 复旦开源LVOS:面向真实场景的长时视频目标分割数据集
复旦开源LVOS:面向真实场景的长时视频目标分割数据集
本文介绍复旦大学提出的面向真实场景的长时视频目标分割数据集LVOS,论文被ICCV2023收录

现有的视频目标分割(VOS)数据集主要关注于短时视频,平均时长在3-5秒左右,并且视频中的物体大部分时间都是可见的。然而在实际应用过程中,用户所需要分割的视频往往时长更长,并且目标物体常常会消失。现有的VOS数据集和真实场景存在一定的差异,真实场景中的视频更加困难。
虽然现在的SOTA的视频目标分割方法在短时的VOS数据集上已经取得了90%的分割准确率,但是这些算法在真实场景中的表现如何却由于缺少相关的数据集不得而知。

因此,为了探究VOS模型在真实场景下的表现,弥补现有数据集的缺失,我们提出了第一个面向真实场景的长时视频目标分割数据集Long-term Video Object Segmentation (LVOS)。
背景介绍:
视频目标分割(VOS)旨在根据视频中第一帧的物体的掩膜,在视频之后每一帧中准确地跟踪并分割目标物体。视频目标分割有着十分广泛的应用,比如:视频编辑、现实增强等。在实际应用场景中,待分割的视频长度常常大于一分钟,且视频中的目标物体会频繁地消失和重新出现。对于VOS模型来说,在任意长的视频中准确地重检测和分割目标物体是一个十分重要的能力。
但是,现有的VOS模型主要是针对于短时视频设计的,并不能很好的处理长时的物体消失和错误累计。并且部分VOS算法依赖于不断增长的记忆模块,当视频长度较长时,存在着低效率甚至显存不够的问题。
目前的视频目标分割数据集主要关注于短时视频,平均视频长度为六秒左右,和真实场景存在着较大差异。与现有的数据集相比,LVOS的视频长度更长,对于VOS算法的要求更高,能够更高地评估VOS模型在真实场景下的性能。
LVOS数据集介绍:
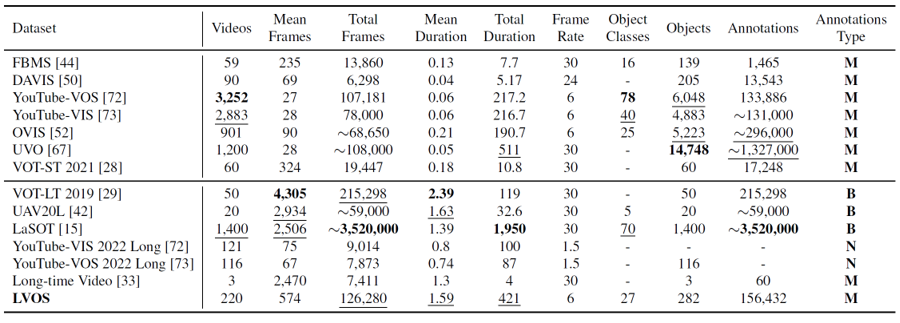
LVOS包含220个视频,总时长达421分钟,平均每个视频时长为1.59分钟,远远大于现有的VOS数据集。LVOS中的视频更加复杂,且有着在短时视频中不存在的挑战,比如长时消失重现和跨时序混淆。这些挑战更难,且对VOS模型的性能影响更大。LVOS中涉及27个类别的物体,其中包含了7种只有测试集中存在的未见类别,能够很好地衡量VOS模型的泛化性。
LVOS分为120个训练视频,50个验证视频和50个测试视频,其中测试视频和验证视频已经全部开源,而测试视频目前只开源了视频图像和第一帧中目标物体的掩膜,需要将预测结果上传到测试服务器中进行在线评测。
方法介绍:
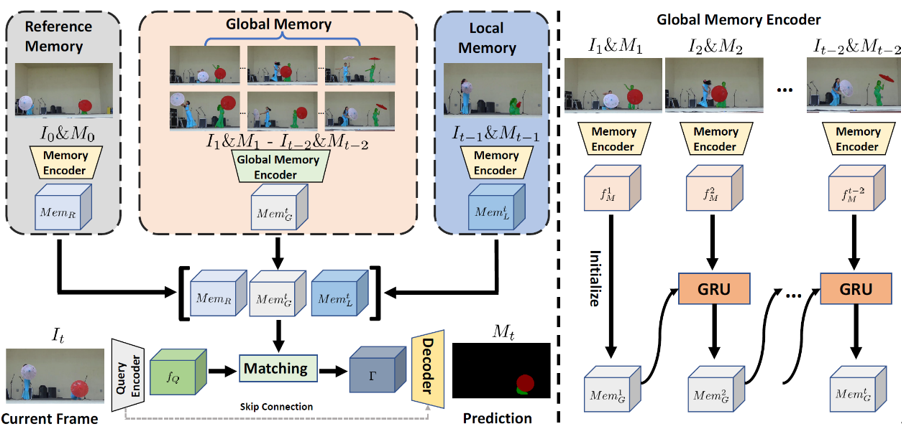
针对于长时视频,我们提出了一个新颖的VOS算法,Diverse Dynamic Memory (DDMemory)。DDMemory包含三个固定大小的记忆模块,分别是参考记忆,全局记忆和局部记忆。通过记忆模块,DDMemory将全局的时序信息压缩到三个固定大小的记忆特征中,在保持高准确率的同时实现了低GPU显存占用和高效率。在分割当前帧时,当前帧图像特征会与三个记忆模块特征进行匹配,并根据匹配结果输出掩膜预测。参考记忆存储第一帧的图像和掩膜信息,参考记忆负责物体消失或者遮挡之后的找回。局部记忆会随着视频不断更新,存储前一帧的图像和掩膜,为当前帧的分割提供位置和形状的先验。而全局记忆利用了全局记忆编码器,通过循环网络的形式,有效地将全局历史信息存储在一个固定大小的特征中,实现对于时序信息的高效压缩和对冗余噪声干扰的排除。
实验:
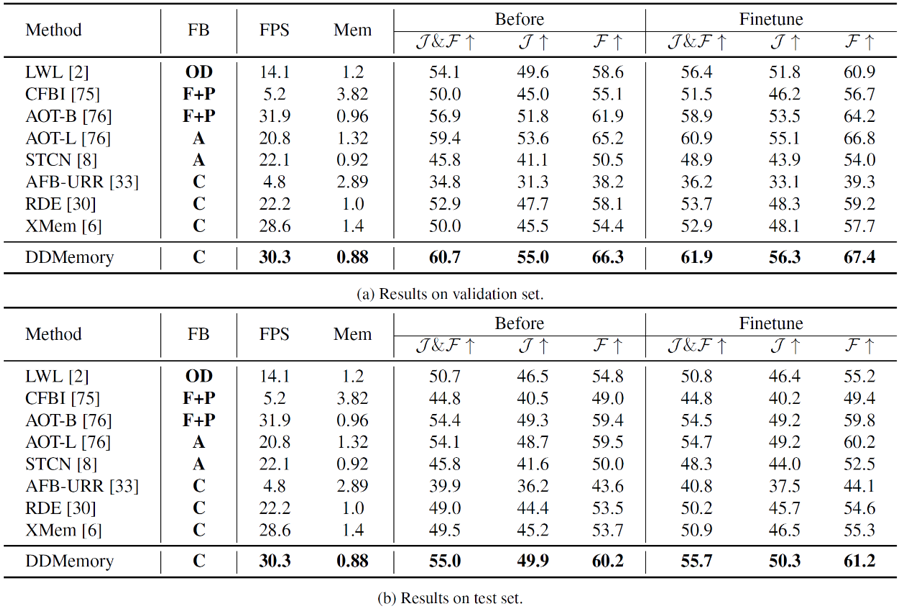
在验证集和测试集上,我们对现有的VOS模型和DDMemory进行了分别评测。从表中可以看到,现有仅在短时视频上训练的VOS模型在长时视频上表现不如人意,而在长时视频上进行了微调之后,性能均有一定的提升。我们提出的DDMemory能够使用最小的GPU显存,在实现最好性能的同时,实现实时的速度(30.3FPS)。实验结果表明,现有的VOS模型对于真实场景表现较差,且由于缺少面向真实场景的数据集,在一定程度上限制了现有VOS模型的发展,也证明了LVOS数据集的价值。

