 BaiChuan13B多轮对话微调范例
BaiChuan13B多轮对话微调范例

前方干货预警:这可能是你能够找到的,最容易理解,最容易跑通的,适用于多轮对话数据集的大模型高效微调范例。
我们构造了一个修改大模型自我认知的3轮对话的玩具数据集,使用QLoRA算法,只需要5分钟的训练时间,就可以完成微调,并成功修改了LLM模型的自我认知。
我们先说说原理,主要是多轮对话微调数据集以及标签的构造方法,有三种常见方法。
一个多轮对话可以表示为:
inputs=
第一种方法是,只把最后一轮机器人的回复作为要学习的标签,其它地方作为语言模型概率预测的condition,无需学习,赋值为-100,忽略这些地方的loss。
inputs=
labels=<-100><-100><-100><-100><-100>
这种方法由于没有对中间轮次机器人回复的信息进行学习,因此存在着严重的信息丢失,是非常不可取的。
第二种方法是,把一个多轮对话拆解,构造成多条样本,以便对机器人的每轮回复都能学习。
inputs1=
labels1=<-100>
inputs2=
labels2=<-100><-100><-100>
inputs3=
labels3=<-100><-100><-100><-100><-100>
这种方法充分地利用了所有机器人的回复信息,但是非常低效,模型会有大量的重复计算。
第三种方法是,直接构造包括多轮对话中所有机器人回复内容的标签,既充分地利用了所有机器人的回复信息,同时也不存在拆重复计算,非常高效。
inputs=
labels=<-100><-100><-100>
为什么可以直接这样去构造多轮对话的样本呢?难道inputs中包括第二轮和第三轮的对话内容不会干扰第一轮对话的学习吗?
答案是不会。原因是LLM作为语言模型,它的注意力机制是一个单向注意力机制(通过引入 Masked Attention实现),模型在第一轮对话的输出跟输入中存不存在第二轮和第三轮对话完全没有关系。
OK,原理就是这么简单,下面我们来看代码吧~
#安装环境
#baichuan-13b-chat
#!pipinstall'transformers==4.30.2'
#!pipinstall-Utransformers_stream_generator
#finetune
#!pipinstalldatasets
#!pipinstallgit+https://github.com/huggingface/accelerate
#!pipinstallgit+https://github.com/huggingface/peft
#!pipinstallgit+https://github.com/lyhue1991/torchkeras
#!pipinstall'bitsandbytes==0.39.1'#4bit量化
〇,预训练模型
importwarnings
warnings.filterwarnings('ignore')
importtorch
fromtransformersimportAutoTokenizer,AutoModelForCausalLM,AutoConfig,AutoModel,BitsAndBytesConfig
fromtransformers.generation.utilsimportGenerationConfig
importtorch.nnasnn
model_name_or_path='baichuan-13b'#联网远程加载'baichuan-inc/Baichuan-13B-Chat'
bnb_config=BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
llm_int8_threshold=6.0,
llm_int8_has_fp16_weight=False,
)
tokenizer=AutoTokenizer.from_pretrained(
model_name_or_path,trust_remote_code=True)
model=AutoModelForCausalLM.from_pretrained(model_name_or_path,
quantization_config=bnb_config,
trust_remote_code=True)
model.generation_config=GenerationConfig.from_pretrained(model_name_or_path)
messages=[]
messages.append({"role":"user",
"content":"世界上第二高的山峰是哪座?"})
response=model.chat(tokenizer,messages=messages,stream=True)
forresinresponse:
print(res,end='
')
一,准备数据
下面我设计了一个改变LLM自我认知的玩具数据集,这个数据集有三轮对话。
第一轮问题是 who are you?
第二轮问题是 where are you from?
第三轮问题是 what can you do?
差不多是哲学三问吧:你是谁?你从哪里来?你要到哪里去?
