 流浪者缓解PyTorch DDP的层次SGD
流浪者缓解PyTorch DDP的层次SGD
罗汉·瓦尔马(梅塔·艾)
PyTork DDP 点火 DDP该技术的性能对于模型勘探期间的快速迭代以及资源和成本节约至关重要。该技术的性能对于模型开发和勘探的快速迭代和成本节约至关重要。为了解决大规模培训中慢节点引入的无处不在的性能瓶颈问题,巡航和梅塔公司共同开发了一个基于此解决方案的解决方案。SGD 等级式 SGD算法可以大大加速训练 在有这些累赘者在场的情况下
减少斯特拉格勒公司的必要性
在 DDP 设置中,当一个或多个流程运行比其他流程慢得多时,可能会出现累赘问题(“累赘者 ” ) 。 如果发生这种情况,所有流程都必须等待累赘者,然后才能同步梯度和完成通信,而通信的瓶颈基本上将业绩分配给了最慢的工人。 因此,即使培训相对较小的模型,通信成本也可能是一个主要的性能瓶颈。
Stragglers 的潜在原因
在同步之前,工作量不平衡通常会造成严重的累赘问题,许多因素可能促成这种不平衡。 比如,在分布环境中,一些数据载荷工人可能会成为累赘者,因为某些输入实例在数据大小方面可能出乎意料,或者由于网络一/O不稳定,一些实例的数据传输可能大大放缓,或者在飞行数据转换成本可能有很大差异。
除数据加载外,梯度同步之前的其他阶段还可能造成累赘,例如,在建议系统中的前端路过时,嵌入表格的查寻工作量不平衡。
Stragglers 外观
如果我们剖析 DDP 培训有累加器的工作, 我们就会发现有些过程的梯度同步成本( a.k.a., 全部降低梯度) 可能比其它过程高得多。 因此, 分布式的性能可以以通信成本为主, 即使模型大小很小 。 在这种情况下, 有些过程的运行速度比拖累器的步数快, 因此它们必须等待拖累器, 并且花费更长的时间来进行减速 。
以下显示 PyTorrch 剖析器在使用案例中输出的两个追踪文件的截图。 每个截图剖析图分立为 3 步 。
