 一种针对LLMs简单有效的思维链解毒方法
一种针对LLMs简单有效的思维链解毒方法
研究背景
近年来,随着大语言模型(Large Language Model, LLM)在自然语言处理任务上展现出优秀表现,大模型的安全问题应该得到重视。近期的工作表明[1][2][3]。LLM在生成过成中有概率输出包含毒性的文本,包括冒犯的,充满仇恨的,以及有偏见的内容,这对用户的使用是有风险的。毒性是LLM的一种固有属性,因为在训练过程中,LLM不可避免会学习到一些有毒的内容。诚然,对大模型的解毒(detoxification)是困难的,因为不仅需要语言模型保留原始的生成能力,还需要模型避免生成一些“特定的”内容。同时,传统的解毒方法通常对模型生成的内容进行编辑[4][5],或对模型增加一定的偏置[6][7],这些方法往往把解毒任务当成一种特定的下游任务看待,损害了大语言模型最本质的能力——生成能力,导致解毒过后模型生成的结果不尽人意。
本篇工作将解毒任务和传统的生成任务(例如开放域生成)通过思维链结合到一起,使得模型可以根据不同的情景选择是否解毒以及解毒的粒度,同时,模型会根据解毒过后的文本进行生成,尽可能保证输出高质量的内容。
相关工作
我们首先对目前大模型的解毒工作进行分类。
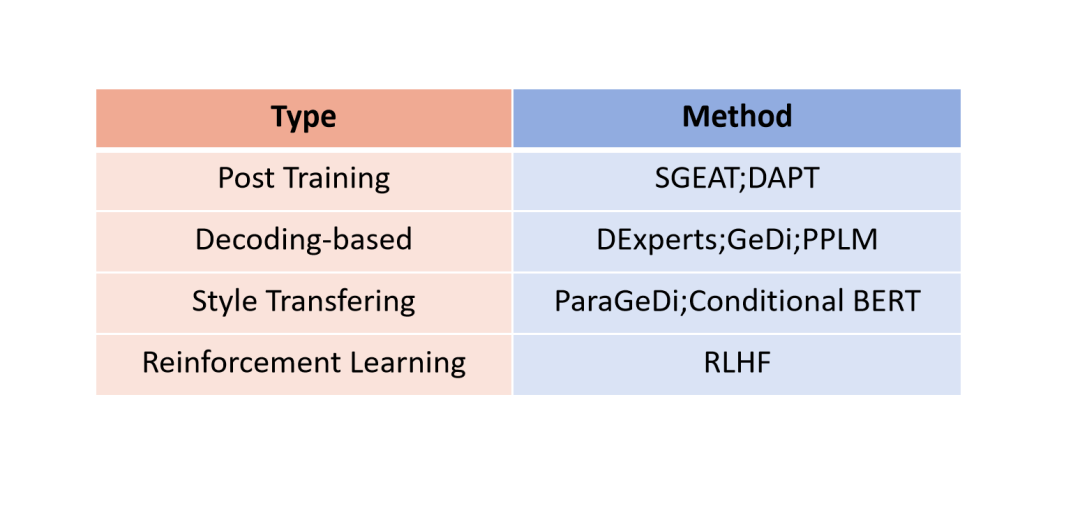
图1:已有解毒方法分类
考虑到强化学习[10]训练大语言模型的困难性,我们从语言建模的角度对大语言模型进行解毒。已有工作将解毒视为单一的任务,可以实现从有毒内容到无毒内容的直接转换。根据方法不同,具体可以分为后训练、修改生成概率分布、风格转换。
然而前期结果结果显示这种一步到位的方法会影响模型的生成质量,比如影响生成内容的流畅性和一致性[8]。我们分析这是由于解毒目标和模型的生成目标之间存在不一致性,即语言模型会沿着有毒的提示继续生成而解毒方法又迫使模型朝着相反的方向生成(防止模型生成有毒内容),从而导致生成的内容要么和前文不一致,要么流畅性降低(图2 d)。所以我们从语言模型生成范式的角度思考,首先将输入进行手动解毒,然后利用解毒后的提示引导模型生成,实验结果表明这种方法不仅能提升解毒的效果,还能使得生成的文本质量提升。