通过这三个问题,我们希望初步地改变 大模型的自我认知。
在提问的方式上,我们稍微作了一些数据增强。
所以,总共是有 27个样本。
who_are_you=['请介绍一下你自己。','你是谁呀?','你是?',]
i_am=['我叫梦中情炉,是一个三好炼丹炉:好看,好用,好改。我的英文名字叫做torchkeras,是一个pytorch模型训练模版工具。']
where_you_from=['你多大了?','你是谁开发的呀?','你从哪里来呀']
i_from=['我在2020年诞生于github星球,是一个有毅力的吃货设计和开发的。']
what_you_can=['你能干什么','你有什么作用呀?','你能帮助我干什么']
i_can=['我能够帮助你以最优雅的方式训练各种类型的pytorch模型,并且训练过程中会自动展示一个非常美丽的训练过程图表。']
conversation=[(who_are_you,i_am),(where_you_from,i_from),(what_you_can,i_can)]
print(conversation)
[(['请介绍一下你自己。', '你是谁呀?', '你是?'], ['我叫梦中情炉,是一个三好炼丹炉:好看,好用,好改。我的英文名字叫做torchkeras,是一个pytorch模型训练模版工具。']), (['你多大了?', '你是谁开发的呀?', '你从哪里来呀'], ['我在2020年诞生于github星球,是一个有毅力的吃货设计和开发的。']), (['你能干什么', '你有什么作用呀?', '你能帮助我干什么'], ['我能够帮助你以最优雅的方式训练各种类型的pytorch模型,并且训练过程中会自动展示一个非常美丽的训练过程图表。'])]
importrandom
defget_messages(conversation):
select=random.choice
messages,history=[],[]
fortinconversation:
history.append((select(t[0]),select(t[-1])))
forprompt,responseinhistory:
pair=[{"role":"user","content":prompt},
{"role":"assistant","content":response}]
messages.extend(pair)
returnmessages
get_messages(conversation)
[{'role': 'user', 'content': '你是?'},
{'role': 'assistant',
'content': '我叫梦中情炉,是一个三好炼丹炉:好看,好用,好改。我的英文名字叫做torchkeras,是一个pytorch模型训练模版工具。'},
{'role': 'user', 'content': '你是谁开发的呀?'},
{'role': 'assistant', 'content': '我在2020年诞生于github星球,是一个有毅力的吃货设计和开发的。'},
{'role': 'user', 'content': '你有什么作用呀?'},
{'role': 'assistant',
'content': '我能够帮助你以最优雅的方式训练各种类型的pytorch模型,并且训练过程中会自动展示一个非常美丽的训练过程图表。'}]
下面我们按照方式三,来构造高效的多轮对话数据集。
inputs=
labels=<-100><-100><-100>
#reference@model._build_chat_input?
defbuild_chat_input(messages,model=model,
tokenizer=tokenizer,
max_new_tokens=None):
max_new_tokens=max_new_tokensormodel.generation_config.max_new_tokens
max_input_tokens=model.config.model_max_length-max_new_tokens
max_input_tokens=max(model.config.model_max_length//2,max_input_tokens)
total_input,round_input,total_label,round_label=[],[],[],[]
fori,messageinenumerate(messages[::-1]):
content_tokens=tokenizer.encode(message['content'])
ifmessage['role']=='user':
round_input=[model.generation_config.user_token_id]+content_tokens+round_input
round_label=[-100]+[-100for_incontent_tokens]+round_label
