1. 腾讯云宣布全面支持Llama2等主流开源模型
原文:https://t.cj.sina.com.cn/articles/view/1654203637/629924f5020010xw1?from=tech
腾讯云方面16日宣布,腾讯云TI平台已经全面接入Llama 2、Falcon、Dolly、Vicuna、Bloom、Alpaca等20多个主流模型,这些主流模型支持直接部署调用、应用流程简单、可全程低代码操作。企业、开发者可以根据不同细分场景的业务需求,灵活选择各类大模型,降低大模型使用成本。

据腾讯云公众号透露,腾讯云是国内第一批上架和支持开源模型的大模型厂商,腾讯云持续推动MaaS(Model-as-a-Service)建设,让大模型更懂行业、更易落地。
在具体执行方面,腾讯云发布了行业大模型解决方案,依托腾讯云TI平台打造行业大模型精选商店,提供涵盖模型预训练、模型精调、智能应用开发等一站式行业大模型服务,已为10大行业提供了超50个大模型解决方案。腾讯云还推动大模型时代底层基础设施建设,发力算力、网络、数据“铁三角”,为客户提供HCC高性能计算集群、星脉高性能计算网络以及向量数据库等基础设施服务,加速大模型落地。与此同时,腾讯云积极参与、推动行业大模型标准建设。早在2020年,腾讯就被选举为全国信标委人工智能分委会委员兼副秘书长。前不久,腾讯云联合信通院牵头开展国内首个金融行业大模型标准,助力金融行业智能化的高质量规范化发展。
2. 稚晖君人形机器人问世:大模型加持,会自己换胳膊,要上生产线造车
原文:https://mp.weixin.qq.com/s/cgfbJgl9enzGXGTb6q6FGA
大模型技术的新一波浪潮:具身智能,已经有了重要进展。刚刚,稚晖君的创业公司「智元机器人」开了自己的第一场发布会。

以「天才少年」身份加入华为的稚晖君(彭志辉)于去年底宣布离职创业,人们都在关注他在机器人与大模型方向探索的新实践。今天在上海,他成立的智元机器人终于发布了首款产品「远征 A1」。在现场,机器人走上了讲台,这是稚晖君创业以来交出的第一份答卷。

远征 A1 不仅长得像人,也有着近似人类的一系列数据:它身高 175cm,重 53kg,最高步速达到 7km/h,全身有 49 个自由度,可以承重 80kg,单臂最大负载 5kg。这款机器人在双足行走、智能任务、人机互动等领域展现了业界领先的能力。

稚晖君表示:「远征 A1 是我们的第一台通用型智具身智能机器人,它融合了各种先进的本体控制、感知、认知和决策的智能技术,基于当前 AI 领域前沿的大语言模型,以及我们自研的视觉控制模型,完成了一系列创新。」此前,很多机器人产品大多具备 20 余个自由度。据介绍,远征 A1 的 49 个自由度是考虑到实际应用场景,如汽车生产过程中整理线束、拧螺丝、总装等任务来确定的。它虽然是个人形机器人,但从一开始就面向工业制造:
未来也可以成为人们日常生活的助手:
「远征 A1」是模块化的,可以面向不同任务,自己给自己换组件:

稚晖君表示,把机器人做得像人,是因为现在的世界一直是为人形态而设计的,人形机器人可以在大量工作中直接应用现有工具、任务和场景,同时更具有亲和力。但想让机器人模仿人类,需要在机械设计、运动和感知等方面解决很多挑战。
自研电机,模块化设计
用两条腿来走路,又能够拥有生产力,这意味着硬件设计要有强大的能力。智元机器人构建了一套自研的硬件系统,包括关节电机、灵巧手等。如果从零部件算,整个机器人的国产化率在 80% 以上。
自研核心关节电机 PowerFlow
如果想让人形机器人行动灵敏、准确,它的关节需要满足很多条件,比如体积小、重量轻、功率密度高、能量利用效率高、响应带宽高、耐冲击等等。其中,核心关节不仅是让人形机器人更加灵活、更加自由的关键,也是未来实现规模量产、低成本制造的重要门槛之一,稚晖君在现场解释说。为了实现这些目标,智元团队自研、设计了一款专用关节 ——PowerFlow。这个关节采用了准直驱的方案,它的优点是功率高、不需要传感器(可以用电机电流判断力矩),通过电流直接做力矩控制,价格低。为了增加功率密度,远征 A1 的关节模组还集成了液冷循环散热系统。搭配上自研的一体化矢量驱动控制器,整个关节的峰值扭矩可以达到 350Nm。不过,稚晖君表示,他们还没有测到扭矩的真正上限,估计潜力比想象中高。而且,由于水冷散热的加持,它可以保持更长时间的峰值扭距输出,而重量仅为 1.6 公斤。

这个关节还有个非常有意思的设计,它让机器人的膝关节向后弯曲,而不是和人一样向前。稚晖君解释说,这是为了让机器人干活更加方便,毕竟再好的人造关节也不可能让机器人像人一样那么灵活,反屈膝关节的设计可以让它拥有更大的操作空间。

自研灵巧手 SkillHand
要想让机器人更好地干活,手是另外一个关键部件,因此智元研发了灵巧手 SkillHand。这个灵巧手有 12 个主动自由度、5 个被动自由度,而且所有驱动都是内置的。考虑到这个灵巧手未来将面对精密制造场景,智元在它的指尖安装了一些传感器。其中,视觉传感器可以分辨操作物的颜色、材质。基于各种算法的数据融合,指尖还可以做到近似的触觉压力传感器效果。由于这些传感器可以帮助机器人实现末端的视觉闭环,整机的电机精度需求得以降低。有意思的是,如果场景需要,这个机器人其实可以自主更换灵巧手,比如把手换成螺丝刀。稚晖君说,这是模块化设计思想在他们机器人中的体现。类似的模块化设计还可以让机器人由腿式变成轮式,「这是它通用性的一个体现」。

