 基于ChatGLM2和OpenVINO™打造中文聊天助手
基于ChatGLM2和OpenVINO™打造中文聊天助手
基于ChatGLM2和OpenVINO™打造中文聊天助手
ChatGLM 是由清华大学团队开发的是一个开源的、支持中英双语的类 ChatGPT 大语言模型,它能生成相当符合人类偏好的回答, ChatGLM2 是开源中英双语对话模型 ChatGLM 的第二代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,通过全面升级的基座模型,带来了更强大的性能,更长的上下文,并且该模型对学术研究完全开放,登记后亦允许免费商业使用。接下来我们分享一下如何基于 ChatGLM2-6B 和 OpenVINO™ 工具套件来打造一款聊天机器人。
注1:由于 ChatGLM2-6B 对在模型转换和运行过程中对内存的占用较高,推荐使用支持 128Gb 以上内存的的服务器终端作为测试平台。
注2:本文仅分享部署 ChatGLM2-6B 原始预训练模型的方法,如需获得自定义知识的能力,需要对原始模型进行 Fine-tune;如需获得更好的推理性能,可以使用量化后的模型版本。
OpenVINO™
模型导出
**第一步,**我们需要下载 ChatGLM2-6B 模型,并将其导出为 OpenVINO™ 所支持的IR格式模型进行部署,由于 ChatGLM 团队已经将 6B 版本的预训练模型发布在 Hugging Face 平台上,支持通过 Transformer 库进行推理,但不支持基于Optimum 的部署方式(可以参考Llama2的文章),因此这里我们需要提取 Transformer 中的 ChatGLM2 的 PyTorch 模型对象,并实现模型文件的序列化。主要步骤可以分为:
1.获取 PyTorch 模型对象
通过Transformer库获取PyTorch对象,由于目前Transformer中原生的ModelForCausalLM类并不支持ChatGLM2模型架构,因此需要添加trust_remote_code=True参数,从远程模型仓库中获取模型结构信息,并下载权重。

2.模拟并获取模型的输入输出参数
在调用 torch.onnx.export 接口将模型对象导出为 ONNX 文件之前,我们首先需要获取模型的输入和输出信息。由于 ChatGLM2 存在 KV cache 机制,因此这个步骤中会模拟第一次文本生成时不带 cache 的输入,并将其输出作为第二次迭代时的 cache 输入,再通过第二次迭代来验证输入数据是否完整。以下分别第一次和第二次迭代的 PyTorch 代码: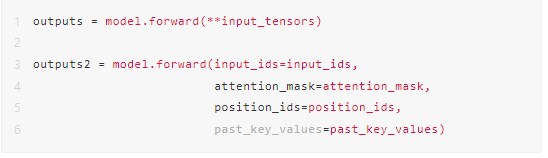
3.导出为ONNX格式
在获取完整的模型输入输出信息后,我们可以利用 torch.onnx.export 接口将模型导出为 ONNX 文件,如果通过模型结构可视化工具查看该文件的话,不难发现原始模型对象中 attention_mask 这个 input layer 消失了,个人理解是因为 attention_mask 对模型的输出结果没有影响,并且其实际功能已经被 position_ids 代替了,所以 ONNX 在转化模型的过程中自动将其优化掉了。
4.利用 OpenVINO™ Model Optimizer 进行格式转换
最后一步可以利用 OpenVINO™ 的 Model Optimizer 工具将模型文件转化为 IR 格式,并压缩为 FP16 精度,将较原始 FP32 模式,FP16 模型可以在保证模型输出准确性的同时,减少磁盘占用,并优化运行时的内存开销。
**模型部署 **
当完成 IR 模型导出后,我们首先需要构建一个简单的问答系统 pipeline,测试效果。如下图所示, Prompt 提示会送入 Tokenizer 进行分词和词向量编码,然后有 OpenVINO™ 推理获得结果(蓝色部分),来到后处理部分,我们会把推理结果进行进一步的采样和解码,最后生成常规的文本信息。这里 Top-K 以及 Top-P作 为答案的筛选方法,最终从筛选后的答案中进行随机采样输出结果。

