 Eideticom NoLoad计算存储解决方案解读
Eideticom NoLoad计算存储解决方案解读
NoLoad 计算存储设备与英特尔 Agilex FPGA 及英特尔 至强 处理器相结合,可为要求严苛的存储和计算工作负载带来出色性能,同时显著降低TCO。
如今的计算工作负载比过去规模更大、更复杂、更多样化。科学计算、人工智能 (AI)、机器学习(ML)、数据分析和其他专门任务的爆发式增长正在推动数据量呈指数级增长。而处理这些数据不仅需要大量算力,还需要具备低时延、高带宽的数据存取能力。
计算存储
(Computational Storage)
随着存储市场规模的扩大,我们需要新的技术和解决方案来传输、管理和保护已存储的数据。要增加存储容量,可视化、数据保护、数据安全(加密)和数据压缩等存储处理功能必不可少。然而,这些功能常涉及多种需要消耗大量计算周期的基础设施服务。
过去,从 CPU 内核卸载基础设施功能的第一步是引入 SmartNIC。SmartNIC会使用 FPGA 来增强常规网卡 (NIC) 中以太网芯片组的性能。但“SmartNIC”这个词某种程度上已被赋予了太多含义,不同供应商提供的实现方案往往截然不同。不管怎样,SmartNIC 在最基础层面上可定义为可编程的网卡。换言之,SmartNIC 支持从 CPU 内核中卸载基础设施功能的数据路径部分。
近期,英特尔推出基于 FPGA 的基础设施处理单元(IPU),配备高端 FPGA 及紧密耦合的英特尔 至强 CPU 等高端处理器,将这一卸载过程提升至更高水平。IPU 是 SmartNIC 的演进产品,可视为“更智能的 SmartNIC”,它通过将能够处理数据路径功能的 FPGA 和能够处理控制路径功能的 CPU 相结合,可在更大程度上卸载主机系统上的工作负载。
英特尔 Agilex 7 FPGA 的高速收发器、高密度逻辑和大内存,结合英特尔及其合作伙伴提供的知识产权 (IP) 解决方案,可帮助开发人员轻松创建理想的在线、近线和离线存储解决方案。