全套 AI 框架
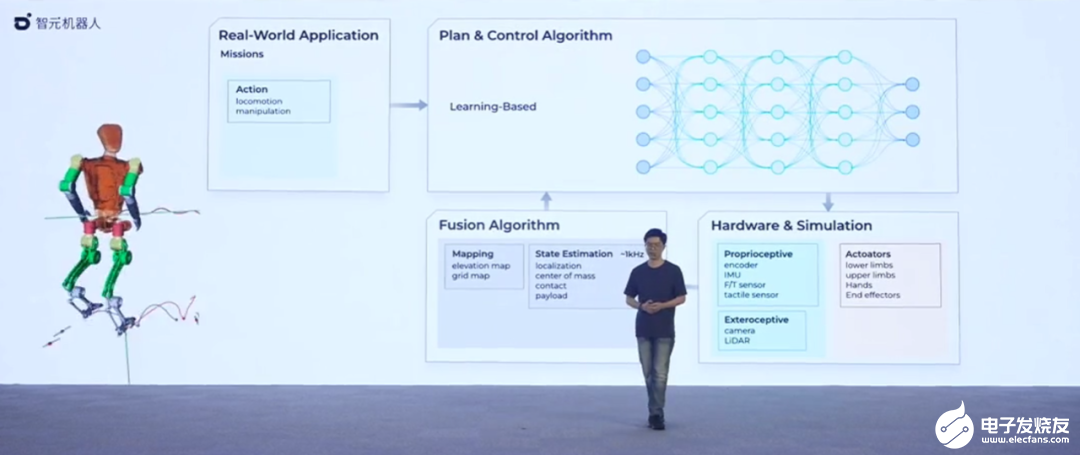
如何让通用机器人实现低成本量产,产生实际应用价值?稚晖君表示,硬件只是前提条件之一,更重要的其实是背后的机器人大脑。在当前的具身智能领域,很多研究都在尝试将大模型作为机器人的大脑,稚晖君也不例外,他也想用多模态大模型的能力赋能智元机器人的行为动作编排。在智元机器人上个月发布的一个视频中,我们已经看到了这个想法的初步实现,比如给出自然语言指令「把离你最近的木块放到紫色的方块右边 3 厘米」,机器人就会按照指示行动。
稚晖君把这个机器人背后的大模型叫做 WorkGPT,这是一个百亿级参数的大模型。
 在稚晖君看来,语言和图像大模型对于机器人领域应用最大的价值在于两个方面,一是庞大的先验知识库和强大的通识理解能力,比如你不用告诉它什么是垃圾,它就能自己分辨出来;二是复杂的语义多级推理能力,即所谓的「思维链」,这体现在它可以把复杂的指令分成一个一个的步骤。「在大模型时代到来之前,机器人都是专用设备,我们需要针对性地对每一个任务进行调试和部署。现在利用大模型的各种通识能力和举一反三的推理能力,我们可以看到解决这些问题,然后最终走向通用机器人的一道曙光。」稚晖君说。所以,在智元,他们打造了一个名为 EI-Brain 的具身智脑框架。在框架中,机器人系统被分为不同层级,包括部署在云端的超脑,部署在端侧的大脑、小脑以及脑干,分别对应机器人任务不同级别的技能,包括技能级、指令级、伺服级等。具体来说,「大脑」负责跟我们人类一样进行抽象思考、多级推理,「小脑」负责运动控制方面的一些指令生成,「脑干」负责电机控制、伺服等硬件底层任务。
在稚晖君看来,语言和图像大模型对于机器人领域应用最大的价值在于两个方面,一是庞大的先验知识库和强大的通识理解能力,比如你不用告诉它什么是垃圾,它就能自己分辨出来;二是复杂的语义多级推理能力,即所谓的「思维链」,这体现在它可以把复杂的指令分成一个一个的步骤。「在大模型时代到来之前,机器人都是专用设备,我们需要针对性地对每一个任务进行调试和部署。现在利用大模型的各种通识能力和举一反三的推理能力,我们可以看到解决这些问题,然后最终走向通用机器人的一道曙光。」稚晖君说。所以,在智元,他们打造了一个名为 EI-Brain 的具身智脑框架。在框架中,机器人系统被分为不同层级,包括部署在云端的超脑,部署在端侧的大脑、小脑以及脑干,分别对应机器人任务不同级别的技能,包括技能级、指令级、伺服级等。具体来说,「大脑」负责跟我们人类一样进行抽象思考、多级推理,「小脑」负责运动控制方面的一些指令生成,「脑干」负责电机控制、伺服等硬件底层任务。

如果端侧模型泛化能力不够,系统可以去连接云端,实现更复杂的任务调度;另一方面,偏向于硬件底层的电机控制等工作都在本地甚至模块中完成。「这类似于自动驾驶上 L1 到 L5 的不同分级 —— 想要构建全场景通用的智能机器人,存在不同的发展阶段,」稚晖君表示。「我们定义了一系列 Meta skill,在语言操作库范围限定的有限泛化的场景内,机器人可以实现自主的推理决策,然后完成端到端的任务编排。随着能力库不断扩充,机器人能够胜任的任务空间也将指数级增长,最终可以实现全场景的覆盖,切入千行百业。这体现了具身智能在交互和学习中进化成长的逻辑。」为了让这些层级起作用,智元不止在大模型方面展开了探索,还迭代了其他方面的算法。比如,在运动控制算法方面,他们在几个月的时间里进行了多次迭代,一直迭代到最近使用的非线性的 NMPC,以及目前正在开发中的基于各种 learning (比如强化学习)的方法。
同时,他们也在搭建一个用于离线轨迹优化的动作库平台。

未来,他们还将建立一个开放平台,为开发者提供持续的技术支持、资金奖励以及合作的机会,而且鼓励开发者基于智元的机器人平台去开发各种创新的应用功能和解决方案。未来,这个开放平台会包含整个机器人的开发套件,包括 HDK、SDK、基于中间件 AGi ROS 的仿真平台,以及一些基础的预训练大模型等等。同时他们也会去考虑推出一个低成本的教育版的硬件,供大家去进行二次开发。

未来要卖 20 万以内
公司成立半年不到就发布第一款样机,还具备完整的体系,让人们不由得感叹现在 AI 领域创业公司速度之快。更重要的是,智元机器人并不是一味在追求前沿技术探索,而是「所有产品都在为商业落地服务」。发布会上稚晖君表示,希望能把整机成本控制在 20 万元以内,使其具备落地的条件,并计划在远征 A1 发布后,以此为基础马上推出第一代商用产品。商业化也已经有了相对具体的方向:基于当前的人形机器人技术,公司已在与国内新能源头部车企商讨合作。希望在汽车制造总装线、分装线等场景上进行商用化落地的尝试,另外也在和 3C 制造的大厂研究合作。智元机器人还计划在未来几年里把人形机器人推广到更多领域。在消费级市场,人形机器人预计可适用的方式包含烹饪、家政、家庭护理、康复训练等。智元机器人(AGIBOT)成立于 2023 年 2 月,目前融资已经完成了四轮,投资方包括高领、百度等风投机构。说到公司未来的发展,智元计划逐步开放开发平台,在未来以每年一代的速度迭代新的样机产品,并不断进行商用验证。稚晖君也表示,为了支持计划,公司即将开启秋招。 智元机器人投身的具身智能当前是一个热门领域。谷歌、斯坦福、英伟达等国际科技机构都在这方面展开了研究,并在近期展示了他们的具身智能机器人成果。今年 3 月份,一家名为 1X 的具身智能机器人公司还拿到了 OpenAI 的投资。随着稚晖君等国内外优秀人才的快速进场,或许我们很快就能看到行业内出现颠覆性的应用。「我的梦想是有一天能够真正造出科幻电影中的智能机器人,它不再是简单的机械装置,而是拥有自主思考和学习能力的智能伙伴,能够感知、理解我们的世界,并与我们深入沟通,」稚晖君说道。「远征 A1 的发布,只是我们追求的起点。」
智元机器人投身的具身智能当前是一个热门领域。谷歌、斯坦福、英伟达等国际科技机构都在这方面展开了研究,并在近期展示了他们的具身智能机器人成果。今年 3 月份,一家名为 1X 的具身智能机器人公司还拿到了 OpenAI 的投资。随着稚晖君等国内外优秀人才的快速进场,或许我们很快就能看到行业内出现颠覆性的应用。「我的梦想是有一天能够真正造出科幻电影中的智能机器人,它不再是简单的机械装置,而是拥有自主思考和学习能力的智能伙伴,能够感知、理解我们的世界,并与我们深入沟通,」稚晖君说道。「远征 A1 的发布,只是我们追求的起点。」
3. 钉钉个人版开放内测:无打卡、无已读 提供一站式AI服务
原文:https://news.mydrivers.com/1/929/929366.htm
快科技8月16日消息,根据钉钉官网显示,全新的钉钉个人版已经正式启动内测,所有用户都可在官网申请加入内测。据了解,钉钉个人版,主要面向小团队、个人用户、高校大学生等人群,旨在探索每个个体、每个团队的数字生产力工具,让智能化变革普惠每一个个体,AI人人可用。
加入内测后,用户可抢先体验各类AI服务,目前文生文、文生图、角色化对话以及AI创作等服务均限时免费。值得一提的是,钉钉个人版并没有常规的打卡和消息已读显示功能,对个人用户来说更加友好。

