 wenet的优化
wenet的优化
wenet概述#
wenet处理流程#
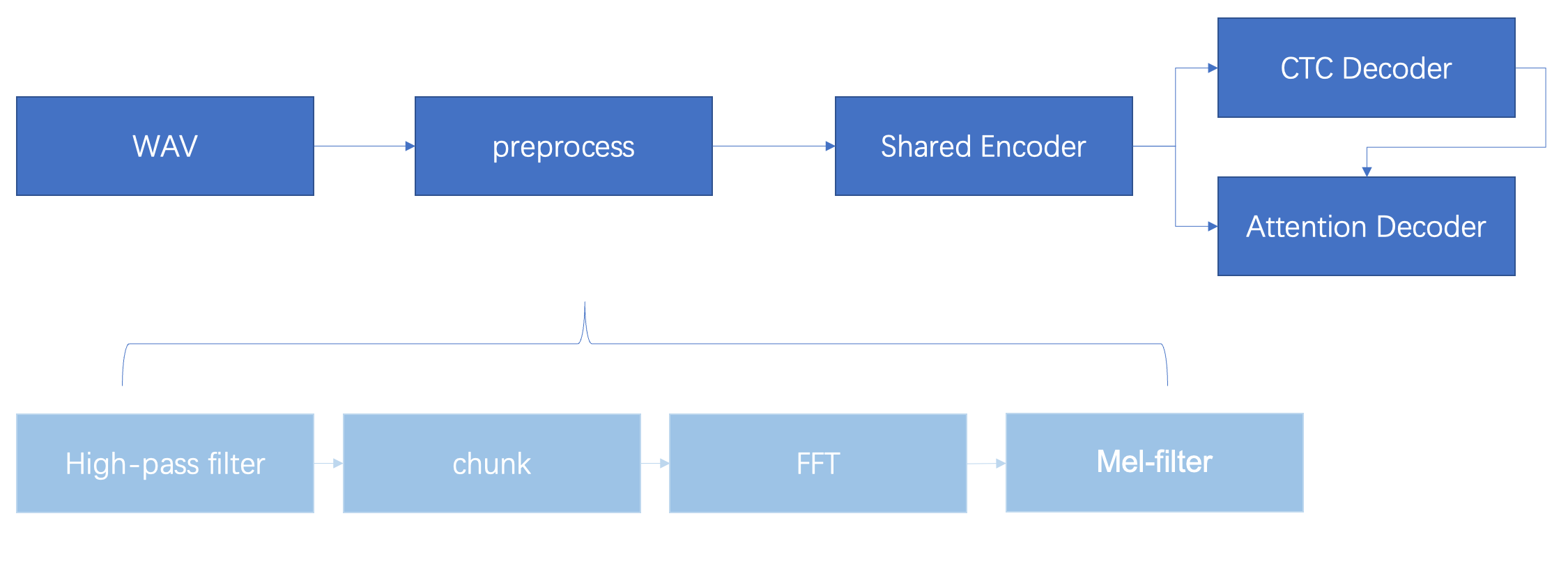
wav语音经过一系列前处理之后送入encoder,encoder的输出会给到ctc decoder和attention decoder。其中ctc decoder是深度优先的搜索程序,负责搜索出n段候选预测序列,然后ctc的结构与encoder的结果一起送入attention decoder进行预测序列的打分,选出最好的预测序列,输出结果
模型结构#
encoder#
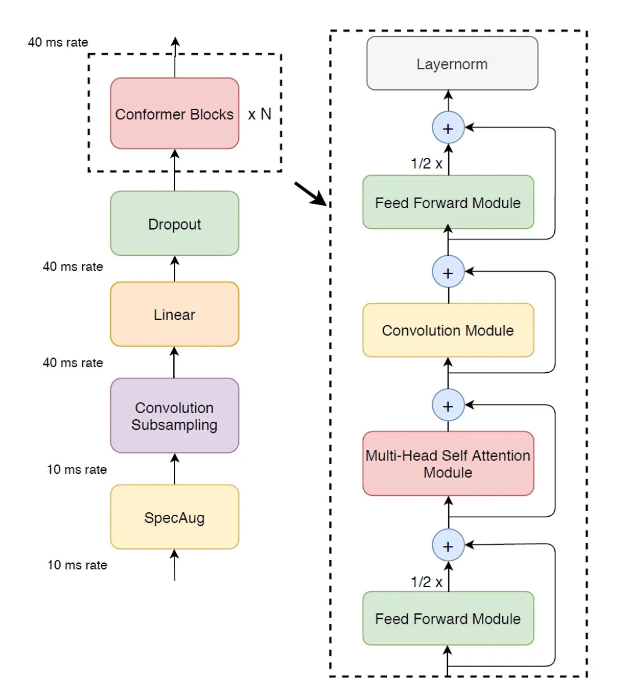
encoder是12个conformer模块堆叠
decoder#
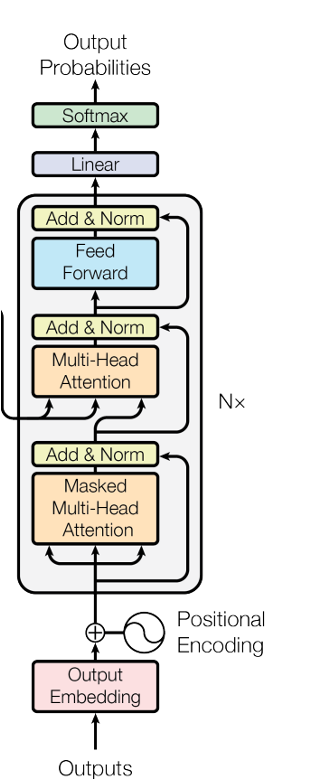
decoder基本结构是transformer,先经过字的自注意力再和mel特征进行交叉注意力,wenet的decoder是双向decoder,有一个预测序列从左到右的打分,还一个从右到左的打分,每个decoder堆叠3个transformer(取决于训练时的配置文件,也可以是6个)
模型优化#
图优化#
结合netron观察模型图结构,考虑以下几个优化方向
删除冗余算子
算子融合
改变算子执行顺序
