 国内8种大模型体验测评报告(2023)
国内8种大模型体验测评报告(2023)
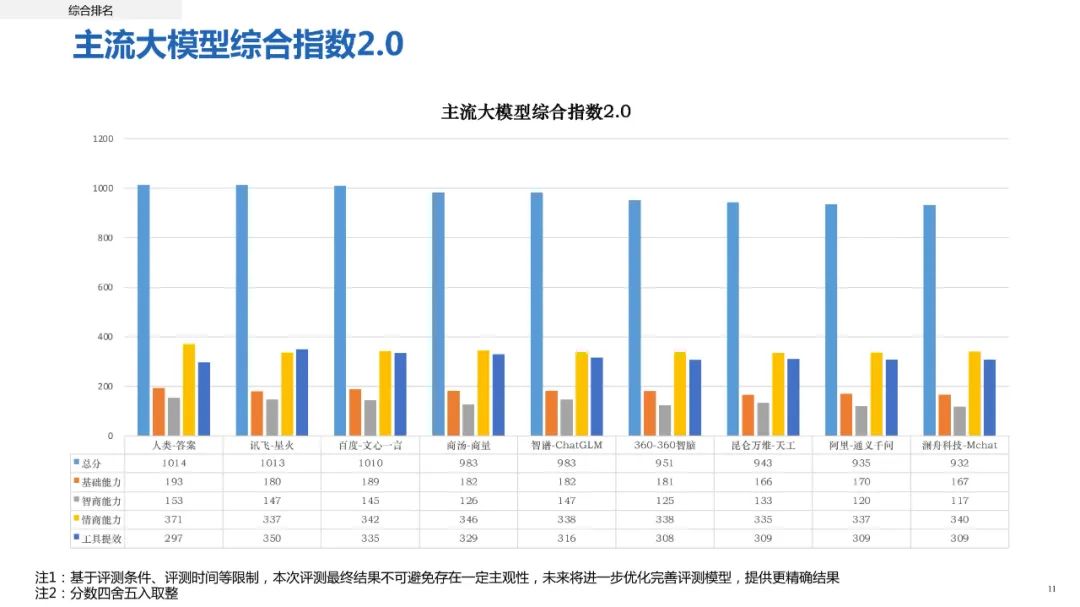
《人工智能大模型体验报告2.0》报告指出当前国产大模型产品已具有显著进步,讯飞星火、百度文心一言、商汤商量和智谱AI-ChatGLM均表现抢眼,但与接受过高等教育的人类相比,在智商、情商等方面仍存在一定程度差距。
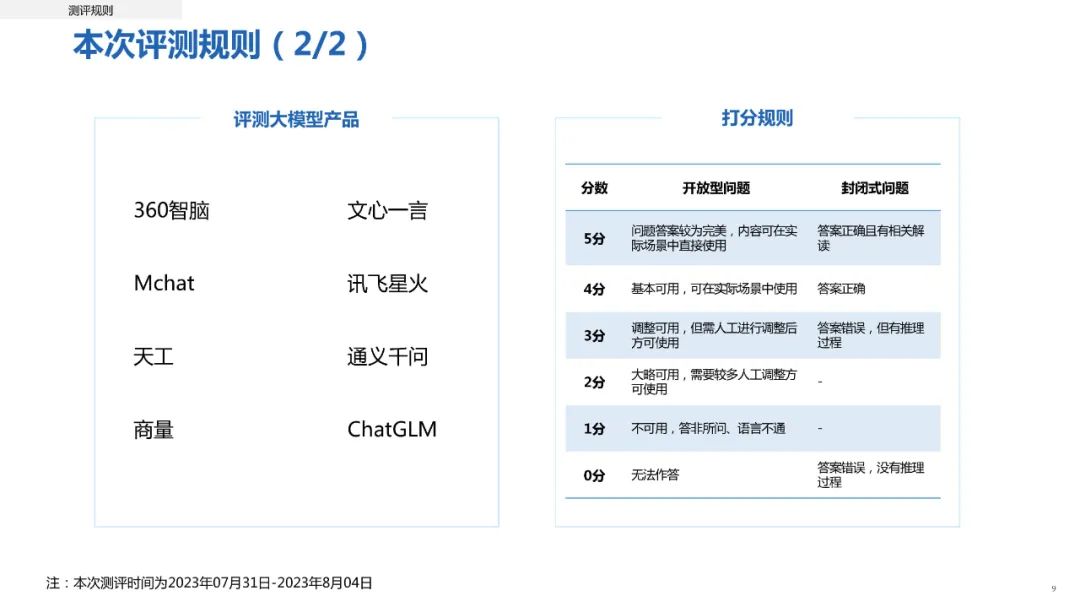
报告选取360智脑、百度文心一言、澜舟 Mchat、商汤商量、讯飞星火、阿里通义千问、昆仑天工、智谱 ChatGLM 共 8 种大模型产品进行评测,根据基础能力、智商能力、情商能力、工具提取四个维度计算总分。
报告显示,与2023年6月相比,当前中国大模型产品进步显著。但与接受过高等教育的人类相比,大模型在智商、情商等方面还存在一定程度差距。具体来看,讯飞星火在工作提效方面优势明显,百度文心一言基础能力仍处领军水准,商汤商量则在情商方面表现优秀,智谱AI-ChatGLM整体表现优秀。
针对各维度能力测评,该报告还给出了相应的案例展示和分析。