在数据中心领域,FPGA 可提供数据分析、AI、智能网络、超融合存储等功能实现加速所需的低时延卸载能力。FPGA 支持内联、旁路和多功能处理模式,通过减少复杂的瓶颈问题来卸载 CPU 的工作负载(图 1)。
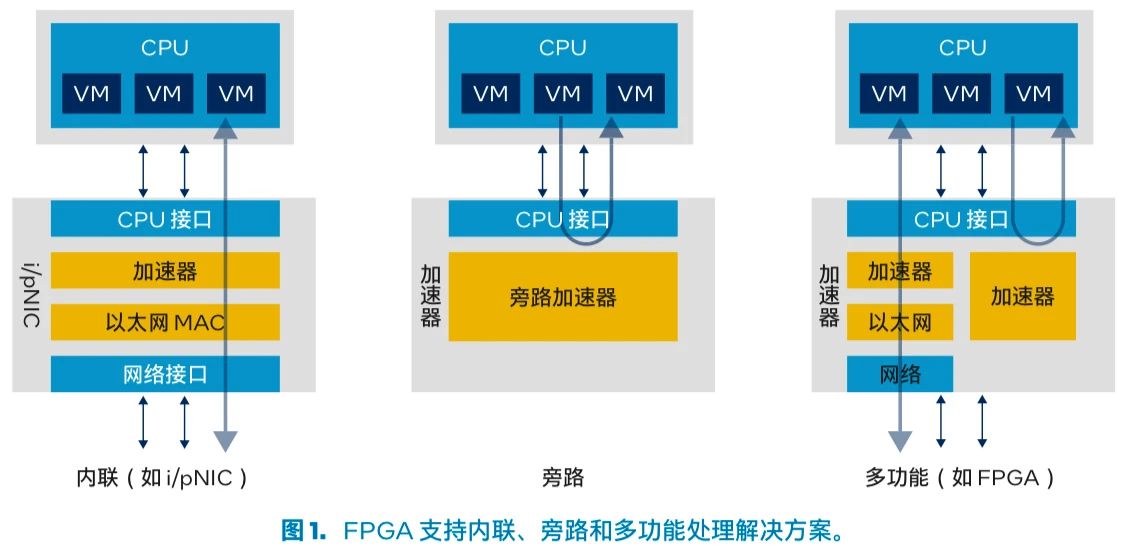
图 1. FPGA 支持内联、旁路和多功能处理解决方案。
就计算存储 (CS) 这一全新存储范式而言,系统架构的特点是将计算存储功能 (CSF)接入存储设备本身,进而卸载主机处理器上的工作负载,减少数据传输。使用这种架构,CSF 计算资源可以部署于固态盘 (SSD) 存储设备本身[在这种情况下,这些设备将归类为计算存储设备 (CSD)],或者部署在位于固态盘和主机之间的设备上,例如基于 FPGA 的加速器、SmartNIC 或 IPU。
基于 FPGA 的加速器可以为包括压缩和解压缩、加密和解密、SQL 查询以及图算法(中心性算法、寻路算法、社区检测算法等)在内的更多功能加速。
另一个潜在的应用是数据转码。例如,很多数据库目前都在采用开源内存格式 Apache Arrow(一种与语言无关的软件框架,用于开发处理列式数据的数据分析应用),因为它有助于在现代 CPU 和 GPU 硬件上进行高效的数据分析操作。此外,还有开源的磁盘数据存储格式 Apache Parquet。该存储格式提供高效的数据压缩和编码方案,能够以更强的性能,批量处理复杂的数据。可以预见,Apache Arrow 和 Apache Parquet 之间的数据转码将变得越来越重要。
Eideticom NoLoad 解决方案释放
第四代英特尔 至强 可扩展处理器强大性能
如前所述,计算存储带来的助益能够提升应用的性能和/或减少主机 CPU 内核用量,而释放出来的内核资源可用于执行其他创收任务。这可以提升基础设施效率,降低 TCO。
Eideticom 是专为数据中心存储或计算工作负载开发计算存储解决方案的领航企业,同时也是英特尔的合作伙伴之一1。Eideticom NoLoad 解决方案是一种基于 NVM Express (NVMe)的计算存储处理器 (CSP)。NoLoad 计算存储解决方案打破了处理存储密集型或计算密集型工作负载时以 CPU 为中心的计算系统面临的诸多限制。
