 TPU-MLIR中的融合处理
TPU-MLIR中的融合处理
通常,模型的输入是 预处理过的NCHW 格式的张量,但有时我们可能希望直接将原始图像输入模型。 在这种情况下,我们需要将预处理操作作为模型的一部分。我们目前支持这些类型的图像输入,它们对应不同的像素和通道格式。 其中一些是专门针对 CV 系列芯片的,所以这部分我们暂且先不深入探讨。
对于预处理类型,我们目前可以做一些典型的预处理操作,包括中心裁剪、转置、像素格式变换和归一化,更多类型的操作会在未来完成。
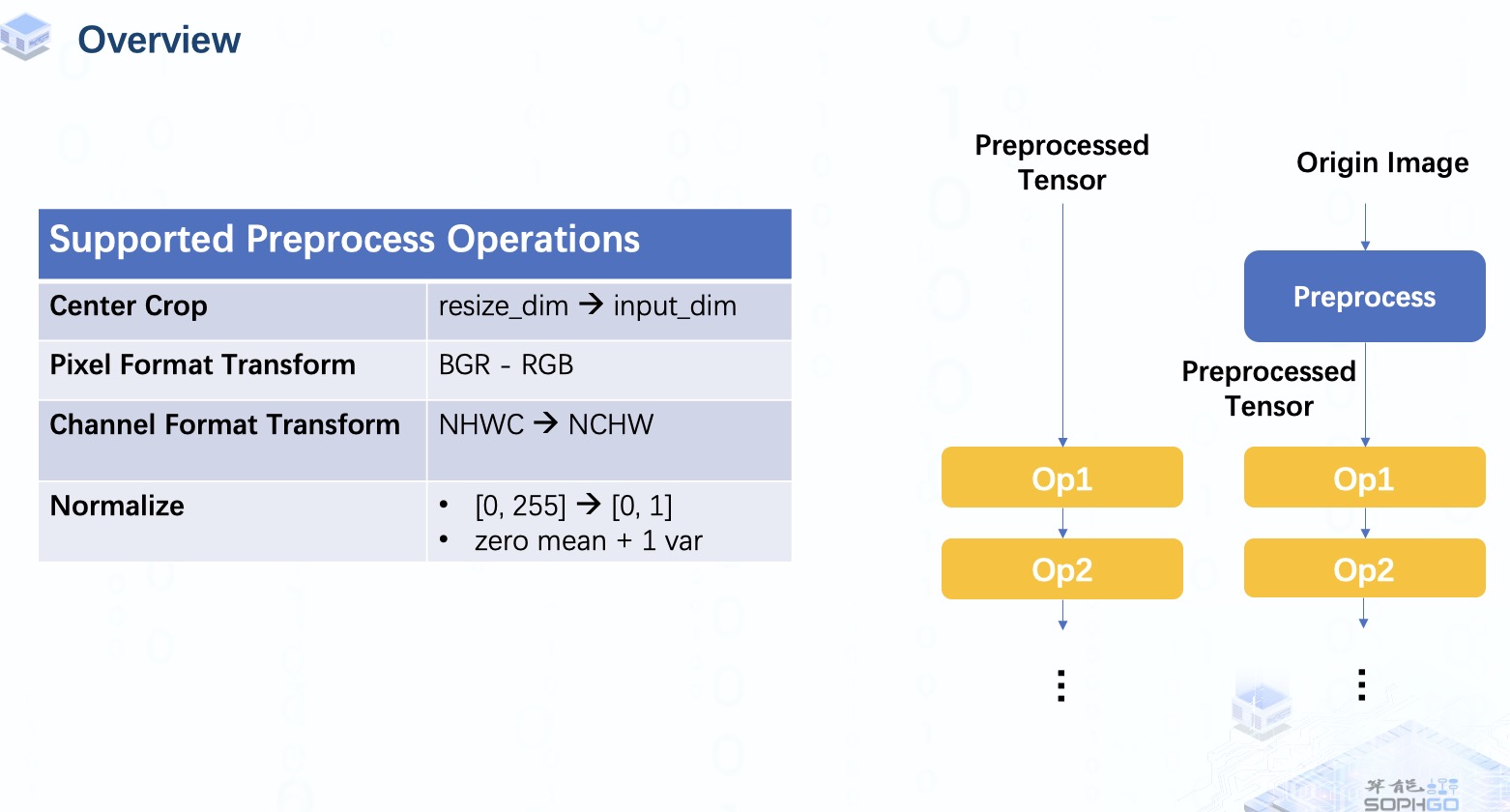
那么,我们怎样才能得到一个包含预处理操作的bmodel呢?