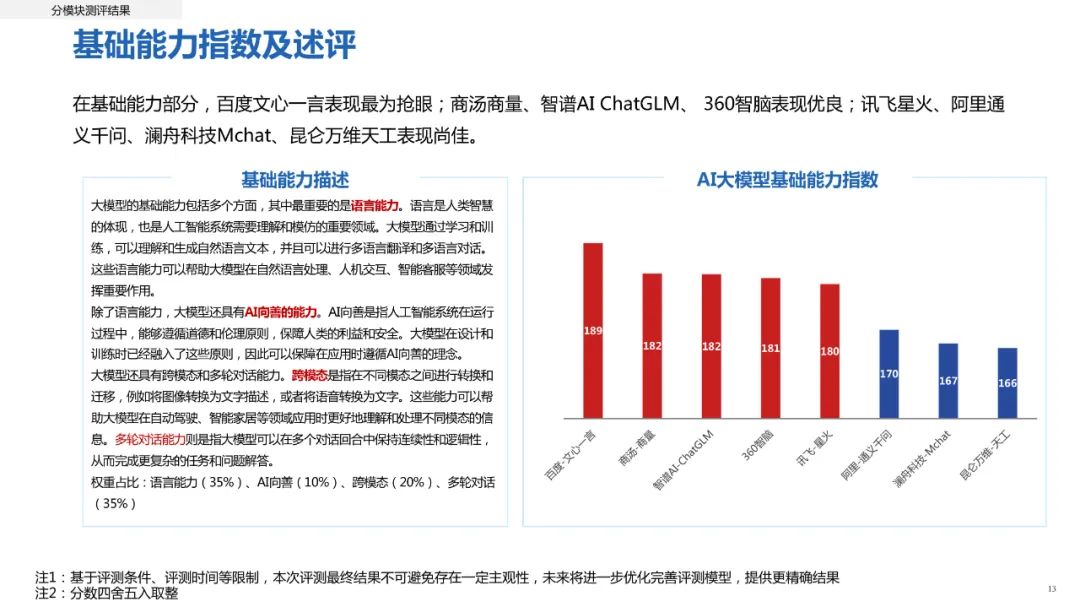
在基础能力方面,人类与AI之间的差距并不显著。课题组分别从语言能力(35%)、AI向善(10%)、跨模态(20%)和多轮对话(35%)四大指标进行测评。测评显示,科技企业大模型中,百度文心一言表现最为抢眼,商汤商量、智谱AI-ChatGLM、360智脑表现优良。
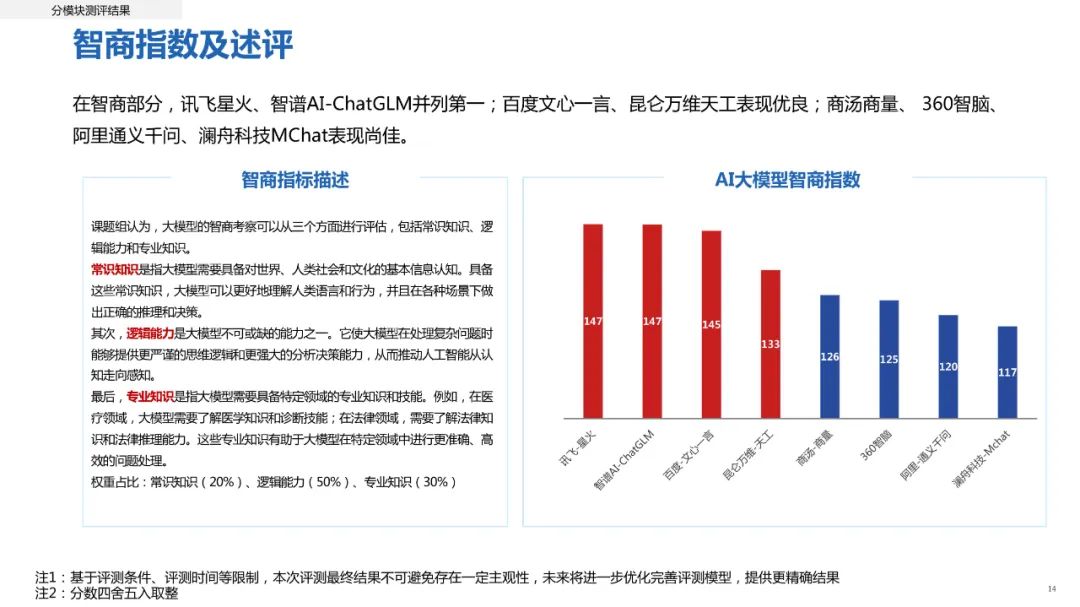
在智商评估方面,人类在智商方面仍然具有明显优势。课题组分别从常识知识(20%)、逻辑能力(50%)和专业知识(30%)方面对科技企业大模型进行考量。结果显示,讯飞星火、智谱AI-ChatGLM表现突出,百度文心一言、昆仑万维天工表现优良。
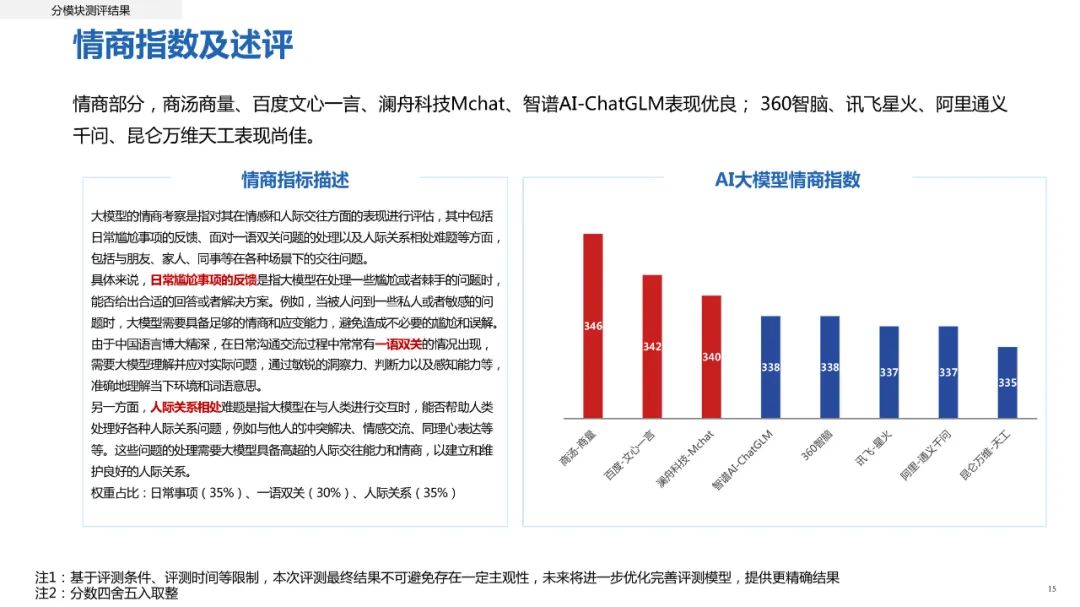
在情商方面,AI与人类之间的差距最为明显。人类在情绪理解和处理方面通常具有更强的优势,和更灵活的处理能力。通过对处理日常事项(35%)、一语双关(30%)、人际关系(35%)问题进行分析发现,科技企业大模型中,商汤商量表现亮眼,百度文心一言、澜舟科技Mchat、智谱AI-ChatGLM及360智脑均表现优良。