NoLoad 解决方案现已量产并且正在出货,它基于 Eideticom 硬件合作伙伴多种外形规格,如 BittWare 的 IA-220-U22 U. 2 模块和 IA-420F3 卡——二者均采用了可通过 PCIe 4.0 与主机 CPU 进行通信的英特尔 Agilex 7 FPGA(图 2)。
NoLoad 具备一整套功能,包括压缩和解压缩、加密和解密、去重和数据分析。
作为“金融科技”的集大成者,FSI将是 NoLoad 技术的一大受益者。FSI是指在交付金融服务方面使用新技术与传统金融方法展开竞争的公司。AI、区块链、云计算和大数据被视为 FSI 的 “ABCD”(四大关键领域)。
FSI 分析用例的
基准测试
近期,我们通过一项基准测试对在两种不同计算环境中执行的典型高端 FSI 任务进行了比较。该真实场景示例配备了一款性能出色、软件定义的数据包捕获与分析引擎。
基准测试场景 1 仅在两个第四代英特尔 至强 可扩展处理器[之前代号 Sapphire Rapids (SPR)] 上的软件中运行。场景 2 则利用基于 FPGA 的加速器使 CPU 性能得到增强,且所有这些设备均接入 Eideticom NoLoad 解决方案。
FSI 任务涉及对 1 GB 数据文件中的股票市场数据执行压缩和解压缩。
场景 1 的硬件配备的是 2 个主频为 2 GHz 的第四代英特尔 至强 可扩展处理器(双路平台)(图 3)。每个 CPU 包含 56 个内核,每个内核对应两个线程,因此共有 224 个可用内核。
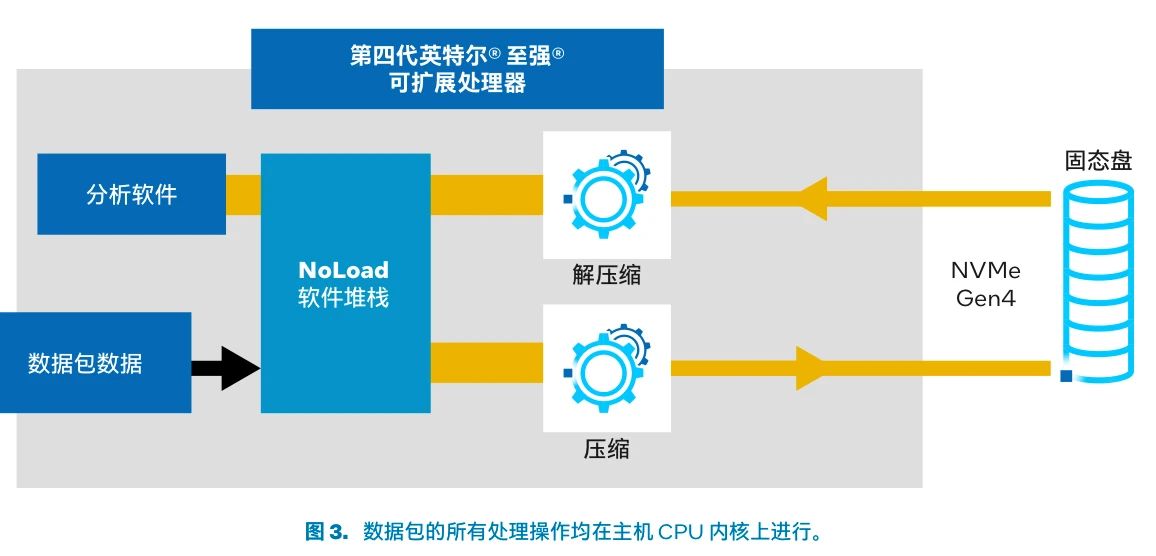
图 3. 数据包的所有处理操作均在主机 CPU 内核上进行。
场景 2 的硬件(图 4)使用了在 CPU 和基于 FPGA 的加速器上实现的 NoLoad 解决方案。用于压缩/解压缩的是 2 个 IA-220-U2 卡。
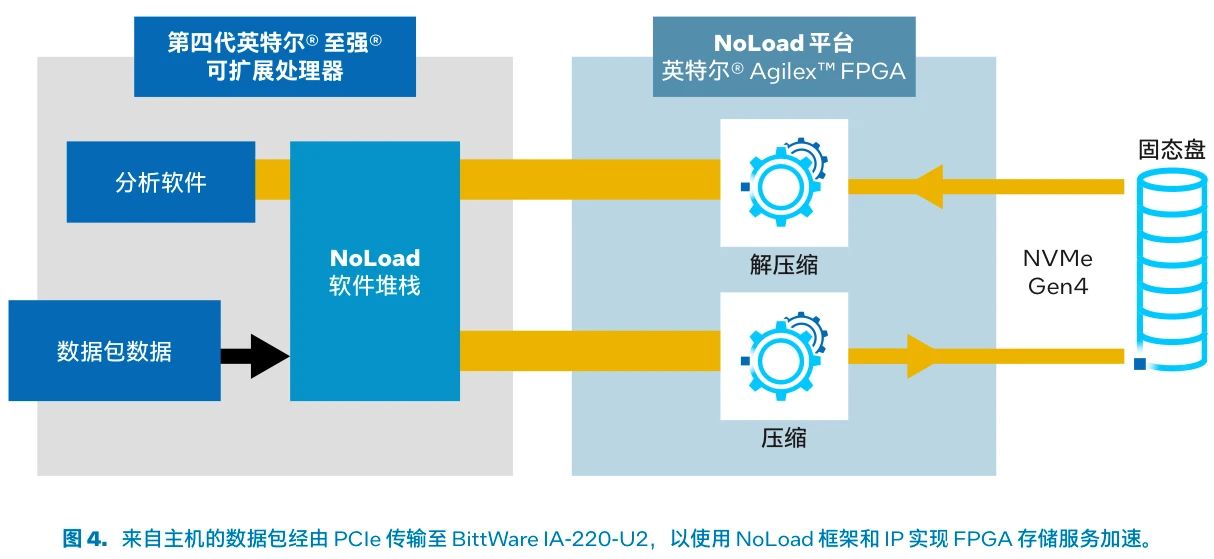