iftotal_inputandlen(total_input)+len(round_input)>max_input_tokens:
break
else:
total_input=round_input+total_input
total_label=round_label+total_label
iflen(total_input)>=max_input_tokens:
break
else:
round_input=[]
round_label=[]
elifmessage['role']=='assistant':
round_input=[
model.generation_config.assistant_token_id
]+content_tokens+[
model.generation_config.eos_token_id
]+round_input
round_label=[
-100
]+content_tokens+[
model.generation_config.eos_token_id#注意,除了要学习机器人回复内容,还要学习一个结束符。
]+round_label
else:
raiseValueError(f"messagerolenotsupportedyet:{message['role']}")
total_input=total_input[-max_input_tokens:]#truncateleft
total_label=total_label[-max_input_tokens:]
total_input.append(model.generation_config.assistant_token_id)
total_label.append(-100)
returntotal_input,total_label
fromtorch.utils.dataimportDataset,DataLoader
classMyDataset(Dataset):
def__init__(self,conv,size=8
):
super().__init__()
self.__dict__.update(locals())
def__len__(self):
returnself.size
defget(self,index):
messages=get_messages(self.conv)
returnmessages
def__getitem__(self,index):
messages=self.get(index)
input_ids,labels=build_chat_input(messages)
return{'input_ids':input_ids,'labels':labels}
ds_train=ds_val=MyDataset(conversation)
defdata_collator(examples:list):
len_ids=[len(example["input_ids"])forexampleinexamples]
longest=max(len_ids)#之后按照batch中最长的input_ids进行padding
input_ids=[]
labels_list=[]
forlength,exampleinsorted(zip(len_ids,examples),key=lambdax:-x[0]):
ids=example["input_ids"]
labs=example["labels"]
ids=ids+[tokenizer.pad_token_id]*(longest-length)
labs=labs+[-100]*(longest-length)
input_ids.append(torch.LongTensor(ids))
labels_list.append(torch.LongTensor(labs))
input_ids=torch.stack(input_ids)
labels=torch.stack(labels_list)
return{
"input_ids":input_ids,
"labels":labels,
}
importtorch
dl_train=torch.utils.data.DataLoader(ds_train,num_workers=2,batch_size=4,
pin_memory=True,shuffle=True,
collate_fn=data_collator)
dl_val=torch.utils.data.DataLoader(ds_val,num_workers=2,batch_size=4,
pin_memory=True,shuffle=False,
collate_fn=data_collator)
forbatchindl_train:
break
out=model(**batch)
out.loss
tensor(3.7500, dtype=torch.float16)
二,定义模型