第一个截图显示,一个过程在第一和第二步都有非常高的削减成本,因为这个过程比排减速器提前到达同步阶段,而且要花更多的时间等待。另一方面,在第二步,削减成本相对较低,这意味着:(1) 这一步没有排减速器;或者(2) 这个过程是所有过程的排减速度,因此它不必等待任何其他过程。
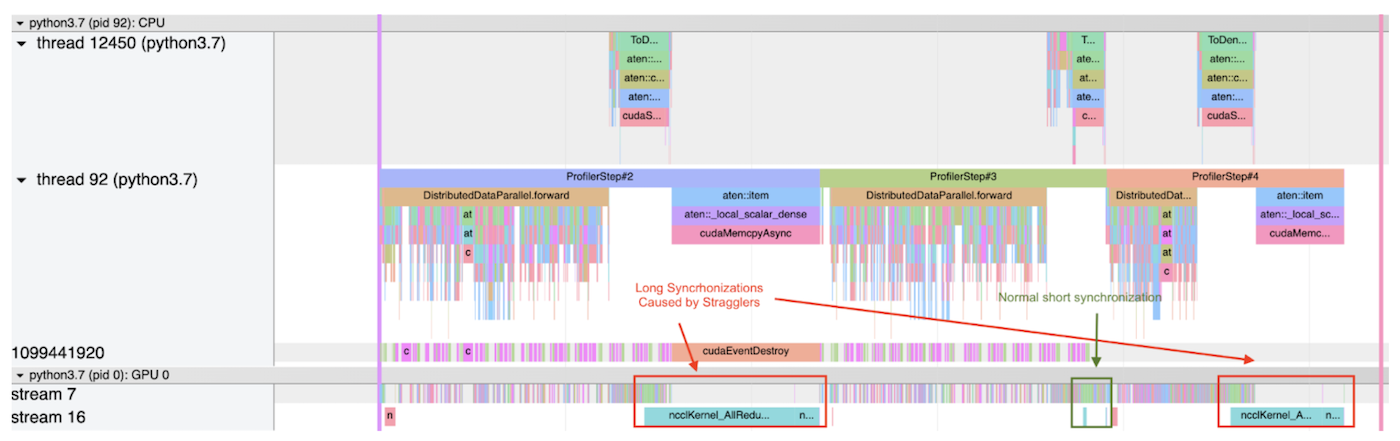
第一步和第三步 都被斯特拉格勒人拖慢了
第二个截图显示一个正常的大小写, 不带斜体。 在此情况下, 所有梯度同步都相对短 。
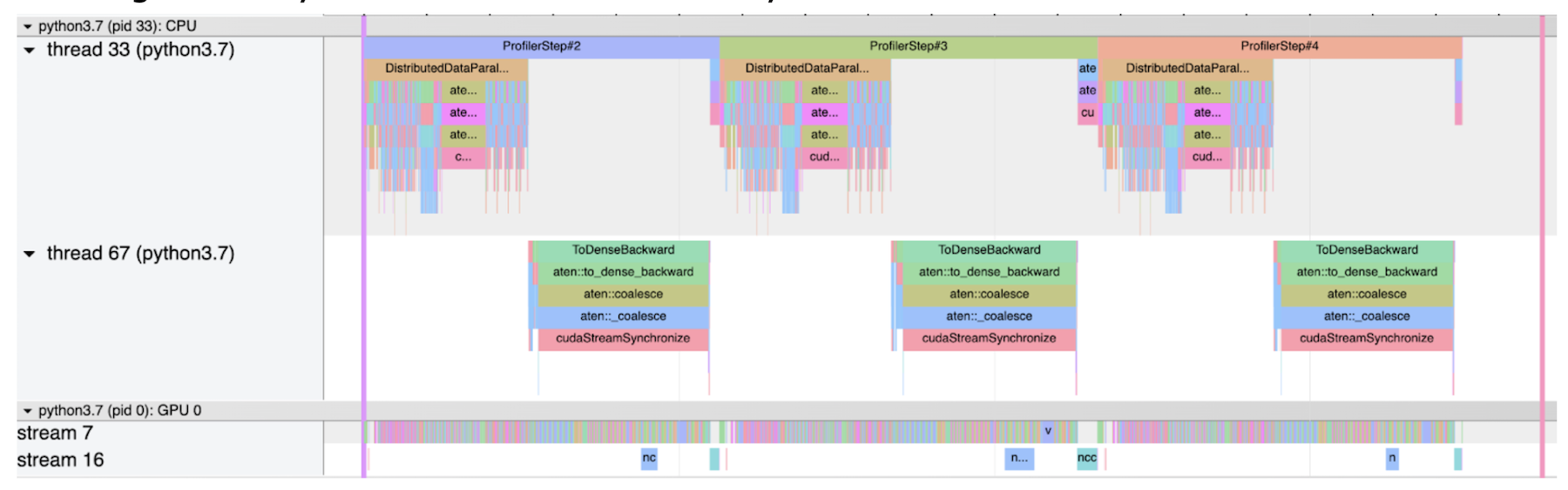
普通无斯特拉格器的普通大小写
PyTorch 中的等级 SGD
最近,已提议通过减少大规模分布式培训中的数据传输总量,优化通信成本,并提供了多重趋同分析,从而优化了通信成本(最近,SGD等级结构已提议通过大规模分布式培训减少数据传输总量)。示例示例示例作为这一职位的主要新颖之处,在游轮上,我们可以利用SGD等级来减轻拖拉机,这也可能发生在培训相对较小的模型上,2022年初,我们通过游轮到皮托尔奇执行。
等级制的SGD如何运作?
正如名称所暗示的那样,SGD等级将所有过程按等级划分为不同层次的分组,并按以下规则同步进行:
同一级别的所有组组都有相同数量的流程,这些组的流程同步同步,同步期由用户预先确定。
较高层次的一组是,使用较大的同步期,因为同步越来越昂贵。
当多个重叠组应该按照各自时期同步时,为了减少冗余同步和避免不同组间的数据竞赛,只有最高层组可以同步。
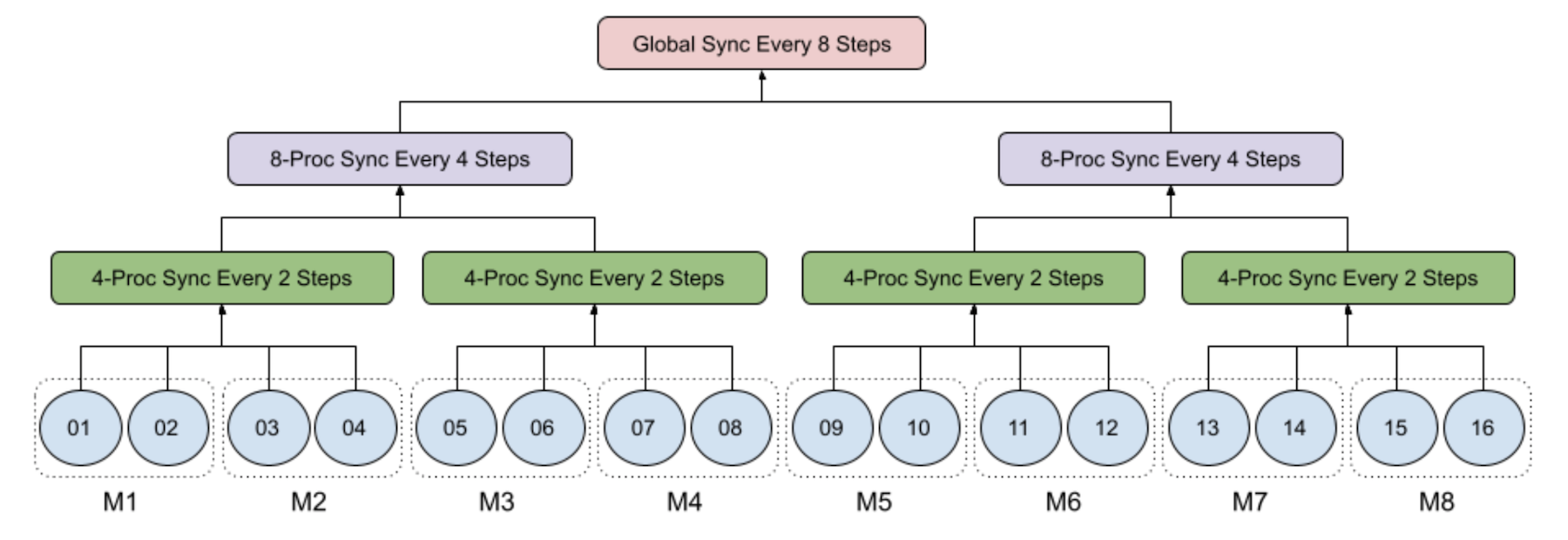
下图举例说明了8台机器的16个工艺中4级级的SGD,每台有2个GPU:
1级:1级:每个过程都在当地经营小型批次的SGD;
第2级:每两台机器的4-处理小组每两台机器每两步同步;
第3级:每四台机器每组8-处理8个程序,每四步同步;
4级:全球流程组由所有16个流程组成,超过8台机器每8个步骤同步运行。