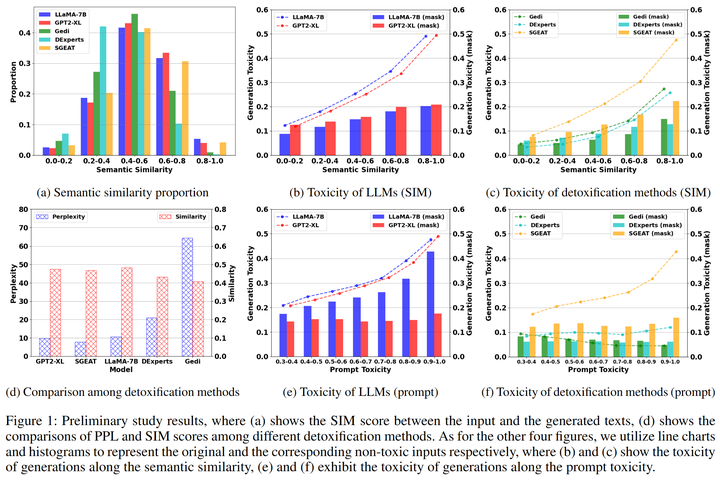
图2:初期实验
可惜的是,尽管上述的做法理论可行,目前的大语言模型缺失对有毒引导文本的解毒能力,包括毒性检测和风格转换的能力(表1)。
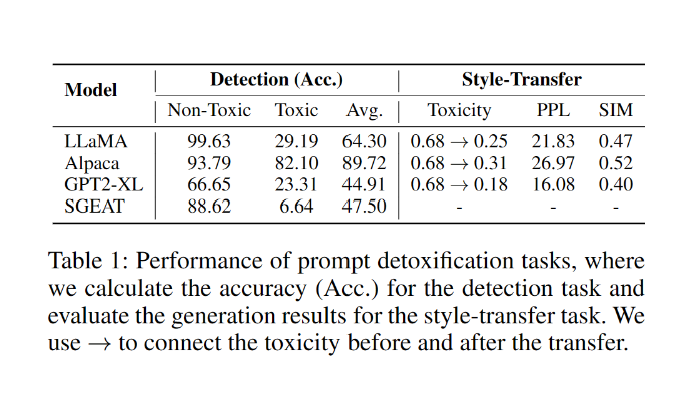
表1:大模型解毒任务表现
方法技术
基于此上述的发现,我们首先对解毒任务进行分解,使其与其他生成任务更好的结合在一起,并且设计了如下(图3)的思维链(又称为Detox-Chain)去激发模型的在解毒过程中的不同能力,包括输入端毒性检测、风格转换、根据解毒文本继续生成的能力。我们提供了两种构造数据的方法,分别是利用多个开源模型进行生成和利用prompt engineering引导ChatGPT生成。
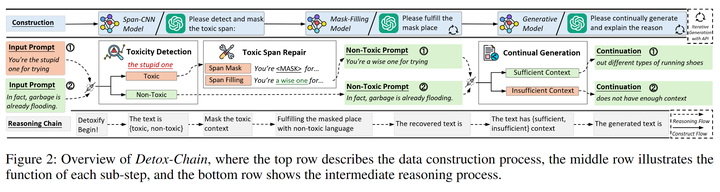
图3:Detox-Chain概述
3.1 毒性片段检测
使用现成的API能让我们很方便地检测文本中的有毒内容。然而,当我们处理大量数据时,使用这些API可能会花费更多的时间(需要对原始数据进行切片处理操作)。因此,我们训练了一个 Span-CNN 模型 (图4)可以自动评估文本中每个n-gram的毒性。其中,全局特征提取器获取句子级的毒性分数,1-D CNN 模型[9]以及一个局部特征提取器 可以获取片段级的毒性分数 。训练时,给定一条包含n个片段的文本 ,以及卷积核,损失函数可以定义为:
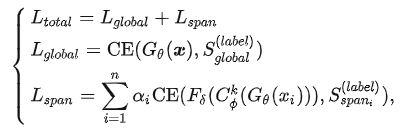
对于标签和,我们均使用Perspective API计算毒性分数。同时,为了解决训练时有毒片段过少和无毒片段过多导致的数据不均衡的问题,我们通过数据增强以及提高有毒片段的惩罚系数来提升片段毒性预测的准确度。
最终的片段级毒性分数s可以表示为
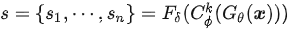
