 盘点:AI大模型背后不同玩家的网络支撑
盘点:AI大模型背后不同玩家的网络支撑
“没有好网络,别玩大模型。”
随着AI大模型“百花齐放”,底层的算力需求与日俱增。目前,AI大模型的训练参数已飙升至万亿级别,如此庞大的训练任务无法由单个服务器完成,需要大量服务器作为节点,通过高速网络组成算力集群,相互协作完成任务。这些服务器通过网络相连接,不断交换数据。
AI大模型需要一个超大规模、超高带宽、超强可靠的网络,为训练提供强有力的支持。因此,高性能与高可用的网络对 AI 大模型的构建尤为重要。
高性能网络并非一蹴而就,其背后需要有从架构设计到芯片方案等诸多细节的配合。本文盘点了部分互联网厂商、设备厂商、芯片厂商以及运营商在AI大模型底层网络支撑方面所做的工作与进展。
*以下公司排名不分先后
互联网公司
腾讯云
4月,腾讯云发布了新一代HCC高性能计算集群,为大模型训练提供高性能、高带宽、低延迟的智算能力支撑。6月,腾讯云进一步披露了HCC高性能计算集群背后的网络底座——星脉。
星脉是腾讯云数据中心网络架构的第三次进化,具备3.2T 通信带宽,能提升 40% 的 GPU 利用率,节省 30%~60% 的模型训练成本,进而为 AI 大模型带来 10 倍通信性能提升。基于腾讯云HCC,可支持 10 万卡的超大计算规模。
据介绍,腾讯对大模型集群网络做了以下几大优化:
1. 采用高性能 RDMA 网络。腾讯自研的星脉 RDMA 网络,可以让 GPU 之间直接进行数据通信,CPU 资源得以节省,从而提高计算节点的整体性能和效率。
2. 自研网络协议TiTa。腾讯云通过自研端网协同协议 TiTa ,使星脉网络可以实现 90% 负载 0 丢包。TiTa 协议内嵌拥塞控制算法,以实时监控网络状态并进行通信优化,使得数据传输更加流畅且延迟降低。
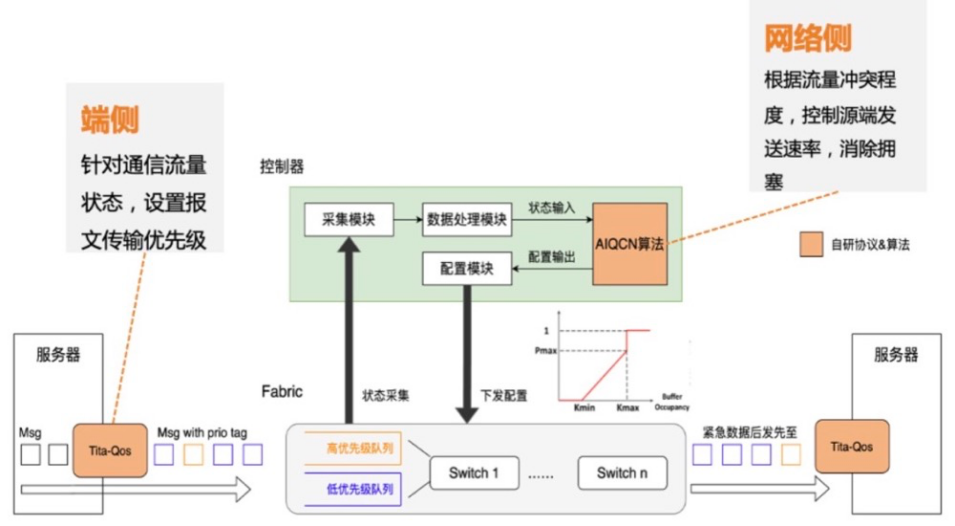
3. 定制化高性能集合通信库 TCCL。腾讯云为星脉定制了高性能集合通信库 TCCL,相对业界开源集合通信库,可以提升 40% 左右的通信性能。
4. 多轨道网络架构。星脉网络对通信流量做了基于多轨道的流量亲和性规划,使得集群通信效率达 80% 以上。
5. 异构网络自适应通信。星脉网络将机间(网卡 + 交换机)、机内(NVLink/NVSwitch 网络、PCIe 总线网络)两种网络同时利用起来,达成异构网络之间的联合通信优化,使大规模 All-to-All 通信在业务典型 message size 下的传输性能提升达 30%。
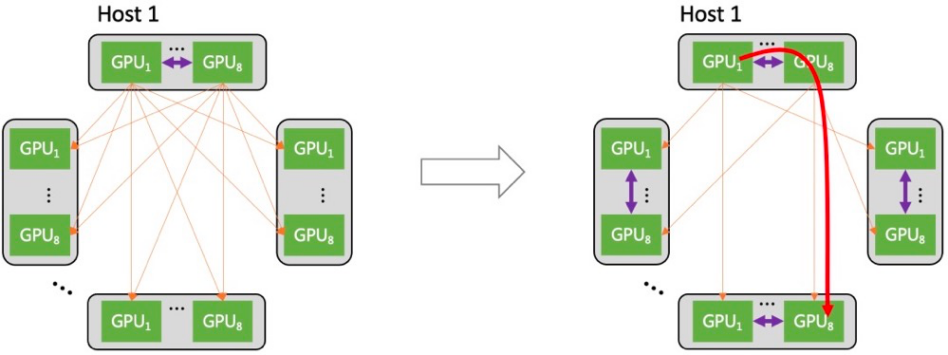
6. 自研全栈网络运营系统。腾讯云自研了端到端全栈网络运营系统,实现了端网部署一体化以及一键故障定位,提升高性能网络的易用性,进而通过精细化监控与自愈手段,提升可用性,为极致性能的星脉网络提供全方位运营保障。
阿里云
面对日益爆发的算力需求,简单粗暴的硬件堆砌已不可持续。为此,阿里云基础设施推出低延时、高带宽、可线性扩展的“磐久高性能网络PredFabric”。
磐久PredFabric采用自研的Solar-RDMA高速网络协议,使处理器可以通过load/store指令访问其他任意服务器的内存,非常适合深度学习模型内神经网络的交互形态,相比传统模式故障自愈时间和长尾时延均可降低90%。同时,结合网络协议硬件化、芯片化,使整体性能得到极大提升,延时最低可至2微秒,并实现高算力下网络规模的线性扩展。
基于这套超高性能网络技术及软硬一体化能力,同年阿里云推出了新一代高性能AI训练计算平台——灵骏。据悉灵骏可最小化所有非计算开销,实现5倍的通信性能提升,千卡并行计算效率高达90%。
此外,灵骏还具有以下特点:
一云多芯:支持国产化CPU/GPU芯片,通过自研“共中心架构”,解决多芯融合及跨代兼容问题。
融合算力池:基于云原生技术体系,实现异构算力资源池化(eGPU),使资源利用率提升3倍,最小化数据搬迁成本,加速AI研发过程;多元化算力支持混合负载,满足人工智能等多领域应用混合部署。
深度性能优化:建立万卡级计算系统的通信与调度能力。自研RDMA高速网络架构,将时延显著降低90%;自研通信库(C4),结合自研硬件,对超大规模AI计算系统提供无拥塞、高性能的通信环境;针对数据密集型场景,通过自研系统软件KSpeed,最高可将系统IO性能提升10倍。