特别是,当步数除以8时,只执行3时的同步,而当步数除以4而不是8时,只执行2时的同步。
从直觉上看,可以将SGD等级视为本地 SGD只有两级等级 — — 每一个过程都在当地运行小型批次 SGD , 然后以一定频率同步全球。 这也可以帮助解释一下,就像本地 SGD 一样,等级 SGD 同步模型参数而不是梯度。 否则,当频率大于1时,梯度下降在数学上是不正确的。
为什么分级的SGD SGD Mipigate Stragglers 能够?
这里的关键洞察力是,当有一个随机的减速器时,它只会直接减慢相对较少的一组进程,而不是所有进程。 下一次,另一个随机的减速器很可能减慢另一组不同的小组,因此,一个等级可以帮助平滑减速效应。
下面的例子假设每步有8个流程中有一个随机的分隔符。 在4个步骤后, 运行同步 SGD 的香草 DDP 会被排缩 4 次, 因为它每步都运行全球同步 。 相反, 等级 SGD 在前两步后与四组流程同步, 然后在后两步后与四组流程同步。 我们可以看到前两步和最后两步都有很大的重叠, 从而可以减少性能损失 。
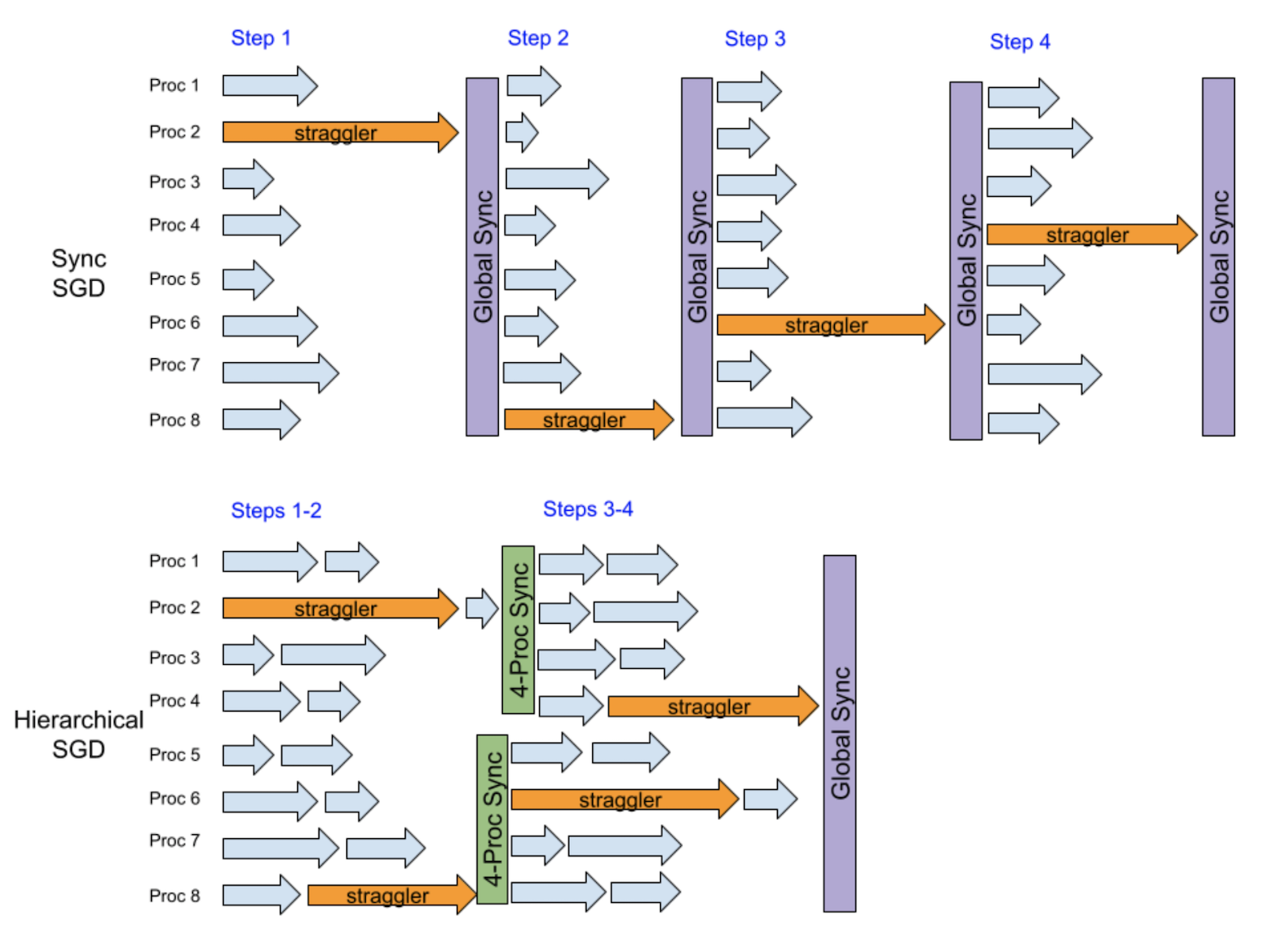
基本上,这一等级的SGD实例的缓解效应实际上是在每两个步骤的频率和每四个步骤的频率之间,地方的SGD相对于地方的SGD的主要优势是同一全球同步频率的更好趋同效率,因为等级的SGD允许更低层次的同步。此外,等级的SGD有可能提供比地方的SGD低的同步频率,并具有模型等同性,从而导致更高的培训业绩,特别是在大规模分布式培训中。
使用范围
减少斯特拉格勒排放量并不是在分布式培训中进行的一项新研究。Galk SGD八八八流, 数据编码, 梯度编码,以及某些特别设计的参数-服务器结构,包括:后备工人和平平同步平行然而,据我们所知,在这项努力之前,我们还没有找到一个良好的开放源码PyTorch(开放源码PyTorch)的缓解拖拉机的功能,可以像我们游轮培训系统的插件一样运作。相反,我们的实施只需要最小的修改 — — 不需要修改现有的代码或调整现有的任何超参数。这对工业用户来说是一个非常有吸引力的优势。
