 riscv的fpga实现案例 基于RISC-V加速器实现现场可编程门阵列 CNN异构的控制方案
riscv的fpga实现案例 基于RISC-V加速器实现现场可编程门阵列 CNN异构的控制方案
作者:吴海龙, 李金东, 陈翔,电子与信息工程学院,中山大学,中国 (在此特别鸣谢!)
摘要:现场可编程门阵列(FPGA)具有低功耗、高性能和灵活性的特点。FPGA神经网络加速的研究正在兴起,但大多数研究都基于国外的FPGA器件。为了改善国内FPGA的现状,提出了一种新型的卷积神经网络加速器,用于配备轻量级RISC-V软核的国产FPGA(紫光同创PG2L100H)。所提出的加速器的峰值性能达到153.6 GOP/s,仅占用14K LUT(查找表)、32个DRM(专用RAM模块)和208个APM(算术处理模块)。所提出的加速器对于大多数边缘AI应用和嵌入式系统具有足够的计算能力,为国内FPGA提供了可能的AI推理加速方案。
背景
卷积神经网络在机器视觉任务中越来越流行,包括图像分类和目标检测。如何在有限的条件下充分发挥FPGA的最大性能是各研究者的主要方向。如今,大多数CCN使用外国FPGA器件。由于国内FPGA起步较晚,其相关开发工具和设备落后于其他外国制造商。因此,在国内FPGA上构建高性能CNN并替换现有成熟的异构方案是一项具有挑战性的任务。 Zhang[1]于2015年首次对卷积网络推理中的数据共享和并行性进行了深入分析和探索。Guo[2]提出的加速器在214MHz下达到了84.3 GOP/s的峰值性能。2016年,Qiu[3]更深入地探索了使用行缓冲器的加速器。
本文提出了一种更高效、更通用的卷积加速器。提出的加速器峰值性能达到153.6GOP/s,仅占用14K LUT、32个DRM和208个APM。本文的章节安排如下,第2节介绍了我们提出的加速器的详细设计以及基于RISC-V的加速器实现的控制调度方案。第3节给出了实验结果。
系统设计
整个RISC-V片上系统设计如图1所示。该系统主要由RISC-V软核CPU、指令/数据存储器、总线桥、外围设备、DMA(直接存储器访问)和卷积加速器组成。
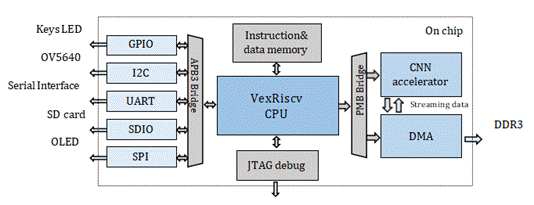
Fig. 1. 片上RISC-V系统设计图
我们的工作主要在三个方面。首先,我们使用软核CPU作为片上系统的主控,控制外设,DMA,CNN加速器来实现数据调度和操作。其次,1D(一维)加速器被设计用于改变缓冲机制。第三,为紫光同创的FPGA设备设计了一个DMA IP,用于卷积加速的应用。
A、RISC-V 软核CPU 架构
软核。使用RISC-V软核VexRiscv代替Ibex[4]构建RISC-V的片上系统和面向软件的方法可以使VexRiscv具有高度的灵活性和可扩展性。
接口。I2C和SPI等外围设备通过APB3总线连接到RISC-V软核。DMA和加速器通过PMB总线连接到RISC-V软核。
指令与数据存储。程序被交叉编译以获得一个特定的文件,该文件由JTAG烧录到片上指令/数据存储器中。
B、CNN 加速器结构
输入缓存。使用乒乓缓存来实现缓冲区,可以有效地提高吞吐量。
输出缓存。权重缓存模块由一系列分布式RAM和串行到并行单元组成。
卷积。图2中的1D卷积模块分为四组,其中包含四个1D卷曲单元。每个单元负责1D卷积的一个信道。
合并。积分模块有四组加法器树。每组加法器树将每组卷积运算单元的结果相加,得到单向输出结果。
累加。累加模块中有四组FIFO和四个加法器。加速器一次只能接收四个通道的输入特征图数据。
量化。该量化模块由乘法单元和移位单元组成。它通过比例变换将24位累加结果重新转换为8位[5]。
激活。激活功能通过查找由一系列分布式RAM组成的表来实现。它存储ReLu、Leaky ReLu和sigmoid函数的INT8函数表。
池化。确定当前卷积层是否与池化层级联,然后决定是否使用池化模块来完成池化操作。
输出缓存。输出缓冲器由FIFO而不是乒乓缓存实现。输出高速缓存FIFO将结果存储回片外存储器,作为下一卷积层的输入。
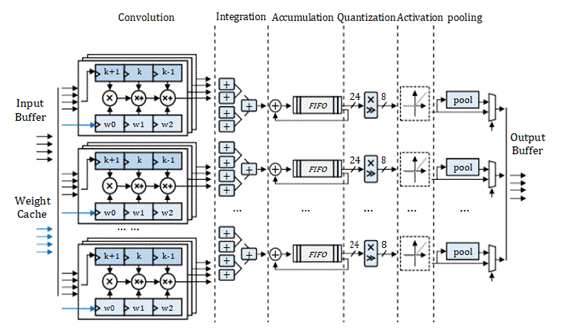
Fig. 2.CNN 加速器实现
C、DMA 结构
神经网络不仅对计算能力有很高的要求,而且对内存也有很大的需求。中低端FPGA通常需要DDR SRAM(双数据速率同步动态随机存取存储器)来承载整个神经网络和所有中间运算结果的权重。紫光同创的FPGA的DDR3内存驱动器IP为用户提供了简化AXI4总线的内存访问接口。 由于Simpled AXI和AXI之间的标准差异,需要新的DMA设计。DMA设计如下。读和写地址通道由RISC-V软核直接控制。读写数据通道的FIFO用作卷积加速器和DDR3驱动器IP的缓冲器,以完成端口转换。
D、实现细节
1、一维卷积单元阵列设计 神经网络不仅对计算能力有很高的要求,而且对内存也有很大的需求。中低端FPGA通常需要DDR SRAM(双数据速率同步动态随机存取存储器)来承载整个神经网络和所有中间运算结果的权重。紫光同创的FPGA的DDR3内存驱动器IP为用户提供了简化AXI4总线的内存访问接口。 由于Simpled AXI和AXI之间的标准差异,需要新的DMA设计。DMA设计如下。读和写地址通道由RISC-V软核直接控制。读写数据通道的FIFO用作卷积加速器和DDR3驱动器IP的缓冲器,以完成端口转换。
