 如何加速生成2 PyTorch扩散模型
如何加速生成2 PyTorch扩散模型
产生性人工智能的近期进展大部分来自去除传播模型,这些模型能够从文本提示中产生高质量的图像和视频。 这个家族包括图像、 DALLE、 延迟传播等。 但是,这个家族的所有模型都有一个共同的缺点: 生成速度相当缓慢, 因为生成图像的取样过程具有迭接性。 这使得优化取样圈内运行的代码非常重要 。
我们以开放源实施流行文本到图像传播模式作为起点,利用PyTorrch 2:编集和快速关注实施中的两种优化方法加快其生成速度,同时对代码进行少量的记忆处理改进,这些优化使原实施速度比原实施速度加快49%。旧前和 39% 的推论比方使用旧前的原始代码(不包括编译时间)的速度加快,这取决于 GPU 架构和批量大小。重要的是,加速不需要安装 旧前 或其他任何额外依赖关系。
下表显示从安装了旧前的最初实施到我们以PyTorch集成内存高效关注(最初为PyTorch集成内存有效关注开发并在旧前图书馆)和PyTorrch汇编,不包括汇编时间。
与原x格式相比,运行时间改善%%
见“基准设定和成果摘要”一节中的绝对运行时间数字。
| GPU | 批量大小 1 | 批量大小 2 | 批量大小 4 |
| p100 p100 (p100)(没有汇编) | -3.8 -3.8 | 0.44 | 5.47 5.47 |
| T4 | 2.12 2.2.12 | 10.51 妇女 10.51 | 14.2 女14.2 |
| A10 | -2.34 | 8.99 | 10.57 10.57 |
| v100 (v100) | 18.63 | 6.39 | 10.43 |
| a100 (a100) | 38.5 | 20.33 | 12.17 12.17 |
人们可以注意到以下情况:
对于a100 (a100)和v100 (v100)等强大的GPU等强大的GPU来说,这些改进是显著的。 对于这些GPU来说,第1批的改进最为显著。
对于功率较小的GPUs,我们观察到较弱的GPUs,我们观察到较小的超速超速(或两种情况下略有倒退 ) 。 这里的批量规模趋势被逆转:较大批量的改进更大
在以下各节中,我们介绍应用优化,并提供详细的基准数据,将生成时间与不同最佳运行/关闭功能进行比较。
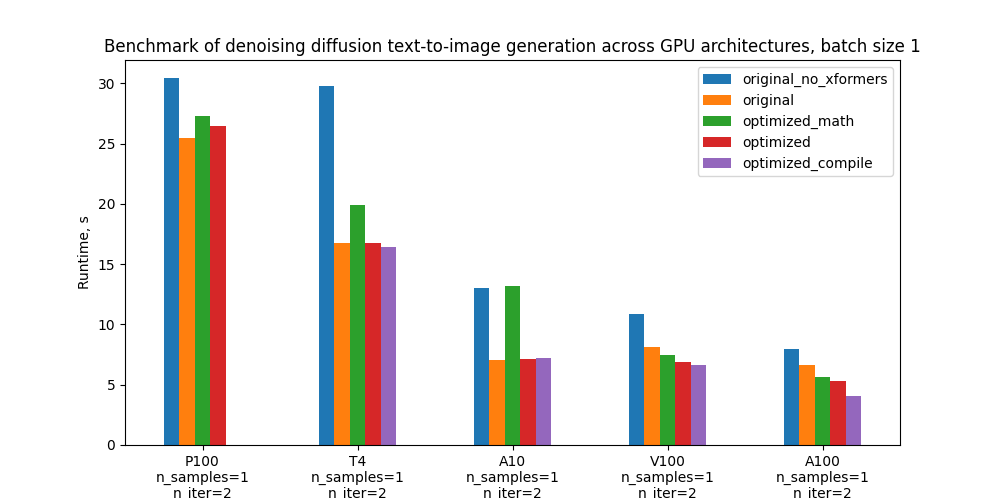
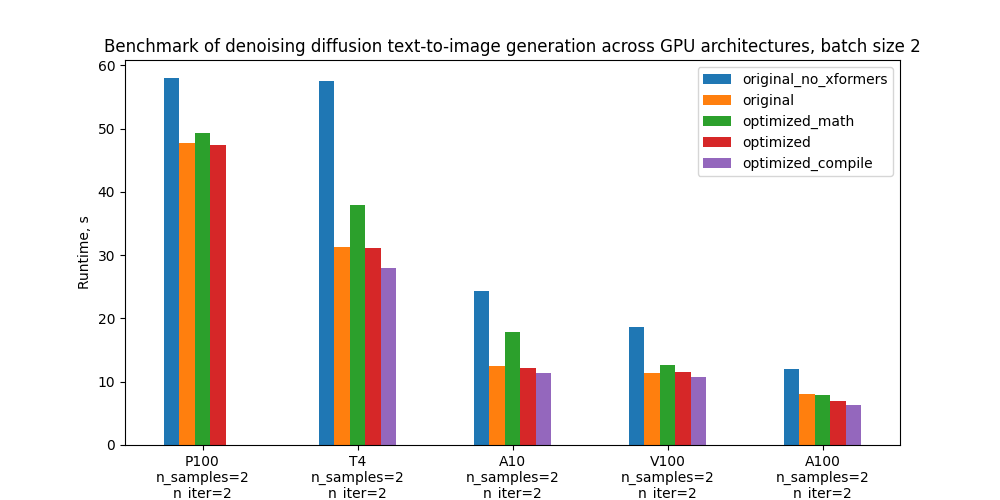