如下面的代码示例所示,DDP模式的设置只需要增加几行,培训循环代码可以保持不动。 如前所述,SGD等级是本地 SGD 的扩大形式,因此增强功能可以与本地 SGD 相当相似(见PyTorch docs,2003年)。后 postlocalsg 喷雾器):
注册一个本地的 SGD 后通信钩,以运行一个同步的 SGD 和推迟级别 SGD 的热级阶段。
创建后本地 SGD 优化器, 将现有的本地优化器和等级 SGD 配置包起来 。
发件人: 发件人: 发件人: 发件人: 发件人: 发件人: 发件人: 发件人: 发件人: 发件人: 发件人: 发件人:
高分数计
等级SGD有两个主要的超强参数:周期_ 群群大小_ dict和暖化步骤.
周期_ 群群大小_ dict命令从同步期到处理组大小的字典绘图,用于在等级体系中初始化不同大小的流程组,以同时同步参数。预计较大组将使用较大的同步期。
暖化步骤指定一些步骤作为在 SGD 等级前同步 SGD 运行的热级阶段。 类似之后的本地 SGD运算算法,通常建议一个暖化阶段,以达到更高的精度。开始日期(_localsgd_iter)用于后 本地 国家当 post_ localSGD_hook 注册时。 通常在损失急剧减少时, 热身阶段至少应覆盖培训开始阶段 。
PyTorrch 实施与相关文件提出的初步设计之间的一个微妙区别是,在暖化阶段之后,每个东道主内部的流程默认仍然每一步都运行东道主内部的梯度同步。 这是因为:
东道方内部通信相对便宜,通常能够大大加快趋同速度;
东道方内部组(对于大多数行业用户来说,规模为4或8)通常可以很好地选择最经常同步的最小流程组。 如果同步期为1, 则梯度同步比模型参数同步(a.k.a., 平均模型)要快, 因为 DDP 自动重叠梯度同步和后传。
这种东道方内部梯度同步可因不设置而禁用员额(_L) 本地_ 梯度_ 全部减少参数以后 本地 国家.
