,都不会再命中缓存。原因是在进行 LRU 缓存的时候,把它替换出来,但其实在一个 epoch 中已经被访问一次,这个 epoch 中就永远不会再被访问到了。LRU 反倒把它进行缓存了,LRU 不但没有帮助,反倒是变得更糟糕了。不如使用 uniform,比如下面这种方式。下面这种 uniform 的方式,永远在缓存中缓存 D 和 B,永远不做任何的替换。在这样情况下,你会发现至少有 50% 的命中率。所以可以看到,缓存的算法不用搞得很复杂,只要使用 uniform 就可以了,不要使用 LRU、LFU 这类算法。
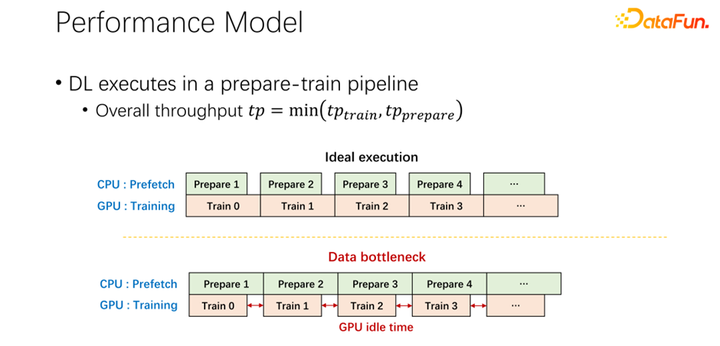
对于第二个问题,也就是关于缓存和远程带宽之间关系的问题。现在所有主流的 AI 框架中都内置了数据预读,防止 GPU 等待数据。所以当 GPU 做训练的时候,其实是触发了 CPU 预取下一轮可能用到的数据。这样可以充分利用 GPU 的算力。但当远程存储的 IO 成为瓶颈的时候,就意味着 GPU 要等待 CPU 了。所以 GPU 会有很多的空闲时间,造成了资源的浪费。希望可以有一个比较好的调度管理方式,缓解 IO 的问题。

缓存和远程 IO 对整个作业的吞吐是有很大影响的。所以除了 GPU、CPU 和内存,缓存和网络也是需要调度的。在以往大数据的发展过程中,像 Hadoop、yarn、my source、K8s 等,主要都是调度 CPU、内存、GPU。对于网络,尤其对于缓存的控制都不是很好。所以,我们认为,在 AI 场景中,需要很好的调度和分配它们,来达到整个集群的最优。
二、SiloD 框架

在 EuroSys 2023 发表了这样一篇文章,它是一个统一的框架,来调度计算资源和存储资源。
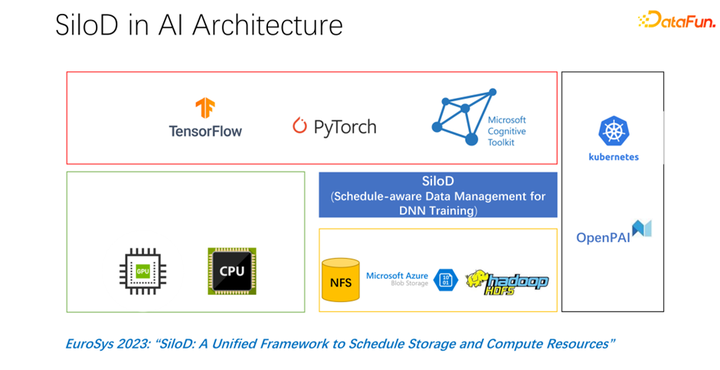
整体架构如上图所示。左下角是集群中的 CPU 和 GPU 硬件计算资源,以及存储资源,如 NFS、云存储 HDFS 等。在上层有一些 AI 的训练框架 TensorFlow、PyTorch 等。我们认为需要加入一个统一管理和分配计算和存储资源的插件,也就是我们提出的 SiloD。