Where(MaskedFill)的优化#
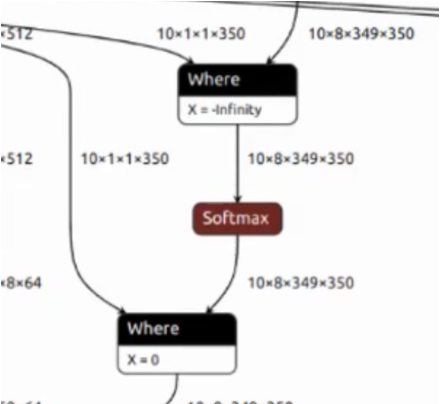
这段网络是在做掩码操作,即输入一个掩码 Tensor对数据做Mask,第一个Where把不需要的数据设置为-inf。经过Softmax之后这些数据已经变成了0,但是后面又增加了一个Where,把相同位置再次设置为了0。
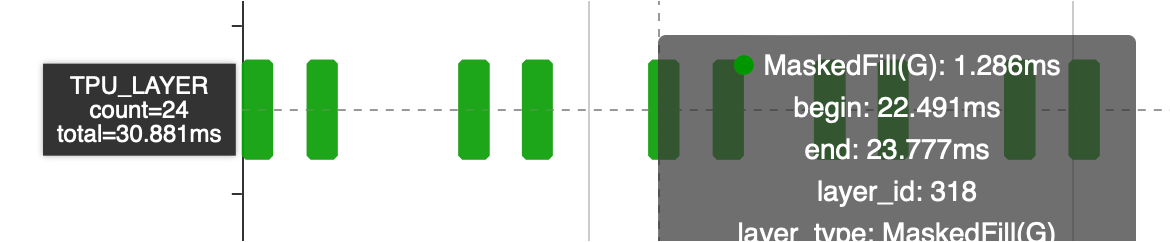
这段结构在网络中出现了12次,单Where算子耗时30 ms相当于多了一倍的计算时间,可以在编译阶段使用图优化进行消除,减少模型计算量。
耗时从30ms降低到15ms
MatMul的优化#
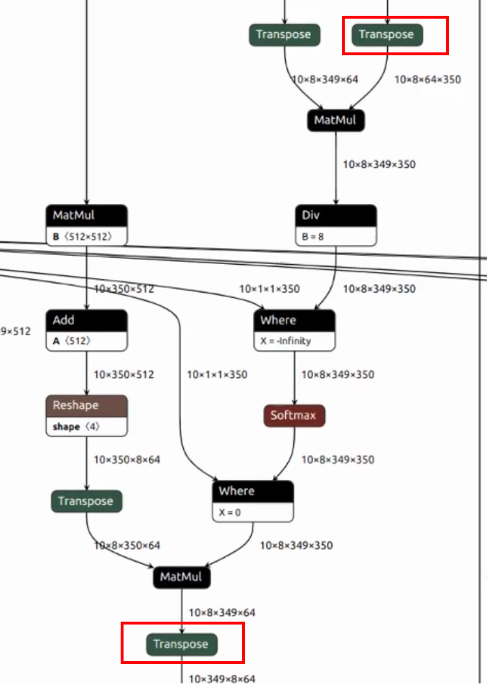
1.这段结构在Decoder中出现6次,且属于计算集中的attention部分。但是C维度在transpose之后只有8,我们的TPU有64个lane,算力没有完全利用起来
2.有transpose隔断了layer group,增加了数据搬运
优化:
1.可以使用hdim_is_batch优化,把attention的head放在h维。为了保证网络变换前后等效,需要在matmul后面新生成一个transpose。