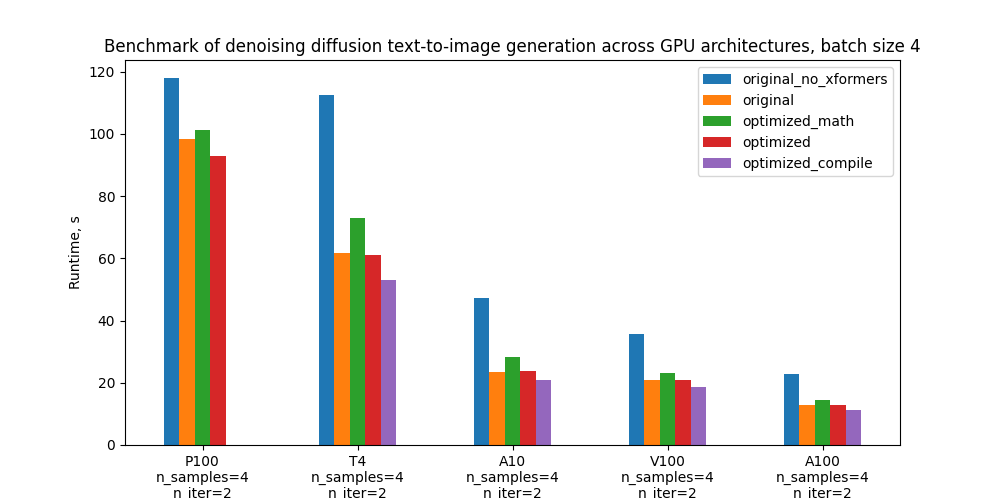
具体而言,我们以5个配置基准和下面的地块为基准,比较其不同GPU和批量大小的绝对性性能,这些配置的定义见“基准设置和结果”一节。
优化优化
这里我们将更详细地介绍在模式代码中引入的优化。 这些优化依赖于最近发布的PyTorrch 2.0的特征。
优化关注
我们优化的代码的一部分就是对点产品的关注比例。人们知道,注意是一个繁重的操作:天真地执行会影响关注矩阵,导致时间和记忆的复杂二次序列长度。扩散模型使用关注是常见的( 通常使用关注的 ) ( ) 。相互注意))作为U-Net多个部分的变换元块的一部分。由于U-Net运行在每个取样步骤,这成为优化的关键点。多头目,PyTorrch 2 中优化了关注执行的功能, 并被纳入其中。 这种优化的示意图可归结为以下伪代码 :
类交叉注意( nn. module): def __ initt_( 自 己, ) :
替换为
类交叉注意(nn.Module): def __initt_( 本身, ......): 自我. mmha = nn. Multihead 注意 (...) def 前进( 自己, x, 上下文): 返回自我. mmha (x, 上下文, 上下文)
PyTorrch 1.13中已经提供了最佳的注意落实(见在这里和广泛通过(例如,见A/CN.9/WG.III/WP.Huggging 纸面变压器库示例特别是,它吸收了《公约》和《公约》的记忆有效关注。旧前和闪闪着的注意http://arxiv.org/abs/2205.14135PyTorrch 2.0将这一功能扩大到更多的关注功能,如交叉关注和为进一步加速而定制的内核,使之适用于扩散模型。
在计算能力为SM 7.5或SM 8.x的GPU上可提供闪光关注,例如,在T4、A10和a100 (a100)上可提供闪光关注,这些都包括在我们的基准中(你可以检查每个NVIDIA GPU的计算能力)。在这里然而,在我们对a100 (a100)a100 (a100)的测试中,由于关注头和小批量数量少,因此对扩散模型特定案例的记忆有效关注比对传播模型的闪光关注效果的注意效果好于对传播模型的具体案例的闪光关注效果。在这里为了充分控制注意力后端(模拟有效关注、闪光关注、“香草数学”或任何未来数学),电力用户可以在上下文管理员的帮助下手动启用和禁用这些后端。后端... cudda. sdp_ 内核.