演示演示
现在,我们证明,SGD等级可以通过减轻累赘来加快分散培训。
实验设置
我们比较了SGD等级与当地SGD等级与SGD等级与SGD等级与SGD等级的成绩,并比较了SGD等级与重新发送18由于模型太小,培训不会因同步期间的数据传输成本而受阻。 为了避免从远程存储中输入数据时产生的噪音,输入数据是从内存中随机模拟的。 我们把培训使用的GPU数量从64个增加到256个。 每个工人的批量规模为32个,而培训的迭代数量是1,000个。 由于我们不评估这一组实验的趋同效率,因此无法进行暖化。
我们还以128个和256个GPU和64个GPU的比例1%和2%的速率模仿了挤压器,以确保平均每个步骤至少有一个压压压器。这些压压器随机出现在不同的 CUDA 设备上。每个压压压器在正常的单步训练时间之外再拖延1秒( 在我们的设置中为~ 55米 ) 。 这可以被视为一种实际的情景,其中1%或2%的输入数据在培训期间在数据处理费用( I/O 和/或苍蝇的数据转换)方面出局,而这种费用比平均数高20x。
下面的代码片段显示了如何在训练循环中模仿一个拖拉机。 我们将其应用到 ResNet 模型中, 它也可以很容易地应用到其他模型中 。
损失 = 损失 fn(y_pred, y)
每台机器有4台NVIDIA Tesla T4GPU,每台GPU有16GB内存,通过32Gbit/sepernet网络连接,每台都装有96个VCPU,360GB RAM。