首先,我们像往常一样进行 model_transform 以获得Top层的mlir 文件。但是在 model_deploy 步骤中,我们需要指定 fuse-preprocess 参数。 一旦指定了这个参数,test_input 应该是一个图像而不是 numpy 数组。对于自定义格式,如果不指定,它会被默认设置为和preprocesse infor一致。
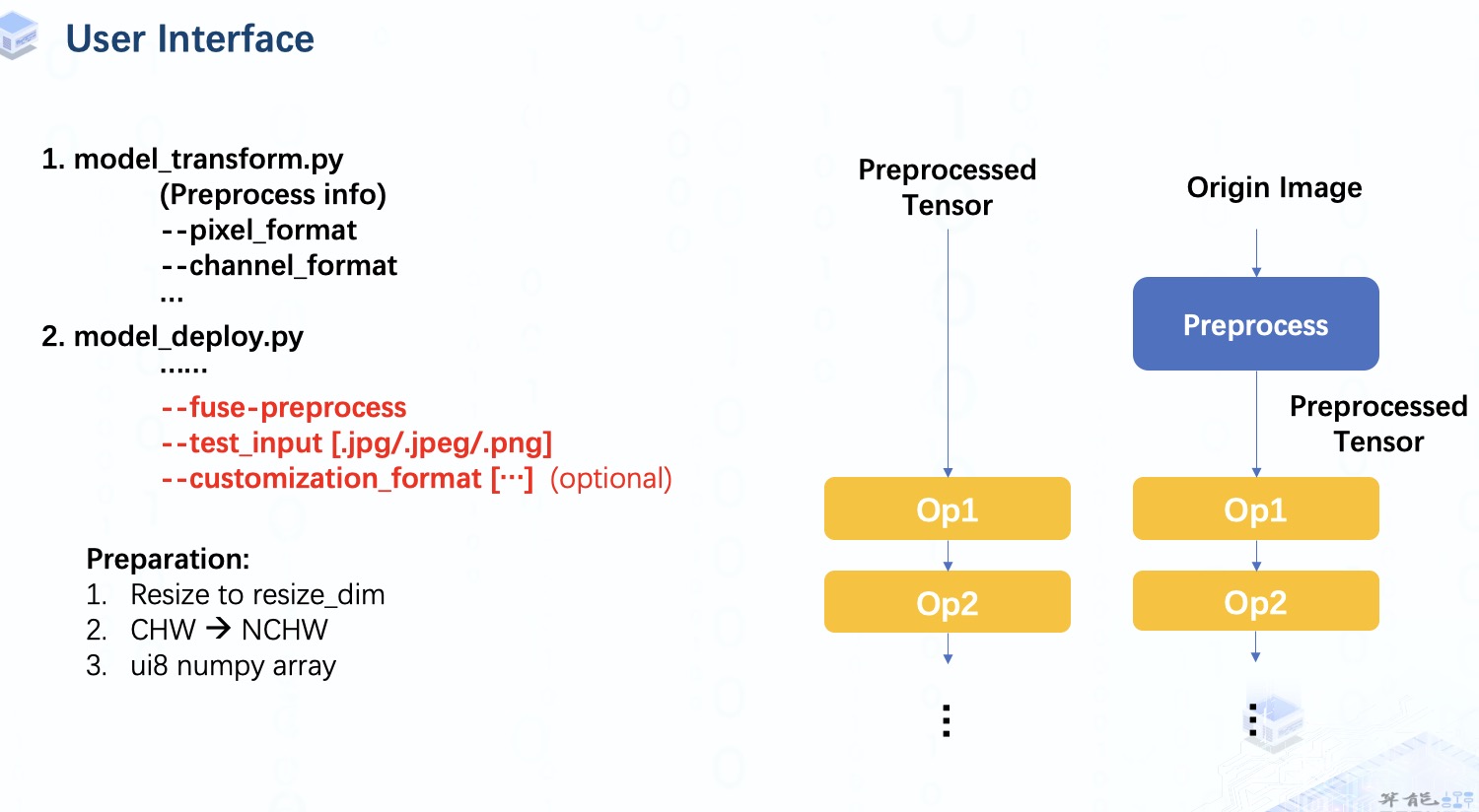
在我们将它提供给模型之前,我们仍然需要对图像数据做一些工作,包括:
调整图像到指定尺寸。
将数据扩展为4维。
并转换为ui8 numpy 数组。这里数据格式是 unsinged int8,因为像素值范围是0到255的整数值。
通过运行带有 fuse-preprocess 参数的 model_deploy 接口,TPU-MLIR 将从 inputOp 收集所有必要的预处理和校准信息,然后将它们保存在 InputOp 之后的 preprocessOp 中。
