 TPU-MLIR之量化感知训练
TPU-MLIR之量化感知训练
Hello大家好,在之前的视频中我们的讲解主要集中在训练后量化,也就是PTQ,那么这期视频我们就再来讲一下另一种主要的量化类型,量化感知训练,我们暂且不会涉及到QAT在TPU-MLIR中的应用,只是先停留在理论层面进行一个介绍。
我们在学习PTQ的时候知道了量化其实就是一个寻找合适的量化参数,将高位数据流映射为低位数据流的过程,实现模型轻量化并且提高推理效率,但在这个过程中模型的精度不可避免地会下降。
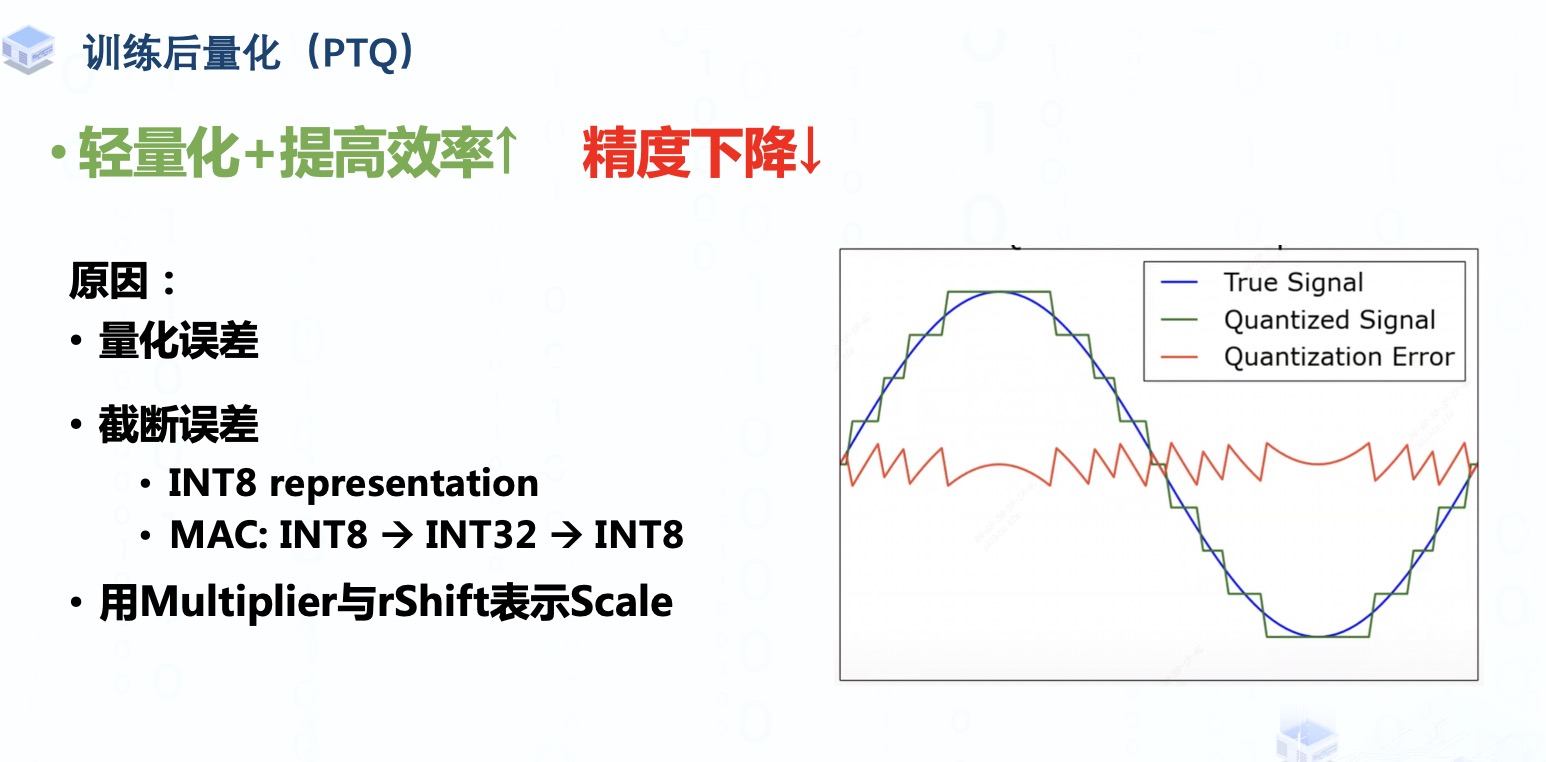
造成精度下降的原因有很多,其中主要有:
量化误差的引入,就像右边这张信号图所示,我们在量化时做的取整操作其实就是用有限的离散取值去近似无限的连续取值,会不可避免的导致量化后的信号与量化前的信号有一定的偏差,当这种偏差越大时量化误差往往也就越大。
而且Weight 与activation tensor用INT8来表示则不可避免地也会出现一定的信息损失,例如我们之前提到的截断误差,并且模型在进行Multiply-Accumulate操作中会采用INT32来接收累加的结果,然后将累加的结果再转换回INT8,这个过程可能也会导致一定的截断误差。