图 4. 来自主机的数据包经由 PCIe 传输至 BittWare IA-220-U2,以使用 NoLoad 框架和 IP 实现 FPGA 存储服务加速。
在这一基准测试中,数据包经压缩后写入固态盘阵列。NoLoad 软件堆栈支持在文件系统、内核空间或用户空间中使用 NoLoad 压缩和解压缩服务。
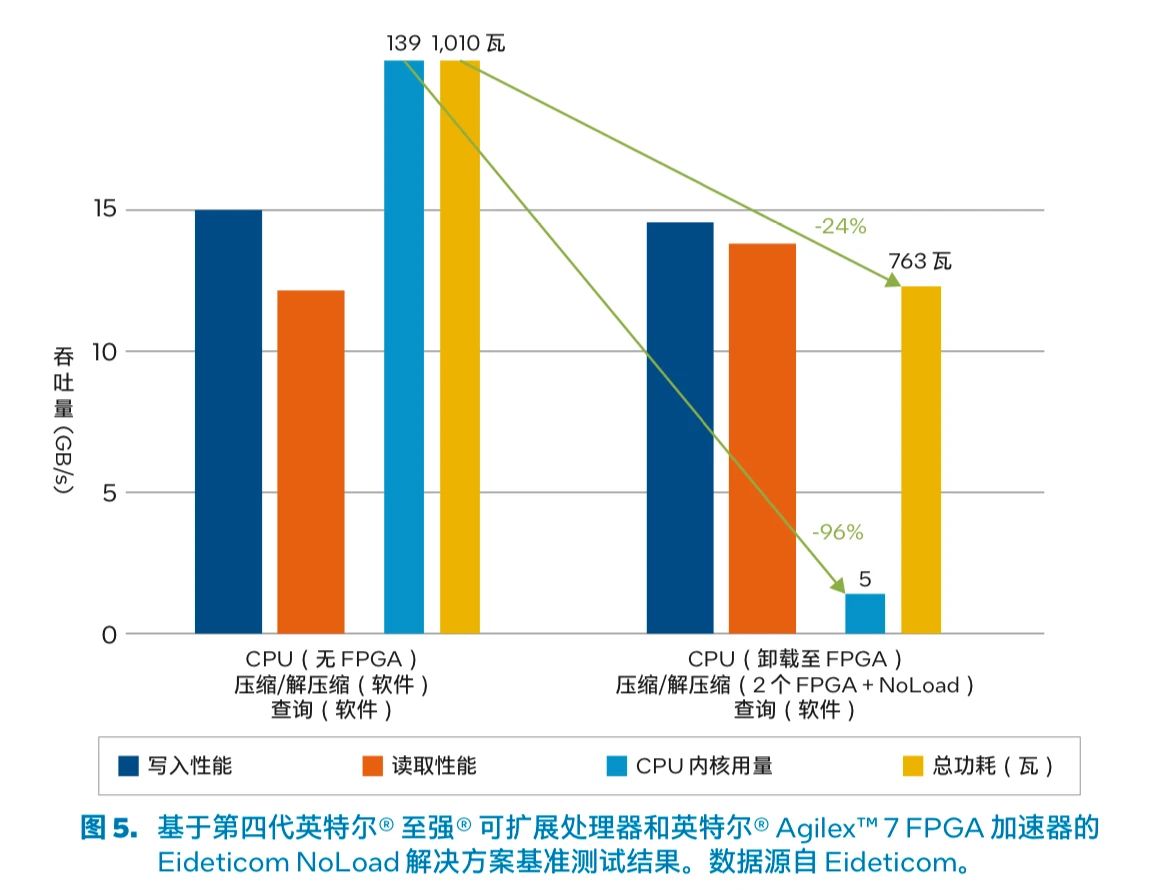
图 5. 基于第四代英特尔 至强 可扩展处理器和英特尔 Agilex 7 FPGA 加速器的 Eideticom NoLoad 解决方案基准测试结果。数据源自 Eideticom。
基准测试结果
分析对比场景 1 和场景 2 中 3 个关键指标(吞吐性能、CPU 内核用量和总功耗)的测试结果(图 5)可以清楚地看到,虽然基于 FPGA 的加速器的测试场景中性能几乎相同,但所使用的 CPU 内核数量大大减少,功耗也更低。FPGA 场景的总功耗为系统总功耗,包括 CPU 内核、NMVe 存储和两个 FPGA 卡。FPGA 卸载 能力结合 NoLoad 解决方案释放的 CPU 内核现在可用于执行其他任务或工作负载。
CPU内核用量减少96%(越低越好) 功耗降低24%(越低越好)
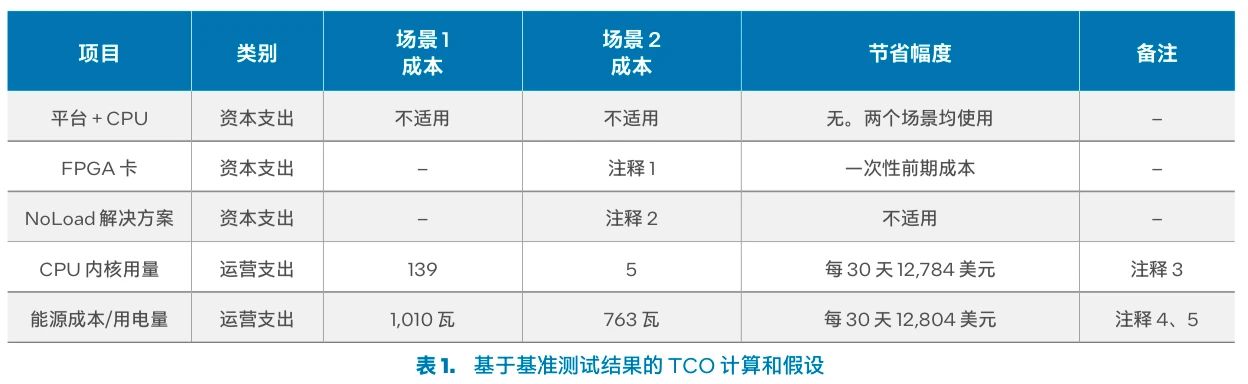
表 1. 基于基准测试结果的 TCO 计算和假设
注:
取决于 FPGA 卡(自主设计或从第三方供应商处购买现货)。
联系 Eideticom 获取 NoLoad 解决方案报价。
每个 CPU 内核的价值 =(每小时 1.06 美元/8 个内核)x 24 小时 x 30 天 = 95.40 美元。
假设电力成本 = 0.04 美元/千瓦。
假设两种场景均在 2 秒内完成操作。
TCO 节省情况估算