绿色低碳:支持自研单相浸没液冷技术,PUE最低可至1.09,能耗最高可降低50%。
据悉,阿里云在张北和乌兰察布分别建设有两座超级智算中心,规模超过了谷歌和特斯拉。不仅如此,阿里还拥有自研的芯片含光800和倚天710,能够为AI大模型提供算力支撑。
百度云
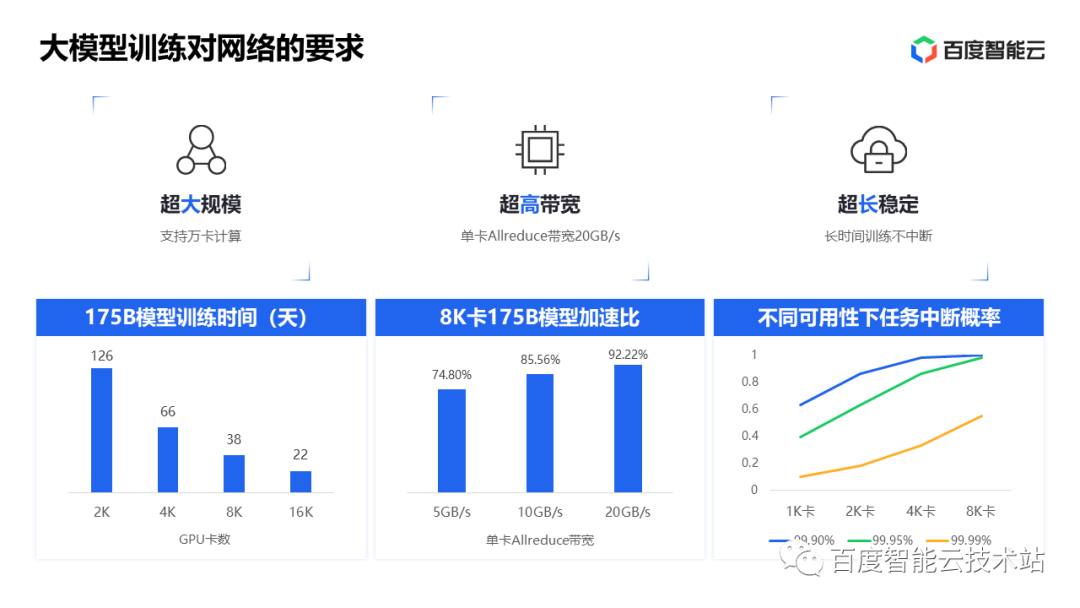
早在 2021 年 6 月,为了满足未来的大模型训练任务,百度智能云开始规划全新的高性能 GPU 集群的建设,联合英伟达共同完成了可以容纳万卡以上规模的 IB 网络架构设计,集群中节点间的每张 GPU 卡都通过 IB 网络连接, 并在 2022 年 4 月将集群建设完成,提供单集群 EFLOPS 级别的算力。
2023 年 3 月,文心一言大模型在这个高性能集群上诞生,并不断迭代出新的能力。目前,这个集群的规模还在不断扩大。与此同时,大模型训练对网络也提出了要求。百度 AI 高性能网络的三大目标:超大规模、超高带宽以及超长稳定。
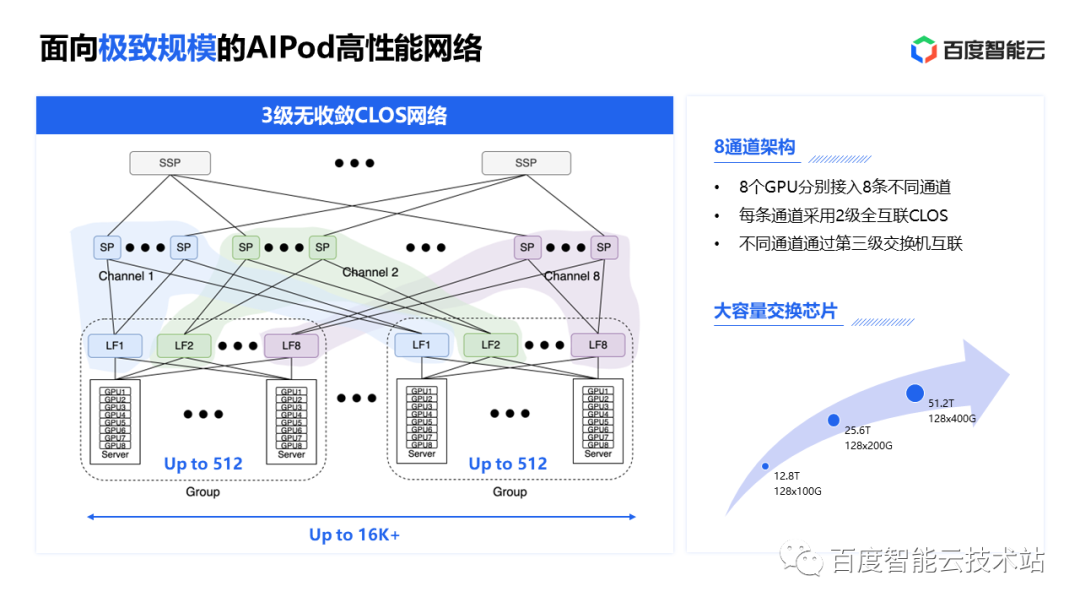
百度AI 高性能网络 AIPod有约 400 台交换机、3000 张网卡、10000 根线缆和 20000 个光模块。其中仅线缆的总长度就相当于北京到青岛的距离。AIPod 网络采用 3 层无收敛的 CLOS 组网结构。
AIPod 网络采用了 8 通道的架构,每个服务器上的 8 个网口对应 8 个 GPU,分别连接 8 个不同的 Leaf 交换机,每个通道内 Spine 交换机和 Leaf 交换机之间做 fullmesh 全互联,一个集群最大可以支持超过 16K GPU。跨通道的通信通过 SuperSpine 把不同的通道的 Spine 交换机连接起来,打通各个通道。
在带宽方面,为了减少跨交换机的通信,AIPod采用了网络架构感知的方法,允许上层感知到当前 GPU 在网络架构的什么位置,归属于哪一个汇聚,让训练任务调度的时候把同一个任务尽可能调度在同一个汇聚组下。当通信不在一个汇聚组内时,通过汇聚组信息对全局 GPU 做有序化处理,让通信库在构建 Allreduce 拓扑图时,减少跨交换机的互通流量。
在稳定性方面,AIPod 网络着重构建快速从硬件故障中恢复的能力。其基于百度自研交换机设计了 AIPod 网络的黑盒探测机制,保障各种网络问题被第一时间感知。此外还通过基于百度自研交换机的 Telemetry 遥测技术,搭建了无损网络的性能透视平台,确保网络内的任一丢包信息和 PFC、缓存的异常变化都能被迅速感知到。
谷歌
谷歌从2016年推出TPU v1开始布局AI模型算力,TPU v4的算力水平全球领先。与传统处理器不同,TPU v4 没有专用的指令缓存,它采用类似于 Cell 处理器的直接内存访问 (DMA) 机制。
TPU v4利用了OCS 来快速实现不同的芯片互联拓扑。OCS 能够动态重新配置其互连拓扑,以提高规模、可用性、利用率和性能。与 Infiniband 相比,OCS 的成本更低、功耗更低、速度更快。TPU v4主要与Pod相连发挥作用,每一个TPU v4 Pod中有4096个TPU v4单芯片,得益于OCS独特的互连技术,能够将数百个独立的处理器转变为一个系统。
8月29日,谷歌宣布推出新一代TPU v5e ,与 TPU v4 相比,TPU v5e 可为LLM和新一代 AI 模型提供高达 2 倍的训练性能和高达 2.5 倍的推理性能,并且成本还不到 TPU v4 的一半。
在NSDI2022会议上,谷歌发布了数据中心分布式交换架构Aquila。Aquila将超低延迟作为核心设计目标,同时也支持传统的数据中心业务。Aquila使用了一种新的二层基于单元的协议、GNet、一个集成交换机和一个定制的ASIC,ASIC和GNet一同设计,并具有低延迟远程存储访问(RMA)。
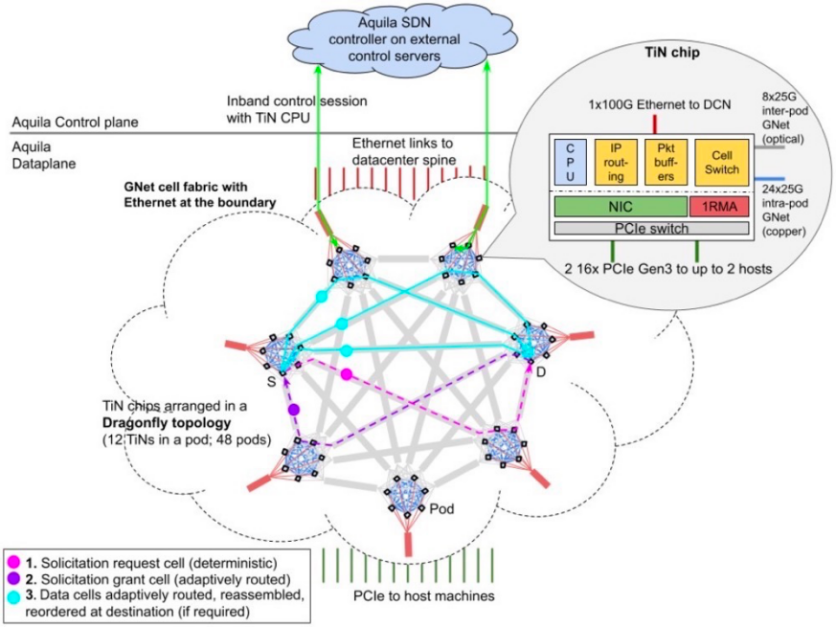
此前,谷歌还提出了下一代人工智能架构 “Pathways” 。Pathways旨在提高异构AI加速芯片集群上的数据处理效率。随着大模型语料规模、算力规模、参数规模的不断上升,简单的数据并行(将数据分成不同份,每份在一个计算集群上进行训练)已难以满足大模型训练的需求,例如PaLM即采用了数据并行与模型并行(将模型按层分成不同份,每份在一个计算集群上进行训练)相结合的方式提升训练效率。

