 大语言模型“书生·浦语”多项专业评测拔头筹
大语言模型“书生·浦语”多项专业评测拔头筹
最近,AI大模型测评火热,尤其在大语言模型领域,“聪明”的上限被不断刷新。
“SuperCLUE是由创立于2019年的CLUE学术社区最新发布的中文通用大模型综合性评测基准,包含SuperCLUE-Opt客观题测试、SuperCLUE-Open主观题测试、SuperCLUE-LYB琅琊榜用户投票的匿名对战测试三大基准组成。为更好地反映国内大模型与国际领先大模型间的差距和优势,SuperCLUE选取了多个国内外有代表性的可用模型进行评测,同时由于其数据集保密性高,对大模型来说是‘闭卷考试’,减少了模型训练数据混入评测数据的可能性。此外,SuperCLUE还通过自动化评测方式测试不同模型效果,可一键对大模型进行评测,相对更客观。” “书生·浦语”:不仅善于考试,还是开源大模型中的佼佼者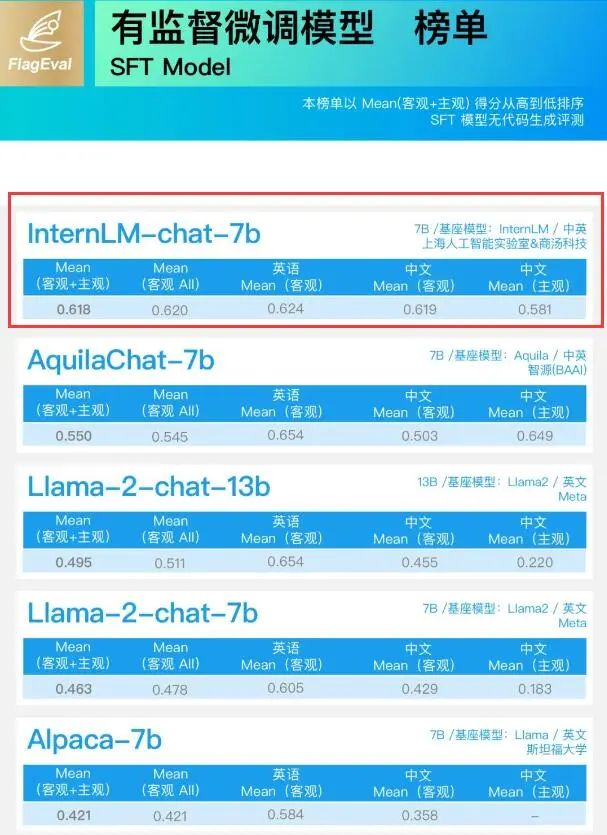

