 科大讯飞获国际多通道语音分离与识别大赛CHiME-7冠军
科大讯飞获国际多通道语音分离与识别大赛CHiME-7冠军
前方有好消息传来!
时隔3年后,国际多通道语音分离和识别大赛CHiME-7再次“上线”。当地时间8月25日,CHiME-7 Workshop在Meta公司都柏林研发中心举行,官方组委会现场公布了大赛成绩:
科大讯飞联合中科大语音及语言信息处理国家工程研究中心(NERC-SLIP)、国家智能语音创新中心,在参与的多设备多场景远场语音识别任务(DASR)中获得全部两个赛道的第一名。
继2016年以来参与CHiME-4、CHiME-5、CHiME-6三届比赛并夺冠后,讯飞联合团队坚持技术创新,此次在参与任务主赛道中语音识别错误率21%,相比赛事官方给出的基线系统,相对降低了60%以上。连续四届拿下冠军、领跑国际竞争对手的同时,科大讯飞在核心源头技术上也实现了自我突破。
语音识别任务难度加码!“群雄逐鹿”再领头
作为有“最难语音识别任务”之称的语音领域权威赛事,CHiME(Computational Hearing in Multisource Environments)系列比赛发起于2011年,致力于集聚学术界和工业界优秀的学术力量,持续突破语音识别技术水平,不断在更高噪声、更高混响、更高对话复杂度的场景下提出具有创新性的解决方案,解决著名的“鸡尾酒会问题”,难点在于怎样在充满噪声的鸡尾酒会,分辨并听清多人同时交谈的声音。