Meta
近日,MIT和Meta团队发布了名为“Rail-Only”的全新大语言模型架构设计,对专门用于训练大型语言模型的 GPU 集群的传统any-to-any网络架构提出了挑战。
Rail-Only架构通过将GPU分组,组成一个高带宽互联域(HB域),然后再将这些HB域内的特定的GPU跨接到特定的Rail交换机,虽然增加了跨域通信的路由调度复杂度,但是通过合理的HB域和Rail交换机设计,整体架构可以大量减少交换机的使用,最多可以降低75%的网络通信耗费。
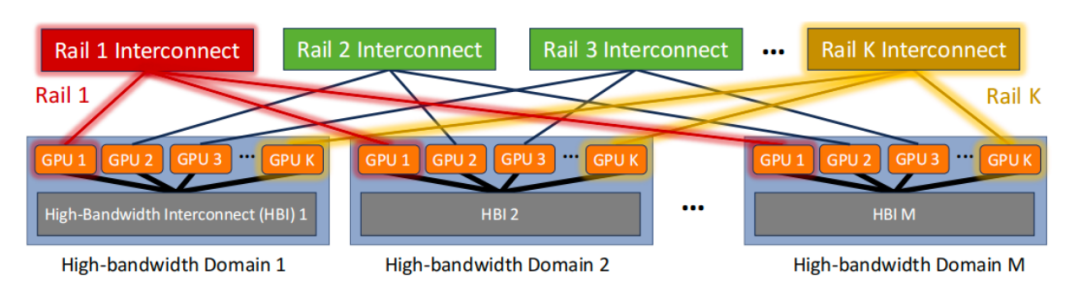
与传统的Rail-Optimized GPU集群相比,Rail-Only保留了HB域,并仅在同一Rail上提供连接。实现Rail-Only架构的一个简单方法是,删除传统基于Rail-Optimized的any-to-any网络架构中的Spine交换机,并将连接Rail交换机到Spine的所有上行链路重新用作到GPU的下行链路。因此,每个Rail都由专用且独立的Clos网络连接。Rail-Only网络架构消除了不同Rail中具有不同等级GPU之间的网络连接。
未来,Meta还将针对人工智能工作负载开发新的数据中心架构,以及开发用于运行人工智能模型的自研定制芯片。新数据中心将采用人工智能优化设计,支持液冷人工智能硬件和高性能人工智能网络,将数千个人工智能芯片连接在一起,形成数据中心规模的人工智能训练集群。
此外,Meta表示正在开发人工智能超级计算机,以支持下一代人工智能模型的训练、增强现实工具并支持实时翻译技术。
设备厂商
华为
华为CloudFabric智能无损网络通过AI Ready的硬件架构及AI智能无损算法,为AI人工智能、存储、HPC高性能计算等应用场景提供提供“无丢包、低时延、高吞吐”的网络环境,加速计算和存储的效率。
边缘网络级智能采用独创拥塞调度算法:动态拥塞水线、虚拟输入队列和快速拥塞反馈,实现定时获取流量特征、网络状态实时监测和动态基线智能调整。
核心计算级智能采用华为独创iLossless智能无损算法,该算法采用逐流业务感知,不仅可以感知网络的PFC帧数、队列出口利用率等,还可以感知业务的AI训练、高性能数据库等。
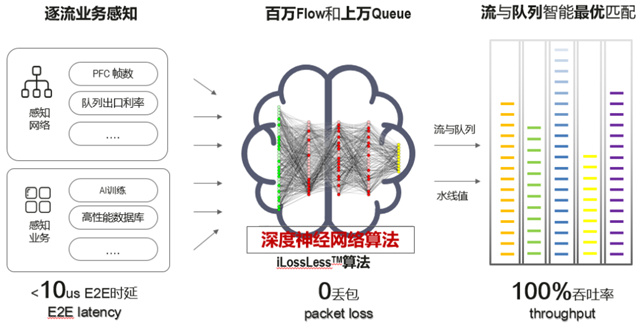
iLosslessTM 智能无损交换算法
此外,华为还面向AI智算场景推出了星河AI网络。星河AI网络通过独创的网络级负载均衡(NSLB)、网络智能调优AI ECN以及数据面故障快速收敛等创新技术,为客户打造高吞吐、低时延、高可靠的AI智算网络。
星河AI网络融合运得多、运得快、运得稳三大优势,为客户提供了大规模、高吞吐、高可靠的网络建设。目前,华为星河AI网络解决方案已在全球100+个人工智能计算中心成功商用部署。
运得多:大带宽,大组网。AI大模型中适配万卡集群是网络最基本的要求,华为打造端到端200GE/400GE设备构建大带宽AI无损网络,4倍于业界规模,完美匹配AI场景诉求,支撑网络运得多。
运得快:高吞吐,性能加速。华为采用算网一体化的方式部署,效率可以提升10倍以上,整个过程自动校验0配置差错。独创AI网络加速器,大大提高网络吞吐,保障网络运得快。
运得稳:月级训练不中断。大规模高性能网络的运维是一大难题,华为采用智能化运维保证训练全程实时可视,分钟级识别慢主机(丢包、超时延),保障集群持续稳定运行,月级训练无中断,护航网络运得稳。
华为在各单点创新的基础上,充分发挥云、计算、存储、网络、能源的综合优势,进行架构创新,以“DC as a Computer”的理念推出昇腾AI集群。目前,昇腾AI集群已支撑全国25个城市的人工智能计算中心建设,其中7个城市公共算力平台入选首批国家“新一代人工智能公共算力开放创新平台”。
近期,华为宣布昇腾AI集群全面升级,集群规模从最初的4000卡集群扩展至16000卡,是业界首个万卡AI集群,拥有更快的训练速度和30天以上的稳定训练周期。
思科