内测版本仅有空间、AI、云盘、会议4项功能,产品将以AI为核心,用户可一站获取类似ChatGPT、Midjourney、Notion AI等各类大模型能力,并提供“贾维斯”文生文 AI 和“缪斯”文生图 AI。钉钉个人版负责人表示,除了支持升级会员版本提高功能权益外,钉钉个人版在商业化设计方面,也将率先推出“算粒”这一AI服务的计量单位,用户使用 AI 问答、AI 图片将会消耗不同数量的算粒,消耗完之后将只能使用免费的限额次数,或者增购算粒。
4. GPT-4数学再提30分,代码解析器任督二脉被打开,网友:像大脑的工作方式
原文:https://www.thepaper.cn/newsDetail_forward_24270135
GPT-4数学能力还能更强!新研究发现GPT-4代码解释器做题准确率与其使用代码的频率有关。为此,研究人员提出新方法对症下药,直接将其数学能力拔至新SOTA:在MATH数据集上,做题准确率从53.9%增加到了84.3%。
你没听错,就是前段时间被称为ChatGPT推出后最强模式的那个代码解析器(Code Interpreter)。研究人员窥探了其代码生成和执行机制,使用自我验证、验证引导加权多数投票的方法,直接打开其做数学题的任督二脉。好奇网友随即而来:还想看他们做高数。

还有网友认为:这也就是大脑的工作方式,人类在解决数学问题时也会自我验证。

一起来康康这项研究的细节~两步提升数学能力GPT-4代码解析器的代码生成和执行机制究竟是怎样的?来自港中文MMLab、南京大学、中科大、清华、城大、长沙理工等多个机构的学者为解开这一问题,使用特定代码约束提示进行了一项试验。

他们设计了3种不同的提示方法,限制GPT-4代码解析器使用代码的频率:Prompt 1:完全不允许使用代码,输出完全依赖自然语言推理,禁止将代码合并到解决方案中。Prompt 2:只允许使用1次代码,也就是在生成解决方案时,只能在单个代码块内使用代码。Basic Prompt:没有限制,GPT-4代码解析器可以进行一系列推理步骤,每个步骤都可由文字+Python代码组成。
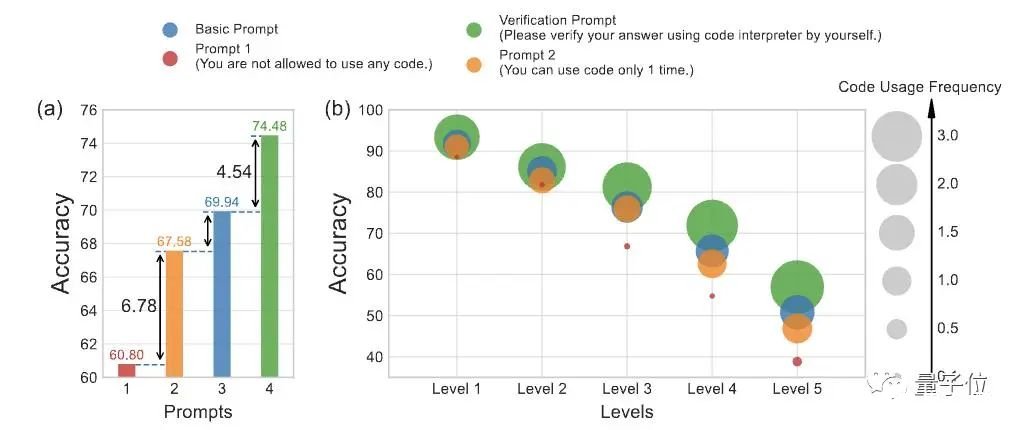
△(a)不同提示回答准确率比较(b)代码使用频率与五个难度级别准确率都成比例,这种现象在数学问题相对复杂时尤为明显。结果发现,允许GPT-4代码解析器多次生成和执行代码,其解题正确度明显高于仅用自然语言推理或只用1次代码的情况。经分析,研究人员认为代码的多次生成和执行可以让GPT-4代码解析器逐步完善解决方案,当代码执行产生错误时,GPT-4代码解析器可以自我调试修改方案。继而引入“代码使用频率”概念,量化不同提示方法下代码的使用次数。基于前面的分析结果,研究人员希望能加强GPT-4代码解析器生成准确代码、评估代码执行结果以及自动调整解决方案的能力。所以提出了CSV(自我验证)提示的方法,也就是为解决方案C引入了一个额外的验证阶段,称为V。加入自我验证提示效果对应上图绿色Verification Prompt。如此一来,GPT-4代码解析器需额外生成代码来验证答案,如果结果是False则重新推理得到正确答案。
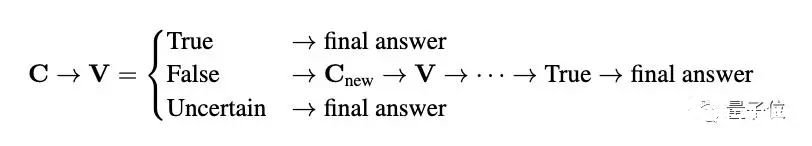
CSV提示不仅对验证到逻辑推理每一步都进行了扩展,而且可以自动更正错误,无需外部模型或人工参与。