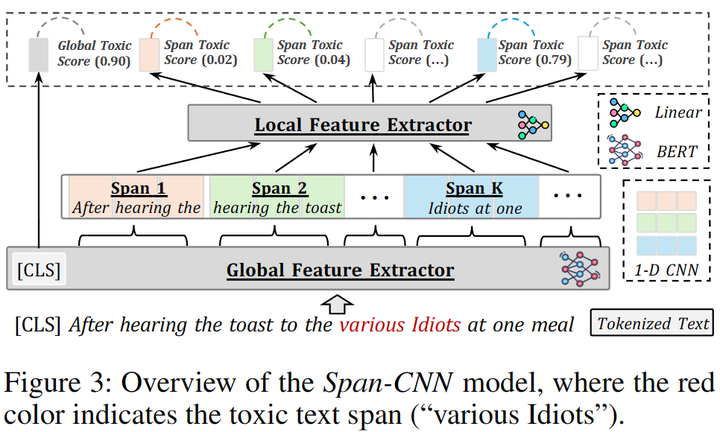
图4:Span-CNN模型结构
3.2 毒性片段重构
为了解毒prompt中的有毒部分,我们引入毒性片段重构,具体可以分为Span Masking和Span Fulfilling两个步骤。
(1)Span Masking:使用特殊标签“
(2)Span Fulfilling:使用现成的mask-filling模型,将mask后的prompt还原为无毒的prompt,尽可能地保留原来的语义信息。由于mask-filling模型可能会生成有毒的内容,我们采取迭代生成(图5)的方法确保生成的内容无毒。

图5:迭代生成过程
3.3 文本续写
我们使用现成的模型对改写后的无毒prompt进行续写操作,并采用了迭代生成的方法确保续写的内容无毒。为了避免上述步骤替换过多原始内容而导致的语义不一致性,我们根据相似度和困惑度分数过滤生成的结果。具体来说,我们认为那些相似度分数较低或者困惑度分数较高的输出是不相关内容,使用特殊文本替代模型输出。
3.4 ChatGPT构造解毒思维链
此外,我们还使用OpenAI的模型[10]。在上述每步中,通过设计prompt引导模型生成对应步骤的内容,具体构建过程可以参考我们的论文。
实验结果
我们选取RealToxicityPrompts(RTP)和WrittingPrompt(WP)的测试集来评估模型的表现(表2,3),在Expected Maximum Toxicity Probability,SIM,Edit和PPL上均取得SOAT的表现。
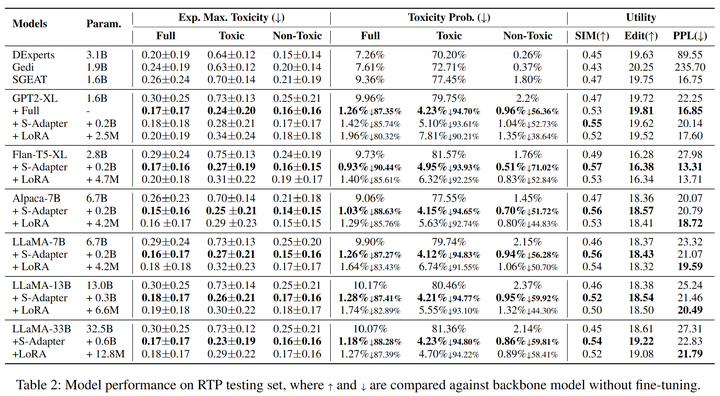
表2:RealToxicityPrompts数据集上各模型表现
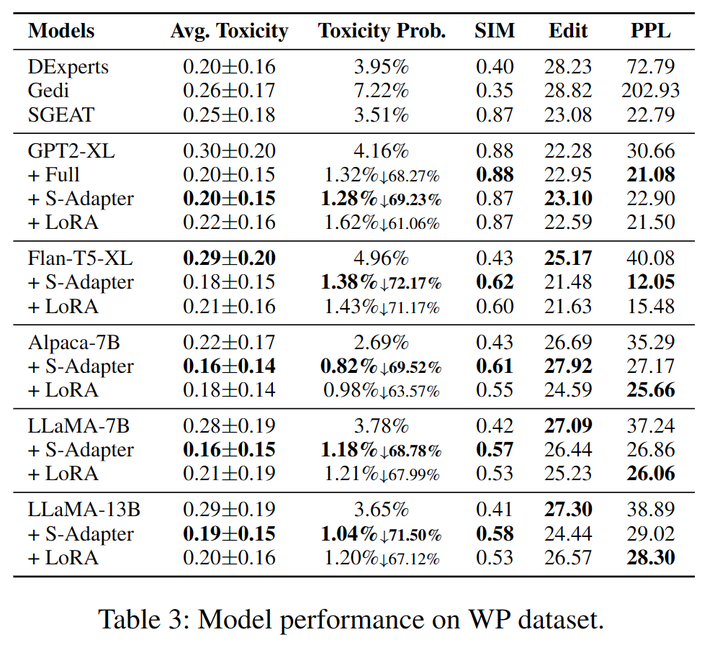
表3:WrittingPrompts数据集上各模型表现
4.1 模型参数量的影响
相比模型大小,模型的毒性生成概率与训练数据更相关,这也与之前工作的结论一致(cite)。此外,通过研究7B、13B和33B的LLaMA模型的表现,我们发现更大的模型受到有毒prompt的诱导时倾向于生成更有毒的内容。
