 不只是GPU,内存厂商们的AI野望
不只是GPU,内存厂商们的AI野望
电子发烧友网报道(文/周凯扬)在诸多云服务厂商或互联网厂商一头扎进GPU的疯抢潮后,不少公司也发现了限制AI大模型性能或是成本消耗的除了GPU以外,还有内存。内存墙作为横亘在AI计算和HPC更进一步的阻碍之一,在计算量井喷的今天,已经变得愈发难以忽视。所以,在今年的HotChips大会上,内存厂商们也竞相展示自己的内存技术在AI计算上的优势。
三星
三星作为最早一批开始跟进存内计算的公司,早在两年前的HotChips33上,就展示了HBM2-PIM的技术Aquabolt-XL。三星在去年底展示了用PIM内存和96个AMD Instinct MI100 GPU组建的大规模计算系统,并宣称这一配置将AI训练的速度提高了近2.5倍。
而今年的HotChips上,三星也着重点明了PIM和PNM技术在生成式AI这类热门应用上的优势。三星认为在ChatGPT、GPT-3之类的应用中,主要瓶颈出现在生成阶段的线性层上,这是因为GPU受到了内存限制且整个过程是线性顺序进行的。
在三星对GPT的分析中,其主要由概括和生成两大负载组成,其中概括考验的是计算单元的性能,而生成则考验的是内存的性能。而生成占据了绝大多数的运算次数和耗时,其中占据了60%到80%延迟的GEMV(矩阵向量操作)也就成了三星试图用PIM和PNM攻克的目标。
根据三星的说法,像GPT这类Transformer架构的模型,都可以将多头注意力(MHA)和前馈神经网络(FFN)完全交给PIM或PNM,完全利用他们的所有带宽,从而减少在推理上所花费的时间和能耗。三星也在单个AMD MI100-PIM的GPU上进行了试验,得出运行GPT模型时,在HBM-PIM的辅助下,能效是GPU搭配传统HBM的两倍,性能同样提升至两倍以上。
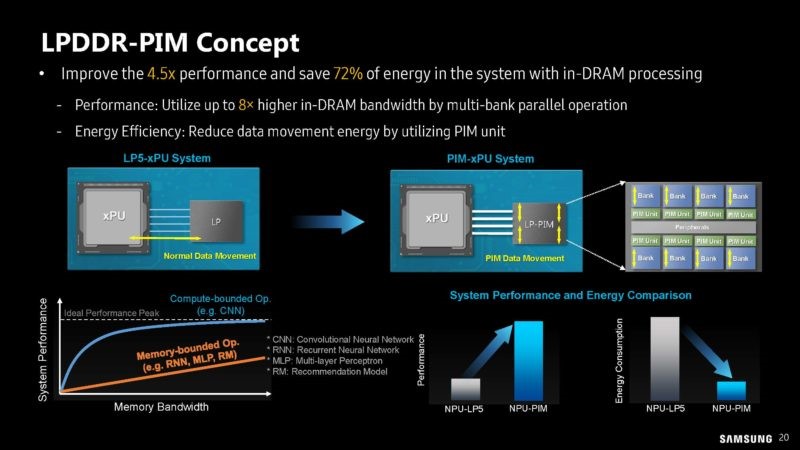
LPDDR-PIM概念 / 三星
除了HBM-PIM外,这次三星还展示了最新的LPPDR-PIM概念。除了云端生成式AI需要存内计算的辅助外,诸如智能手机这样的端侧生成式AI概念也被炒起来,所以LPPDR-PIM这样的存内计算技术,可以进一步保证续航的同时,也不会出现为了带宽内存使用超量的情况。
SK海力士
另一大韩国内存巨头SK海力士也没有闲着,在本次HotChips大会上,他们展示了自己的AiM存内加速器方案。相较三星而言,他们为生成式AI的推理负载准备的是基于GDDR6的存内计算方案。
GDDR6-AiM采用了1y的制造工艺,具备512GB/s内部带宽的同时,也具备32GB/s的外部带宽。且GDDR6-AiM具备频率高达1GHz的处理单元,算力可达512GFLOPS。GDDR6-AiM的出现,为存内进行GEMV计算提供了端到端的加速方案,比如乘法累加和激活函数等操作都可以在内存bank内同时进行,单条指令实现全bank操作提供更高的计算效率。
同时,SK海力士也已经考虑到了AiM的扩展性问题,比如单个AiM卡中集成了8个AiM封装,也就是8GB的容量和256个处理单元。但这类扩展方案最大的问题还是在软件映射、硬件架构和接口上,这也是绝大多数集成存内计算的新式内存面临的问题。
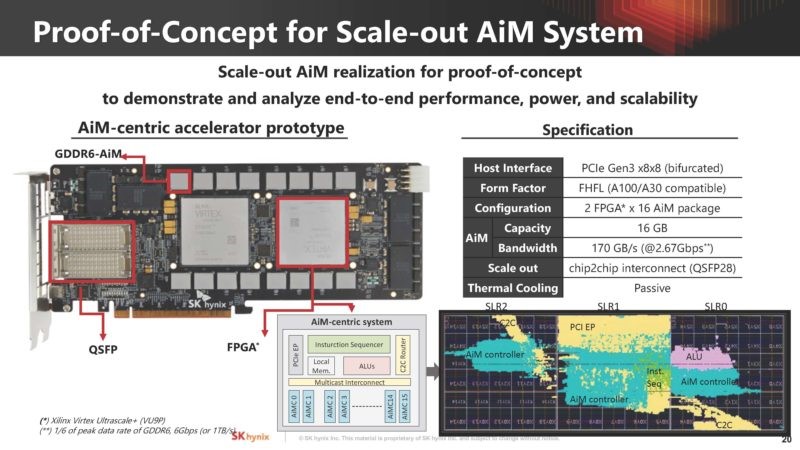
AiM系统扩展性验证Demo / SK海力士
而SK海力士已经给出了这方面的解决方案,比如专门针对AiM的Tiling、基于AiM架构的控制器、路由和ALU等等。他们还展示了在两个FPGA上结合GDDR6-AiM的Demo,以及用于LLM推理的软件栈。与此同时,他们也还在探索AiM的下一代设计,比如如何实现更高的内存容量,用于应对更加庞大的模型。
写在最后
无论是三星还是SK海力士都已经在存内计算领域耕耘多年,此次AI热来势汹汹,也令他们研发速度进一步提快。毕竟如今能够解决大模型训练与推理的耗时与TCO的硬件持续大卖,如果存内计算产品商业化量产落地进展顺利,且确实能为AI计算带来助力的话,很可能会小幅提振如今略微萎缩的内存市场。
-
gpu
+关注
关注
28文章
4768浏览量
129325
发布评论请先 登录
相关推荐
GPU是如何训练AI大模型的
PON不只是破网那么简单
《算力芯片 高性能 CPUGPUNPU 微架构分析》第3篇阅读心得:GPU革命:从图形引擎到AI加速器的蜕变


不只是前端,后端、产品和测试也需要了解的浏览器知识(二)
为什么跑AI往往用GPU而不是CPU?

AI训练,为什么需要GPU?

新型的FPGA器件将支持多样化AI/ML创新进程
国产GPU在AI大模型领域的应用案例一览

Achronix新推出一款用于AI/ML计算或者大模型的B200芯片

GPU交期缓解,AI服务器厂商营收暴涨





 工商网监
工商网监
评论