△MATH数据集中第712个中级代数问题。CSV prompt:To solve the problem using code interpreter step by step, and please verify your answer using code interpreter.通过上图这个例子可看出,在没有自我验证的情况下,模型生成了一个错误的答案。通过自我验证,模型纠正了错误并生成了正确的答案。此外,鉴于CSV可以有效地验证问题的答案,研究人员又提出了验证引导加权多数投票(VW-voting)的方法,将自我验证结果集成到多数表决中,给予不同验证状态不同权重,使表决更可靠。
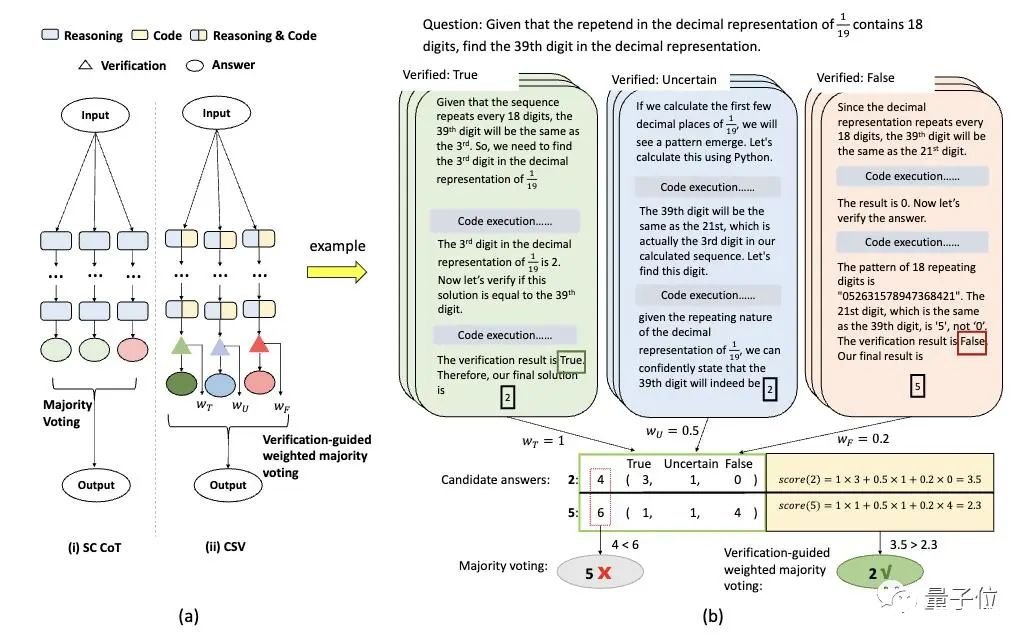
在实际操作中,一旦一个答案被确认为错误,那就不会进行额外的验证,从而得到一个错误的验证状态。研究人员分配相应的权重给这些状态:真实(wT)、不确定(wU)和错误(wF)。
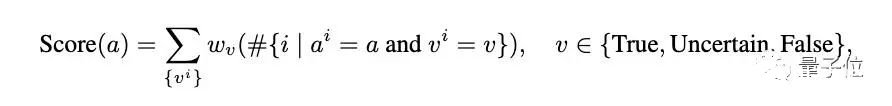
最后从候选答案中择取得分最高的那一个:
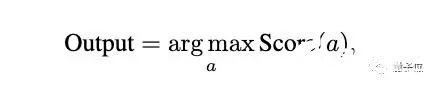
比此前最高水平提高30%用上了上述方法,GPT-4代码解析器做数学题的能力up up。在MATH数据集上,原始GPT-4代码解析器的准确率为69.69%,使用CSV提示后提高到73.54%,再结合加权多数表决后进一步提高到84.32%,相比之前SOTA提高了30%以上。
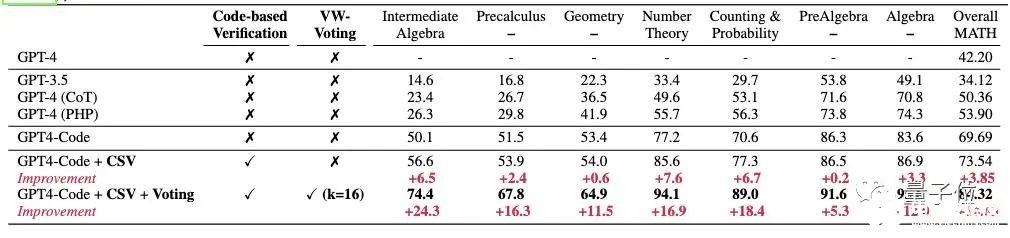
△在MATH数据集上的准确率(%)在MATH数据集的各个子任务中,提出方法均取得显著提高,尤其是在高难度级别的题目中效果更明显。例如在中级代数(Intermediate Algebra)题目中,原来的GPT-4代码解析器准确率为50.1%,使用新方法后提高到74.4%。除此之外,研究人员还在GSM8K、MMLU-Math、MMLU-STEM等数据集上进行了验证。
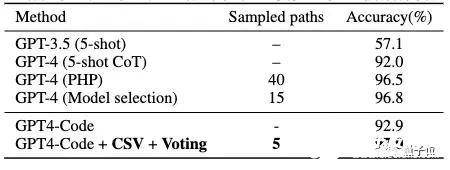
△在GSM8K数据集上的表现上表可以看出,使用验证引导加权多数投票的方法还可以显著减少需要采样的解路径数量(Sampled paths),在GSM8K数据集上只需要5个路径就达到97%的准确率。
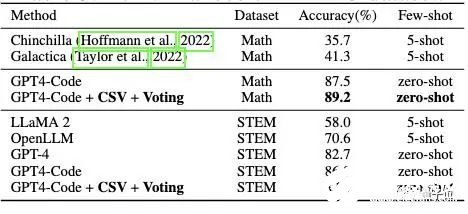
△在MMLU数据集上的表现针对不同难度的题目(下图a)以及不同类型题目(下图b)的测试中,使用新方法后准确率都有了提升。
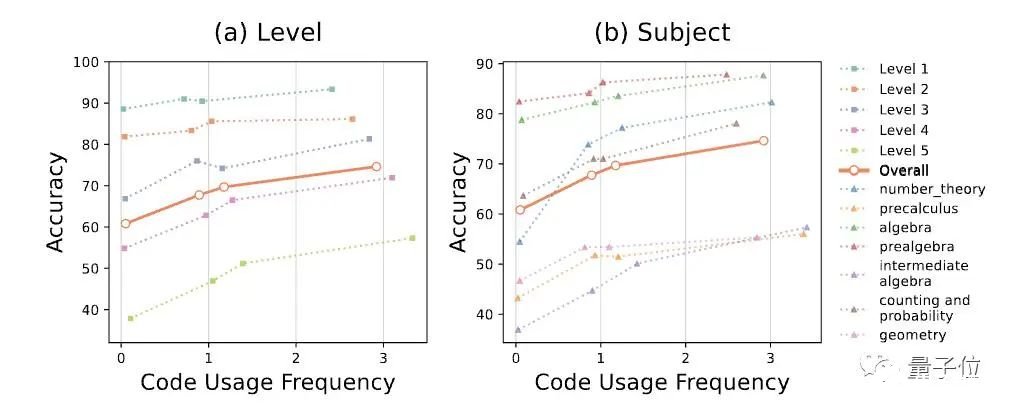
△每条曲线上的四个点分别对应于使用Prompt 1、Prompt 2、BasicPrompt、CSV Prompt得到的结果。研究人员还发现GPT-4代码解析器的代码使用频率提高与准确率提高正相关。随着题目难度的增加,代码使用频率稳步上升。这说明在较难的数学问题上,更频繁地使用代码很重要。此外,值得注意的是,尽管添加基于代码的自我验证可以提高每个单独题目类型的性能,但改进的程度也因题目类型而异,从7.6%到仅0.6%不等。研究人员指出:特别是几何问题的准确性仅提高了0.6%,原本GPT-4代码解析器的准确性也只有54.0%,在各个题目类型中属于较低的。这种差异可能是因为解决几何问题通常需要多模态,超出了本文研究范围。论文传送门:https://arxiv.org/abs/2308.07921参考链接:[1]https://twitter.com/_akhaliq/status/1691734872329699813?s=20[2]https://x.com/justfannet/status/1691983780498600376?s=46&t=iTysI4vQLQqCNJjSmBODPw
5. 数学能力超ChatGPT,70B开源大模型火了:用AI微调AI,微软全华班出品
原文:https://www.thepaper.cn/newsDetail_forward_24224649
用AI生成的指令微调羊驼大模型,数学能力超ChatGPT——微软最新开源大模型WizardMath来了。

