 Meta发布一款可以使用文本提示生成代码的大型语言模型Code Llama
Meta发布一款可以使用文本提示生成代码的大型语言模型Code Llama
今天,Meta发布了Code Llama,一款可以使用文本提示生成代码的大型语言模型(LLM)。Code Llama在代码任务上是公开可用的LLM中最先进的,它有可能让当前开发者的工作流程更快更高效,也降低了学习编程的门槛。Code Llama有可能被用作一种生产力和教育工具,帮助程序员编写更健壮、更有文档的软件。
Code Llama是一个新的大型语言模型,专门用于生成代码,它基于Meta的Llama 2基础模型构建。它可以从自然语言提示生成代码。
Code Llama是免费的,可用于研究和商业用途。
Code Llama是基于Llama 2构建的,有三种模型:
Code Llama,基础的代码模型;
Code Llama - Python,专门针对Python;
以及Code Llama - Instruct,它是为了理解自然语言指令而微调的。
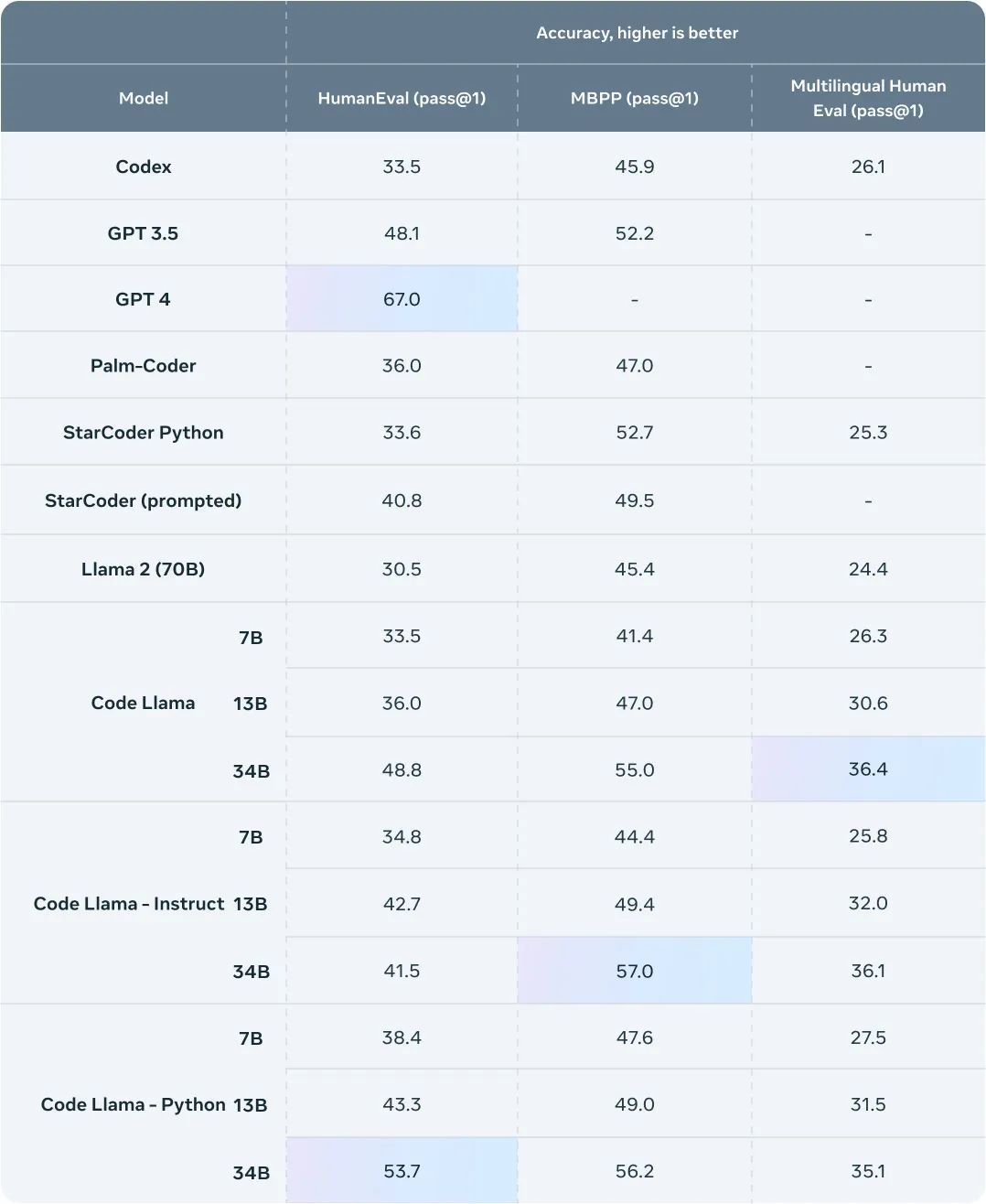
Code Llama在代码生成基准测试(如HumanEval和MBPP)上优于其他公开可用的模型。它与ChatGPT可媲美。
发布了三种大小的Code Llama模型 - 7B、13B和34B参数。34B模型具有最佳性能,但较小的模型更快。
Code Llama支持许多流行的编程语言,并可以处理长达10万个标记的输入上下文。
潜在的应用包括帮助开发人员更有效地编写、调试和记录代码。它还可以帮助降低学习编程的门槛。
Code Llama 工作原理
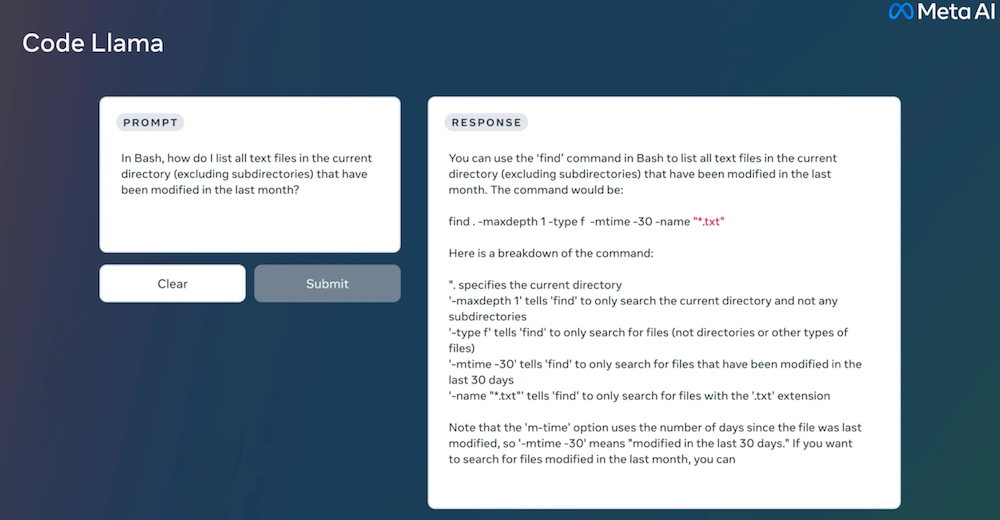
