 Serverless 冷启动:如何让函数计算更快更强?
Serverless 冷启动:如何让函数计算更快更强?

问题背景
Serverless 计算也称服务器无感知计算或函数计算,是近年来一种新兴的编程模式。其致力于大幅简化云业务开发流程,使得应用开发者从繁杂的服务器运维工作中解放出来(例如自动伸缩、日志和监控等)。借助 Serverless 计算,开发者仅需上传业务代码并进行简单的资源配置便可实现服务的快速构建部署,云服务商则按照函数服务调用量和实际资源使用收费,从而帮助用户实现业务的快速交付(fastbuilt&Relia.Deliv.)和低成本运行。
然而,Serverless 计算的无状态函数编程在带来高度弹性和灵活性的同时,也导致了不可避免的冷启动问题。由于函数通常在执行完请求后被释放,当请求到达时,如果没有可用实例则需要从零开始启动新的实例处理请求(即冷启动)。当冷启动发生时,Serverless 平台需要执行实例调度、镜像分发、实例创建、资源配置、运行环境初始化以及代码加载等一系列操作,这一过程引发的时延通常可达请求实际执行时间的数倍。相对于冷启动调用,热调用(即请求到达时有可用实例)的准备时间可以控制在亚毫秒级。在特定领域例如 AI 推理场景,冷启动调用导致的高时延问题则更为突出,例如,使用 TensorFlow 框架的启动以及读取和加载模型可能需要消耗数秒或数十秒。
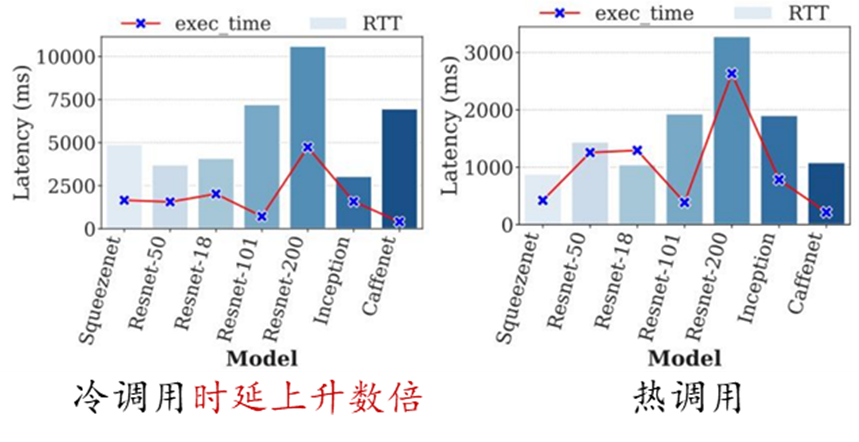
因此,如何缓解 Serverless 函数的冷启动问题,改善函数性能是当前 Serverless 领域面临的主要挑战之一。
解决方案
从研究思路上看,目前工业界和学术界主要从两个方面入手解决冷启动问题:
(1)加快实例启动速度:当冷启动调用发生时,通过加速实例的初始化过程来减少启动时延;
当冷启动发生时,Serverless 平台内部实例的初始化过程可以划分为准备和加载两个阶段。其中,准备阶段主要包括控制面决策调度/镜像获取、Runtime 运行时初始化、应用数据/代码传输几个部分。而加载阶段位于实例内部,包括用户应用框架和代码的初始化过程。在工业界和学术界公开的研究成果中,针对实例启动过程中的每个阶段都有大量的技术手段和优化方法。如下图所示,经过优化,实例冷启动的准备阶段和加载阶段时间可被极大得缩短。
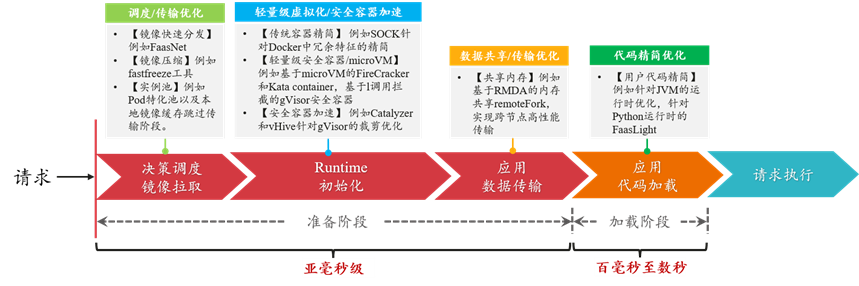
下面列举了一些近年来发表在计算机系统领域知名会议的相关工作,主要可以分为五个方面:
1、调度优化/镜像快速分发/本地池化:
例如基于树结构的跨节点快速镜像分发FaasNet[ATC'21];Pod 池+特化实例跳过镜像传输[华为 FunctionGraph]。其中,快速镜像分发依赖于 VM 节点的上/下行网络带宽,Pod 池特化技术则是典型的以空间换时间的做法。
2、轻量级虚拟化/安全容器:
例如针对传统容器 Docker 的精简优化工作 SOCK[ATC'21];更侧重安全性的轻量级虚拟化技术(KataContainers,gVisor 等);基于安全容器的进一步的精简优化工作(Catalyzer[ASPLOS'20],REAP[ASPLOS'21])。通过裁剪优化,安全容器的启动时延最快可以被压缩至亚毫秒级。
3、数据共享/跨节点传输优化:
例如基于 RDMA 共享内存减少跨节点启动过程的数据拷贝RemoteFork[OSDI'23];或者利用本地代码缓存跳过代码传输[华为 FunctionGraph,字节 ByteFaaS 等]。基于 RDMA 技术的跨节点数据传输时延可降低至微妙级。
4、用户代码精简/快速加载:
例如针对 Java 语言的 JVM(JavaVirtualMachine)运行时优化技术[FunctionGraph];以及针对 Python 运行时库的裁剪优化工作 FaasLight[arxiv'23]。通过特定的优化,JVM 启动时间可由数秒降低至数十毫秒,而 Python 代码的启动加载时延可降低约 1/3。