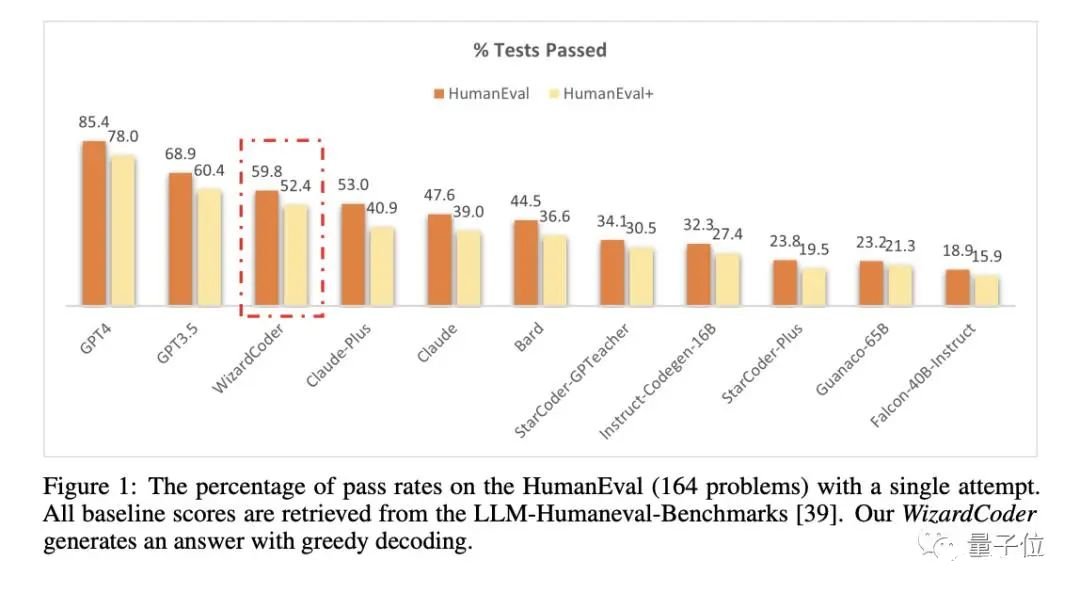
如下图所示,经过GSM8k数据集测试,WizardMath数学能力直接击败了ChatGPT、Claude Instant 1、PaLM 2-540B等一众大模型——并且是在参数只有700亿,远不及后三者的情况之下。
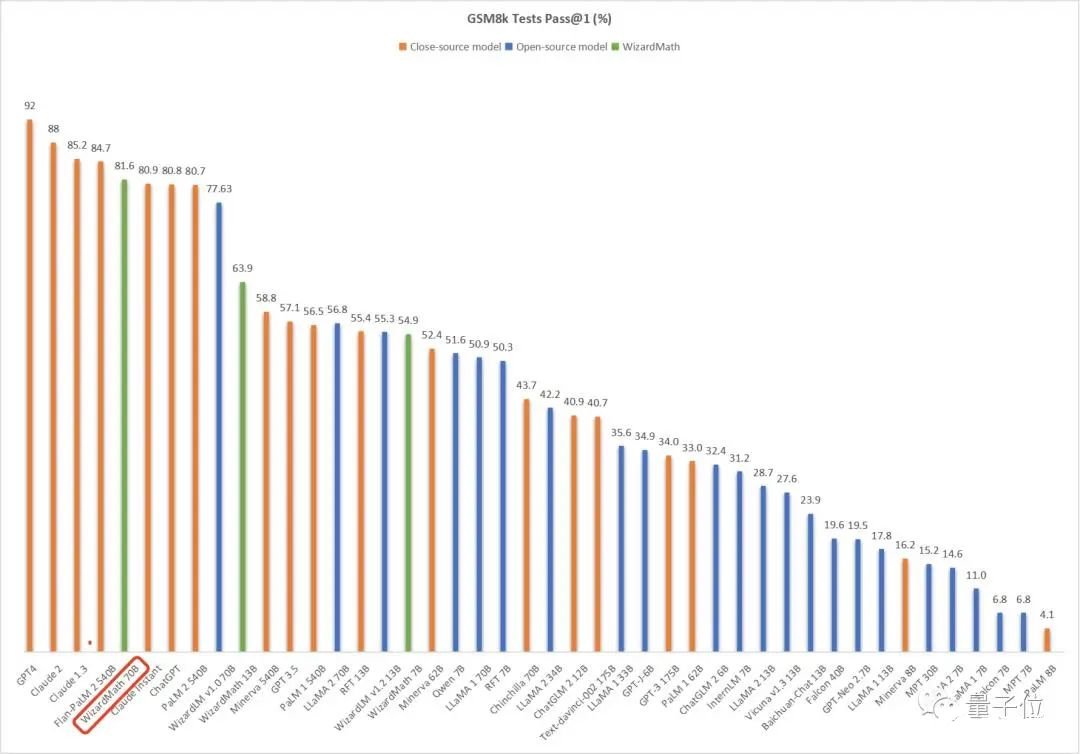
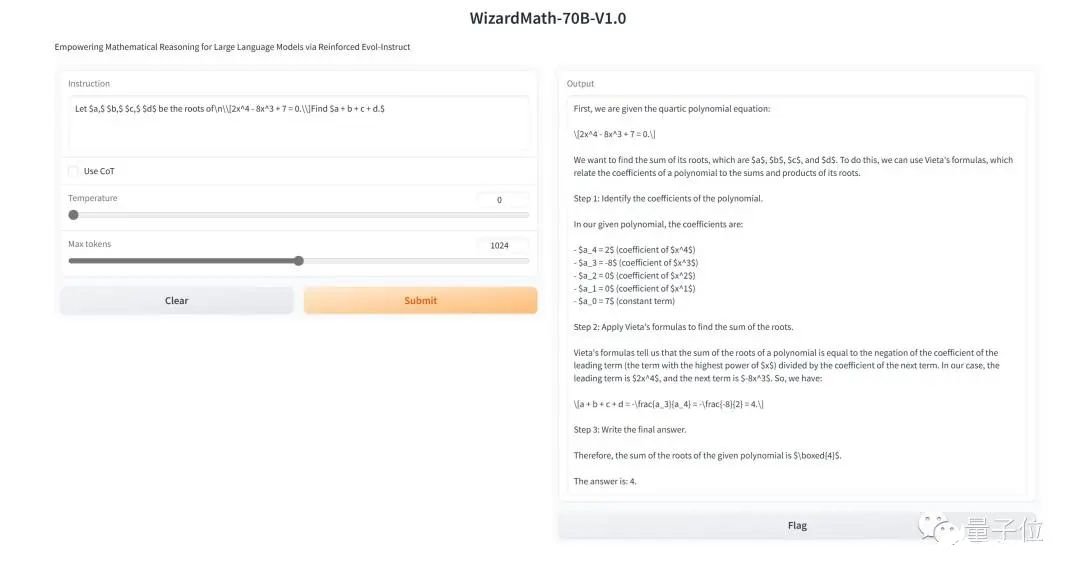