compilation
汇编是PyTorrch 2. 0 的新特性,从而能够以非常简单的用户经验实现巨大的超速。要援引默认行为,只需将一个 PyTorch 模块或函数包成I. 火炬燃烧器:
模型 = 火炬. combile( 模型)
PyTorrch 编译器然后将 Python 代码转换成一套指令, 可以在没有 Python 管理费的情况下高效执行。 该编译器在代码首次被执行时动态发生。 在默认行为下, 在使用的 PyTorrch 头罩下核电厂汇编代码和火焚化器以进一步优化它。此教义以获取更多细节。
虽然上面的单班条足以进行编译, 但对代码的某些修改可以压缩更大的速度。 特别是, 人们应该避免所谓的图形分解, 即PyTorrch无法编译的代码中的位置。 与先前的 PyTorrch 编译方法( 如 火炬Script ) 相比, PyTorrch 2 编译器在此情况下不会中断。 相反, 它会回到急切的执行中 - 所以代码运行, 但性能下降 。 我们对模式代码做了一些小小改动, 以删除图形分解器 。 这包括删除编译器不支持的图书馆的功能, 比如 。检查职能和电离电离电离电离电离电离电离电离电离电离电离电离电离电离电离电离电离电离电离电离电离电离电离电离电离电离电离电离电离电离电离电离电离电离电离电离电离电离电离电离电离电离电离电离电离电离电离电离电离电离电离电离电离电离电离电离电离电离电离电离电离电离电离电离电离电。 看看这个doc学习更多关于图表分解和如何消除这些分解的信息。
从理论上讲,可以适用I. 火炬燃烧器然而,在实践中,仅仅汇编U-Net就足够了。I. 火炬燃烧器还没有环形分析器,因此将重新拼凑取样循环的每一次迭代的代码。 此外,已编译的样本代码可能会生成图形折断符 — — 因此,如果人们想从已编译的版本中获得良好的性能,就需要调整它。
注意该汇编requires GPU compute capability >= SM 7.0以非倾向模式运行。这涵盖了我们基准中的所有 GPU ----T4, v100 (v100), A10, a100 (a100) - p100 p100 (p100) 除外(见完整列表).
其他优化
此外,我们通过消除一些常见的陷阱提高了GPU内存操作的效率,例如直接在GPU上创建高压GPU,而不是直接在CPU上创建高压GPU,然后转移到GPU,因此我们提高了GPU内存操作的效率。火焰图.