AI大模型的爆发开辟了构建AI算力的新战场,这对网络也提出了全新的要求。思科正在通过 Silicon One 芯片和网络架构的创新,帮助客户构建面向未来的高性能、可扩展且高效率的新一代 AI 数据中心网络。思科 Silicon One 的统一芯片架构优点使得客户可以通过软件定义的方式将 AI 数据中心网络配置成为三种模式:1)基于 ECMP 的标准以太网;2)增强以太网;3)全调度分布交换(Distributed Switch Fabric, DSF)以太网(VOQ+逐包负载分担)

Silicon One 可以灵活支持多种架构,客户不需要在网络建设的第一天就固化技术演进路线图,可以根据业务的不断发展采集网络传输的实际数据,并做出数据驱动的技术决策。而 Silicon One 的 P4 可编性程架构通过软件迭代持续支持未来不同 AI 模型业务的需求与发展。
为了分析不同网络架构对 AI 任务的执行效能的影响,思科创建了一个小型训练集群模型,其中包含 256 个 GPU、八个架顶 (TOR) 交换机和四个主干(SPINE)交换机。通过使用一个 all-to-all 集约通讯来传输 64MB 的集约数据,通过改变网络上同时运行的 AI 任务数量,以及 TOR 到 SPINE 设备互联链路带宽的加速比来测量最终 AI 作业完成时间(JCT)以考察不同网络架构的性能差异。
另一方面,DSF 网络架构提供了完全无阻塞的通讯性能,并且网络不会暂停 GPU 发送流量。这意味着对于相同的物理网络,采用 DSF 架构可连接的 GPU 数量是 ECMP 以太网架构的两倍。这大大地提高了网络的效率、降低了成本。
此外,思科 Silicon One 同样可以支持遥测(INT)增强的 AI 以太网架构, 这种架构的目标是通过在数据包内部插入沿途网络设备的数据拥塞位置与程度的信息,向收发侧的服务器或采集器节点发出业务路径、拥塞信号,从而可以快速、主动改进负载均衡决策来提高标准以太网 ECMP 的吞吐性能,并降低时延,避免丢包。上述三种网络架构采用的各种技术的相对优点因客户而异,并且可能会随着时间和不同业务需求的变化发生改变。
中兴
2022 年,中兴通讯推出星云 1.0 解决方案,基于数字星云的架构,可以替代已有的“烟囱”数据,形成数据共享。2023 年,中兴通讯进一步发布数字星云 2.0,提供更强大的接入集成、计算存储、数据治理和共享交易能力服务,可以在数据处理、AI 训练、AI 推理部署三大环节,帮助企业节省算力资源、 提升算力使用效率。数字星云 2.0 将在数智时代高价值场景发挥更为明显的优势。同时,在生成式 AI 方面的能力提升将成为数字星云未来发展的长期规划。
此外,在网络方面,中兴通讯采用了高速“无损”网络,实现了AI算力的“无损”。以DPU为中心,基于无损交换机的高性能RDMA网络,构建了超大规模算力集群。引入NEO智能云卡,服务器可实现单节点800Gbps转发性能、微秒级时延,从而突破了节点间网络瓶颈,可以将 GPU集群算力发挥到极致。
在服务器方面,中兴通讯全系列服务器支持GPU和液冷,可以以极致低耗构建大模型计算资源池,使数据中心的PUE降到1.13以下。中兴通讯已经推出R6500G5 GPU服务器,最大支持20个GPU; 今年底,还将推出更高性能的R6900G5 GPU训练服务器。
在存储方面,中兴通讯提供高带宽多元融合存储,以满足AI训练多态数据存储需求。中兴通讯提供分布式磁阵和高端全闪磁阵组合方案,兼顾了大容量和高性能需求,同时提供文件、对象和块等多元存储。此外,通过NEO智能云卡卸载高性能存储传输协议NVMe,实现了3M IOPS的存储性能。
中兴表示未来将重点投入三个产品方向:
1. 公司新一代智算中心基础设施产品,全面支持大模型训练和推理,包括高性能 AI 服务器、高性能交换机、DPU 等;
2. 下一代数字星云解决方案,利用生成式 AI 技术,在代码生成、办公和运营智能化等领域展开研究,全面提升企业效率;
3. 新一代 AI 加速芯片、模型轻量化技术,大幅降低大模型推理成本。
新华三
新华三集团凭借在企业网络领域20多年的深厚积累,针对AI大模型和AIGC热潮,有着自己的体系化思考,也布局了很多技术。6月,新华三集团发布了全新的智算解决方案,全面助推AI业务加速前行。

异构算力:提供异构的多元AI算力,主要有商业英伟达GPU(主)、国产AI计算加速卡,在大规模分布式训练为主的场景(如NLP),主推R5500G5机型服务器,该机型内部AI计算加速卡为OAM模组形态,训练时服务器内部以高速互联协议传输数据,节点之间可支持8张100G RoCE网卡与其他节点互联,形成AI集群;在小规模训练为主的场景(如小型CV),可以选用R5300G5,此机型主要支持PCIE款型AI加速卡,内部通过PCIESwich互联,成本较低,可适配的AI加速卡款型较多。