2.生成新的transpose之后,实现masked fill算子、softmax算子的transpose move down的优化pattern,使得tranpose的执行顺序可以放到该段结构结束处,同时与结束处原本有的tranpose做抵消,达到减少数据搬运的目的。
3.由于消除了transpose,使得这段网络可以做到local layer,同时因为把349放到c维度了,又可以充分利用64个lane的计算资源了
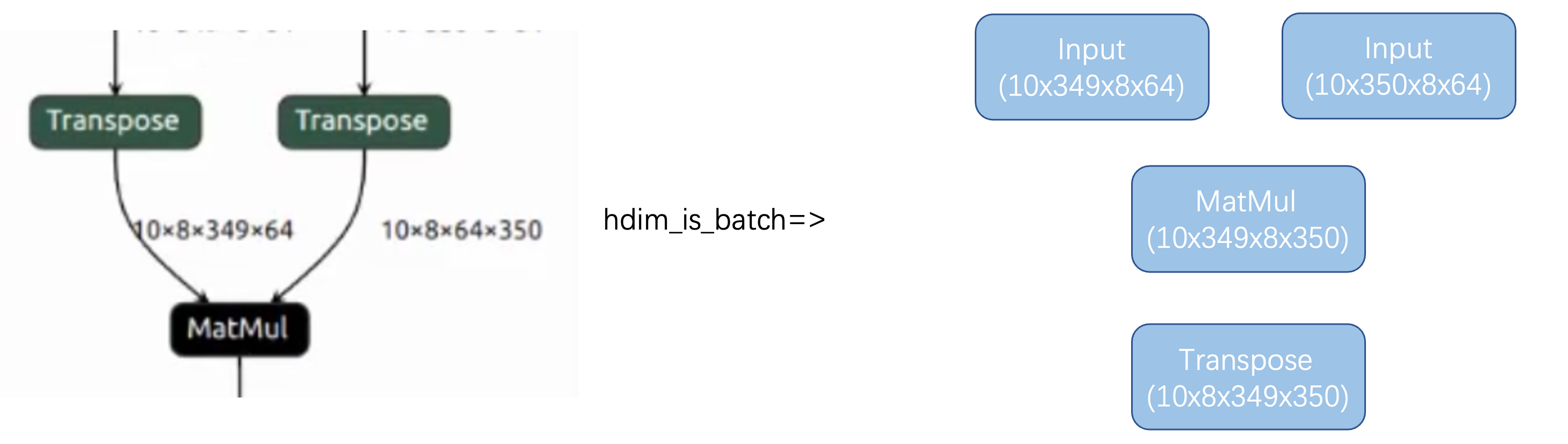
其余的算子经过transpose move down,可以实现transpose的一路下移,在局部网络中让C可以保持349,使得64个lane可以获得更充分的利用
算子层面优化#
Where(MaskedFill)的优化#
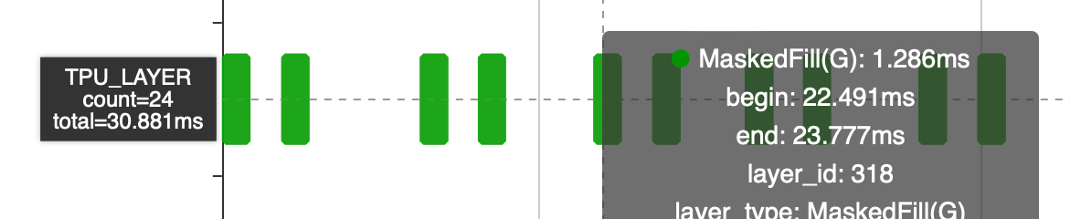
MaskedFill如果全走Global耗时30ms,即便减少一半的算子数量还是15ms。而Select算子有local的实现,同时可以通过参数配置完成MaskedFill的功能,但不支持广播。所以在编译阶段加入Tile完成广播,从而支持Local Layer。
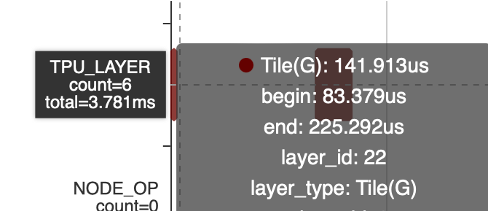
但引入了Tile,Tile操作本身耗时3.8ms,代价可接受,后续可以进一步优化