上一期视频中我们介绍的校准方法只能在截断误差与量化误差之间做一个权衡,而不能完全消除它们。
还有就是我们量化推导那期视频中提到过的用Multiplier与rShift代替Scale的表示也会产生些许误差
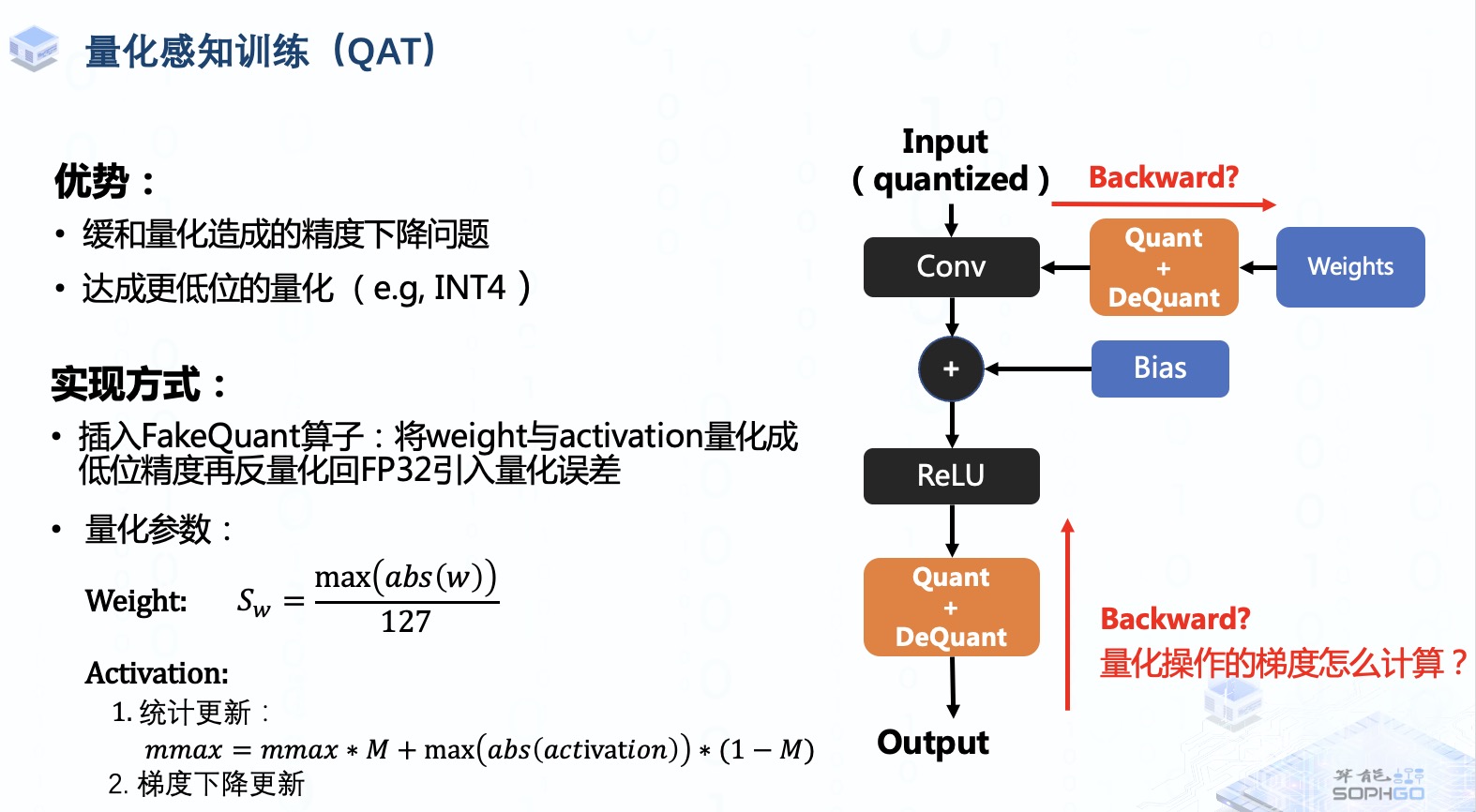
QAT就是通过end-to-end training微调训练后的模型参数,让模型对量化的鲁棒性更强,从而缓和造成的精度下降问题,而且通过QAT,我们也能够达成更低位,例如INT4的量化,从而进一步轻量化模型与提高推理效率
实现方式就是在训练过程中进行模拟量化,或者说是插入FakeQuant伪量化算子,对weight与activation tensor进行量化,然后再做反量化引入量化误差进行训练,所以在fine-tune的过程中模型还是以FP32精度进行运算的,并不是像推理过程中的低位运算。之后我们通过反向传播与梯度下降的方式微调模型权重。