海量存储:分为冷热数据,冷数据以存档为主,通过OneStor的对象存储提供,对象存储有读取方便(HTTP协议)、不可在线编辑、集群大的优势,可为用户提供数据集、镜像、算法、模型的廉价归档空间;热数据以分布式并行文件存储为主,通过CX8028/CX5036提供,分布式文件存储具有IOPS高、延迟低的特性,可为大规模训练提供高性能的数据集、训练临时数据的读写空间。
无损网络:支持RoCEv2协议,主要设备为S9820-8C,可提供100G/400G速率的端口。单台设备提供128个100G端口的能力,支持16台R5500G5服务器接入,算力规模可达80P 峰值算力。
锐捷
锐捷针对AIGC算力、GPU利用率与网络的关系,以及主流HPC组网面临的挑战,推出了“智速”DDC(Distributed Disaggregated Chassis,分布式分散式机箱)高性能网络方案,并计划于今年推出两款可交付产品,分别是400G NCP交换机和200G NCF交换机。
DDC是一种分布式解耦机框设备的解决方案,它将传统软硬一体的框式设备的组件进行拆解,以NCP替代传统框式设备的线卡板,以NCF替代交换网板,并通过光纤互联替代原先两者之间的连接器组件;传统框式设备的控制管理引擎也独立出来,可以以软件化的方式灵活部署于任何一台标准服务器或多台服务器,能有效节省部署成本,提升系统冗余性和可靠性。
DDC方案突破了传统框式设备的资源限制,让大规模组网化繁为简,不仅具有扩展弹性、扩容升级快、单机功耗低、运维管理效率高等特点,可灵活支持AI集群大规模部署,而且具有集群路由设计简单、数据转发方式更优化等优势,能有效提升网络通信性能。
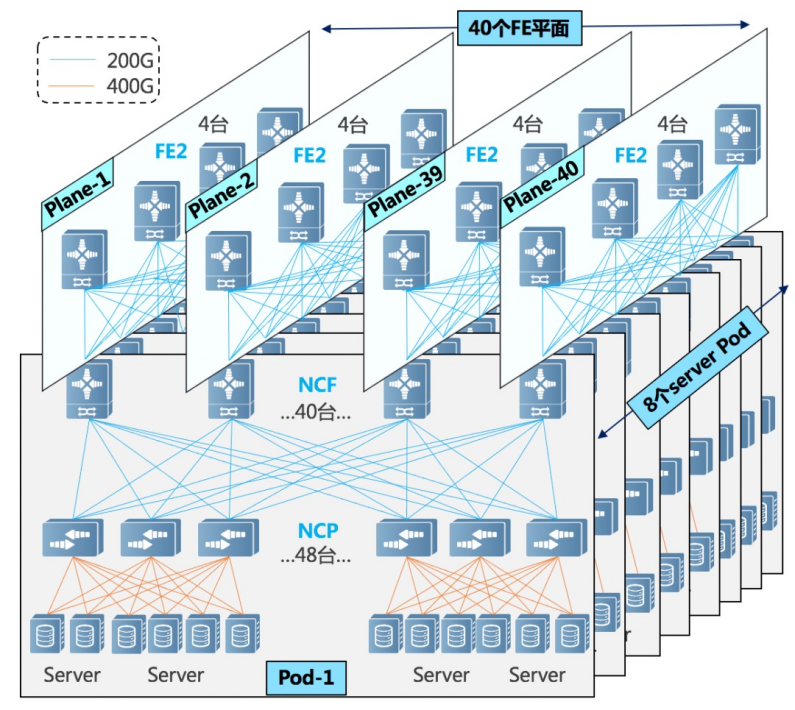
在支持AI集群超大规模部署方面,在单POD组网中,采用96台NCP作为接入,其中NCP下行共18个400G接口,负责连接AI计算集群的网卡。上行共40个200G接口最大可以连接40台NCF,NCF提供96个200G接口,该规模上下行带宽为超速比1.1:1。整个POD可支撑1728个400G网络接口,按照一台服务器配8块GPU来计算,可支撑216台AI计算服务器。
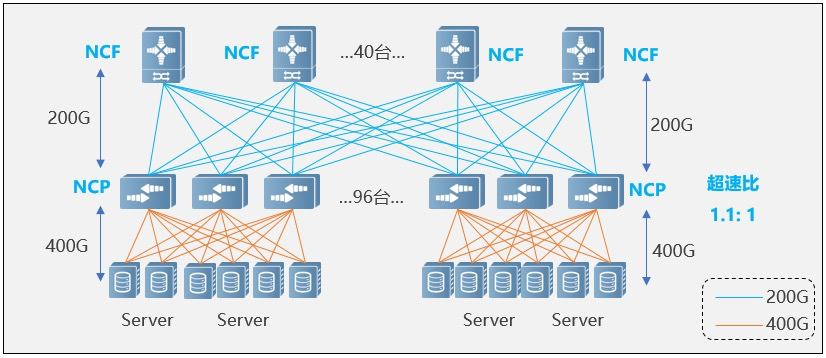
在多级POD组网中,可以实现基于POD的按需建设。考虑该场景POD中NCF设备要牺牲一半的SerDes用于连接第二级的NCF,单POD采用48台NCP作为接入,下行共18个400G接口,单POD内可以支撑864个400G接口。通过横向增加POD实现规模扩容,整体最大可支撑6912个400G网络端口。
浪潮
浪潮认为要解决超大规模、超高带宽、超强可靠的“三超”网络的挑战,就需要着重思考如何建设符合大规模训练的组网方案。从组网架构上看,当前AIGC组网一般多采用胖树架构,具有高带宽、低延迟的特性,以及较好的可拓展性。而在组网协议上,当前业界主流的是基于IB及RoCE两种无损网络技术,两种技术都可以很好的满足大规模训练高带宽、低延迟的要求。IB的延迟足够低,而RoCE在开放性、性价比及易维护性等方面更胜一筹。
浪潮推出了基于RoCE的智能无损网络解决方案,助力AIGC“三超”网络的打造,其具备如下优势:
一是多协议、多场景的融合。在大规模集群中,往往存在通用计算集群、AI/HPC集群、存储等多种场景,传统方案是部署以太网、IB、FC等多套网络及多种协议,各协议之间互不兼容,大大增加了管理和维护的难度。
浪潮基于RoCE的智能无损网络解决方案,可以适配通用计算、AI/HPC、存储等多种场景,并实现以太/IB/FC三网融合。这样从维护多张网络到维护一张网络,大大降低了整体建设和维护成本。
二是智能弹性、动态调整。在大规模集群训练中,要求整个集群可以快速部署与交付,在节约训练时间的同时,尽可能减少宕机等故障的发生。
浪潮基于RoCE的智能无损网络解决方案中,通过数字化网络引擎IDE可以实现集群网络的自动化部署,加速业务上线。并实时监控设备与链路的负载和健康状态,如CRC错包,端口带宽百分比、队列缓存,CNP及Pause反压帧等,完成故障的快速定位及智能分析,实现基于业务的网络跟踪。此外,还可以提供北向标准API接口,能够与上层计算平台进行对接,实现算网联动,更好的释放集群算力。