参与CHiME-7的团队高手如云,如中科院声学所、西北工业大学、剑桥大学、帕德博恩大学、捷克布尔诺理工大学、日本电信NTT、英伟达、俄罗斯STC等国内外知名研究机构、高校和企业。
本次CHiME-7中的语音识别任务由马尔凯理工大学、卡内基梅隆大学、约翰霍普金斯大学、东京都立大学的学者们共同组织,称为“多设备多场景远场语音识别任务(DASR)”。
在CHiME-6的基础上,CHiME-7进一步提升了难度,不仅在对话场景、麦克风设备类型上进行了扩充,同时要求参赛者只能使用统一的一套算法系统进行测试,这对语音识别系统的鲁棒性提出了极高的要求。具体如下:
在考察场景中,扩大了CHiME-6测试集范围,同时新增加了两个数据集DiPCo和Mixer 6;
三个数据集分别使用不同的麦克风设备,包含线性阵列、环形阵列、分布式麦克风等;
数据集中多人对话场景更加丰富,除朋友聚会之外还新增了采访、打电话等场景。
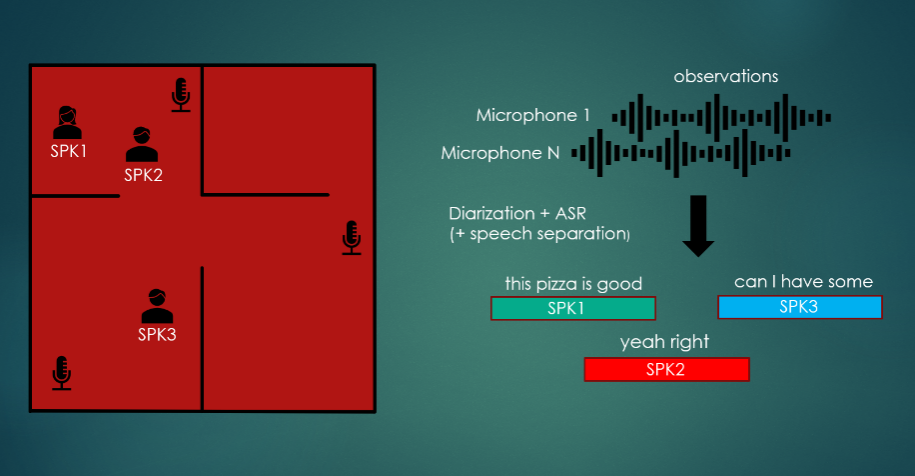
CHiME-7官方给出的任务图例
该任务分为主赛道(Main Track,默认提交)和子赛道(Sub Track,自由提交),具有很高的挑战性,也与真实复杂场景中的语音识别要求更为贴近:
主赛道需要首先要完成远场数据下的说话人角色分离任务,即从连续的多人说话语音中切分出不同说话人片段、判断出每个片段是哪个说话人,然后再进行语音识别;