5、其它非容器运行时技术:
例如 WASM(即 WebAssembly)技术以及针对 WASM 的内存隔离方面的优化工作 Faasm[ATC'20]。相比容器化技术,直接以进程和线程方式组织运行函数,可在保证低开销函数运行的同时具备高度灵活性。
(2)降低冷启动发生率:通过函数预热、复用或实例共享等方法提高实例的利用效率,减少冷启动调用的发生
尽管已有的一些实例启动加速方法已经可以将运行时环境的初始化时间压缩至数十毫秒甚至是数毫秒,然而用户侧的延迟却仍然存在,例如程序状态的恢复,变量或者配置文件的重新初始化,相关库和框架的启动。具体来讲,在机器学习应用中,TensorFlow 框架的启动过程往往需要花费数秒,即使实例运行时环境的启动时间再短,应用整体的冷启动时延对用户而言依然是无法接受的(注:通常大于 200ms 的时延可被用户察觉)。在这种情况下,可以从另一个角度入手解决冷启动问题,即降低冷启动调用的发生率。例如,通过缓存完整的函数实例,请求到达时可以快速恢复并处理请求,从而实现近乎零的初始化时延(例如 Dockerunpause 操作时延小于 0.5ms)。
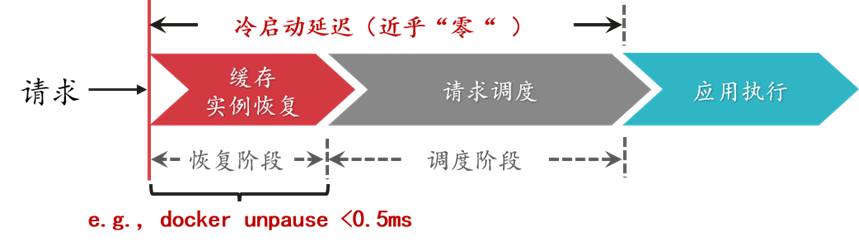
降低冷启动发生率的相关研究可以分为如下几个方面:
1、实例保活/实例预留:
例如基于 Time-to-Live 的 keepalive 保活机制[AWSLambda,OpenWhisk];或者通过并发配置接口预留一定数量的实例[AWSLabmda 等];这些方法原理简单,易于实现,但是在面对负载变化时缓存效率较低。
2、基于负载特征学习的动态缓存:
例如基于请求到达间隔预测的动态缓存方案ServerlessintheWild[ASPLOS'20];学习长短期负载变化特征的动态缓存方案INFless[ASPLOS'22];基于优先级的可替换缓存策略 FaasCache[ATC'21];面向异构服务器集群的低成本缓存方案IceBreaker[ASPLOS'22]。这些动态缓存方案根据负载特征学习决定实例缓存数量或时长,从而在降低冷启动调用率的同时改善缓存资源消耗。
3、优化请求分发提高命中率:
例如兼顾节点负载和本地化执行的请求调度算法CH-RLU[HPDC'22]。通过权衡节点负载压力和缓存实例的命中率来对请求的分发规则进行优化设计,避免节点负载过高导致性能下降,同时兼顾冷启动率。
4、改善并发/实例共享或复用:
例如允许同一函数工作流的多个函数共享 Sandbox 环境SAND[ATC'18];使用进程或线程编排多个函数到单个实例中运行Faastlane[ATC'21];提高实例并发处理能力减少实例创建Fifer[Middle'20];允许租户复用其它函数的空闲实例减少冷启动时间Pagurus[ATC'22]。这些实例共享或者复用技术可以同缓存方案结合使用,降低冷启动带来的性能影响。
总结
Serverless 的无状态设计赋予了函数计算高度弹性化的扩展能力,然而也带来了难以避免的冷启动问题。消除 Serverless 函数的冷启动开销还是从降低函数冷启动率和加速实例启动过程两个角度综合入手。对于冷启动开销比较大的函数,在函数计算框架的设计机制中进行优化,尽量避免冷启动发生;当冷启动发生时,采用一系列启动加速技术来缩短整个过程进行补救。在 Serverless 平台的内部,冷启动的管理在实践中可以做进一步精细的划分,例如针对 VIP 大客户,针对有规律负载的,或是针对冷启动开销小的函数,通过分类做定制化、有目的的管理可以进一步改善系统效率。
审核编辑 黄宇
-
函数计算机
+关注
关注
0文章
3浏览量
6767 -
华为云
+关注
关注
3文章
2837浏览量
19388
发布评论请先 登录
国家先进计算产业创新中心青岛基地正式启动
LX2080释放复位瞬间启动电流过大,有什么办法让CPU核缓启动或者8个核分时依次启动吗?
利用PKC6100A交直流电流探头测试开关电源冷启动峰值电流

单片机启动&库函数的构成
BNC线束 | 精准传输,让信号更快一步




评论