如果没有提供校准表,这意味着我们得到一个不需要任何校准信息的纯浮点型bmodel,在这种情况下我们实际上也不需要任何校准信息。
接下来,我们会对InputOp进行修改,特别是Type,由于模型的输入是unsigned INT8张量,所以我们需要将其设置为ui8的均匀量化类型。 您会发现量化参数只是单纯设置为 1,因为我们将真实的校准信息保存在preprocessOp中了。接着,func type也要修改,以保证其和inputOp的Type一致。完成所有这些工作后,该模型的输入现在已修改为图像。

这里我们便可以开始lower到 Tpu Dialect。
在这个阶段,如果我们处于F32等浮点量化模式,在 InputOp 之后会插入一个 CastOp,将数据从整数转换为浮点数,以确保类型的一致性。由于 inputOp 的量化参数已经被设置为 1。对于 f32,我们就相当于只是单纯进行类型转换。
接下来,我们将开始插入算子,首先在模型中设置插入点,然后在输入图像为NHWC格式时插入permuteOp。当resize_dim与模型输入形状不同时,SliceOp 会被用来进行裁剪的工作。
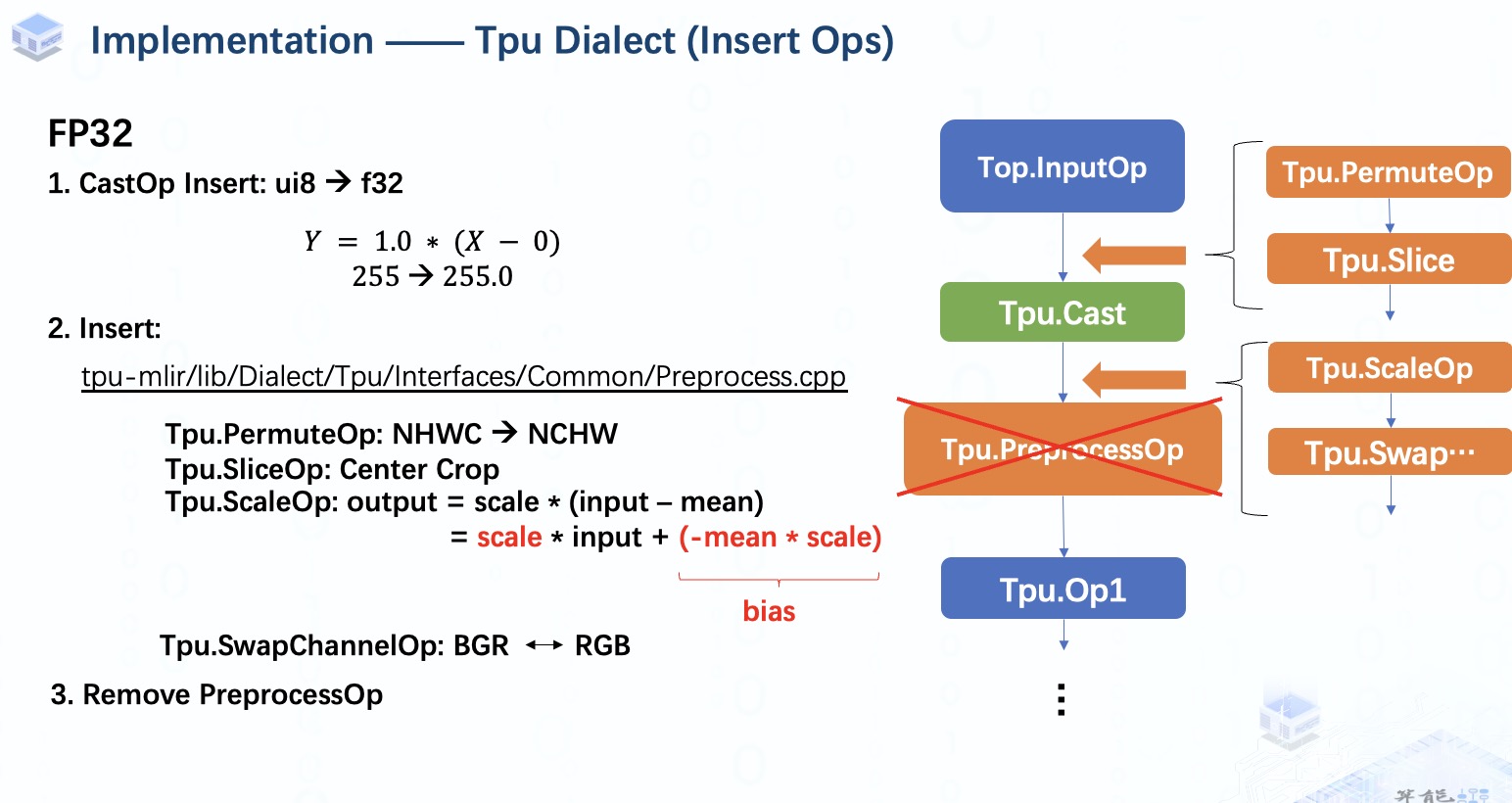
之后我们会在CastOp后设置一个新的插入点,ScaleOp在这里会被用来完成归一化操作。然后,我们还将添加 swapChannelOp 以进行 RGB 和 BGR之间的转换。完成所有算子插入工作后,我们将删除 preprocessOp,它就像一个占位符一样,利用完后就该跟它说再见了。
但是预处理融合工作还没有完成,这里我们还可以做一些优化。
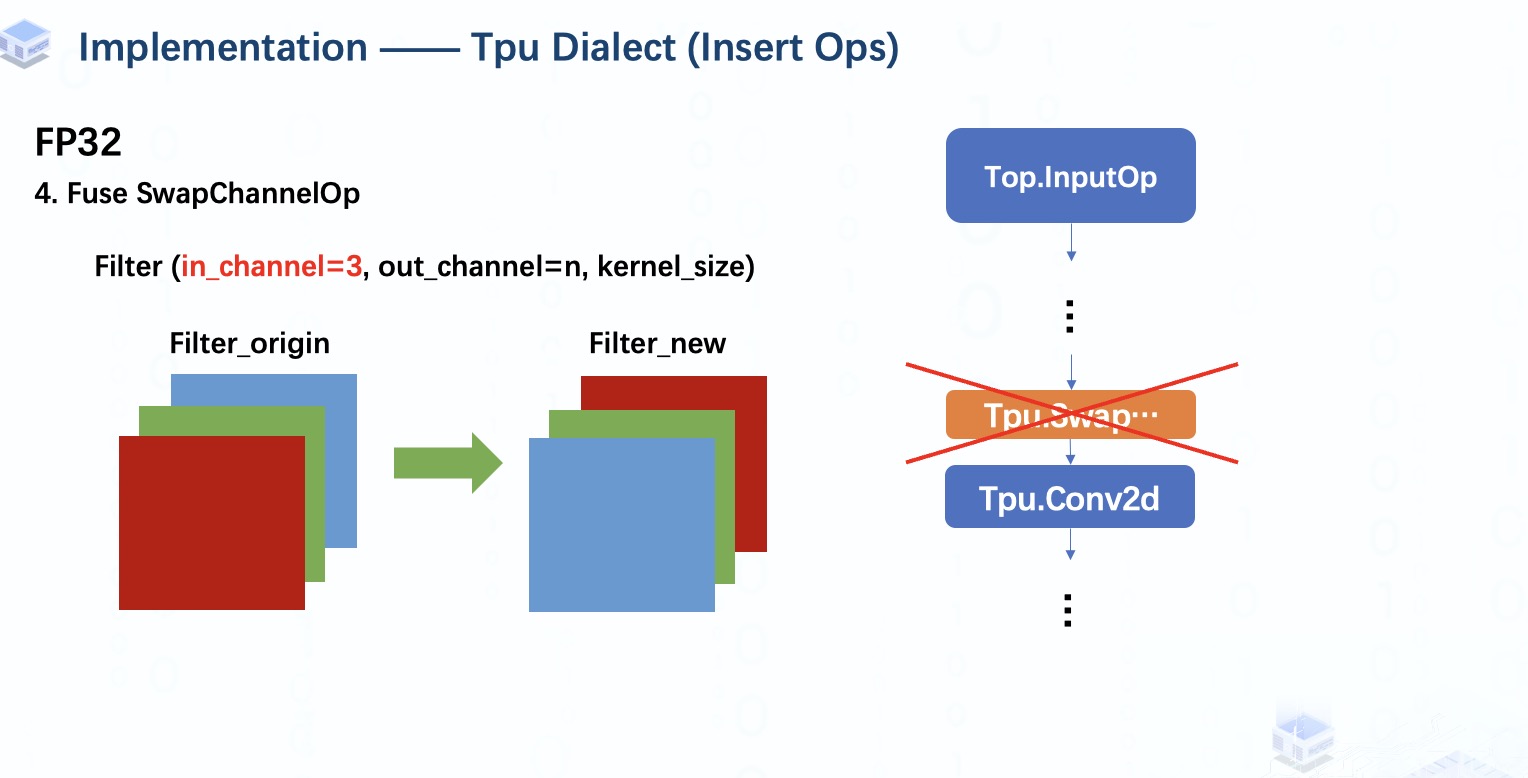
如果模型原本的第一个算子是Conv2d,那么其filter的输入通道一定是3,对应输入图像数据的3个颜色通道。
所以我们可以通过简单地转换filter的输入通道来替换swapChannelOp。至此,预处理工作结束。