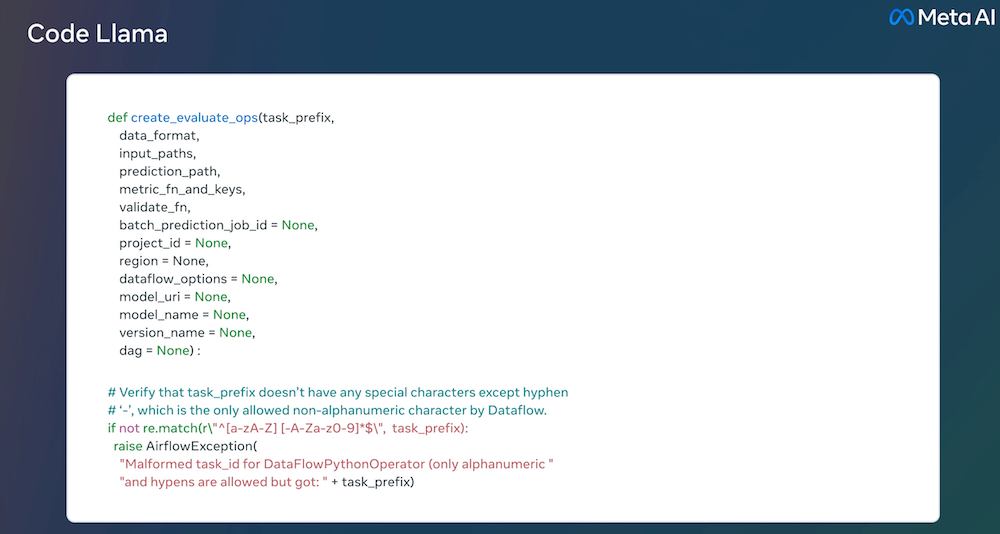
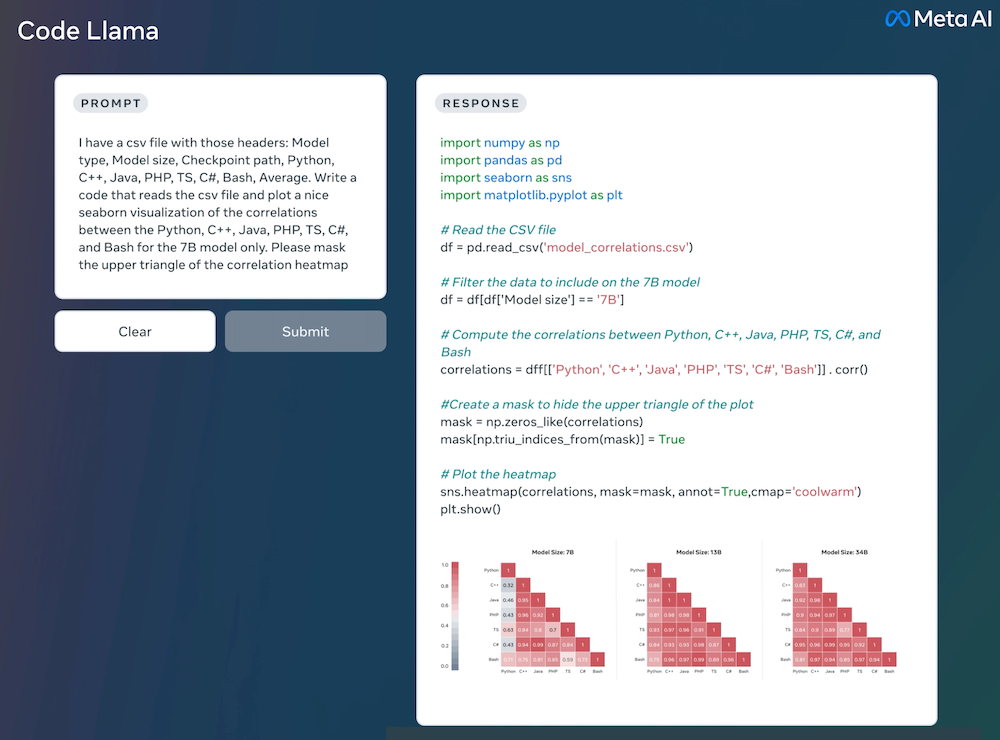
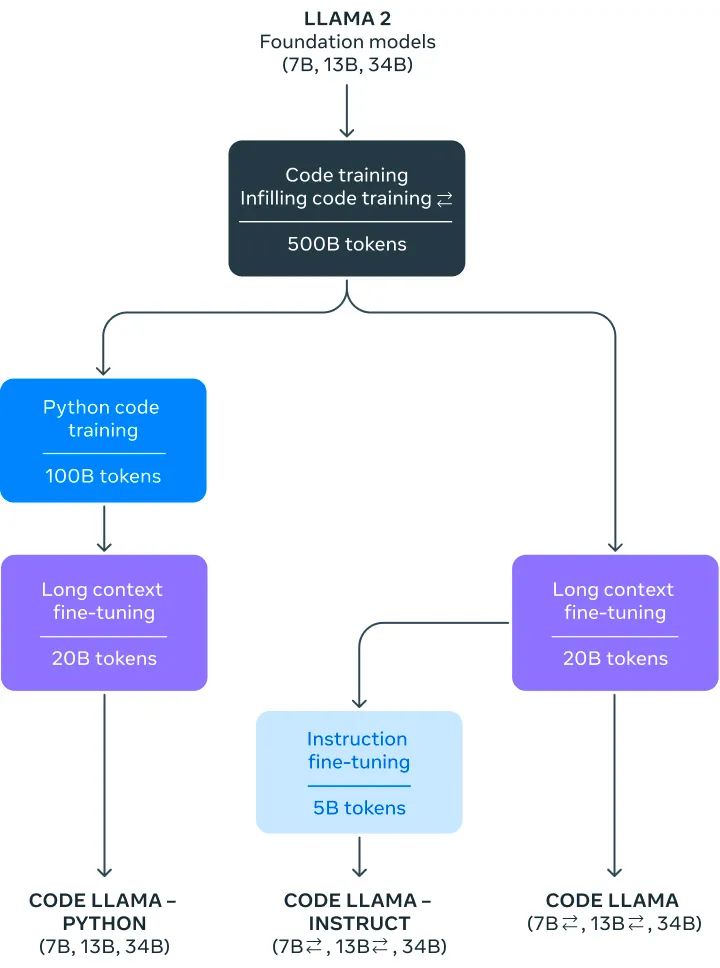
Code Llama是Llama 2的一个代码专用版本,它是通过在Llama 2的代码特定数据集上进一步训练,从同一数据集中采样更多的数据进行更长时间的训练而创建的。本质上,Code Llama具有增强的编码能力,建立在Llama 2之上。它可以从代码和自然语言提示(例如,“写一个输出斐波那契数列的函数。”)生成代码,以及关于代码的自然语言。它也可以用于代码补全和调试。它支持许多当今最流行的语言,包括Python, C++, Java, PHP, Typescript (Javascript), C#, 和Bash(请参阅下面参考的研究论文以获得完整的列表)。
我们将发布三种尺寸的 Code Llama,分别具有 7B、13B 和 34B 参数。每个模型都使用 500B 代码令牌和代码相关数据进行训练。7B 和 13B 基础模型和指令模型也经过了中间填充 (FIM) 功能的训练,允许它们将代码插入到现有代码中,这意味着它们可以支持开箱即用的代码完成等任务。
这三种模型满足不同的服务和延迟要求。例如,7B 模型可以在单个 GPU 上运行。34B 模型返回最佳结果并提供更好的编码辅助,但较小的 7B 和 13B 模型速度更快,更适合需要低延迟的任务,例如实时代码完成。
Code Llama 模型提供了具有多达 100,000 个上下文标记的稳定生成。所有模型都在 16,000 个标记的序列上进行训练,并在最多 100,000 个标记的输入上显示出改进。