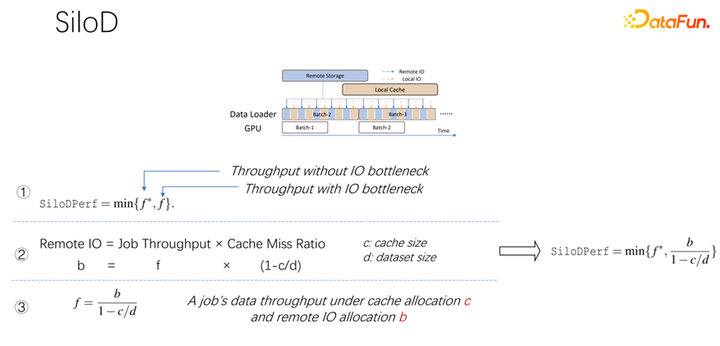
如上图所示,一个作业可以达到什么样的吞吐和性能,是由 GPU 和 IO 的最小值决定的。使用多少个远程 IO,就会使用多少远端的 networking。可以通过这样一个公式算出访问速度。作业速度乘以缓存未命中率,也就是(1-c/d)。其中 c 就是缓存的大小,d 就是数据集。这也就意味着数据只考虑 IO 可能成为瓶颈的时候,大概的吞吐量是等于(b/(1-c/d)),b 就是远端的带宽。结合以上三个公式,可以推出右边的公式,也就是一个作业最终想达到什么样的性能,可以这样通过公式去计算没有 IO 瓶颈时的性能,和有 IO 瓶颈时的性能,取二者中的最小值。
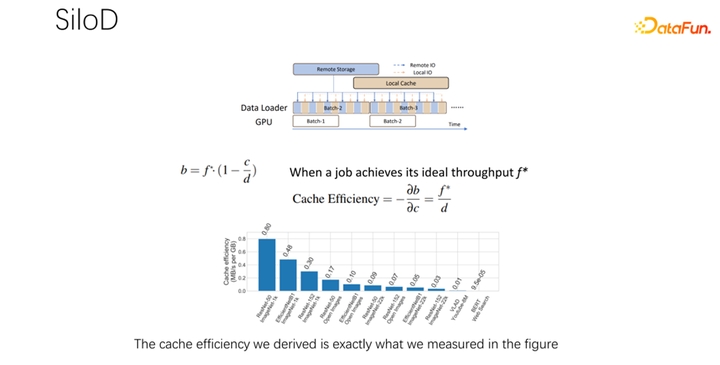
得到上面的公式之后,把它微分一下,就可以得到缓存的有效性,或者叫做缓存效率。即虽然作业很多,但在分配缓存的时候不能一视同仁。每一个作业,基于数据集的不同,速度的不同,缓存分配多少是很有讲究的。这里举一个例子,就以这个公式为例,如果发现一个作业,速度非常快,训练起来非常快,同时数据集很小,这时候就意味着分配更大的缓存,收益会更大。
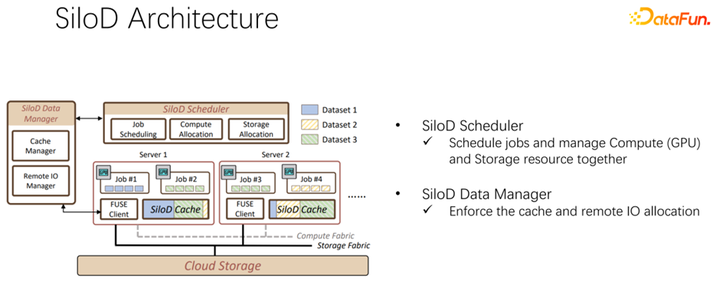
基于以上观察,可以使用 SiloD,进行缓存和网络的分配。而且缓存的大小,是针对每个作业的速度,以及数据集整个的大小来进行分配的。网络也是如此。所以整个架构是这样的:除了主流的像 K8s 等作业调度之外,还有数据管理。在图左边,比如缓存的管理,要统计或者监控分配整个集群中缓存的大小,每个作业缓存的大小,以及每个作业使用到的远程 IO 的大小。底下的作业,和 Alluxio 方式很像,都可以都使用 API 进行数据的训练。每个 worker 上使用缓存对于本地的 job 进行缓存支持。当然它也可以在一个集群中跨节点,也可以进行共享。
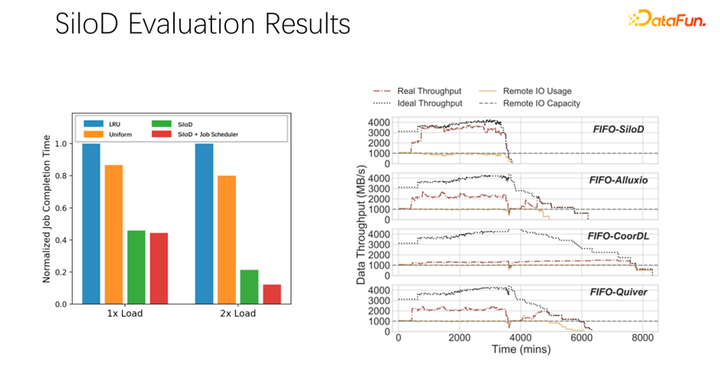
经过初步测试和实验,发现这样一个分配方式可以使整个集群的使用率和吞吐量都得到非常明显的提升,最高可以达到 8 倍的性能上的提升。可以很明显的缓解作业等待、GPU 空闲的状态。