表 1 中从财务角度对使用基于 FPGA 的加速器的测试场景进行了考量。我们使用亚马逊云服务 EC2 实例的价格代表每个 CPU 内核的价值。基于亚马逊 EC2 F1 实例(提供基于 FPGA 的加速器的虚拟云服务 + 每 CPU 内核服务),我们假设每小时成本为 1.06 美元4。这一成本包含使用 1 个 FPGA 和 8 个虚拟 CPU 内核的费用,不过为了简化计算,假设该价格仅适用于 CPU 内核。
第四代英特尔 至强 可扩展处理器
第四代英特尔 至强 可扩展处理器专为快速增长的计算密集型和内存密集型工作负载实现更高性能而设计。
通过内置加速器和软件优化,上一代英特尔 至强 可扩展处理器已被证明可以在真实场景下的目标工作负载上实现出色的每瓦性能5。这不但可以提高 CPU 利用率、降低功耗、提升投资回报率(ROI),而且还能帮助企业实现可持续发展目标。
第四代英特尔 至强 可扩展处理器内置更多加速器,可为AI、数据分析、网络、存储和科学计算等快速增长的工作负载带来更大的性能和能效优势。为实现新的内置加速器功能,英特尔还为生态系统提供了操作系统级软件、库和 API 支持。值得一提的是,全新英特尔 至强 可扩展处理器还具备其他一些重要特性,包括支持 DDR5、PCI Express 5.0 和 Compute Express Link (CXL) v1.1。
英特尔 Agilex 7 FPGA
从数据中心到网络,再到边缘,FPGA 在现代应用中发挥着越来越重要的作用。FPGA 的灵活性、出色能效、大规模并行架构和高输入/输出 (I/O) 带宽使其在加速和/或卸载AI、存储和网络等广泛任务方面非常具有吸引力。这些应用中有很多都对内存提出了严苛要求(包括内存的容量、带宽、时延和能效)。为了满足这些应用的严苛要求,英特尔开发了英特尔 Agilex 7 FPGA 和 SoC FPGA(图 6)。
英特尔 Agilex 7 FPGA I 系列6 采用了英特尔的 10 纳米 SuperFin 技术,专为带宽密集型应用打造。这些 FPGA 和 SoC FPGA 包含支持外部 DDR4 内存的硬核化控制器,同时还支持 FPGA 领域首个 CXL 硬核 IP,使开发人员能够将时延敏感型功能通过 CXL 互联技术卸载至加速器上。