除了是生成更长程序的先决条件之外,拥有更长的输入序列还可以为代码LLM解锁令人兴奋的新用例。例如,用户可以为模型提供来自其代码库的更多上下文,以使各代更相关。它还有助于在较大的代码库中调试场景,在这种情况下,掌握与具体问题相关的所有代码对于开发人员来说可能是一项挑战。当开发人员面临调试大量代码时,他们可以将整个代码长度传递到模型中。
此外,我们还进一步微调了 Code Llama 的两个附加变体:Code Llama - Python 和 Code Llama - Instruct。
Code Llama - Python 是 Code Llama 的语言专用变体,在 Python 代码的 100B 标记上进一步微调。因为 Python 是代码生成方面最具基准测试的语言,并且因为 Python 和PyTorch在 AI 社区中发挥着重要作用,所以我们相信专门的模型可以提供额外的实用性。
Code Llama - Instruct 是 Code Llama 的指令微调和对齐变体。指令调整继续训练过程,但目标不同。该模型接受“自然语言指令”输入和预期输出。这使得它能够更好地理解人们对提示的期望。我们建议在使用 Code Llama 进行代码生成时使用 Code Llama - Instruct 变体,因为 Code Llama - Instruct 已经过微调,可以用自然语言生成有用且安全的答案。
我们不建议使用 Code Llama 或 Code Llama - Python 执行一般自然语言任务,因为这两个模型都不是为遵循自然语言指令而设计的。Code Llama 专门用于特定于代码的任务,不适合作为其他任务的基础模型。
使用 Code Llama 模型时,用户必须遵守我们的许可和可接受的使用政策。