子赛道中说话人角色分离的信息是人工标注的,参赛者可以直接使用,在人工分离边界的基础上直接进行语音识别。
此次比赛核心考察指标为DA-WER(Diarization Attributed WER),即综合考察系统对多个说话人的角色分离效果,以及语音识别效果。
科大讯飞联合团队参加了所有两个赛道,在主赛道和子赛道分别以21%和16%语音识别错误率拿下双冠,将真实说话人角色分离情况下的语音识别错误率与使用人工标注间的差别控制在5%,这也标志着在实际环境中的应用效果将得到进一步提升。
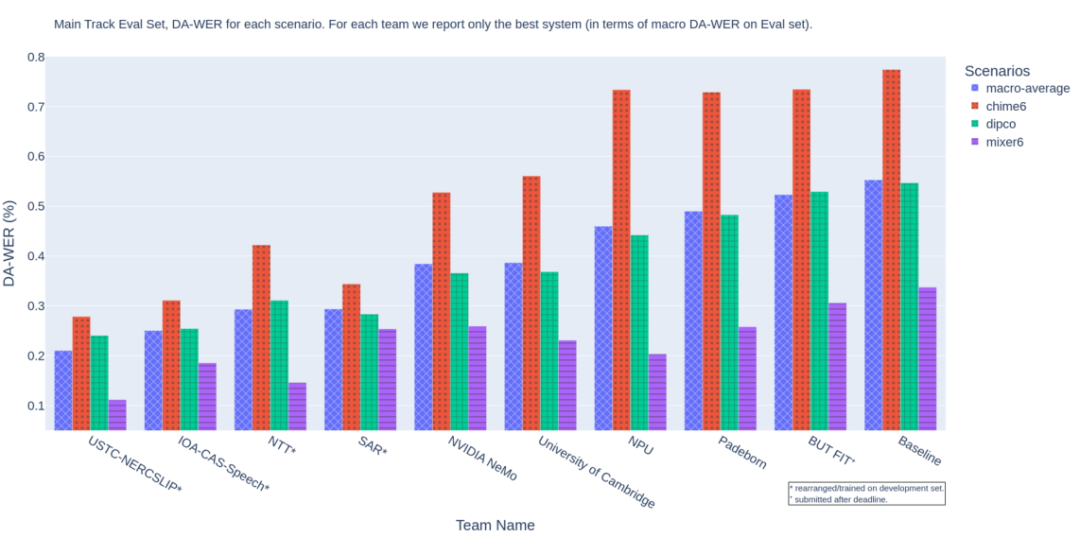
主赛道语音识别成绩,排名指标DA-WER取自三个数据集上的平均值,值越低成绩越好
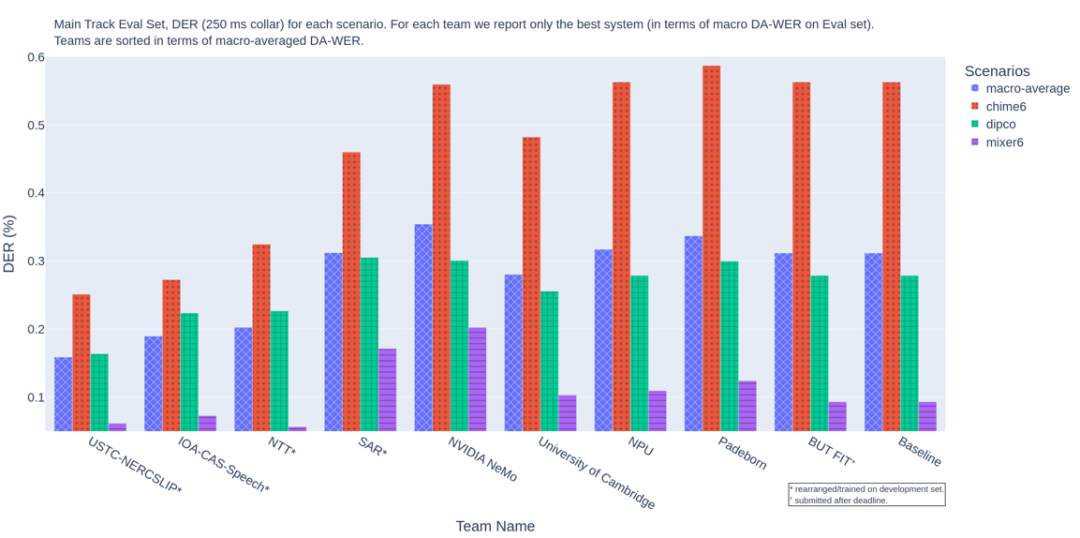
主赛道说话人角色分离成绩,排名指标DER代表说话人角色分离错误率,值越低成绩越好
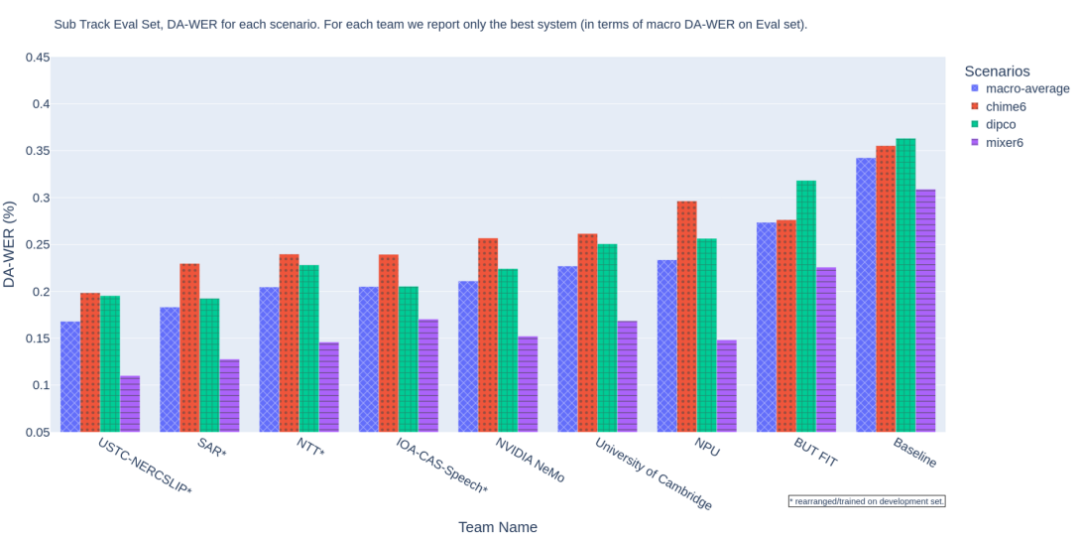
子赛道语音识别成绩,排名指标DA-WER取自三个数据集上的平均值,值越低成绩越好
面对挑战,我们的“新招数”有哪些?
如何突破语音交叠、远场混响与噪声干扰、随意的对话风格等重重难关,在更复杂的语音素材里精准实现说话人角色分离和语音识别?