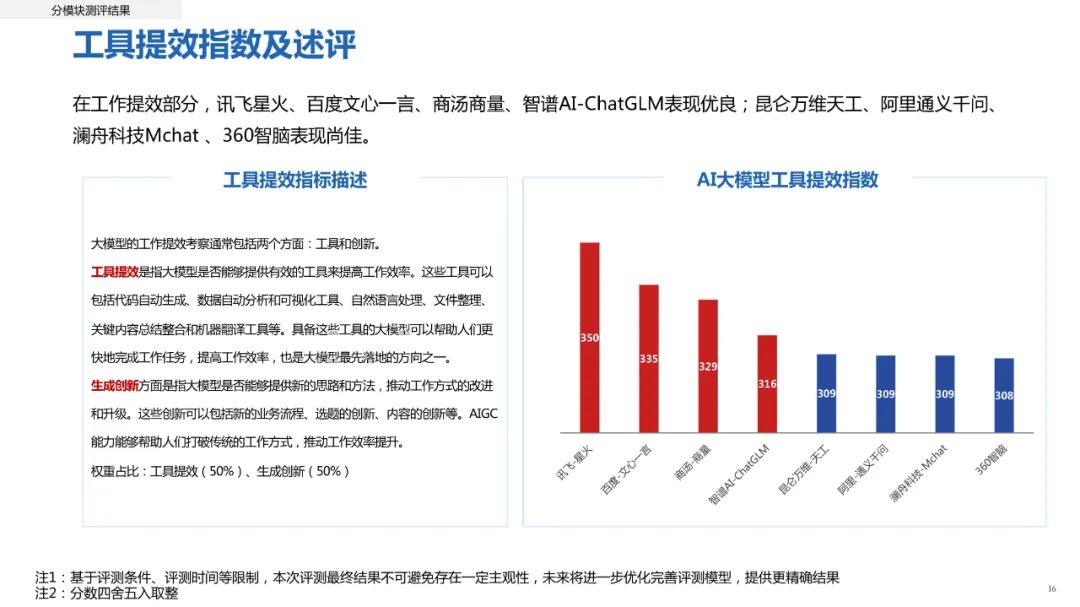
在工作效率提升方面,课题组重点在工具提效(50%)和生成创新(50%)方面进行考量。结果显示,讯飞星火表现最为抢眼,百度文心一言、商汤商量、智谱AI-ChatGLM表现优良。不过,尽管AI具有高速度和高效率的优势,但在某些复杂和具有创新性的任务中,人类的智慧和想象力仍然具有无法替代的作用。
在不同领域中,AI和人类表现出不同的优劣势,但在整体上,AI大模型的发展为人类工作和生活的提质增效带来了重要的积极影响,大模型正在加速走进生活、走进产业。在本次体验测评基础上,研究团队将继续深耕,加强在大模型安全可解释性、工作提效能力、实际落地情况、产业优秀案例等维度上的探索与研究。


















-
AI
+关注
关注
87文章
31155浏览量
269487 -
人工智能
+关注
关注
1792文章
47442浏览量
239004 -
大模型
+关注
关注
2文章
2491浏览量
2870
原文标题:国内8种大模型体验测评报告(2023)
文章出处:【微信号:AI_Architect,微信公众号:智能计算芯世界】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
高通发布《2023高通中国企业责任报告》
中兴通讯发布2023年可持续发展报告
【附实操视频】聆思CSK6大模型开发板接入国内主流大模型(星火大模型、文心一言、豆包、kimi、智谱glm、通义千问)
中文大模型测评基准SuperCLUE:商汤日日新5.0,刷新国内最好成绩

小米大语言模型获备案,有望应用于汽车、手机等产品
ChatGPT、Gemini、通义千问等一众大语言模型,哪家更适合您?
“云天天书”大模型成功入选“磐石·X”榜单!

2023 “IBM 影响力”报告
理想汽车发布2023年ESG报告
芯原股份正式发布《2023年社会责任报告》
名单公布!【书籍评测活动NO.30】大规模语言模型:从理论到实践
佐思汽研发布《2023-2024年汽车AI大模型技术和应用趋势报告》





 工商网监
工商网监
评论