| 结构架构架构 | 重新发送18(450MB) |
| 工人 工人 | 64、128、256 |
| 后端 | nccc 单位 |
| gpu | Tesla T4, 16 GB内存 |
| 批批批量大小 | 32x 32 x |
| Straggler 期限 | 1 秒 1 秒 |
| Straggler 率 | 128个和256个GPU的1%,64个GPU的2% |
本地SGD和等级 SGD使用多种配置。 本地SGD每2、4和8个步骤分别运行全球同步。
我们用以下配置来管理SGD的等级结构:
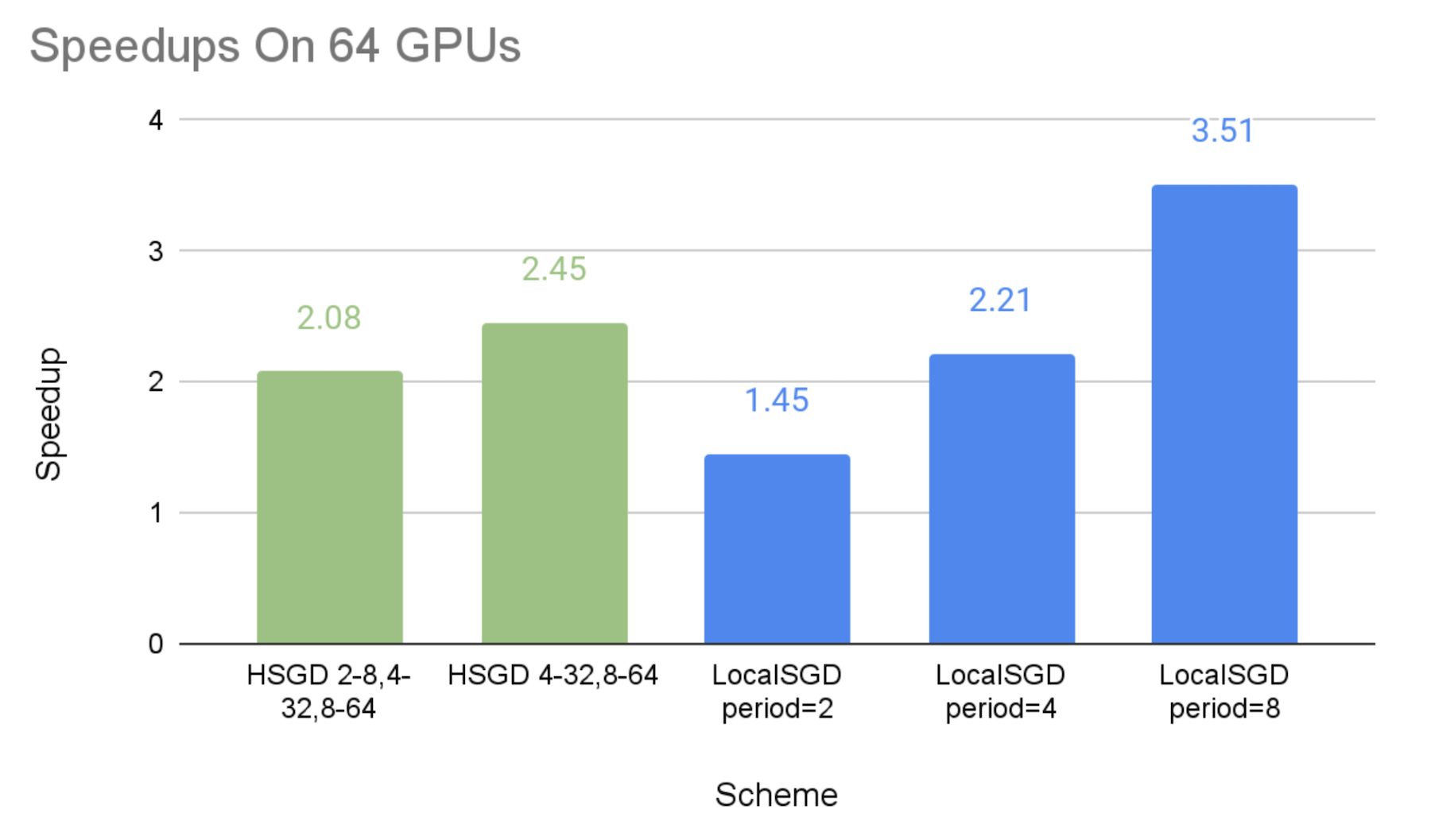
64 GPUs:
8-处理组、32-处理组和全球64-处理组分别每2、4和8个步骤同步。HSGD 2-8,4-32,8-64”.
每个32个处理组和全球64个处理组分别每4个和8个步骤同步。HSGD 4-32,8-64”.
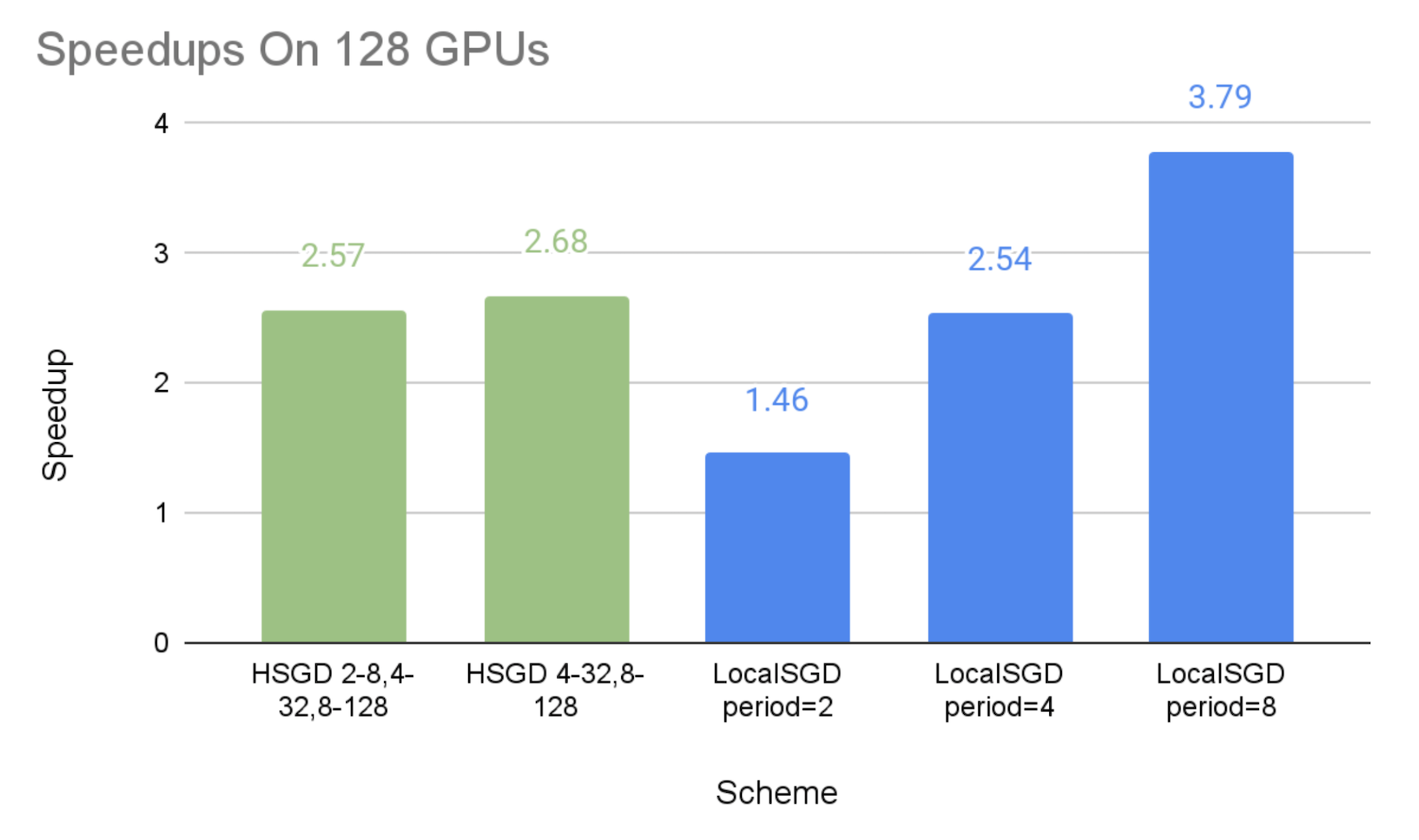
在128个GPUs上:
8-处理组、32-处理组和全球128-处理组的每个8-处理组、32-处理组和全球128-处理组分别每2、4和8个步骤同步。SGSGD 2-8,4-32,8-128”.