芯片厂商
伴随AI、大数据等新兴技术的崛起,传统通用计算性能愈发捉襟见肘,异构计算成为了整个半导体行业的前行方向。英特尔正考虑如何在异构平台上合理分配负载,以进行AI处理工作。在底层方面,英特尔采用了OneAPI(一种统一编程模型和应用程序接口)思路,利用OneAPI提供的优化库,希望以打包的平台方案整合自家庞杂的产品路线,降低客户对底层硬件差异的敏感度。
英特尔还计划提高网络传输的可靠性,通过更新和创新更高层网络协议来提高以太网传输RDMA协议的可靠性,这个功能将包含在即将发布的下一代IPU中。
针对AI在不同场景、不同环节的异构计算需求,英特尔将其产品线分为通用计算与加速计算。其中,英特尔的CPU产品,第四代至强处理器解决通用计算,可满足客户在大部分模型较小场景的AI推理需求;Gaudi2解决加速计算,可解决大模型的训练及推理需求。
英特尔用来实现AI能力的是一个CPU上首次出现的全新计算模式——VPU,VPU是专门为AI设计的一套架构,能够非常高效地完成一些矩阵运算,而且对稀疏化的处理非常擅长。VPU最大的优势就是在消费端PC上用最快速、最便宜、最低成本的方式实现AI功能。

下半年即将面市的Meteor Lake集成了Movidius视觉处理器,与以往的通过CPU和GPU的人工智能加速指令集去实现人工智能服务不同,这是一个独立的处理单元,在针对人工智能进行加速处理模式中,采用的是“CPU+GPU+VPU“的混合处理方式,通过各个计算单元的特点,将AI处理效率最大力。
在暴涨的AI需求下,博通发布了Tomahawk 5系列网络芯片。由于做到了更高的端口密度,Tomahawk 5可以实现256高性能AI/ML加速器之间的单跳连接,且每个都能做到200Gbps的网络带宽。这对于数据中心的AI训练和推理的负载来说,无疑提高了吞吐效率,尤其是针对日益流行且愈发复杂的生成式AI模型。
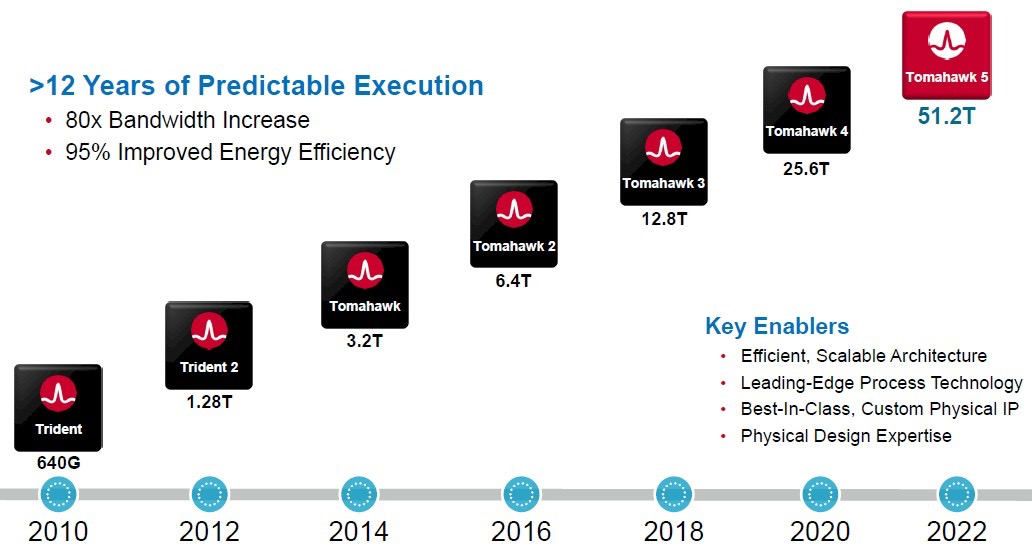
4月,博通发布了Jericho3-AI芯片,用于将超级计算机连接在一起,利用已广泛使用的网络技术进行人工智能工作。Jericho3-AI针对AI训练负载做了特殊的优化,更高的端口密度使得Jericho3-AI可以在单个集群中连接32000个GPU,并做到800Gbps的连接带宽表现。
Jericho3-AI芯片结构设计是为了降低在网络间进行人工智能训练时间。Jericho3-AI 拥有一系列的先进特性,如改进的负载平衡,可以确保在最高网络负载下实现最大的网络利用率,无拥塞操作,无流量冲突和抖动,以及零影响故障转移——确保低于10ns 的自动路径收敛。所有这些特性都将减少AI工作负载的完成时间。

据介绍,Jericho3-AI 的最高吞吐量为 28.8Tb/s。它有 144 个以 106Gbps PAM4 运行的 SerDes 通道,支持多达 18 个 800GbE/36 个 400GbE/72 个 200GbE 网络端口。
博通将其与英伟达自己的InfiniBand方案对比,Jericho3-AI在完成时间上有着10%左右的优势。这也是Jericho系列独有的优势,实现标准以太网芯片无法实现却在AI或HPC应用上被看重的灵活功能。
英伟达
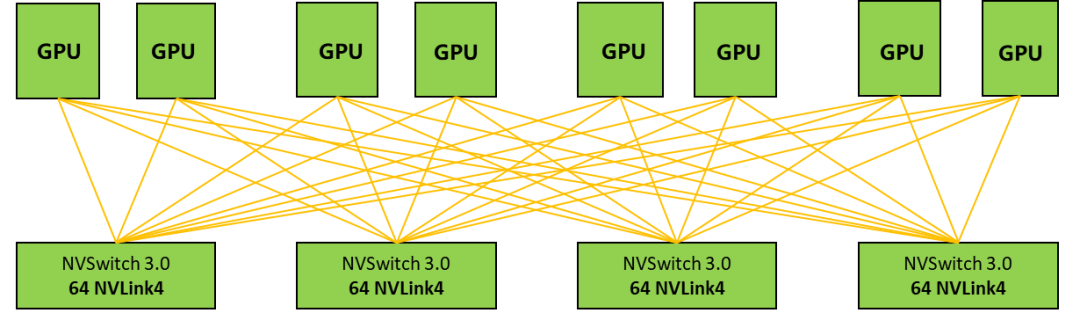
在AI驱动下,英伟达在大规模、大算力、高性能的场景下创造了一个新的网络应用场景,即AI工厂。英伟达首创了NVLink + NVSwitch技术,为多GPU系统提供更加快速的互联解决方案。借助NVLINK技术,能最大化提升系统吞吐量,很好的解决了GPU互联瓶颈。最新的英伟达Hopper架构采用NVLINK4.0技术,总带宽最高可达900GB/s。
今年5月英伟达推出了面向超大规模生成式 AI 的加速以太网平台——Spectrum-X,其拥有无损网络、动态路由、流量拥塞控制、多业务性能隔离等主要特性,能够满足云上部署AI或生成式AI工作负载对网络性能的要求,有助于节约训练成本、缩短训练时间,加速大模型走向面市。
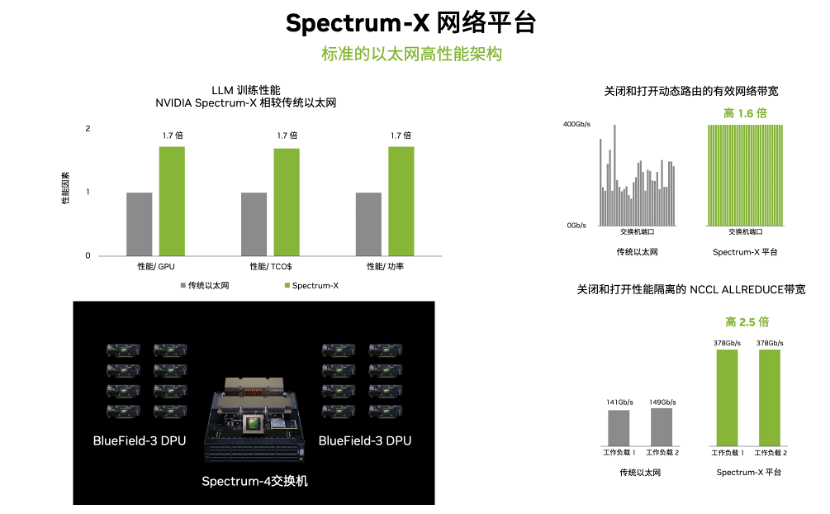