英特尔 Agilex 7 FPGA M 系列7 是第一款基于英特尔 7 制程工艺实现,并配备有封装 HBM2e 内存的英特尔 Agilex FPGA。英特尔 7 制程工艺可实现更高的可编程逻辑结构容量和性能,功耗也更低。硬核化控制器可支持 DDR5 和 LPDDR5 等先进的内存技术。
英特尔 Agilex 7 FPGA 和 SoC FPGA 可带来出色的 I/O 带宽(这对于当今需要处理海量数据负载的系统而言至关重要),收发器数据速率高达 116 Gbps,并可支持 PCIe 5.0 和 CXL 1.1/2.0。
总结
如今的计算工作负载比过去规模更大、更复杂、更多样化。通过将全新英特尔 产品与 Eideticom 和 Bittware 等合作伙伴的创新解决方案相结合,客户可显著降低目标用例或工作负载的 TCO。
在很多情况下,将算法密集型和时延敏感型功能卸载至基于英特尔 Agilex FPGA 的加速器上,可释放主机 CPU 内核,用于执行其他创收任务,使第四代英特尔 至强 可扩展处理器发挥更大的价值。FSI 正是众多从中受益的用例之一。
未来,Eideticon Noload解决方案还将移植到更高版本的 BittWare 卡(IA-440i8)上,这么做可能会将用于此 FSI 用例的 FPGA 卡从 2 个减至 1 个。
审核编辑:汤梓红
-
处理器
+关注
关注
68文章
19523浏览量
231768 -
英特尔
+关注
关注
61文章
10061浏览量
172810 -
cpu
+关注
关注
68文章
10942浏览量
213784 -
存储
+关注
关注
13文章
4401浏览量
86400 -
人工智能
+关注
关注
1799文章
48047浏览量
241946
原文标题:Eideticom NoLoad® 解决方案释放第四代英特尔® 至强® 可扩展处理器强大性能,更好支持存储计算
文章出处:【微信号:英特尔FPGA,微信公众号:英特尔FPGA】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐









 工商网监
工商网监
评论