每个32个处理组和全球128个处理组分别每4个和8个步骤同步。HSGD 4-32,8-128”.
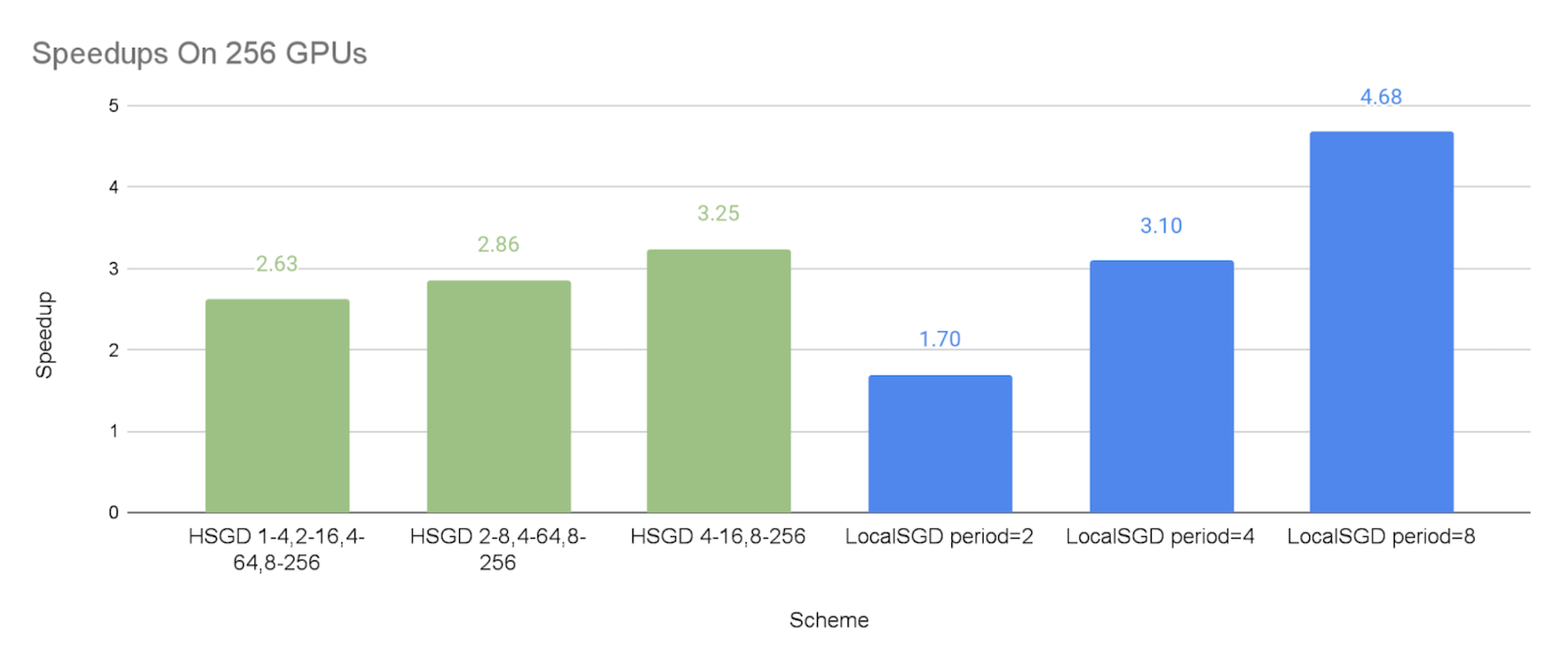
在256个GPUs上:
每个4-处理组、16-处理组、64-处理组和全球256-处理组分别每1、2、4和8个步骤同步一次。1,4,2,16,4,64,8,256”.