图:ChatGLM2 问答任务流程
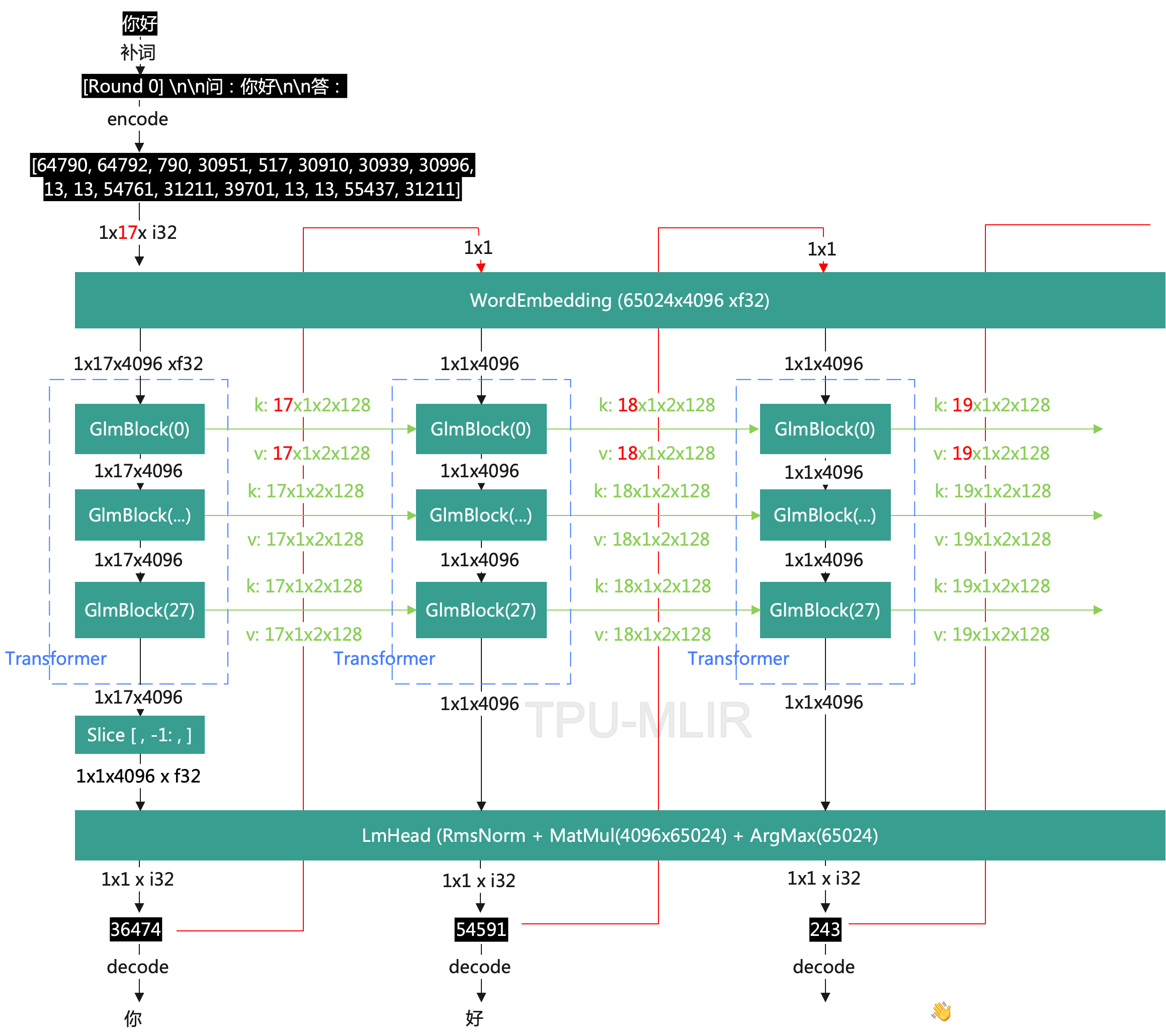
整个 pipeline 的大部分代码都可以套用文本生成任务的常规流程,其中比较复杂一些的是 OpenVINO™ 推理部分的工作,由于 ChatGLM2-6B 文本生成任务需要完成多次递归迭代,并且每次迭代会存在 cache 缓存,因此我们需要为不同的迭代轮次分别准备合适的输入数据。接下来我们详细解构一下模型的运行逻辑:
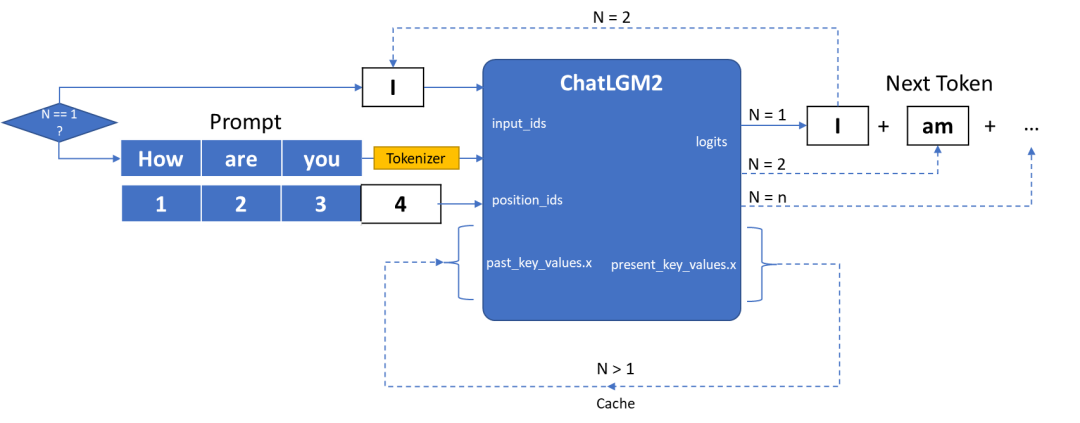
图:ChatGLM2-6B模型输入输出原理
ChatGLM2 的 IR 模型的输入主要由三部分组成:
**· input_ids **是向量化后的提示输入
**· position_ids **用来描述输入的位置信息,例如原始的 prompt 数据为 “How are you”, 那这是 position_ids 就是[[1,2,3]], 如果输入为原始 prompt 的后的第一个被预测词:”I”, 那 position_ids 则为[[4]], 以此类推。
**· past_key_values.x **是由一连串数据构成的集合,用来保存每次迭代过程中可以被共享的 cache.
ChatGLM2 的 IR 模型的输出则由两部分组成:
**· Logits **为模型对于下一个词的预测,或者叫 next token
· present_key_values.x则可以被看作 cache,直接作为下一次迭代的 past_key_values.x 值