评估 Code Llama 的性能
为了针对现有解决方案测试 Code Llama 的性能,我们使用了两个流行的编码基准:HumanEval和 Mostly Basic Python Programming ( MBPP )。HumanEval 测试模型根据文档字符串完成代码的能力,MBPP 测试模型根据描述编写代码的能力。
我们的基准测试表明,Code Llama 的表现优于开源、特定于代码的 Llama,并且优于 Llama 2。例如,Code Llama 34B 在 HumanEval 上得分为 53.7%,在 MBPP 上得分为 56.2%,与其他状态相比最高。最先进的开放解决方案,与 ChatGPT 相当。
与所有尖端技术一样,Code Llama 也存在风险。负责任地构建人工智能模型至关重要,我们在发布 Code Llama 之前采取了许多安全措施。作为我们红队工作的一部分,我们对 Code Llama 生成恶意代码的风险进行了定量评估。我们创建了试图以明确意图征求恶意代码的提示,并根据 ChatGPT (GPT3.5 Turbo) 对 Code Llama 对这些提示的响应进行了评分。我们的结果发现,Code Llama 的回答更安全。
有关负责任人工智能、进攻性安全工程、恶意软件开发和软件工程领域专家的红队工作的详细信息,请参阅研究论文。
发布Code Llama
程序员已经在使用LLM来协助完成各种任务,从编写新的软件到调试现有的代码。我们的目标是让开发者的工作流程更高效,让他们能够专注于他们工作中最具人性化的方面,而不是重复性的任务。