基于长期技术积累,以及讯飞语音识别技术在落地应用中的实践和反馈,联合团队创新并使用了多种技术方法。
基于记忆模块的多说话人特征神经网络说话人角色分离算法 (Neural Speaker Diarization Using Memory-Aware Multi-Speaker Embedding , NSD-MA-MSE)
该方法旨在解决高噪声、高混响、高说话人重叠段场景的说话人角色分离问题。基于对大规模的说话人聚类得到的类中心向量,团队设计了一种记忆模块,可以利用该模块与当前目标人片段,通过注意力机制计算来得到更加精确的目标说话人特征。整体上,团队采用序列到序列的方式来预测多个说话人的输出帧级语音/非语音概率。该模型极大降低了说话人角色分离错误率,有效地帮助了后续的分离和识别模块。
阵列鲁棒的通道挑选算法(Array-Robust Channel Selection)
该算法基于波束语音信噪比挑选准则,即使对于不同的阵列分布场景,也能够自动挑选出有效通道,从而减少下游任务无效噪声和语音干扰。同时,团队提出了一种空间-说话人同步感知的迭代说话人角色分离算法(Spatial-and-Speaker-Aware Iterative Diariazation Algorithm,SSA-IDA),通过结合阵列空间建模和机器学习长时建模的优势,迭代修正说话人角色分离系统中声学特性相似的说话人错分情况,从而更加精确捕捉目标说话人的信息。
该算法不仅有效的降低了环境干扰噪声,而且可以进一步消除干扰说话人的语音,从而大幅降低下游语音识别任务的难度。
场景自适应自监督表征学习方案(Scene Adaptive Self-Supervised Learning Method)
该方案用于匹配复杂场景的语音识别,将经过前端处理后的音频作为自监督模型的输入,并提取高层次表征作为指导标签,实现了对特定场景的快速自适应匹配;同时,结合层级渐进式学习和一致性正则约束,进一步提高了预训练模型对下游语音识别任务的鲁棒性。利用预训练模型的层级信息进行融合,实现了语音识别在复杂场景的效果提升。
望过去、向未来:更好的AI离不开更好的语音识别
连续四届获得CHiME冠军背后,是科大讯飞在语音识别技术和应用上踏过的漫长之路:
从2010年国内首批开展深度神经网络语音识别研究,到全球首个中文语音识别深度神经网络(DNN)上线、循环神经网络(RNN)语音识别全面升级、全球首创基于全序列卷积神经网络(DFCNN)的语音识别,近几年持续探索无监督预训练、多模态在语音识别上的应用;
从2010年推出语音输入的讯飞输入法上线、讯飞语音云发布,到落地教育、医疗、城市、工业、金融、汽车等各行各业,还有面向你我生活学习工作的讯飞翻译机、智能办公本、AI学习机、讯飞听见、录音笔、智能耳机……
不论是大型国际会议、全球赛事,还是身边的一通电话、一次询问,在繁杂的声音世界里,是持续进化的语音识别技术让机器更了解我们所言所语。
面向未来,科大讯飞在CHiME-7中的技术成果链接着更多的应用可能:
立志于让机器人走进每个家庭的“讯飞超脑2030”计划里,似乎可以看到未来人和机器自然交互的新场景。CHiME-7中的技术成果能够让机器人面向每个家庭成员实现更精准的语音识别,再加上多模感知、多维表达、认知智能和AI运动智能算法等有机结合,实现系统性创新——家庭陪伴机器人不仅能够听清、听懂每位家庭成员的需求,还能真正做到情感陪伴与日常生活照顾……
**智能语音是万物互联机器沟通的入口,也是人工智能赋能千行万业、浸润千家万户的秘钥;**智能语音是我们的初心,是载誉的过往和现在,也是灿烂的将来。
审核编辑:刘清
-
机器人
+关注
关注
210文章
28063浏览量
205754 -
信噪比
+关注
关注
3文章
251浏览量
28550 -
语音识别
+关注
关注
38文章
1709浏览量
112471 -
深度神经网络
+关注
关注
0文章
61浏览量
4507
原文标题:四连冠!科大讯飞获国际多通道语音分离与识别大赛CHiME-7冠军
文章出处:【微信号:iFLYTEK1999,微信公众号:科大讯飞】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
科大讯飞发布讯飞星火4.0 Turbo大模型及星火多语言大模型
科大讯飞发布讯飞星火4.0 Turbo:七大能力超GPT-4 Turbo
科大讯飞AI总部园区正式启用
科大讯飞发布智能办公本Air 2
科大讯飞AI学习机暑期重磅升级
科大讯飞发布“讯飞星火V3.5”:基于全国产算力训练的全民开放大模型

科技创新与智能助力:揭秘科大讯飞智能键盘D1的独特魅力

科大讯飞AI机械键盘D1的前瞻性设计:告别传统,迎接智能化时代






 工商网监
工商网监
评论