整个 pipeline 在运行时会对 ChatGLM2 模型进行多次迭代,每次迭代会递归生成对答案中下一个词的预测,直到最终答案长度超过预设值 max_sequence_length,或者预测的下一个词为终止符 eos_token_id。
· 第一次迭代
如图所示在一次迭代时(N=1)input_ids 为提示语句,此时我们还需要利用 Tokenizer 分词器将原始文本转化为输入向量,而由于此时无法利用 cache 进行加速,past_key_values.x 系列向量均为空值,这里我们会初始化一个维度为[0,1,2,128]的空值矩阵
· 第N次迭代
当第一次迭代完成后,会输出对于答案中第一个词的预测 Logits,以及 cache 数据,我们可以将这个 Logits 作为下一次迭代的 input_ids 再输入到模型中进行下一次推理(N=2), 此时我们可以利用到上次迭代中的 cache 数据也就是 present_key_values.x,而无需每次将完整的“提示+预测词”一并送入模型,从而减少一些部分重复的计算量。这样周而复始,将当前的预测词所谓一次迭代的输入,就可以逐步生成所有的答案。
详细代码如下,这里可以看到如果 past_key_values 等于 None 就是第一次迭代,此时需要构建一个值均为空的 past_key_values 系列,如果不为 None 则会将真实的 cache 数据加入到输入中。