对上述介绍进行一下总结: 第一,在 AI 或者深度学习训练场景中,传统的 LRU、LFU 等缓存策略并不适合,不如直接使用 uniform。 第二,缓存和远程带宽,是一对伙伴,对整体性能起到了非常大的作用。 第三,像 K8s、yarn 等主流调度框架,可以很容易继承到 SiloD。 最后,我们在 paper 中做了一些实验,不同的调度策略,都可以带来很明显的吞吐量的提升。
三、分布式缓存策略以及副本管理
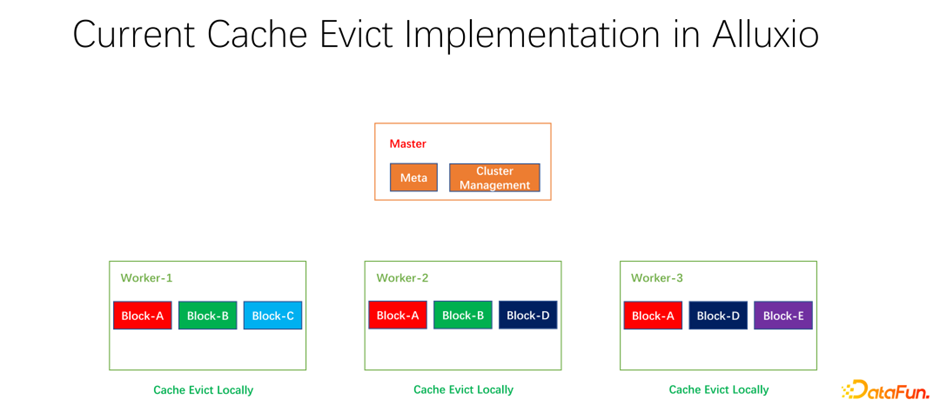
我们还做了一些开源的工作。分布式缓存策略以及副本管理这项工作,已经提交给社区,现在处于 PR 阶段。Alluxio master 主要做 Meta 的管理和整个 worker 集群的管理。真正缓存数据的是 worker。上面有很多以 block 为单位的块儿去缓存数据。存在的一个问题是,现阶段的缓存策略都是单个 worker 的,worker 内部的每个数据在进行是否淘汰的计算时,只需要在一个 worker 上进行计算,是本地化的。
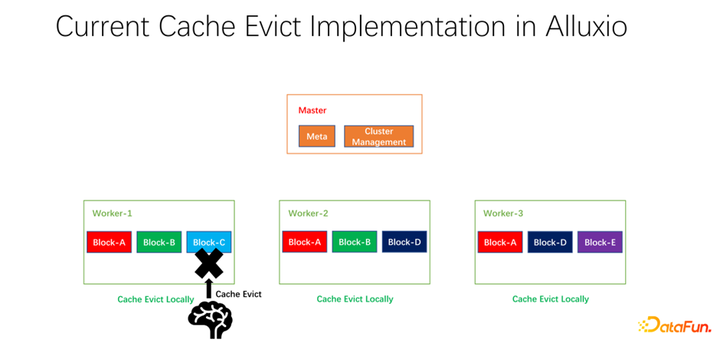
如上图所示的例子,如果 worker 1 上有 block A, block B 和 block C,基于 LRU 算出来 block C 是最长时间没有使用的,就会把 block C 淘汰。如果看一下全局的情况,就会发现这样并不好。因为 block C 在整个集群中只有一个副本。把它淘汰之后,如果下面还有人要访问 block C,只能从远端拉取数据,就会带来性能和成本的损失。我们提出做一个全局的淘汰策略。在这种情况下,不应该淘汰 block C,而应该淘汰副本比较多的。在这个例子中,应该淘汰 block A,因为它在其它的节点上仍然有两个副本,无论是成本还是性能都要更好。
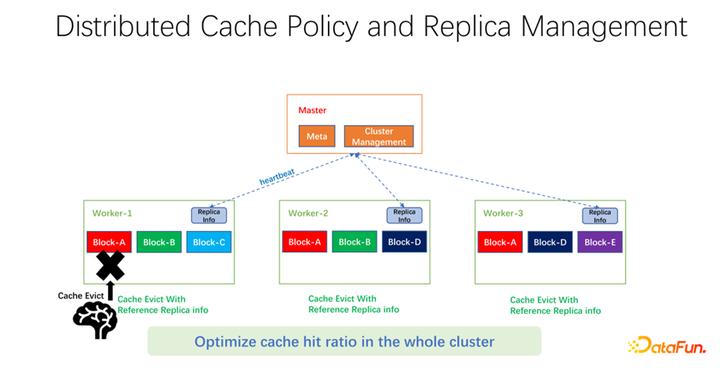