制定基准和成果摘要
我们有两种版本的代码可以比较:原原件和优化优化除此以外,还可以打开/关闭若干优化功能(旧前、PyTorrch内存高效关注、编译)。
没有 旧前 的原始代码
旧前 的原始代码
与香草数学关注后端和无编译的 香草数学关注优化代码
最优化代码, 包含内存高效关注后端, 没有编译
具有内存高效注意后端和编译功能的优化代码
作为原文原版我们采用了使用PyTorrch 1. 12的代码版本,并按惯例执行了关注标准。优化版用途nn. 多头目内相互注意PyTerch 2.0.0.dev20230111 cu117。 在与PyTerch有关的代码中,它还有其他一些微小的优化。
下表显示每个版本代码的运行时间以秒计,与旧前原版相比的百分比改进百分比。 _ 汇编时间不包括在内。
1. 括号 -- -- " 原件与 x Formers " 行相对改进
| 配置配置配置 | p100 p100 (p100) | T4 | A10 | v100 (v100) | a100 (a100) |
| 没有格式的原件 | 30.4s (19.3%) | 29.8s(-77.3%) | 13.0(-83.9%) | 10.9s(-33.1%) | 8.0s (19.3%) |
| 原件与 旧前 | 25.5秒(0%) | 16.8s (0.00%) | 7.1s 7.1s 7.1s 7.1s(0%) | 8.2s(0.00%) | 6.7s(0.00%) |
| 最优化的香草数学关注, 没有编译 | 27.3s (--7.0%) | 19.9s (18.7%) | 13.2% (87.2%) | 7.5s(8.7%) | 5.7s(15.1%) |
| 高效率的注意,没有汇编。 | 26.5%(-3.8%) | 16.8s (0.2%) | 7.1s 7.1s 7.1s 7.1s(-0.8%) | 6.9s (16.0%) | 5.3s(20.6%) |
| 高效关注和汇编 | - 带 | 16.4.4s 16.4.4s(2.1%) | 7.2(-2.3%) | 6.6.6s(18.6%) | 4.1s 4.1s(38.5%) |
批量规模 2 的运行时间
| 配置配置配置 | p100 p100 (p100) | T4 | A10 | v100 (v100) | a100 (a100) |
| 没有格式的原件 | 58.0s (21.6%) | 57.6岁(84.0%) | 24.4s (95.2%) | 18.6秒 (-63.0%) | 12.0s (-50.6%) |
| 原件与 旧前 | 47.7s(0.00%) | 31.3s (0.00%) | 12.5s (0.00%) | 11.4秒 (0.00%) | 8.0s(0.00%) |
| 最优化的香草数学关注, 没有编译 | 49.3%(-3.5%) | 37.9s (-21.0%) | 17.8s (-4.2.2%) | 12.7s (10.7%) | 7.8s(1.8%) |
| 高效率的注意,没有汇编。 | 47.5s 47.5s(0.4%) | 31.2% (0.5%) | 12.2% (2.6%) | 11.5%(-0.7%) | 7.0s (12.6%) |
| 高效关注和汇编 | - 带 | 28.0秒(10.5%) | 11.4秒(9.0%) | 10.7s 10.7s(6.4%) | 6.4.4s(20.3%) |
批量大小 4 的批量运行时间
| 配置配置配置 | p100 p100 (p100) | T4 | A10 | v100 (v100) | a100 (a100) |
| 没有格式的原件 | 117.9s(-20.00%) | 112.4s (-81.8%) | 47.2s (-101.7 %) | 35.8s (-71.9%) | 22.8s (-78.9%) |
| 原件与 旧前 | 98.3s(0.00%) | 61.8s(0.00%) | 23.4s(0.00%) | 20.8s (0.00%) | 12.7s (0.00%) |