我们也进行了oracle实验,给定真实的位置和掩膜,模型的性能都会有所提升。在分割当前帧时,给定目标物体的真实位置,性能能够提升8.3%。而在记忆模块更新时,使用真实掩膜来代替预测掩膜进行更新,预测性能能够提升20.8%。但是即使给定目标物体的真实位置和掩膜,模型预测结果仍然和真实结果存在较大差距。实验表明,错误累计以及真实场景视频中复杂的物体运动对VOS模型仍然是尚未解决的挑战,且这些挑战在现有短时视频数据集中并不明显,却在真实场景下对VOS算法性能有着巨大的影响。
总结
针对于真实场景,我们构建了一个新的长时视频目标分割数据集LVOS,LVOS中的视频物体运动更加复杂,对于VOS模型的能力有着更高的要求,且比现有的短时数据集更加贴近实际应用。我们对现有的VOS算法进行了测试和比较,发现现有的VOS模型并不能很好地解决长时视频中的挑战。基于LVOS,我们也分析了现有方法的缺陷以及一些可能的改进方向。希望LVOS能够为面向真实场景的视频理解研究提供一个平台。
-
算法
+关注
关注
23文章
4644浏览量
93670 -
数据集
+关注
关注
4文章
1212浏览量
24964 -
VOS
+关注
关注
0文章
22浏览量
8165
原文标题:ICCV 2023 | 复旦开源LVOS:面向真实场景的长时视频目标分割数据集
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
鸿蒙开源全场景应用开发资料汇总
复旦微电子学院杨帆:介绍openDACS物理设计&建模验证SIG,发布开源Verilog Parser
广泛应用的城市语义分割的数据集整理
如何在信息熵约束下进行视频的目标分割资料详细概述


港中大IDEA开源首个大规模全场景人体数据集Human-Art
语义分割数据集:从理论到实践
PyTorch教程-14.9. 语义分割和数据集

最全自动驾驶数据集分享系列一:目标检测数据集

SAM-PT:点几下鼠标,视频目标就分割出来了!






 工商网监
工商网监
评论