 作为SuperCLUE综合性三大基准之一,SuperCLUE-Opt评测基准每期有3700+道客观题(选择题),由基础能力(10个子任务)、中文特性能力(10个子任务)、学术专业能力(50+子任务)组成,采用封闭域测试方式。
相比第二名ChatGLM2-6B,InternLM-chat-7B主要在学术专业方面取得较大领先,同时全面领先于第三名Baichuan-13B-Chat。
作为SuperCLUE综合性三大基准之一,SuperCLUE-Opt评测基准每期有3700+道客观题(选择题),由基础能力(10个子任务)、中文特性能力(10个子任务)、学术专业能力(50+子任务)组成,采用封闭域测试方式。
相比第二名ChatGLM2-6B,InternLM-chat-7B主要在学术专业方面取得较大领先,同时全面领先于第三名Baichuan-13B-Chat。
商汤与上海AI实验室等联合打造的大语言模型“书生·浦语”(InternLM)也表现出色,分别在智源FlagEval大语言模型评测8月排行榜和中文通用大模型综合性评测基准SuperCLUE 7月评测榜两项业内权威大模型评测榜单中获得优异成绩。 “FlagEval是知名人工智能新型研发机构北京智源人工智能研究院推出的大模型评测体系及开放平台。FlagEval大模型评测体系构建了“能力-任务-指标”三维评测框架,可视化呈现评测结果,总计600+评测维度,包括22个主观、客观评测数据集,84433道评测题目。除知名的公开数据集 HellaSwag、MMLU、C-Eval外,FlagEval还集成了包括智源自建的主观评测数据集Chinese Linguistics & Cognition Challenge (CLCC),北京大学等单位共建的词汇级别语义关系判断、句子级别语义关系判断、多义词理解、修辞手法判断评测数据集。”
“SuperCLUE是由创立于2019年的CLUE学术社区最新发布的中文通用大模型综合性评测基准,包含SuperCLUE-Opt客观题测试、SuperCLUE-Open主观题测试、SuperCLUE-LYB琅琊榜用户投票的匿名对战测试三大基准组成。为更好地反映国内大模型与国际领先大模型间的差距和优势,SuperCLUE选取了多个国内外有代表性的可用模型进行评测,同时由于其数据集保密性高,对大模型来说是‘闭卷考试’,减少了模型训练数据混入评测数据的可能性。此外,SuperCLUE还通过自动化评测方式测试不同模型效果,可一键对大模型进行评测,相对更客观。” “书生·浦语”:不仅善于考试,还是开源大模型中的佼佼者
“书生·浦语”,是商汤科技、上海AI实验室联合香港中文大学、复旦大学及上海交通大学打造的大语言模型,具有千亿参数,在包含1.8万亿token的高质量语料上训练而成。
今年6月,“书生·浦语”联合团队曾选取20余项评测进行检验,包括全球最具影响力的四个综合性考试评测。结果显示,“书生·浦语”在综合性考试中表现突出,在多项中文考试中超越ChatGPT。(详情可参考「AI考生今日抵达,商汤与上海AI实验室等发布“书生·浦语”大模型」报道) 7月,“书生·浦语”正式开源70亿参数的轻量级版本InternLM-7B。(https://github.com/InternLM/InternLM)
后续又推出升级版对话模型InternLM-Chat-7Bv1.1,成为首个具有代码解释能力的开源对话模型,能根据需要灵活调用Python解释器等外部工具,解决复杂数学计算等任务的能力显著提升。
此外,该模型还可通过搜索引擎获取实时信息,提供具有时效性的回答。
在北京智源人工智能研究院FlagEval大语言模型评测体系8月最新排行榜中, “InternLM-chat-7B”和“InternLM-7B”分别在监督微调模型(SFT Model)榜单、基座模型(Base Model)榜单中取得第一和第二名。
“InternLM-chat-7B”还刷新中英客观评测记录。 「什么是“基座模型”、“有监督微调模型”?」 基座模型(Base Model)是经过海量数据预训练(Pre-train)得到的,它具备一定的通用能力,比如:GPT-3。 有监督微调模型(SFT Model)则是经过指令微调数据(包含了各种与人类行为及情感相关的指令和任务的数据集)训练后得到的,具备了与人类流畅对话的能力,如:ChatGPT。 普遍的观点认为,基座模型在很大程度上决定了微调模型的能力。 因此,FlagEval大语言模型评测体系针对基座模型的评测主要从“提示学习评测”和“适配评测”两方面进行;针对有监督微调模型的评测则从“复用针对基座模型的客观评测” 进一步增加“引入主观评测”。 此次两个榜单中,“InternLM-chat-7B”和“InternLM-7B”均表现出优异的综合性能,超越备受关注的Llama2-chat-13B/7B和Llama2-13B/7B。 特别在SFT Model测试中,InternLM-chat-7B中文能力大幅领先同时,英文能力也与对手保持在相近水平,展现出更强的实用性能。
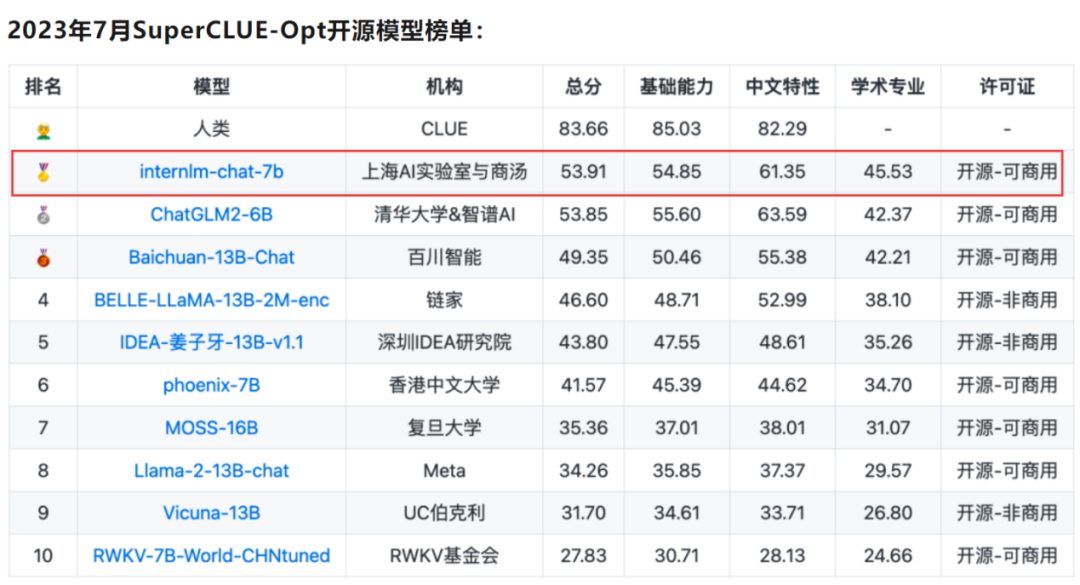
SuperCLUE评测从基础能力、专业能力、中文特性能力三个不同维度对国内外通用大模型产品进行评价,考察大模型在70余个任务上的综合表现。
“书生·浦语”InternLM-chat-7B在7月公布SuperCLUE评测榜单中表现出色,在SuperCLUE-Opt开源大模型榜单拔得头筹。
作为SuperCLUE综合性三大基准之一,SuperCLUE-Opt评测基准每期有3700+道客观题(选择题),由基础能力(10个子任务)、中文特性能力(10个子任务)、学术专业能力(50+子任务)组成,采用封闭域测试方式。
相比第二名ChatGLM2-6B,InternLM-chat-7B主要在学术专业方面取得较大领先,同时全面领先于第三名Baichuan-13B-Chat。