Spectrum-X网络平台采用了国际上先进的Co-Design的技术,将英伟达Spectrum-4以太网交换机与BlueField-3 DPU紧密耦合,实现了相比传统以太网架构1.7倍的整体AI性能和能效提升,并通过性能隔离技术增强了多租户功能运行多任务的性能,在多租户环境中保持与Bare Metal一致、可预测的性能。
基于最新发布的Spectrum-X平台,英伟达构建了生成式AI云超级计算机——Israel-1,实现基于Spectrum-X网络平台的生成式AI云。在其中投入了256 台基于NVIDIA HGX平台的Dell服务器,共包括2048个GPU,并且,配备了2560个BlueField-3 DPU、80 多台 Spectrum-4 以太网交换机。
英伟达的两个网络架构,可以用到不同AI场景,满足不同客户对网络通信的需求:追求超大规模、高性能可以采用NVLink+InfiniBand网络;多租户、工作负载多样性,需融入生成式AI,则用高性能Spectrum-X以太网架构。如果对性能和低延时要求更高,AI云体系架构也可以使用InfiniBand。
Marvell
今年3月,Marvell推出了用于 800 Gb/秒交换机的 51.Teralynx 10交换机芯片。这是一款支持1.6T以太网和800G以太网的交换机芯片。该芯片采用了PAM-4技术和Nova DSP芯片,可以实现更高的速度和更高的可靠性。此外,该芯片还支持多种不同速率的端口,从而实现更高的灵活性和可扩展性。
除了用到业界顶级的112G SerDes IP和先进的工艺实现低功耗的系统设计以外,Marvell宣称Teralynx 10可以提供1.7倍的延迟优势,这对于生成式AI这种看重完成时间和网络传输时间的应用来说至关重要。
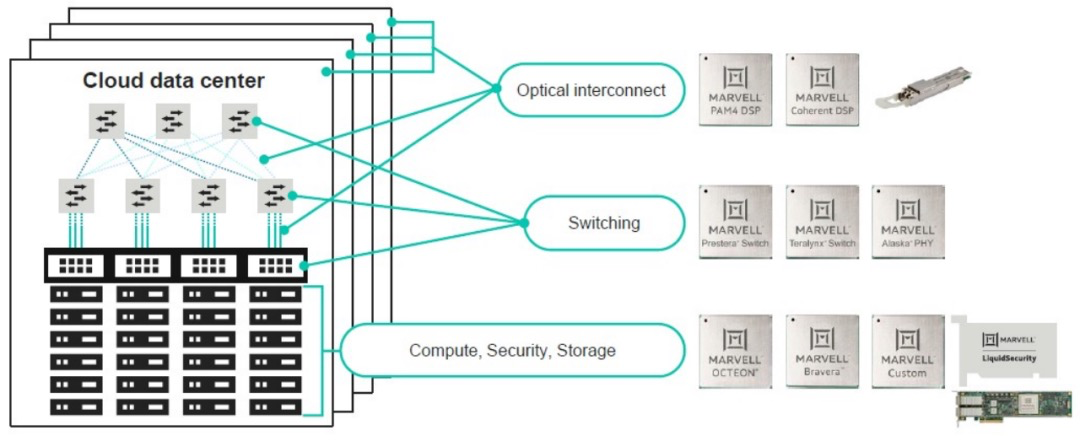
据Marvell介绍,Teralynx 10 旨在解决运营商带宽爆炸的问题,同时满足严格的功耗和成本要求。它可适用于下一代数据中心网络中的 leaf 和 spine 应用,以及 AI / ML 和高性能计算 (HPC) 结构。
据介绍,一个 Teralynx 10 相当于 12 个 12.8 Tbps 一代芯片,由此可以在同等容量下减少 80% 的功耗。Teralynx 10 具有 512 个长距离 (LR) 112G SerDes,有了它,交换机系统可以开发出更全面的交换机配置,例如 32 x 1.6T、 64 x 800G 和 128 x 400G 链路。
运营商
中国移动
中国移动把握算力时代发展脉搏,以网强算提出发展算力网络的全新理念,持续开拓创新,不断提升算力网络发展的高度、广度、深度。今年5月,中国移动联合腾讯等率先发布了《全调度以太网技术(GSE)架构白皮书》,其中详细描述了容器化Packet分发(PKTC)+全局动态调度队列(DGSQ)的技术机制。
容器化Packet分发机制引入分组容器(PKTC)的逻辑概念,而不是单纯的Per Packet分发,在Packet级均衡的基础上能兼顾不同链路Byte级的均衡效果。DGSQ也不同于传统基于VoQ的流量调度,没有采用传统基于端口静态分配,而是基于数据流目标设备端口按需、动态创建,实现全网优化调度。
此外,中国移动加快发展智能算力,以新型智算中心为发力点,打造算力高峰,推动算力网络实现智能跃迁。
新型智算中心(NICC)是以GPU、AI加速卡等智能集群算力为核心集约化建设的E级超大规模新型算力基础设施,具备软硬件全栈环境,是支撑AI大模型的高效训练,推动行业数智化转型升级的基石。相较于传统云数据中心,新型智算中心在算、存、网、管、效五大方面升级,跃迁到更高水平,具备GPU集群算力、多元融合存储、高速无损网络、异构算力池化、高效节能控制五大特征。
面向新型智算中远期发展,中国移动加大算存网管效五大方面技术的融合创新突破,体系化布局攻关“打破异构生态竖井”的算力原生、“突破经典冯氏架构”的存算一体、“突破无损以太性能瓶颈”的全调度以太网、“改变互联网基础架构”的算力路由、“汇聚多样算力”的算力并网等创新技术,打造原创技术策源地。
中国联通
在AI加速行业发展的当下,中国联通在AI领域不断创新,致力于建设云算网一体的信息基础设施,从算力供给、输送、调度和服务四个方面规划算力网络,构建中国联通智算网络。