HuggingFace已上线3个在线可玩版本(分别为7B、13B和70B参数),各种数学题可以直接丢进去试一试。比如解决下面这道四次多项式方程:
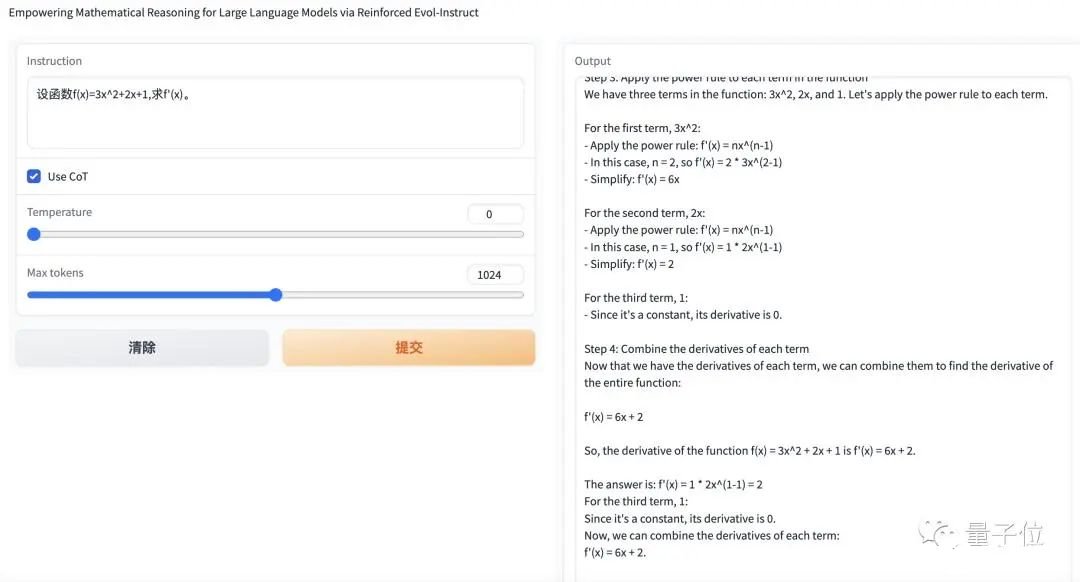
或者是一道简单的微积分:
亦或者是稍微修改过的拉格朗日方程推导:
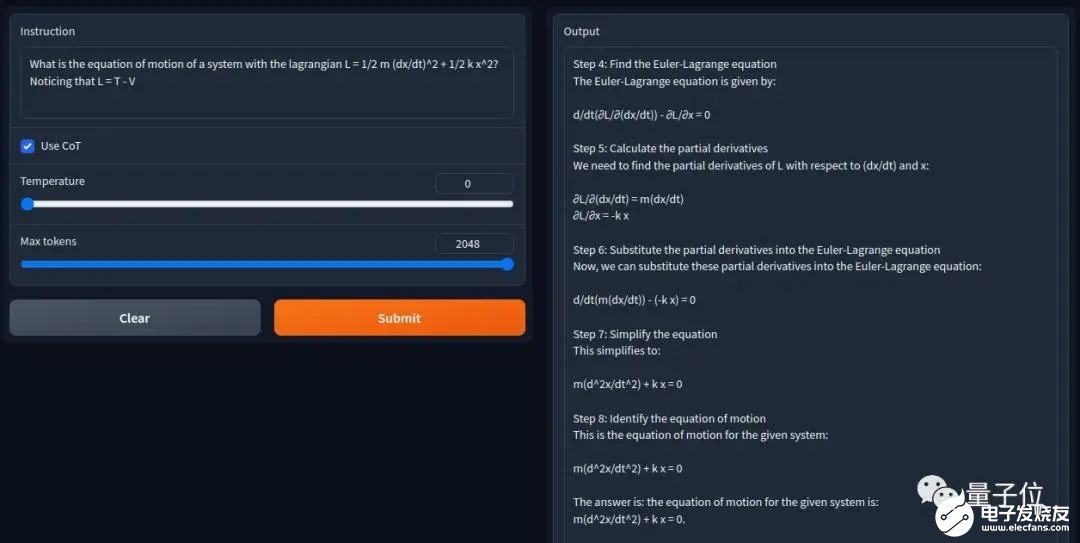
它都全部正确(过程也不需要等太久)。有网友向作者表示:效果真的很惊人,感谢你们对开源LLM的贡献。
目前,相关代码、复现方式以及论文也都开源或上线,GitHub短短几天已揽获4.8k标星。