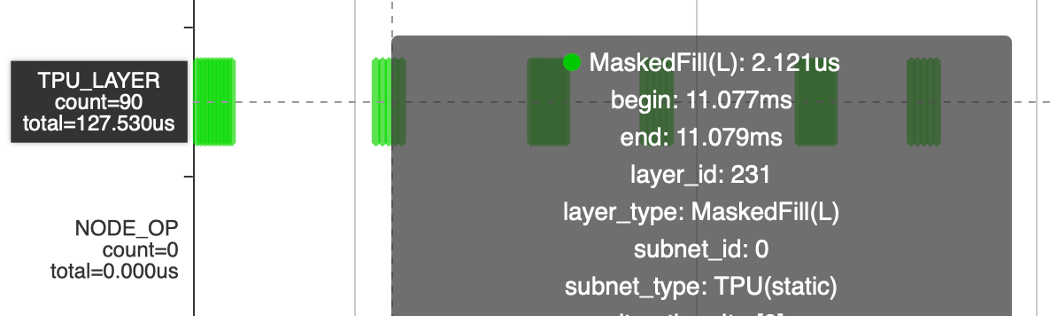
MaskedFill算子从30ms 减半数量后到15ms,引入tile之后减少到3.8ms(Tile)+127us(MaskedFill)
后续考虑使用bdc完成tile操作,完成进一步优化
CPU Layer的优化#
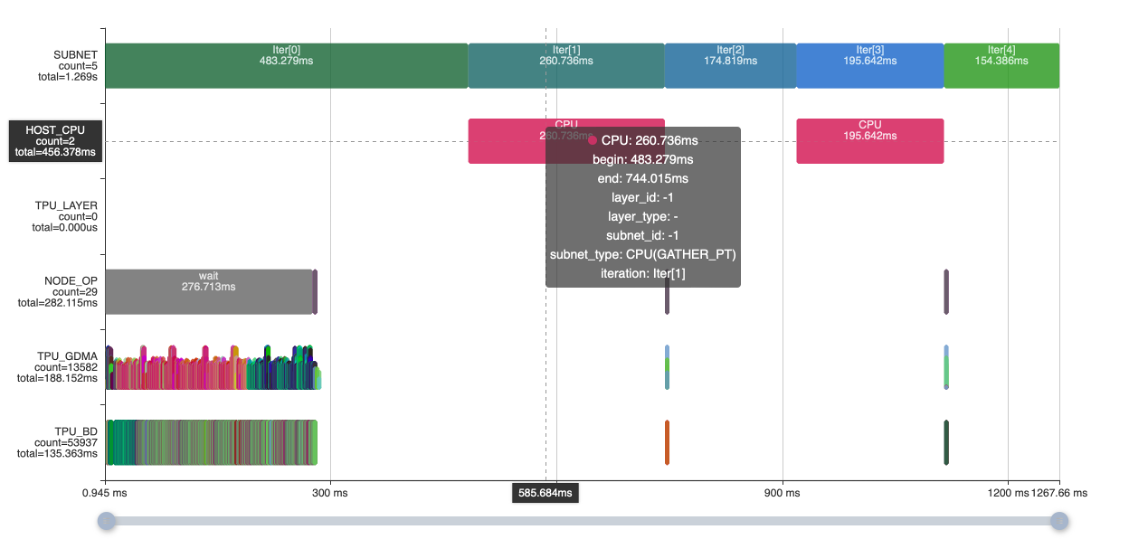
两个CPU Gather PT操作占用456ms,可以使用dma的Gather操作在TPU实现算子
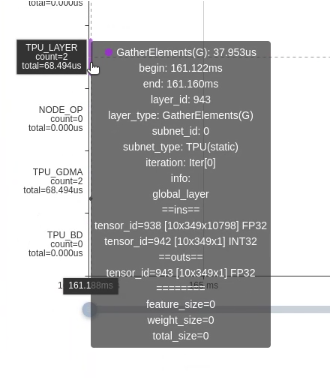
Gather PT算子从456ms减少到68us
优化结果#
| WeNet Decoder | 耗时 |
|---|---|
| 原始模型 | 611ms |
| CPU Layer替换 | 156ms |
| MaskedFill 减半 | 141ms |
| MatMul hdim_is_batch优化+Permute Move优化+MaskedFill支持Local | 71ms |
-
cpu
+关注
关注
68文章
10882浏览量
212236 -
模型
+关注
关注
1文章
3268浏览量
48929 -
算子
+关注
关注
0文章
16浏览量
7267
发布评论请先 登录
相关推荐







 工商网监
工商网监
评论