在INT8 量化模式下,情况就有点不同了,
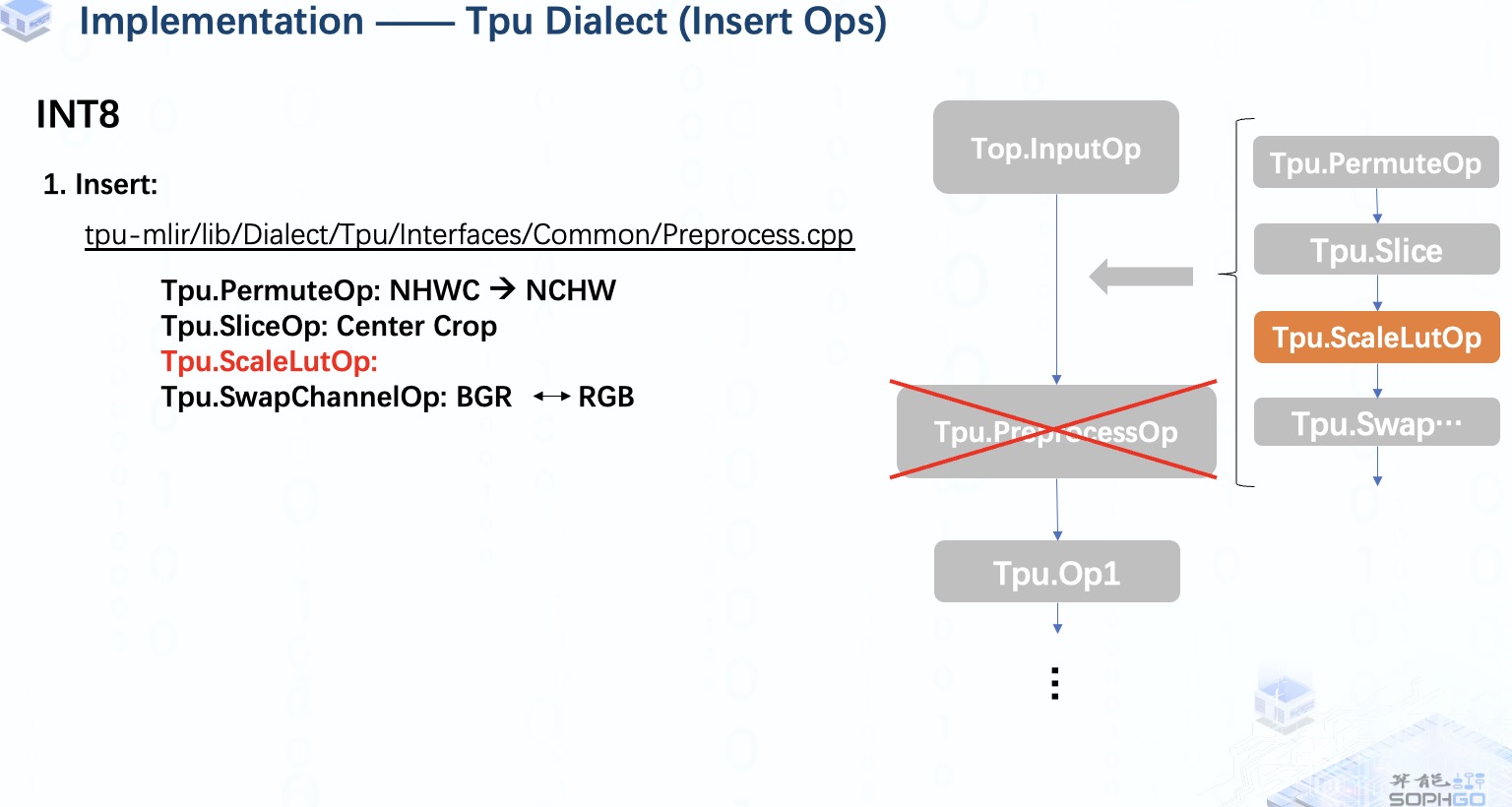
首先,因为所有操作都是int8类型,所以不会有CastOp被插入。
其次,因为我们想对int8数据进行归一化操作,并且结果仍然是 int8,所以我们将插入 scalelutOp 而不是 scaleOp。
ScaleLutOp 就像我们在用查找表的方式进行均匀量化,也就是说我们预先计算出所有 256 个可能的量化结果并保存在表中,然后我们可以在推理时直接从表中得到结果。
但是由于我们有 3 对mean和scale,所以我们必须创建3个表来对每个通道的元素分别进行量化。

需要注意的一点是,当所有均值为零时,我们假设它是unsigned int8量化,否则我们就做signed int8量化。
当然,有时候我们会遇到所有scales_new都等于1,所有means都为0的情况。 在这种情况下,ScalelutOp 实际上对输入数据什么都不做,所以我们将跳过这个插入部分。