对于量化参数的确定,weight tensor的量化参数通常采用绝对最大值除以127的方式确定,而activation tensor量化参数则根据QAT算法的不同可能也有所不同。早期的QAT算法采用滑动平均的方式在训练过程中对量化取值范围进行统计更新,而近些年来主流的QAT算法直接将量化参数定位可学习参数在反向传播过程中通过梯度下降进行更新。
这样的做法在实际实现过程中我们主要会遇到一个问题,就是伪量化算子中的round函数梯度要怎么计算,我们既然在原模型插入了伪量化算子,又要对模型进行重新训练,就不得不考虑反向传播时怎么计算它的梯度。
首先我们之前有看过量化后的信号波形图其实是一个离散的阶梯函数,这样的函数是不可导的,或者说它们的梯度是处处为0的,这就导致权重无法得到更新。所以我们需要想办法去对它做近似操作。
一种传统的方式是用Straight-Through Estimator在反向传播过程中让伪量化算子输入的梯度等于输出的梯度,或者说使他梯度为1。
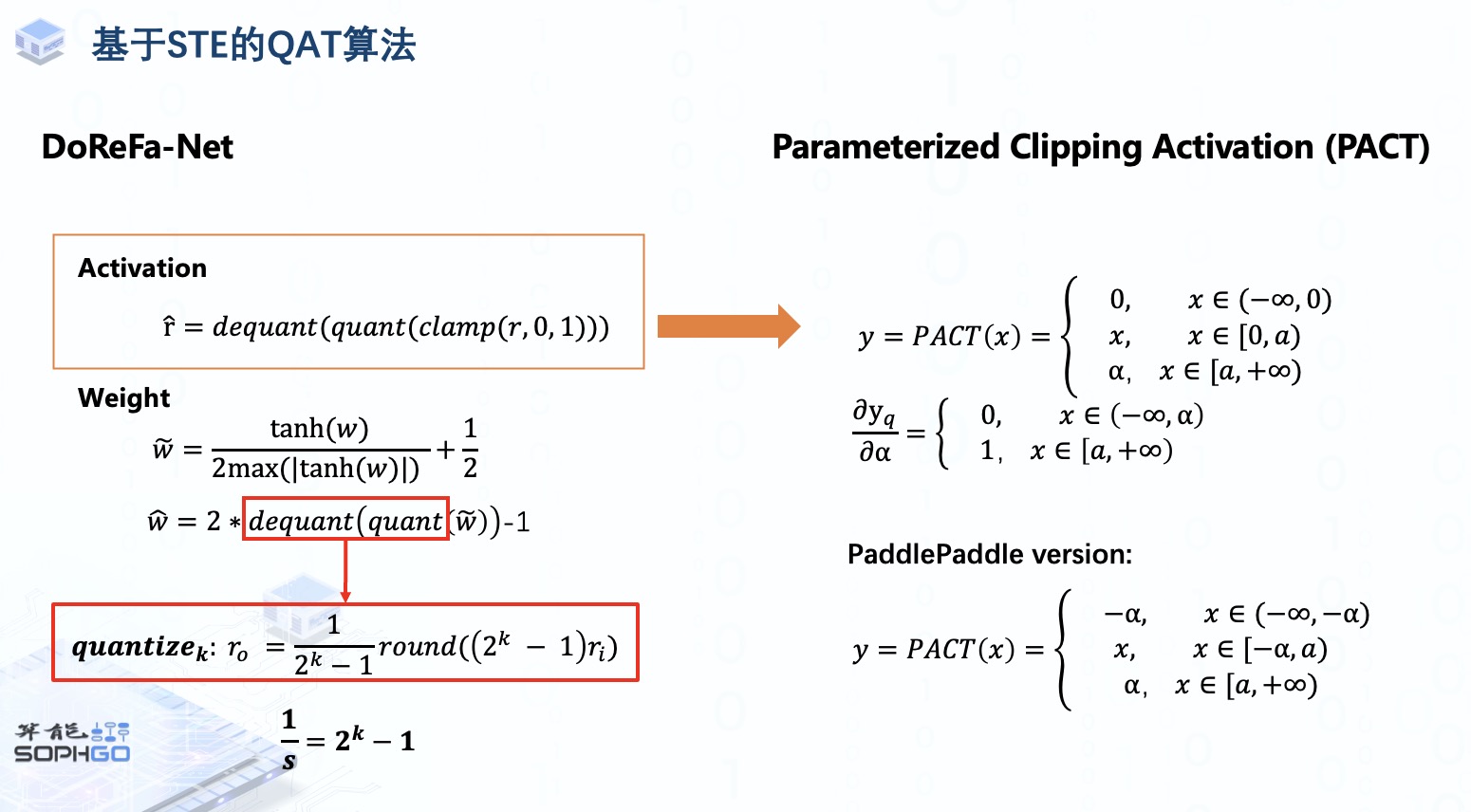
由这种方法延伸出了一系列的QAT算法,例如DoReFaNet,这个算法将activation和weight都压缩在0,1之间进行量化,后面会继续讲解基于STE的QAT算法,敬请期待。
审核编辑:彭菁
-
函数
+关注
关注
3文章
4350浏览量
63141 -
模型
+关注
关注
1文章
3393浏览量
49381 -
数据流
+关注
关注
0文章
122浏览量
14488
发布评论请先 登录
相关推荐
yolov5量化INT8出错怎么处理?
TPU-MLIR开发环境配置时出现的各种问题求解
【算能RADXA微服务器试用体验】+ GPT语音与视觉交互:2,图像识别
YOLOv6中的用Channel-wise Distillation进行的量化感知训练
在“model_transform.py”添加参数“--resize_dims 640,640”是否表示tpu会自动resize的?
Pytorch量化感知训练的详解

TPU-MLIR量化敏感层分析,提升模型推理精度

如何适配新架构?TPU-MLIR代码生成CodeGen全解析!
深入学习和掌握TPU硬件架构有困难?TDB助力你快速上手!
如何高效处理LMEM中的数据?这篇文章带你学会!





 工商网监
工商网监
评论