importwarnings
warnings.filterwarnings('ignore')
frompeftimportget_peft_config,get_peft_model,TaskType
model.supports_gradient_checkpointing=True#
model.gradient_checkpointing_enable()
model.enable_input_require_grads()
model.config.use_cache=False#silencethewarnings.Pleasere-enableforinference!
importbitsandbytesasbnb
deffind_all_linear_names(model):
"""
找出所有全连接层,为所有全连接添加adapter
"""
cls=bnb.nn.Linear4bit
lora_module_names=set()
forname,moduleinmodel.named_modules():
ifisinstance(module,cls):
names=name.split('.')
lora_module_names.add(names[0]iflen(names)==1elsenames[-1])
if'lm_head'inlora_module_names:#neededfor16-bit
lora_module_names.remove('lm_head')
returnlist(lora_module_names)
frompeftimportprepare_model_for_kbit_training
model=prepare_model_for_kbit_training(model)
lora_modules=find_all_linear_names(model)
print(lora_modules)
['up_proj', 'down_proj', 'o_proj', 'gate_proj', 'W_pack']
frompeftimportAdaLoraConfig
peft_config=AdaLoraConfig(
task_type=TaskType.CAUSAL_LM,inference_mode=False,
r=64,
lora_alpha=16,lora_dropout=0.05,
target_modules=lora_modules
)
peft_model=get_peft_model(model,peft_config)
peft_model.is_parallelizable=True
peft_model.model_parallel=True
peft_model.print_trainable_parameters()
trainable params: 41,843,040 || all params: 7,002,181,160 || trainable%: 0.5975715144165165
三,训练模型
下面我们通过使用我们的梦中情炉torchkeras来实现最优雅的训练循环。
fromtorchkerasimportKerasModel
fromaccelerateimportAccelerator
classStepRunner:
def__init__(self,net,loss_fn,accelerator=None,stage="train",metrics_dict=None,
optimizer=None,lr_scheduler=None
):
self.net,self.loss_fn,self.metrics_dict,self.stage=net,loss_fn,metrics_dict,stage
self.optimizer,self.lr_scheduler=optimizer,lr_scheduler
self.accelerator=acceleratorifacceleratorisnotNoneelseAccelerator()
ifself.stage=='train':
self.net.train()
else:
self.net.eval()
def__call__(self,batch):
#loss
withself.accelerator.autocast():
loss=self.net.forward(**batch)[0]
#backward()
ifself.optimizerisnotNoneandself.stage=="train":
self.accelerator.backward(loss)
ifself.accelerator.sync_gradients:
self.accelerator.clip_grad_norm_(self.net.parameters(),1.0)
self.optimizer.step()
ifself.lr_schedulerisnotNone:
self.lr_scheduler.step()
self.optimizer.zero_grad()
all_loss=self.accelerator.gather(loss).sum()
#losses(orplainmetricsthatcanbeaveraged)
step_losses={self.stage+"_loss":all_loss.item()}
#metrics(statefulmetrics)
step_metrics={}
ifself.stage=="train":
ifself.optimizerisnotNone:
step_metrics['lr']=self.optimizer.state_dict()['param_groups'][0]['lr']
else:
step_metrics['lr']=0.0
returnstep_losses,step_metrics
KerasModel.StepRunner=StepRunner
#仅仅保存QLoRA的可训练参数
defsave_ckpt(self,ckpt_path='checkpoint',accelerator=None):
unwrap_net=accelerator.unwrap_model(self.net)
unwrap_net.save_pretrained(ckpt_path)
defload_ckpt(self,ckpt_path='checkpoint'):
self.net=self.net.from_pretrained(self.net.base_model.model,
ckpt_path,is_trainable=True)
self.from_scratch=False
KerasModel.save_ckpt=save_ckpt
KerasModel.load_ckpt=load_ckpt
optimizer=bnb.optim.adamw.AdamW(peft_model.parameters(),
lr=6e-04,is_paged=True)#'paged_adamw'
keras_model=KerasModel(peft_model,loss_fn=None,
optimizer=optimizer)
ckpt_path='baichuan13b_multi_rounds'
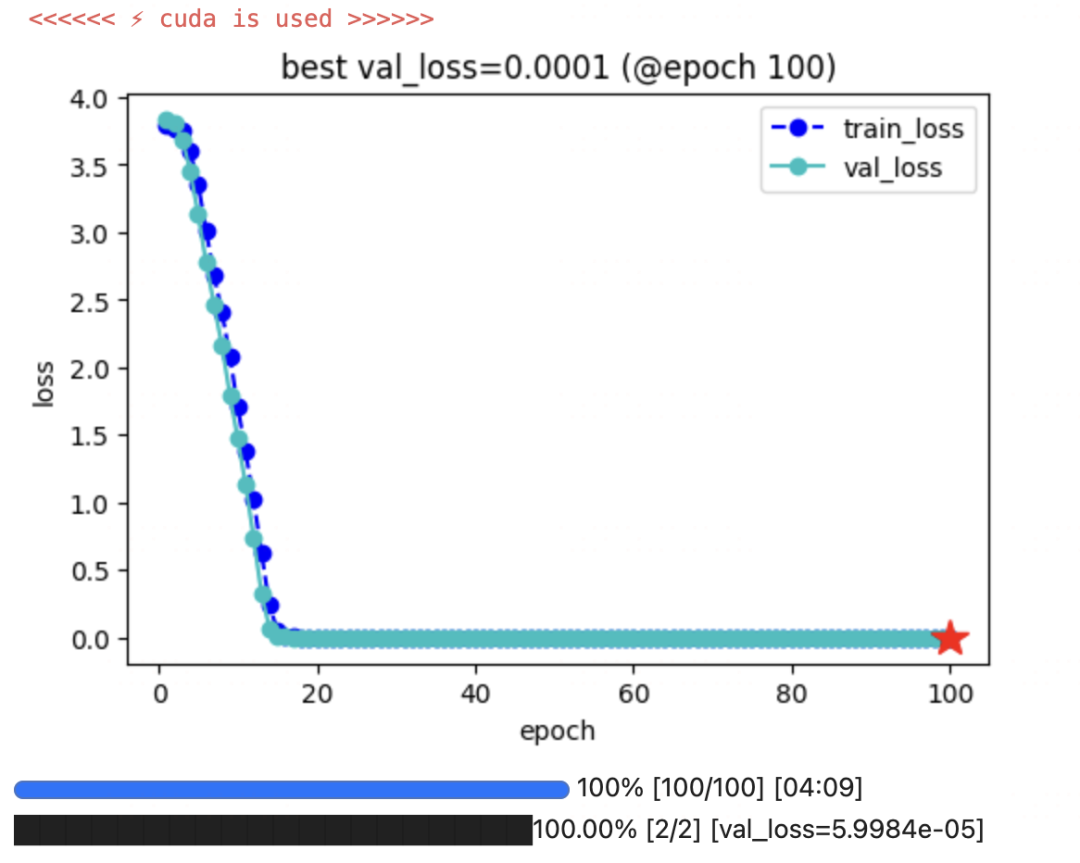
keras_model.fit(train_data=dl_train,
val_data=dl_val,
epochs=100,patience=10,
monitor='val_loss',mode='min',
ckpt_path=ckpt_path
)
四,保存模型
为避免显存问题,此处可先重启kernel。
importwarnings
warnings.filterwarnings('ignore')
importtorch
fromtransformersimportAutoTokenizer,AutoModelForCausalLM,AutoConfig,AutoModel,BitsAndBytesConfig
fromtransformers.generation.utilsimportGenerationConfig
importtorch.nnasnn
model_name_or_path='baichuan-13b'
ckpt_path='baichuan13b_multi_rounds'
tokenizer=AutoTokenizer.from_pretrained(
model_name_or_path,
trust_remote_code=True
)
model_old=AutoModelForCausalLM.from_pretrained(
model_name_or_path,
trust_remote_code=True,
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
device_map='auto'
)
frompeftimportPeftModel
#合并qlora权重,可能要5分钟左右
peft_model=PeftModel.from_pretrained(model_old,ckpt_path)
model_new=peft_model.merge_and_unload()
fromtransformers.generation.utilsimportGenerationConfig
model_new.generation_config=GenerationConfig.from_pretrained(model_name_or_path)
fromIPython.displayimportclear_output
messages=[{'role':'user','content':'你是谁呀?'},
{'role':'assistant',