那么,WizardMath究竟是如何做到的?用AI生成的指令增强大模型能力OpenAI的大模型(InstructGPT、GPT-4等)能够取得巨大成功、去执行各种复杂和多样化的任务,一部分原因是使用了真实人类用户生成的开放域指令数据进行了微调。然而,不是谁都能像这家公司一样获得这样的指令数据集。一是因为整个注释过程极其昂贵且耗时,二是人工难以创建出足够比例的高难度指令。因此,开发出一种成本相对较低的、大规模开放域指令自动生产方法,成为当下指令调优语言模型的关键。在此,作者将他们的方法命名为Evol Instruction。它是一种利用AI来代替人类自动生成涵盖各种难度级别开放域指令的新方法。具体而言,Evol Instruction分为指令进化器和指令消除器。其中指令进化器可通过深度进化(蓝线)或广度进化(红线)两种路径,将简单指令升级为更复杂的指令或创建一条全新指令。具体执行哪一条?随机选择就好。
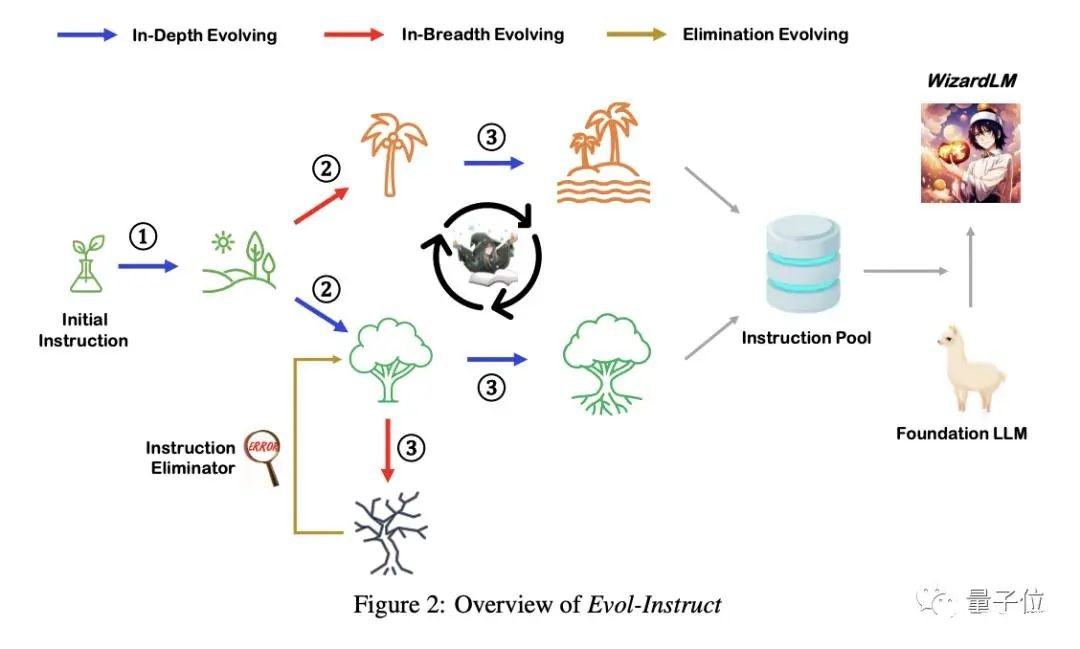
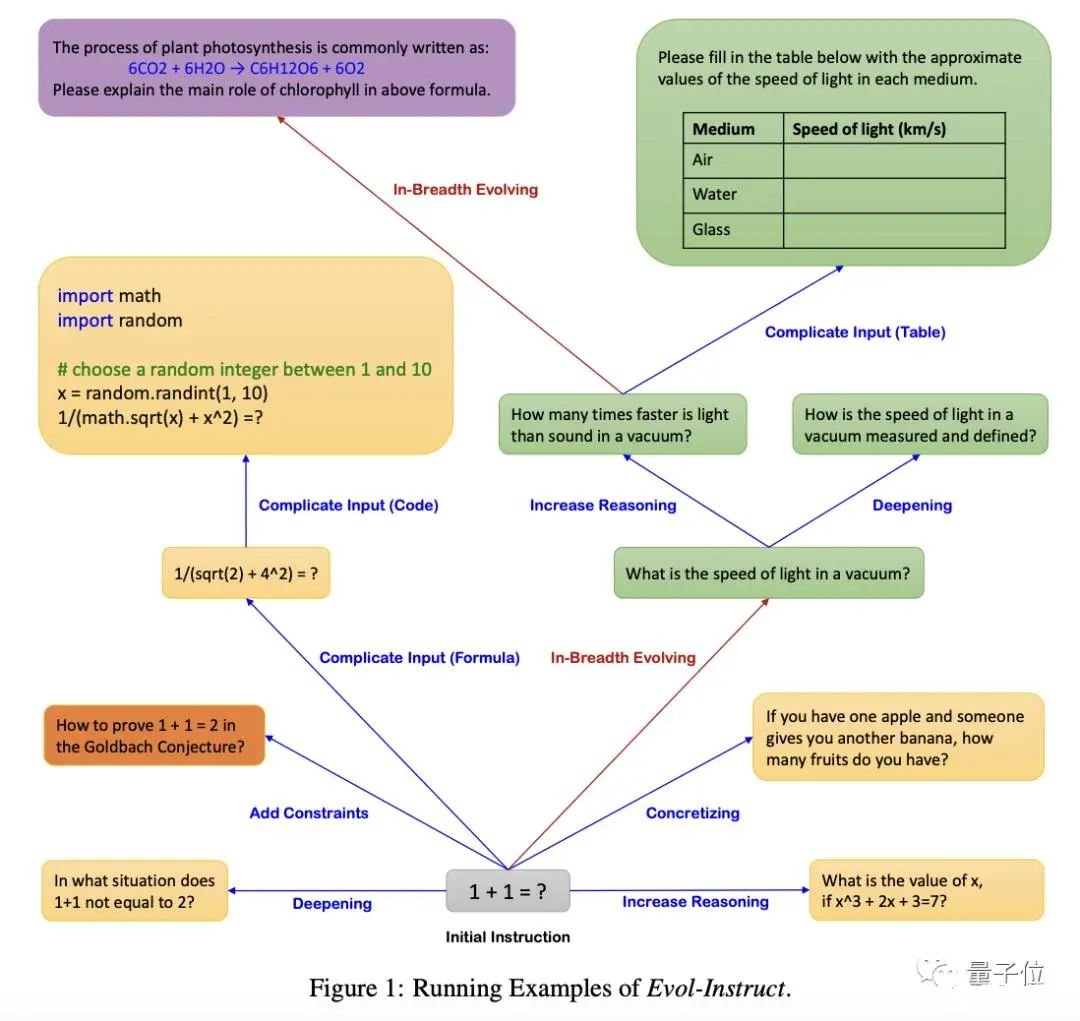
其中,深度进化的具体“进化法”,则是通过五种类型的操作来完成,包括:添加约束(add constraints)、深化(deepening)、具体化(concretizing)、增加推理步骤(increase reasoning steps)和使输入复杂化(complicate input)。由于所有指令均由AI完成,有时难免会出现错误。因此,指令消除器就是用于过滤失败指令的。以下是一个具体示例,该方法从“1+1=?”开始,最终通过以上步骤自动生成了相当多的新指令。
通过重复这一生成过程,最终我们就能得到足够多的指令,然后将它们合并并随机打乱,组成一个难度级别均匀分布的指令集,就可以对基础大模型进行微调了。在此,作者选择Alpaca的训练数据(仅由175条人工创建的种子指令生成)作为初始数据集,然后使用ChatGPT的API执行了四个进化周期,最终获得25万条指令。为了与Vicuna的70k真实用户数据(ShareGPT)进行公平比较,作者从这25万条数据中抽取了等量的样本,训练LLaMA 7B模型,最终得到WizardLM,结果WizardLM的性能明显优于Vicuna。(Alpaca:斯坦福在LLaMa-7B基础上微调出来的模型;Vicuna,UC伯克利在LLaMa-13B的基础上微调得来)此外,在更为复杂的测试指令下,人类更喜欢WizardLM的输出,而非ChatGPT,这表明该方法可以显着提高LLM处理复杂指令的能力。基于此,作者又利用Evol Instruction生成了很多数学领域相关的指令,然后微调羊驼大模型,得到了WizardMath。其效果如开头所示,在GSM8k数据集上测得其数学能力超越包括ChatGPT、Claude Instant 1、PaLM 2-540B等一众大模型,位列第5名,仅次于GPT-4、Claud1.3和2.0,以及5400亿参数的Flan-PaLM 2之后。以此类推,作者还在羊驼之上得到了专攻代码能力的WizardCoder,效果超越Claude和Bard(详情可戳文末地址)。
团队介绍本文共9位作者,全华人。一作有3位:Can Xu,微软亚洲互联网工程院S+D NLP组高级应用科学家,之前曾在微软小冰研究组和微软亚研院从事聊天机器人系统工作;Qingfeng Sun, Microsoft Research科学家,研究方向为自然语言处理和信息检索,精通构建高效搜索系统,为Microsoft Bing和Office 365贡献了核心深度模型;Kai Zheng,Microsoft Research科学家,研究方向为自然语言处理、搜索和推荐排名,同样为Microsoft Bing和Office 365贡献了核心深度模型。
通讯作者为姜大昕,微软全球合伙人、副总裁、前微软亚洲研究院首席科学家,在微软工作16年有余、曾作为微软必应搜索引擎和Cortana智能助手自然语言理解负责人,。
另还有一位作者Jiazhan Feng,是北大学生,这篇合著论文是TA在微软实习时产出的。项目主页:https://github.com/nlpxucan/WizardLM/tree/main/WizardMath论文地址:https://arxiv.org/abs/2304.12244(WizardLM)https://arxiv.org/abs/2306.08568(WizardCoder)
———————End———————
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
原文标题:【AI简报20230818期】人形机器人问世:大模型加持;用AI微调AI,微软全华班出品!
文章出处:【微信号:RTThread,微信公众号:RTThread物联网操作系统】欢迎添加关注!文章转载请注明出处。
相关推荐
他以多个案例详细介绍了用AI大模型赋能具身智能人形机器人的思路和方法,他提出未来在具身智能人形
![的头像]() 发表于
发表于 11-08 11:03
•745次阅读