8-处理组、64-处理组和全球256-处理组每2、4和8个步骤同步。SGSGD 2-8,4-64,8-256”.
每16个处理组和全球256个处理组分别每4个和8个步骤同步。HSGD 4-16,8-256”.
实验结果
下图显示了不同通信计划相对于同步的 SGD 基线,与效仿的施压者相比的加速速度。
如预期的那样,我们可以看到,SGD等级和当地SGD能够以较低的同步频率加快速度。
SGD等级制度的加速实施是:2.08x-2.45x64 GPUs,64 GPUs,64 GPUs,64 GPUs,64 GPUs,64 GPUs,64 GPUs,64 GPUs,64 GPUs,64 GPUs,64 GPUs,64 GPUs,64 GPUs,64 GPUs,64 GPUs,2.57x-2.68x在128个GPUs,和2.63x-3.25x这表明,等级分级的SGD可以大大减轻排挤因素,而这种缓解在更大的规模上可以更加有效。
当地SGD的性能与同步期分别为2个步骤和8个步骤,这可被视为试验的SGD等级制度下限和上限,这是因为,SGD等级制度比全球每2个步骤同步的频率要低,但与全球同步期每8个步骤相比,其在小集团的低水平同步是额外的间接费用。
总体来说,SGD等级可以比当地SGD在通信成本和模式质量之间提供比当地SGD更好的权衡。 因此,如果当地SGD在8或4等相当大的同步期不能带来令人满意的趋同效率,SGD等级可以有更好的机会实现良好的速度和模式对等。
由于试验中只使用模拟数据,我们没有在这里证明模型对等,在实践中可以通过以下两种方式实现:
包括等级制和暖化步骤在内的超参数;
在某些情况下,等级级的SGD可能导致与原有模式相比,相同数量的培训步骤的质量略低(即,趋同率较低),但是,如果每步培训的速度加快到2X,仍然有可能以更多的步骤实现模式对等,但总培训时间更小。
限制
在应用SGD等级来缓解排减因素之前,用户应认识到这种方法的一些局限性:
这种方法只能缓解不同工人在不同时期遇到的非持久性阻力因素。 但是,对于长期性阻力因素,因为硬件退化或特定主机的网络问题可能造成这种阻力因素,这些阻力因素会每次都减缓同一个低层次分组的速度,导致几乎没有缓解阻力因素。
这种方法只能缓解低频排减器。 例如,如果30%的工人可以随机地在每一步中成为排减器,那么大多数低级同步器仍会因排减器而放慢速度。 结果,SGD等级的SGD可能不会显示出相对于同步的 SGD的明显性能优势。
由于SGD适用的平均模式与香草 DDP使用的向后偏差一样,与后向不重叠,其平均模式与香草 DDP使用的向后偏差相同,因此,由于通信和后向通行证之间没有重叠的性能损失,SGD的性能增益必须大于其性能损失。 因此,如果递减者只慢慢了不到10%的培训,SGD的等级可能无法加快速度。 这一限制可以解决。overlapping optimizer step和backward pass未来。
由于SGD等级比当地SGD受到的研究要少,因此不能保证具有精细的同步同步颗粒特性的SGD等级比当地SGD某些先进形式的SGD(例如:慢速然而,据我们所知,这些先进的算法还不能作为PyTorrch DDP插件(如SGD等级插件)得到本地的支持。
承认的确认
我们要感谢巡游队的队友宝天, 谢尔盖·沃罗贝夫, 尤金·塞利文奇克、李宣贤, 丹环, 伊恩·阿克曼, 陈李立, 玛根·朱麦根, 越南 Anh To, 龙小辉, 陈世玉, 亚历山大·西多罗夫, 伊戈尔·茨韦特科夫, 胡信胡, 马纳夫·卡塔利亚, 玛丽娜·鲁布佐娃, 和穆罕默德·法瓦兹以及Meta队友沈力、赵延利、苏拉伊·苏布拉马尼扬、哈米德·舒詹泽里、安贾利·斯里达尔和伯纳德·阮支持。
审核编辑:汤梓红
-
算法
+关注
关注
23文章
4612浏览量
92894 -
pytorch
+关注
关注
2文章
808浏览量
13226
发布评论请先 登录
相关推荐
直流浪涌保护器与交流浪涌保护器的区别和作用

JRCS工控机SGD-640-K7-2C维修,JRCS显示屏维修案例
视频解码芯片DDP3310B电子资料
流浪宠物疫情监控系统的设计资料分享
通过Cortex来非常方便的部署PyTorch模型
什么是声卡DDP电路/声卡杜比定逻辑技术
Pytorch入门教程与范例
人脸识别助力为流浪者找到亲人 应用越发广泛
基于区块链技术的文档处理迁移平台MIGRANET介绍
DDP442X ASIC组件及其应用程序编程接口的详细资料描述





 工商网监
工商网监
评论