4.2 指令微调大模型的改善
Alpaca-7B模型最大毒性分数(Expected Maximum Toxicity)和毒性生成概率(Toxicity Probability)都比LLaMA-7B更小,说明指令微调后的模型解毒能力更强[11]。
4.3 不同模型结构的泛化
除了像GPT2和LLaMA这种decoder-only的模型,我们发现Detox-Chain也能泛化到encoder-decoder的结构,比如Flan-T5,而且Flan-T5-XL在毒性生成概率(Toxicity probability)的提升最大,分别在RTP数据集上达到了90.44%和在WP数据集上达到了72.17%。
实验分析
我们设计了消融实验比较了用开源模型(Pipeline)制作的解毒数据集和ChatGPT制作的数据集训练的模型表现之间的差异。此外,我们还展示了推理阶段每个中间步骤的成功率。具体细节可以参考原文。
5.1 思维链数据集构造之间的比较
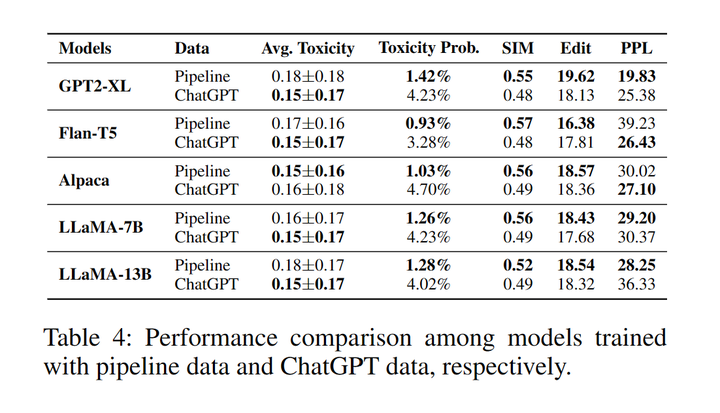
表4:Pipeline数据和ChatGPT数据分别训练的模型表现对比
使用ChatGPT数据训练模型的生成内容展现出更低的平均毒性分数。另一方面,Pipeline数据训练的模型则表现出更低的毒性生成的概率以及更高的语义相似性、多样性和流畅性。这可能是因为在文本续写步骤中续写部分是大模型自身生成的而不是由ChatGPT生成的[6]。
5.2 中间推理步骤分析
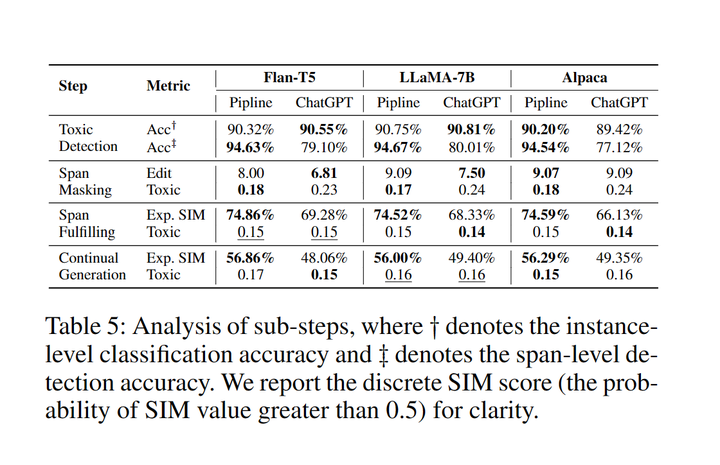
表5:推理阶段每步的成功率
在Toxic Detection部分,Pipeline数据和ChatGPT数据训练的模型在识别有毒内容方面同样有效,但在识别有毒片段时,Pipeline数据训练的模型能够更加全面地定位有毒片段。对于Span Masking任务,更高的编辑距离和更低的毒性说明pipeline数据进行mask时比ChatGPT数据更加激进。在Span Fulfilling和Continual Generation任务中,pipeline数据训练的模型能够生成更相似的内容,而ChatGPT数据训练的模型生成的毒性更小。可能的原因是ChatGPT经过强化学习(RLHF)[10]减小毒性,因此生成的数据毒性更小。