| 最优化的香草数学关注, 没有编译 | 101.1s (-2.9%) | 73.0s(1.8.0%) | 28.3s (-21.0%) | 23.3s(11.9%) | 14.5s (13.9%) |
| 高效率的注意,没有汇编。 | 92.9秒(5.5%) | 61.1s(1.2%) | 23.9s(-1.9%) | 20.8s (-0.1%) | 12.8s (-0.9%) |
| 高效关注和汇编 | - 带 | 53.1s 53.1s(14.2%) | 20.9秒(10.6%) | 18.6秒(10.4%) | 11.2. 11.2(12.2%) |
为了尽量减少对基准代码性能的波动和外部影响,我们逐个运行了代码的每个版本,然后又重复了10次这个序列:A、B、C、D、E、A、B.......因此典型运行的结果将看起来像下面的图片。请注意,人们不应该依赖对不同图表之间绝对运行时间的比较,但是对内部运行时间的比较是相当可靠的,这要归功于我们的基准设置。
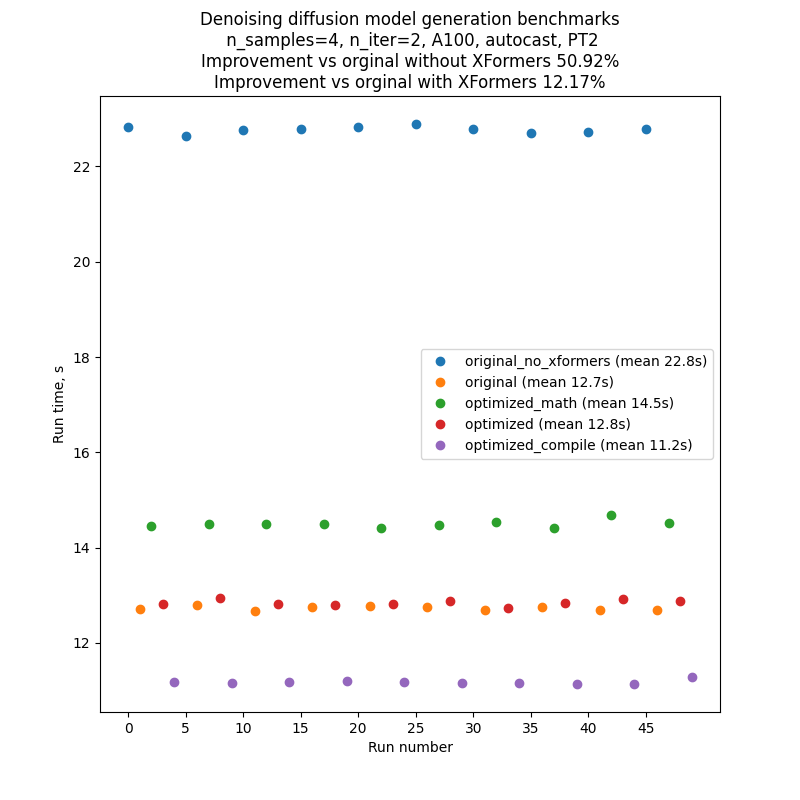
每卷文字到图像生成脚本都产生几批数,其数量受CLI参数管制--niter --niter。在我们使用的基准中n标准=2,但引入了额外的“暖化”迭代,这对运行时间没有帮助。 这对编译运行是必要的,因为编译发生在代码运行的第一次,因此第一次迭代的时间比后来的都要长。 为了比较公平,我们还将这种额外的“暖化”迭代引入了所有其他运行。
上表中的数字是迭代数2(加上“暖热一号”),即时“A”照片,种子1,PLMS取样器,自动打开。
基准使用p100 p100 (p100)、v100 (v100)、a100 (a100)、A10和T4GPUs完成,T4基准在Google Colab Pro完成,A10基准在G5.4xmall AWS实例中与1GPU完成。
结论和下一步步骤
我们已经表明,PyTorrch 2 - 编译者和优化关注实施的新特点 -- -- 使性能改进超过或与以前要求安装的外部依赖(旧前)的功能相仿;PyTorrch特别通过将旧前的内存有效关注纳入代码库来实现这一点,这是对用户经验的重大改进,因为旧前是一家最先进的图书馆,在许多情形中,需要定制的安装过程和长期建筑。
这项工作可以继续往几个自然方向发展:
我们在这里所实施和描述的优化只是为迄今为止的文字到图像的推断基准,有兴趣了解它们如何影响培训绩效。 PyTorch汇编可以直接应用于培训;PyTorch优化关注的扶持培训正在路线图中。
我们有意尽量减少对原示范守则的修改。 进一步的定性和优化可能带来更多的改进。
目前,汇编工作只适用于取样器内部的U-Net模型。由于在U-Net之外发生了很多事情(例如,在取样环中直接作业),汇编整个取样器将是有益的。然而,这需要对汇编过程进行分析,以避免在每一取样步骤中进行重新汇编。
当前代码仅在PLMS取样器内应用编译程序,但将其扩展至其他取样器则微不足道。
除了文字到图像生成外,还应用推广模型来进行其他任务 -- -- 图像到图像和油漆。
审核编辑:彭菁
-
模型
+关注
关注
1文章
3405浏览量
49449 -
代码
+关注
关注
30文章
4856浏览量
69446 -
编译程序
+关注
关注
0文章
13浏览量
4158 -
pytorch
+关注
关注
2文章
808浏览量
13471
发布评论请先 登录
相关推荐
基于扩散模型的图像生成过程

如何在PyTorch中使用扩散模型生成图像

Pytorch模型训练实用PDF教程【中文】
将pytorch模型转化为onxx模型的步骤有哪些
怎样使用PyTorch Hub去加载YOLOv5模型
通过Cortex来非常方便的部署PyTorch模型
将Pytorch模型转换为DeepViewRT模型时出错怎么解决?
pytorch模型转换需要注意的事项有哪些?
扩散模型在视频领域表现如何?
如何改进和加速扩散模型采样的方法1
如何改进和加速扩散模型采样的方法2





 工商网监
工商网监
评论