 TPU内存(一)
TPU内存(一)

首先我们来看一下TPU的简要架构。
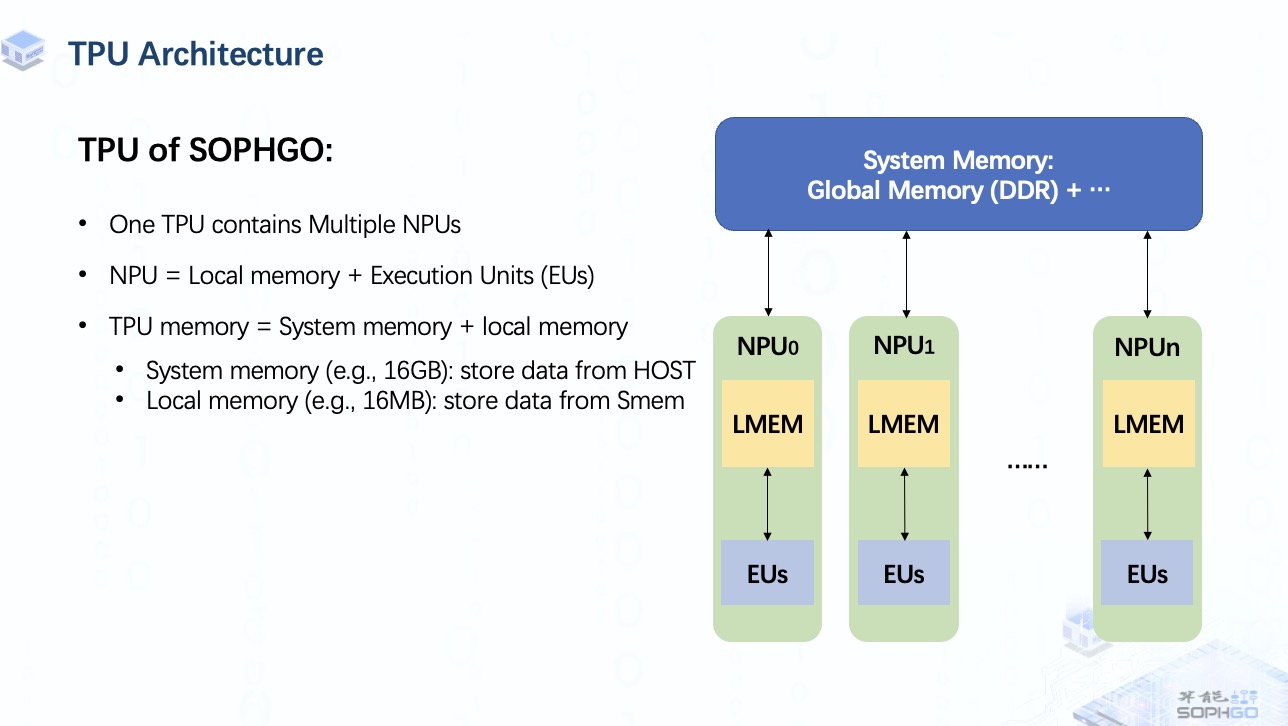
我们可以从ppt中了解到一个TPU中包含多个NPU(Neuron Processing Unit),主要由一个local memory和多个执行单元组成。前者用于存储要运算的数据,后者是TPU上最小的计算单元。每个NPU一次可以驱动它的所有EU做一个MAC操作。
就整体 TPU 内存而言,它由system memory和local memory组成。 system memory的主要部分是global memory,其实就是一块DDR。 有时根据 TPU 的特殊设计还会有其他组件,但我们不会在视频中提及这些部分,所以现在了解global memory就足够了。 而对于local memory,我们暂时只需要知道是一组Static RAM就可以了。 稍后我会进一步解释。
通常global memory很大,用于存储来自host端的整个数据块。
而local memory虽然有限但在计算速度上更有优势。