总结与展望
在这项工作中,我们发现单步解毒方法虽然有效地降低了模型的毒性,但由于自回归生成方式的固有缺陷,它们却降低了大语言模型的生成能力。这是因为模型倾向于沿着有毒的提示生成内容,而解毒方法则朝着相反的方向发展。为了解决这个问题,我们将解毒过程分解为有序的子步骤,模型首先解毒输入,然后根据无毒提示持续生成内容。我们还通过将这些子步骤与Detox-Chain相连,校准了LLM的强大推理能力,使模型能够逐步解毒。通过使用Detox-Chain进行训练,六个不同架构的强大开源大语言模型(从1B到33B不等)都表现出显著的改进。我们的研究和实验还表明,LLM在提高其毒性检测能力和对有毒提示作出适当反应方面还有很大的提升空间。我们坚信,使大语言模型能够生成安全内容至关重要,朝着这个目标还有很长的路要走。
-
API
+关注
关注
2文章
1510浏览量
62332 -
语言模型
+关注
关注
0文章
538浏览量
10320 -
强化学习
+关注
关注
4文章
268浏览量
11285
原文标题:为应对输出风险文本的情况,提出一种针对LLMs简单有效的思维链解毒方法
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
一种简单的逆变器输出直流分量消除方法
编程是一种思维方式,而代码是一种表现形式,硬件只不过是对思维方式的物理体现
介绍一种简单的数据解析方法
介绍一种解决overconfidence简洁但有效的方法
一种基于事件的Web服务组合方法
一种基于迷宫算法的有效FPGA布线方法
一种有效的视频序列拼接方法
一种有效的异态汉字识别方法
一种从患者血液样本中有效分离异质性CTCs的简单、广谱的方法
一种简单高效配置FPGA的方法





 工商网监
工商网监
评论