2023 年 4 月,中国联通研究院、广东联通携手华为建成全栈自主创新AI智算中心,并完成全国首个OSU(光业务单元,Optical Service Unit)灵活入多云的现网验证,实现算网融合发展新突破。
广东联通携手华为打造运营商首个全栈自主创新智算平台,创建算法商城和一体化算力门户交易平台,提供多样性算力服务,并具备全栈自主创新、极简开发、全场景端边云协同和丰富的生态体系四大能力优势:
自主创新的基础软硬件:基于昇腾硬件、欧拉开源操作系统、昇思MindSpore全场景AI框架,CANN异构计算架构等全栈自主创新的基础软硬件支撑原生创新。
极简易用的训推一体平台:提供从训练到推理的一站式AI开发平台,通过昇思AI框架和全流程开发工具包,加速行业算法和应用开发,快速实现AI使能业务能力。
全场景的端边云协同能力:硬件层面均采用统一的达芬奇架构,软件层面支持主流操作系统、多种AI框架,实现增量训练模型迭代,全场景自适应感知与协同。
不断丰富的生态体系:依托智算平台,联合高校、算法厂商等合作伙伴联合创新,孵化AI行业应用,实现产学研用深度融合,构筑成熟AI生态体系。
广东联通在社会算力并网方面也积极实践,实现省内算力协同和生态体系共享;以智算平台为载体,逐步构建区域AI应用创新体系,满足多样性AI应用需求使能千行百业。
中国电信
中国电信正在上海试点新一代智云网络,以高质量、广覆盖大带宽、低时延、云-边-端协同的算力网络为人工智能的大规模应用提供坚实的基础。
2022年,中国电信自研天翼云4.0算力分发网络平台——“息壤”入选国资委央企十大超级工程。目前,“息壤”已全面接入天翼云的多级资源,并与多个合作伙伴实现算力并网,实现基于云原生和跨域大规模调度技术的智能算网调度,为“东数西算”、云渲染、跨云调度、性能压测、混合云AI计算等应用场景,提供多样化、差异化的算力产品形态,满足不同业务需求。
今年来,AI大模型呈井喷式爆发,面对节奏越来越快的技术迭代、创新和升级,坚实的网络基础的重要性愈发凸显。早在去年中国电信就顺应时代趋势和产业发展需求,在AI助力管理应用创新方面,推出全球首款以云网融合为核心架构的“星河AI赋能平台”,这也是业界首个百亿参数级别的城市治理大模型。
中国电信星河AI赋能平台在全球率先以云网融合为核心架构,搭载“全网、区域、边、端”四级算力,拥有31个省级算力集群的人工智能产品和能力平台,可以实现AI能力一键下发、快速部署、全场景应用。
得益于构架层的创新,星河AI实现了算力动态调度、资源高可用、标准开放的API(应用编程接口),能够极速部署安装,集成千余种AI算法能力纳管和封装,满足多样协议视频流智能接入,实现AI能力平台可视化编排。
写在最后
数据中心和算力集群是AI的核心,网络则是它的命脉,它们共同构筑了AI大模型底层网络基础设施,实现了数据和智能的无缝传递。正如身体需要心脏泵血来保持生命,AI也需要这些要素来持续演进,我们应致力于构建更加安全、高效和可靠的网络基础设施,以确保AI的无限潜力能够得以实现。网络不仅是连接,更是创新与合作的桥梁。
-
AI
+关注
关注
87文章
32329浏览量
271430 -
算力
+关注
关注
1文章
1040浏览量
15084 -
大模型
+关注
关注
2文章
2762浏览量
3413 -
AI大模型
+关注
关注
0文章
334浏览量
380
原文标题:盘点:AI 大模型背后不同玩家的网络支撑
文章出处:【微信号:SDNLAB,微信公众号:SDNLAB】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
宁畅AI服务器全面支持DeepSeek大模型
【「大模型启示录」阅读体验】对大模型更深入的认知
巨人网络发布“千影”大模型,加速“游戏+AI”布局
OpenAI世界最贵大模型:昂贵背后的技术突破
AI大模型与深度学习的关系
《AI for Science:人工智能驱动科学创新》第二章AI for Science的技术支撑学习心得
AI大模型与小模型的优缺点
生成式AI与神经网络模型的区别和联系
STM CUBE AI错误导入onnx模型报错的原因?
解锁应用密码,网络基础设施赋能AI大模型
防止AI大模型被黑客病毒入侵控制(原创)聆思大模型AI开发套件评测4






 工商网监
工商网监
评论