所以有时候对于一个很大的张量,我们需要把它切分成几个部分,送到local memory中进行计算,然后把结果存回global memory。
为了在 TPU 上执行这些操作,我们就需要用到指令。
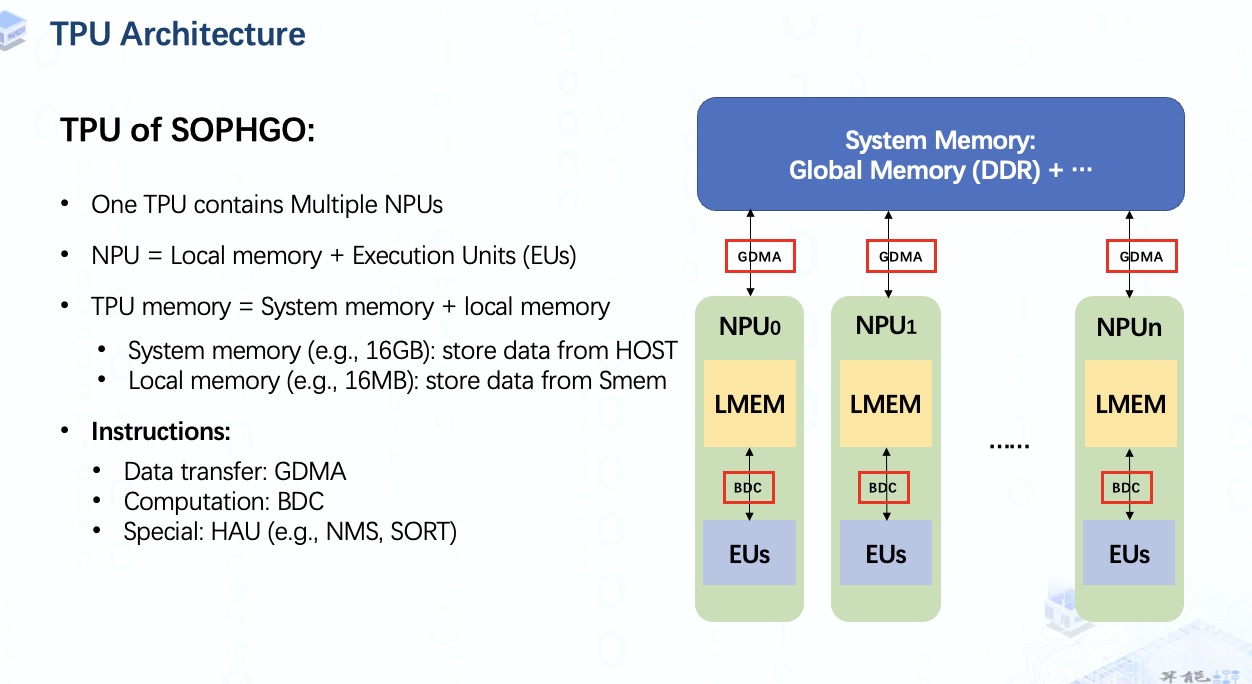
指令主要有两种:
- GDMA用于system memory和local memory间或system memory内的数据传输;
-
BDC用于驱动执行单元在NPU上做计算工作;
另外,对于那些不适合并行加速的计算,比如NMS,SORT,我们还需要HAU指令,但是这意味着我们需要额外的处理器。
对于local memory的构成,它是由多个Static RAM组成的。每个 SRAM 称为一个bank。此外,我们将这些 SRAM 分成多个部分给同样数量的NPU,每个部分称为一个lane。
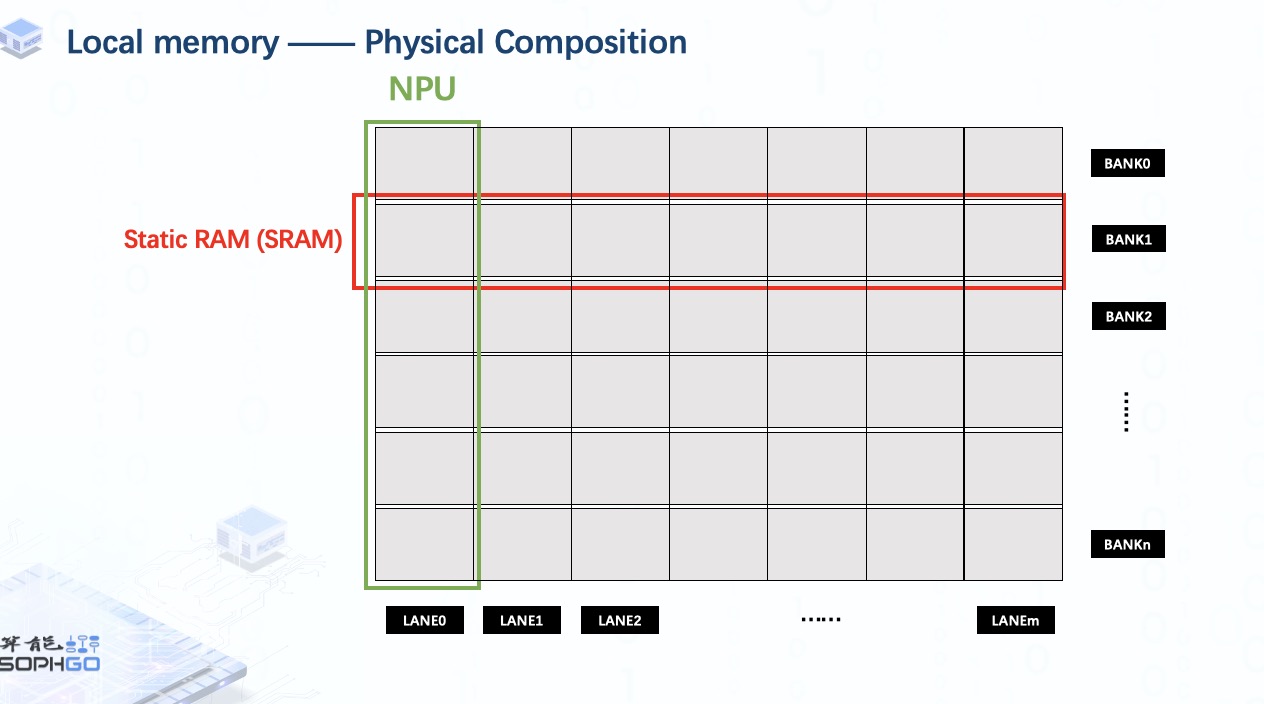
而对于每个NPU,它只能访问属于它的那部分local memory,这使得单个NPU的执行单元只能处理自己local memory上的那部分张量。