如上图所示,我们做的工作是在每个 worker 上维护副本信息。当某一个 worker,比如加了一个副本,或者减了一个副本,首先会向 master 汇报,而 master 会把这个信息作为心跳返回值,返回给其它相关的 worker。其它 worker 就可以知道整个全局副本的实时变化。同时,更新副本信息。所以当进行 worker 内部的淘汰时,可以知道每一个 worker 在整个全局有多少个副本,就可以设计一些权重。比如仍然使用 LRU,但是会加上副本个数的权重,综合考量淘汰和替换哪些数据。经过我们初步的测试,在很多领域,无论是 big data,AI training 中都可以带来很大的提升。所以不仅仅是优化一台机器上一个 worker 的缓存命中。我们的目标是使得整个集群的缓存命中率都得到提升。

最后,对全文进行一下总结。首先,在 AI 的训练场景中,uniform 缓存淘汰算法要比传统的 LRU、LFU 更好。第二,缓存和远端的 networking 也是一个需要被分配和调度的资源。第三,在进行缓存优化时,不要只局限在一个作业或者一个 worker 上,应该统揽整个端到端全局的参数,才能使得整个集群的效率和性能有更好的提升。
审核编辑:刘清
-
存储器
+关注
关注
38文章
7481浏览量
163751 -
缓存器
+关注
关注
0文章
63浏览量
11657 -
机器学习
+关注
关注
66文章
8401浏览量
132534 -
MYSQL数据库
+关注
关注
0文章
96浏览量
9389 -
HDFS
+关注
关注
1文章
30浏览量
9585 -
AI大模型
+关注
关注
0文章
314浏览量
305
原文标题:Alluxio助力AI大模型训练
文章出处:【微信号:OSC开源社区,微信公众号:OSC开源社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
训练AI大模型需要什么样的gpu
如何训练自己的AI大模型
如何训练ai大模型
ai模型训练需要什么配置
AI训练的基本步骤
ai大模型和ai框架的关系是什么
AI大模型训练成本飙升,未来三年或达千亿美元
摩尔线程与师者AI携手完成70亿参数教育AI大模型训练测试
【大语言模型:原理与工程实践】大语言模型的预训练
AI训练,为什么需要GPU?






 工商网监
工商网监
评论