2、卷积加速器控制
本文提出了一种基于指令队列的设计,以减少RISC-V软核中DMA和加速器的响应延迟。RISC-V CPU可以连续发送多个存储器读写请求指令和多个操作调度控制指令,而不用等待DMA和加速器的反馈。DMA和加速器从队列中获取指令,任务完成后直接从队列中取出下一条指令,无需等待相应的CPU,从而实现低延迟调度。
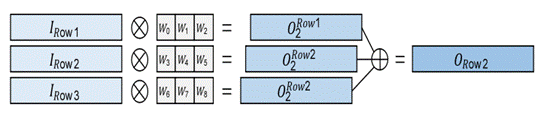
Fig. 3. 1X3 一维卷积原理图
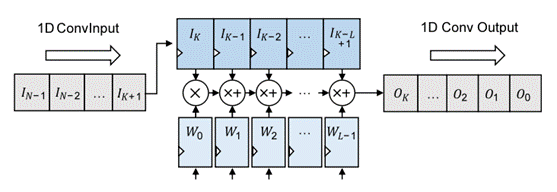
Fig. 4. 一维卷积单元硬件实现
实现结果和备注
通过在PG2L100H和X7Z020上实现相同配置的CNN加速器,完成了CNN加速器的性能测试,验证了国产FPGA CNN加速方案的可行性。加速器的资源消耗和性能如表I和表II所示。
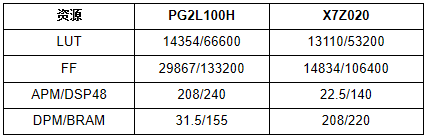
TABLE I 资源利用 PG2L100H和X7Z020的资源消耗相似。PG2L100H需要额外的逻辑资源来构建VexRiscv CPU,而X7Z020为AXI DMA IP使用更多的逻辑资源。就加速器性能而言,可从表II中看出。由于FPGA器件架构的差异,与X7Z020相比,加速器的卷积运算在PG2L100H上只能在200MHz下实现更好的收敛。RISC-V软核只能在100MHz下实现定时收敛。
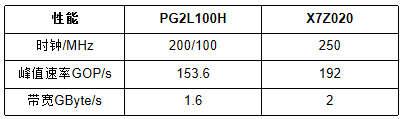
TABLE II 性能对比 我们提出了一种基于RISC-V的一维卷积运算的新设计。该加速器在国内FPGA上的实现和部署已经完成,其性能与具有相同规模硬件资源的国外FPGA相当。
本文论证了基于国产FPGA的CNN异构方案的可行性,该研究是国产FPGA应用生态中CNN加速领域的一次罕见尝试。
作者:吴海龙, 李金东, 陈翔,电子与信息工程学院,中山大学,中国 (在此特别鸣谢!)
REFERENCES:
[1]Zhang. C, et al. "Optimizing FPGA-based Accelerator Design for Deep Convolutional Neural Networks. " the 2015 ACM/SIGDA International Symposium ACM, 2015.
[2]K. Guo et al., "Angel-Eye: A Complete Design Flow for Mapping CNN Onto Embedded FPGA," in IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol. 37, no. 1, pp. 35-47, Jan. 2018.
[3]Qiu.J, et al. "Going Deeper with Embedded FPGA Platform for Convolutional Neural Network." the 2016 ACM/SIGDA International Symposium ACM, 2016.
[4]E. Gholizadehazari, T. Ayhan and B. Ors, "An FPGA Implementation of a RISC-V Based SoC System for Image Processing Applications," 2021 29th Signal Processing and Communications Applications Conference (SIU), 2021, pp. 1-4.
[5]B. Jacob et al., "Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference," 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018, pp. 2704-2713.
[6]B. Bosi, G. Bois and Y. Savaria, "Reconfigurable pipelined 2-D convolvers for fast digital signal processing," in IEEE Transactions on Very Large Scale Integration (VLSI) Systems, vol. 7, no. 3, pp. 299-308, Sept. 1999.
-
FPGA
+关注
关注
1634文章
21830浏览量
608040 -
加速器
+关注
关注
2文章
812浏览量
38315 -
神经网络
+关注
关注
42文章
4789浏览量
101530 -
cnn
+关注
关注
3文章
353浏览量
22428 -
RISC-V
+关注
关注
46文章
2378浏览量
47101
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论