相关阅读,戳这里
《让大模型“百花齐放”,商汤大装置SenseCore提供一片沃土》《商汤发布多模态多任务通用大模型“书生2.5”》
《商汤联合发布通才AI智能体通关<我的世界>》

原文标题:大语言模型“书生·浦语”多项专业评测拔头筹
文章出处:【微信公众号:商汤科技SenseTime】欢迎添加关注!文章转载请注明出处。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
商汤科技
+关注
关注
8文章
506浏览量
36080
原文标题:大语言模型“书生·浦语”多项专业评测拔头筹
文章出处:【微信号:SenseTime2017,微信公众号:商汤科技SenseTime】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
云知声山海大模型多项能力全球领跑
国内人工智能权威机构清华大学基础模型研究中心发布SuperBench九月综合榜单。本次评测选取海内外24个具有代表性的大模型,结果显示,山海大模型对齐、智能体、安全等

【《大语言模型应用指南》阅读体验】+ 俯瞰全书
松。
入门篇主要偏应用,比如大语言模型的三种交互方式,分析了提示工程、工作记忆和长短期记忆,此篇最后讲了ChatGPT的接口和扩展功能应用,适合大语言模型应用技术人员阅读。
进阶篇就非
发表于 07-21 13:35
大模型助力国际术语专业化,前后联动实现所见即所得
、西班牙语、法语、德语、越南语。其中每个语言包的词条都有上万条,且随着新需求的开发迭代也在不断的新增,语言包的不断扩展和词条的不断增加,词条翻译的简洁性、
名单公布!【书籍评测活动NO.34】大语言模型应用指南:以ChatGPT为起点,从入门到精通的AI实践教程
联系,视为放弃本次试用评测资格!
2018 年,OpenAI 发布了首个大语言模型——GPT,这标志着大语言模型革命的开始。这场革命在 20
发表于 06-03 11:39
大语言模型:原理与工程时间+小白初识大语言模型
种语言模型进行预训练,此处预训练为自然语言处理领域的里程碑
分词技术(Tokenization)
Word粒度:我/贼/喜欢/看/大语言模型
发表于 05-12 23:57
【大语言模型:原理与工程实践】大语言模型的应用
,它通过抽象思考和逻辑推理,协助我们应对复杂的决策。
相应地,我们设计了两类任务来检验大语言模型的能力。一类是感性的、无需理性能力的任务,类似于人类的系统1,如情感分析和抽取式问答等。大语言
发表于 05-07 17:21
【大语言模型:原理与工程实践】探索《大语言模型原理与工程实践》2.0
读者更好地把握大语言模型的应用场景和潜在价值。尽管涉及复杂的技术内容,作者尽力以通俗易懂的语言解释概念,使得非专业背景的读者也能够跟上节奏。图表和示例的运用进一步增强了书籍的可读性。本
发表于 05-07 10:30
【大语言模型:原理与工程实践】大语言模型的基础技术
全面剖析大语言模型的核心技术与基础知识。首先,概述自然语言的基本表示,这是理解大语言模型技术的前提。接着,详细介绍自然
发表于 05-05 12:17
名单公布!【书籍评测活动NO.31】大语言模型:原理与工程实践
放弃本次试用评测资格!
缘起:为什么要写这本书
OpenAI的ChatGPT自推出以来,迅速成为人工智能领域的焦点。ChatGPT在语言理解、生成、规划及记忆等多个维度展示了强大的能力。这不仅体现在
发表于 03-18 15:49
名单公布!【书籍评测活动NO.30】大规模语言模型:从理论到实践
评测资格!
2022年11月,ChatGPT的问世展示了大模型的强大潜能,对人工智能领域有重大意义,并对自然语言处理研究产生了深远影响,引发了大模型研究的热潮。
距ChatGPT问世不
发表于 03-11 15:16
上海AI实验室发布新一代书生·视觉大模型
近日,上海人工智能实验室(上海AI实验室)联手多所知名高校及科技公司共同研发出新一代书生·视觉大模型(InternVL)。
书生・浦语 2.0(InternLM2)大语言模型开源
这个模型在 2.6 万亿 token 的高质量语料基础上进行训练,包含 7B 和 20B 两种参数规格以及基座、对话等版本,以满足不同复杂应用场景的需求。
发表于 01-19 09:39
•259次阅读
商汤科技发布新一代大语言模型书生·浦语2.0
1月17日,商汤科技与上海AI实验室联合香港中文大学和复旦大学正式发布新一代大语言模型书⽣·浦语2.0(InternLM2)。





 工商网监
工商网监
评论