另外,在TPU-MLIR中我们也可能会使用mix precision模式,比如在int8量化模式下对原始的首个OP做浮点运算或者在FP量化模式下对原始的首个OP做INT8运算。
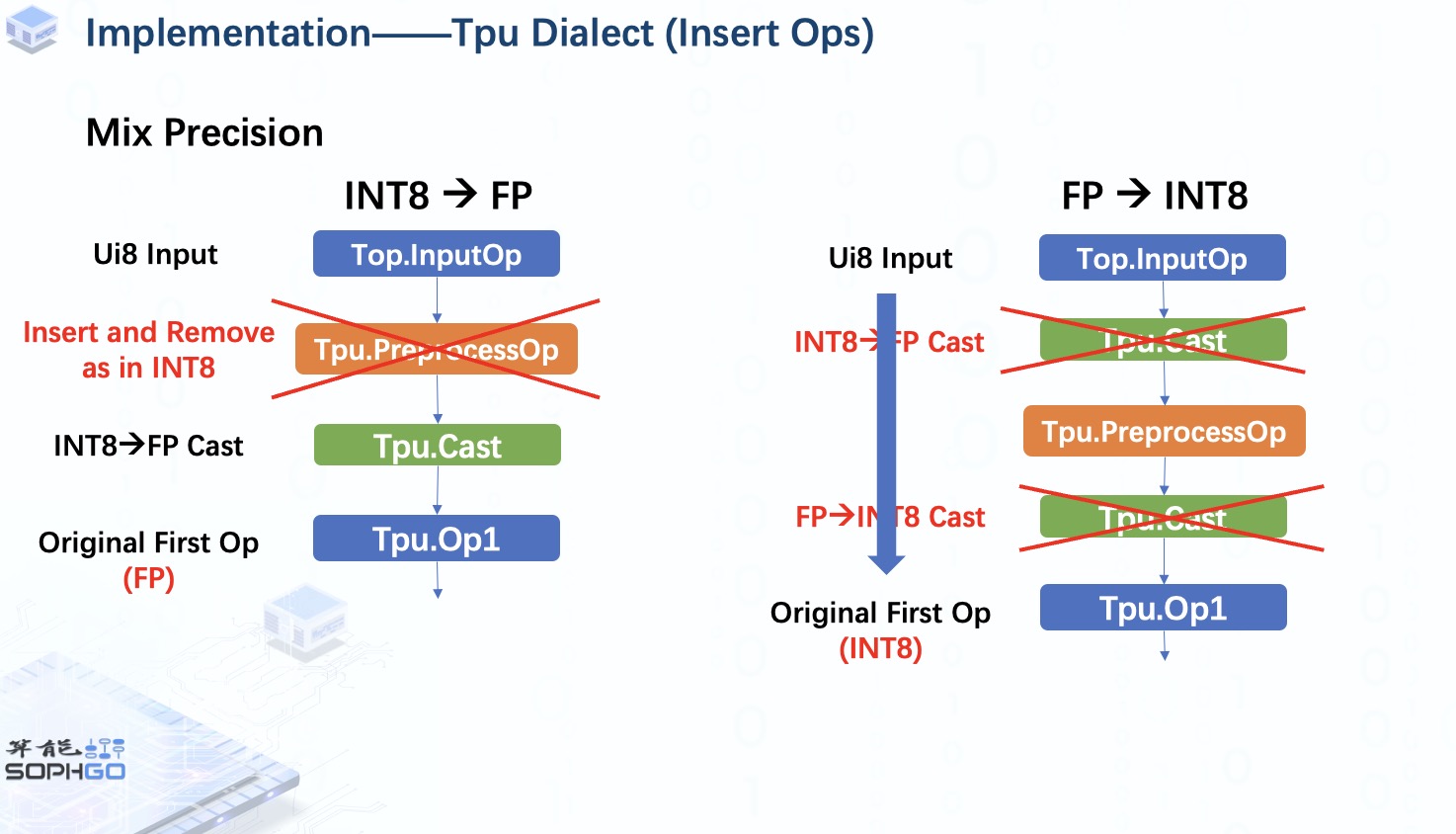
在前者中,将在 preprocessOp 和原始第一个 op 之间插入一个 CastOp,以将 INT8 数据转换为FP,对于这种情况,fuse preprocess步骤将与 int8 量化模式下相同。
但是对于后者,我们可以看到两个CastOp的作用其实相互抵消了,所以我们可以将它们删除并再次像 int8量化模式一样进行fuse preprocess操作。
审核编辑:汤梓红
-
芯片
+关注
关注
455文章
50784浏览量
423450 -
预处理
+关注
关注
0文章
33浏览量
10479 -
TPU
+关注
关注
0文章
141浏览量
20723
发布评论请先 登录
相关推荐
yolov5量化INT8出错怎么处理?
TPU-MLIR开发环境配置时出现的各种问题求解
【算能RADXA微服务器试用体验】+ GPT语音与视觉交互:2,图像识别
TPU透明副牌.TPU副牌料.TPU抽粒厂.TPU塑胶副牌.TPU再生料.TPU低温料
TPU副牌低温料.TPU热熔料.TPU中温料.TPU低温塑胶.TPU低温抽粒.TPU中温塑料
在“model_transform.py”添加参数“--resize_dims 640,640”是否表示tpu会自动resize的?

TPU-MLIR量化敏感层分析,提升模型推理精度

如何适配新架构?TPU-MLIR代码生成CodeGen全解析!
深入学习和掌握TPU硬件架构有困难?TDB助力你快速上手!
如何高效处理LMEM中的数据?这篇文章带你学会!
基于TPU-MLIR:详解EinSum的完整处理过程!





 工商网监
工商网监
评论