从人形机器人到工厂,基于物理 AI 的工业系统正在通过训练、仿真和推理加速发展。
![的头像]() 发表于
发表于 10-27 09:54
•260次阅读
在人工智能与机器人技术融合的浪潮中,Figure AI凭借其强大的技术实力和雄厚的资金支持,成功推出了新一代人形机器人——Figure 02,再次引领行业变革。这款
![的头像]() 发表于
发表于 08-08 16:30
•764次阅读
英伟达近日宣布了一项重大举措,为全球机器人制造业与AI领域注入强劲动力。公司推出了专为人形机器人设计的训练平台,旨在为行业领先的制造商、AI
![的头像]() 发表于
发表于 08-05 11:45
•735次阅读
金航标kinghelm萨科微slkor总经理宋仕强介绍说,萨科微Al大模型机器人有哪些的优势?萨科微AI大模型机器人由清华大学毕业的天才少年
发表于 07-05 08:52
机器人的 AI。 黄仁勋表示:“开发通用人形机器人基础模型是当今 AI 领域中最令人兴奋的课题之
![的头像]() 发表于
发表于 06-04 18:00
•7707次阅读
据悉,该芯片将由台积电(2330)操刀生产。软银集团对AI发展的热情高涨,其与鸿海(2317)集团在人形机器人Pepper项目上的成功合作,以及桦汉(6414)在AI相关领域的实力,引
![的头像]() 发表于
发表于 05-13 10:09
•475次阅读
优必选宣布人形机器人Walker S接入百度文心大模型,共同探索中国AI大模型+人形
![的头像]() 发表于
发表于 04-07 10:17
•918次阅读
NVIDIA Isaac机器人平台近期实现重大升级,通过引入最新的生成式AI技术和先进的仿真技术,显著加速了AI机器人技术的发展步伐。该平台正不断扩展其基础
![的头像]() 发表于
发表于 03-27 10:36
•682次阅读
,与英伟达一起推动全球AI机器人的深度进化。 Unitree H1前段时间刚刚以每秒3.3米的运动速度创下了全尺寸人形机器人速度的世界纪录,
![的头像]() 发表于
发表于 03-20 14:55
•637次阅读
近日,人工智能领域掀起了一股人形机器人的热潮。备受瞩目的新星企业Figure AI成功完成了一轮6.75亿美元的融资,吸引了英伟达、微软、OpenAI等业内重量级企业,以及亚马逊创始人
![的头像]() 发表于
发表于 02-26 18:26
•1245次阅读
人形机器人火热 OpenAI入局人形机器人 英伟达等巨头入局机器人行业 人形
![的头像]() 发表于
发表于 02-26 17:21
•799次阅读
现在的人形机器人不仅形态更接近人类,而且具备更多的智慧。随着大型AI模型的不断推进,人工智能正在加速人形通用
发表于 02-22 09:22
•390次阅读

谷歌(Google)近日宣布,旗下备受瞩目的AI聊天机器人Bard正式更名为Gemini,并推出了一款功能更加强大的付费版本——Gemini Advanced。这一战略调整旨在与微软、OpenAI等科技巨头在
![的头像]() 发表于
发表于 02-18 11:28
•1104次阅读
近日,人形机器人初创公司Figure AI Inc.正与微软和OpenAI展开融资谈判,目标筹集高达5亿美元的资金。据悉,微软和OpenAI
![的头像]() 发表于
发表于 02-04 11:00
•946次阅读
 【AI简报20230818期】人形机器人问世:大模型加持;用AI微调AI,微软全华班出品!
【AI简报20230818期】人形机器人问世:大模型加持;用AI微调AI,微软全华班出品!





 工商网监
工商网监
评论