测试输出如下:
命令:python3 generate_ov.py -m "THUDM/chatglm2-6b" -p "请介绍一下上海?"
ChatGLM2-6B 回答:
“上海是中国的一个城市,位于东部沿海地区,是中国重要的经济、文化和科技中心之一。
上海是中国的一个重要港口城市,是中国重要的进出口中心之一,也是全球著名的金融中心之一。上海是亚洲和全球经济的中心之一,拥有许多国际知名金融机构和跨国公司总部。
上海是一个拥有悠久历史和丰富文化的城市。上海是中国重要的文化城市之一,拥有许多历史文化名胜和现代文化地标。上海是中国的一个重要旅游城市,吸引了大量国内外游客前来观光旅游。“
上海是一个拥有重要经济功能的现代城市。“
OpenVINO™
聊天助手
官方示例中 ChatGLM2 的主要用途为对话聊天,相较于问答模型模式中一问一答的形式,对话模式则需要构建更为完整的对话,此时模型在生成答案的过程中还需要考虑到之前对话中的信息,并将其作为 cache 数据往返于每次迭代过程中,因此这里我们需要额外设计一个模板,用于构建每一次的输入数据,让模型能够给更充分理解哪些是历史对话,哪些是新的对话问题。

图:ChatGLM2对话任务流程
这里的 text 模板是由“引导词+历史记录+当前问题(提示)”三部分构成:
· 引导词:描述当前的任务,引导模型做出合适的反馈
· 历史记录:记录聊天的历史数据,包含每一组问题和答案
· 当前问题:类似问答模式中的问题
我们采用 streamlit 框架构建构建聊天机器人的 web UI 和后台处理逻辑,同时希望该聊天机器人可以做到实时交互,实时交互意味着我们不希望聊天机器人在生成完整的文本后再将其输出在可视化界面中,因为这个需要用户等待比较长的时间来获取结果,我们希望在用户在使用过程中可以逐步看到模型所预测的每一个词,并依次呈现。因此我们需要创建一个可以被迭代的方法 generate_iterate,可以依次获取模型迭代过程中每一次的预测结果,并将其依次添加到最终答案中,并逐步呈现。
当完成任务构建后,我们可以通过 streamlit run chat_robot.py 命令启动聊天机器,并访问本地地址进行测试。这里选择了几个常用配置参数,方便开发者根据机器人的回答准确性进行调整:
· 系统提示词:用于引导模型的任务方向
**· max_tokens: **生成句子的最大长度。
· top-k:从置信度对最高的k个答案中随机进行挑选,值越高生成答案的随机性也越高。
**· top-p: **从概率加起来为 p 的答案中随机进行挑选, 值越高生成答案的随机性也越高,一般情况下,top-p 会在 top-k 之后使用。
· Temperature:从生成模型中抽样包含随机性, 高温意味着更多的随机性,这可以帮助模型给出更有创意的输出。如果模型开始偏离主题或给出无意义的输出,则表明温度过高。
注3:由于 ChatGLM2-6B 模型比较大,首次硬件加载和编译的时间会相对比较久
OpenVINO™
总结
作为当前最热门的双语大语言模型之一,ChatGLM2 凭借在各大基准测试中出色的成绩,以及支持微调等特性被越来越多开发者所认可和使用。利用 OpenVINO™ 构建 ChatGLM2 系列任务可以进一步提升其模型在英特尔平台上的性能,并降低部署门槛。
审核编辑:刘清
-
编码器
+关注
关注
45文章
3646浏览量
134687 -
向量机
+关注
关注
0文章
166浏览量
20887 -
cache技术
+关注
关注
0文章
41浏览量
1069 -
pytorch
+关注
关注
2文章
808浏览量
13240 -
ChatGPT
+关注
关注
29文章
1563浏览量
7775
原文标题:基于 ChatGLM2 和 OpenVINO™ 打造中文聊天助手 | 开发者实战
文章出处:【微信号:英特尔物联网,微信公众号:英特尔物联网】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
CoolPi CM5运行ChatGLM-MNN大语言模型
Coolpi CM5运行ChatGLM-MNN大语言模型
使用OpenVINO trade 2021版运行Face_recognition_demo时报错怎么解决?

云百件客服聊天助手-Windows版特性-云百件

清华系千亿基座对话模型ChatGLM开启内测
ChatGLM2-6B:性能大幅提升,8-32k上下文,推理提速42%,在中文榜单位列榜首

单样本微调给ChatGLM2注入知识
一个简单模型就让ChatGLM性能大幅提升 | 最“in”大模型
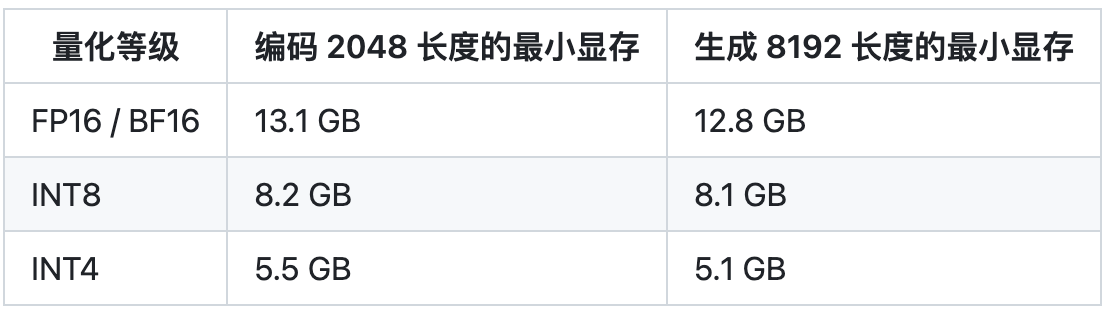
探索ChatGLM2在算能BM1684X上INT8量化部署,加速大模型商业落地

“行空板+大模型”——基于ChatGLM的多角色交互式聊天机器人
chatglm2-6b在P40上做LORA微调





 工商网监
工商网监
评论