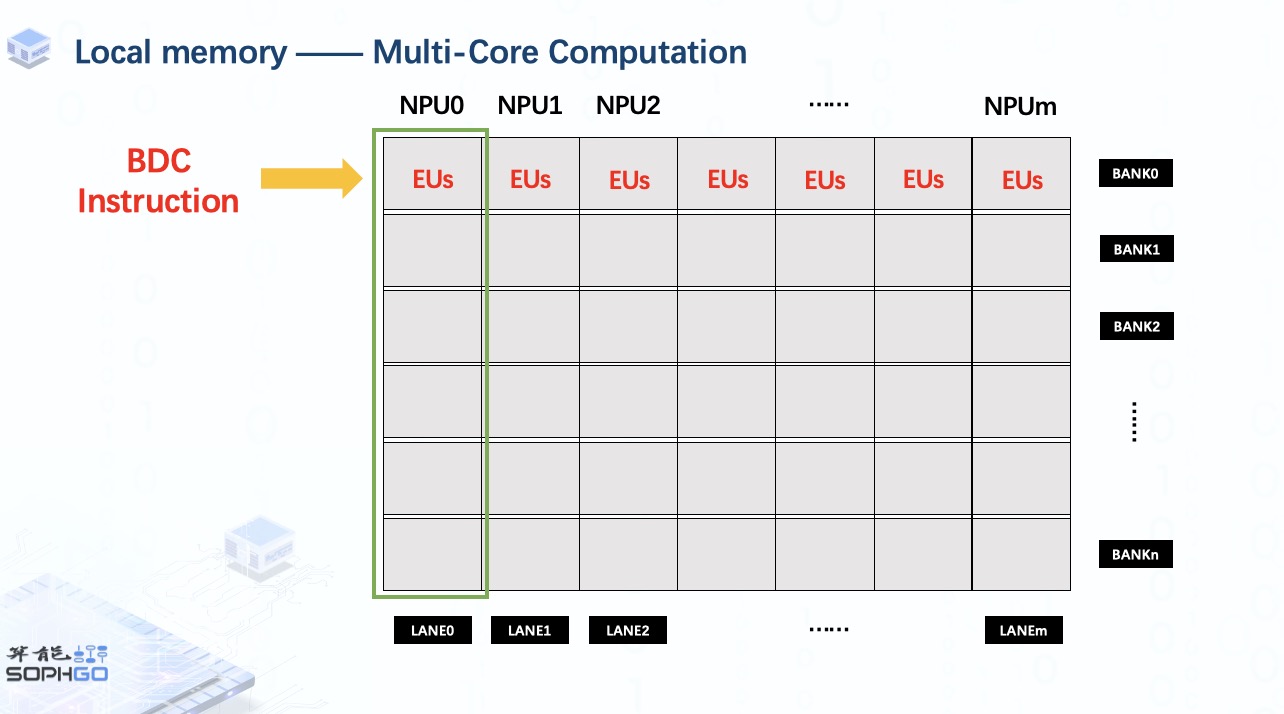
一旦我们调用单个 BDC 指令,所有 NPU 的执行单元将在每个 NPU 的相同位置执行相同的操作。 这就是 TPU 加速运算的方式。
此外,TPU 可以同时处理的数据数量取决于每个 NPU 上的执行单元数量。
对于一个特定的TPU,EU Bytes是固定的,所以对于不同类型的数据,EU的个数会有所不同。
例如当EU Bytes为64时,则表示一个NPU可以同时处理64个int8数据。
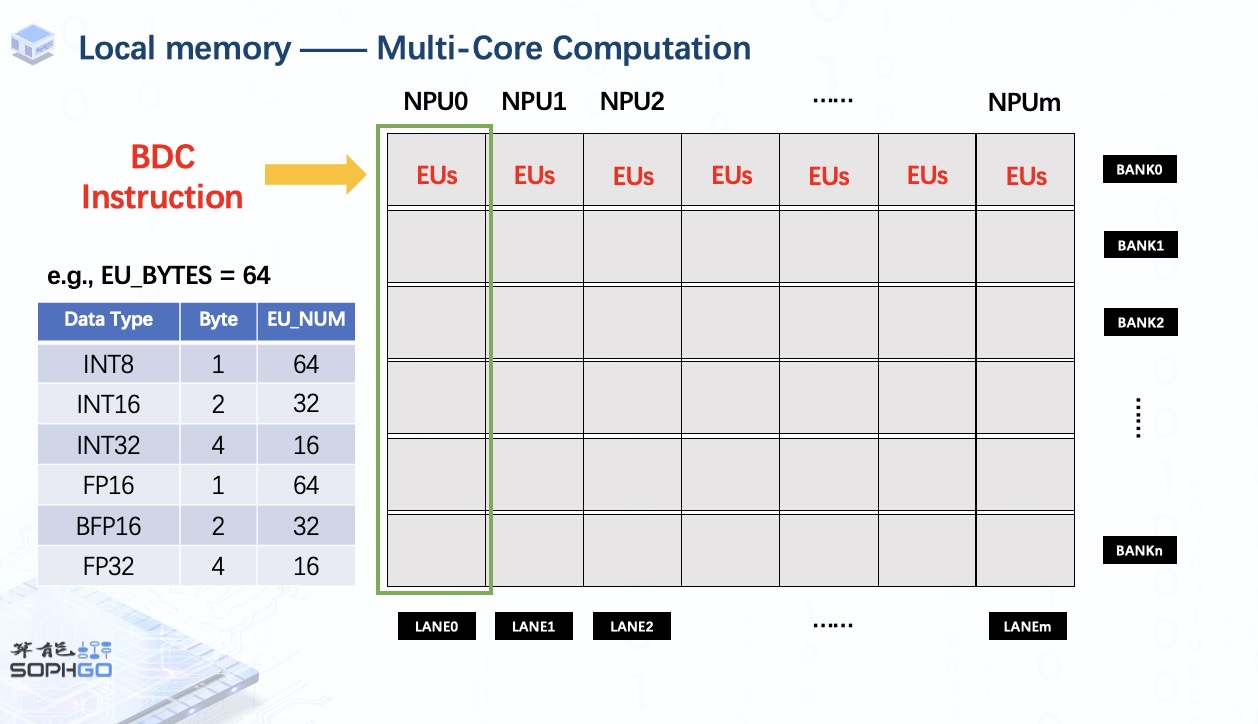
同理,我们可以根据数据的字节计算出对应的EU_NUM。
对于地址分配,假设我们的local memory由16个SRAM组成,总内存为16MB,有64个NPU,那么每个NPU的内存为256KB。

单个通道中每个bank的内存大小则为16KB,相当于16x1024 字节。
所以这个块的地址范围是从0到16x1024 – 1。
同理,NPU0中下个bank的地址从16x1024开始到32x1024-1
按照这个规则,我们就可以得到local memory上的所有地址。
-
DDR
+关注
关注
11文章
761浏览量
69532 -
内存
+关注
关注
9文章
3231浏览量
76497 -
TPU
+关注
关注
0文章
171浏览量
21714
发布评论请先 登录
TPU-MLIR开发环境配置时出现的各种问题求解
CORAL-EDGE-TPU:珊瑚开发板TPU
TPU透明副牌.TPU副牌料.TPU抽粒厂.TPU塑胶副牌.TPU再生料.TPU低温料
TPU副牌低温料.TPU热熔料.TPU中温料.TPU低温塑胶.TPU低温抽粒.TPU中温塑料
供应TPU抽粒工厂.TPU再生工厂.TPU聚醚料.TPU聚酯料.TPU副牌透明.TPU副牌.TPU中低温料
采购TPU复牌料.复牌TPU原料.TPU复牌透明塑料.TPU废边料.TPU废膜料.TPU低温料
如何验证MC68332 TPU配置是否正确?
BM1684中各种内存的概念
tpu是什么材料_tpu硬度范围_tpu的应用
一文了解CPU、GPU和TPU的区别
一文搞懂 CPU、GPU 和 TPU

TPU和NPU的区别
谷歌发布多模态Gemini大模型及新一代TPU系统Cloud TPU v5p



评论