在Meta,我们相信AI模型,特别是编码用的LLM,从开放的方式中受益最多,无论是在创新还是安全方面。公开可用的、代码特定的模型可以促进开发新技术,改善人们的生活。通过发布像Code Llama这样的代码模型,整个社区可以评估它们的能力,发现问题,并修复漏洞。
Code Llama 的训练方法可在我们的Github 存储库中找到,还提供模型参数。
生成式人工智能编码的未来
Code Llama 旨在为所有领域的软件工程师提供支持,包括研究、工业、开源项目、非政府组织和企业。但是,还有更多的用例需要支持,超出了我们的基础模型和指导模型所能提供的服务范围。 我们希望 Code Llama 能够激励其他人利用 Llama 2 为研究和商业产品创建新的创新工具。
审核编辑:刘清
-
PHP
+关注
关注
0文章
452浏览量
26679 -
python
+关注
关注
56文章
4793浏览量
84634 -
GPU芯片
+关注
关注
1文章
303浏览量
5806 -
ChatGPT
+关注
关注
29文章
1560浏览量
7604 -
LLM
+关注
关注
0文章
286浏览量
327
原文标题:Meta发布最先进的代码生成模型Code Llama
文章出处:【微信号:软件质量报道,微信公众号:软件质量报道】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Meta发布Llama 3.2量化版模型
如何使用 Llama 3 进行文本生成
使用OpenVINO 2024.4在算力魔方上部署Llama-3.2-1B-Instruct模型
亚马逊云科技上线Meta Llama 3.2模型
Meta发布全新开源大模型Llama 3.1
Meta发布基于Code Llama的LLM编译器
了解大型语言模型 (LLM) 领域中的25个关键术语






 工商网监
工商网监
评论