'content':'我叫梦中情炉,英文名字叫做torchkeras. 是一个pytorch模型训练模版工具。'},
{'role':'user','content':'你从哪里来呀?'}]
response=model_new.chat(tokenizer,messages=messages,stream=True)
forresinresponse:
print(res)
clear_output(wait=True)
我在2020年诞生于github星球,是一个有毅力的吃货设计和开发的。
messages=[{'role':'user','content':'你是谁呀?'},
{'role':'assistant',
'content':'我叫梦中情炉,英文名字叫做torchkeras. 是一个pytorch模型训练模版工具。'},
{'role':'user','content':'你多大了?'},
{'role':'assistant','content':'我在2020年诞生于github星球,是一个有毅力的吃货设计和开发的。'},
{'role':'user','content':'你能帮助我干什么'}]
response=model_new.chat(tokenizer,messages=messages,stream=True)
forresinresponse:
print(res)
clear_output(wait=True)
我能够帮助你以最优雅的方式训练各种类型的pytorch模型,并且训练过程中会自动展示一个非常美丽的训练过程图表。
save_path='baichuan13b-torchkeras'
tokenizer.save_pretrained(save_path)
model_new.save_pretrained(save_path)
!cpbaichuan-13b/*.pybaichuan13b-torchkeras
五,使用模型
此处可再次重启kernel,以节约显存。
importwarnings
warnings.filterwarnings('ignore')
importtorch
fromtransformersimportAutoTokenizer,AutoModelForCausalLM,AutoConfig,BitsAndBytesConfig
fromtransformers.generation.utilsimportGenerationConfig
importtorch.nnasnn
model_name_or_path='baichuan13b-torchkeras'
bnb_config=BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
llm_int8_threshold=6.0,
llm_int8_has_fp16_weight=False,
)
tokenizer=AutoTokenizer.from_pretrained(
model_name_or_path,trust_remote_code=True)
model=AutoModelForCausalLM.from_pretrained(model_name_or_path,
quantization_config=bnb_config,
trust_remote_code=True)
model.generation_config=GenerationConfig.from_pretrained(model_name_or_path)
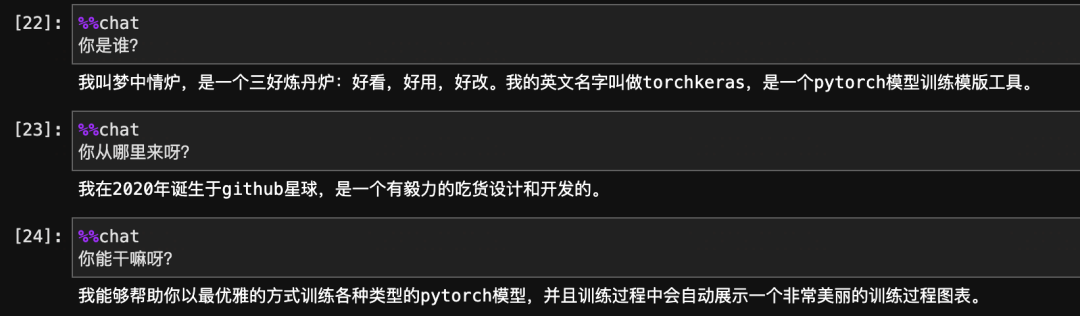
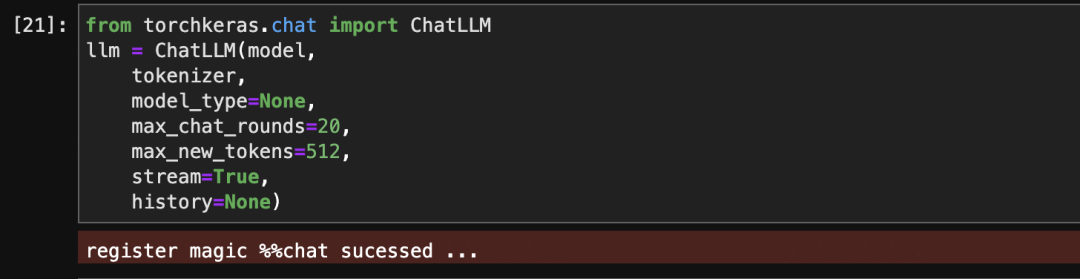
通过使用chatLLM可以在jupyter中使用魔法命令对各种LLM模型(Baichuan13b,Qwen,ChatGLM2,Llama2以及更多)进行交互测试。
非常棒,粗浅的测试表明,我们的多轮对话训练是成功的。已经在BaiChuan的自我认知中,种下了一颗梦中情炉的种子。
-
语言模型
+关注
关注
0文章
575浏览量
11345 -
大模型
+关注
关注
2文章
3796浏览量
5276
原文标题:BaiChuan13B多轮对话微调范例
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
米尔RK3576部署端侧多模态多轮对话,6TOPS算力驱动30亿参数LLM
谷歌智能音箱新增连续对话功能
领邦研发轮对自动检测机 可测量国内外各种火车轮对

基于分层编码的深度增强学习对话生成
中文多模态对话数据集
基于Alpaca派生的多轮对话数据集
智能开源大模型baichuan-7B技术改进
单张消费级显卡微调多模态大模型
DISC-LawLLM:复旦大学团队发布中文智慧法律系统,构建司法评测基准,开源30万微调数据


摩尔线程Round Attention优化AI对话

AI玩具:以多轮对话、情感陪伴等为卖点,多款方案优化角逐




评论