 CPU占用率过高导致系统登录不上问题分析
CPU占用率过高导致系统登录不上问题分析
又是一个百无聊赖的早晨,我在快乐地摸鱼,工作群响了:离线系统登录不上了。我第一反应是不科学啊,系统已经很久改动过了...赶紧上生产环境看看,CPU高达1200%。接着又是熟练地敲出那几行排查CPU过高的命令
top-H-ppid查看java占用率最高的几条线程 jstackpid>xxx.txt打印线程快照 jmap-heappid查看堆内存情况
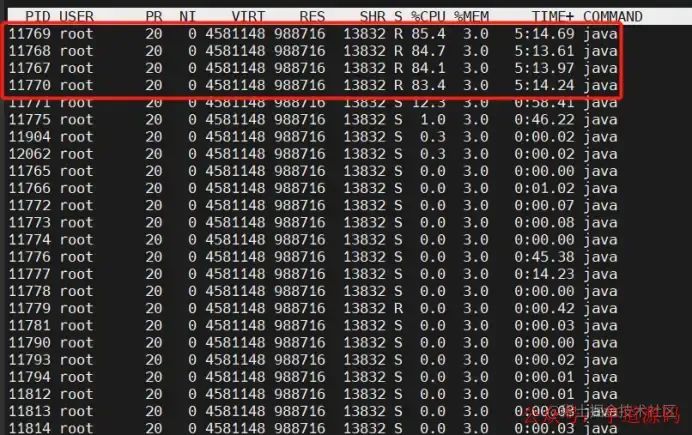 top命令
top命令 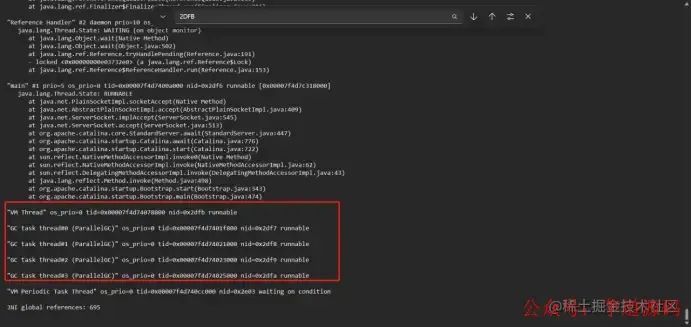 jstack命令
jstack命令 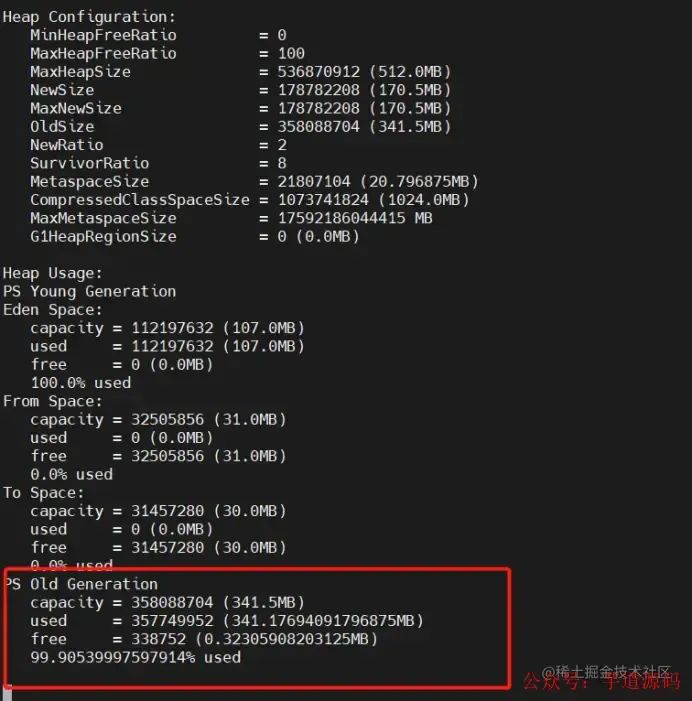 jmap命令
jmap命令
看这玩意啥都看不出来,感觉是系统对象没有释放,在疯狂GC,但是因为FULL GC的时候已经STW了,所以无法查看到底是哪个线程出了问题。然后过了10分钟系统突然又好了....堵塞的操作已经完成,gc能正常回收了。
然后过了两分钟又卡死了,我先重启了系统,后面再分析分析。
等系统没什么人用的时候,我再试着重现一下问题,打开系统一顿乱点,结果是点开某个功能的详情时系统卡住了,CPU又飚上去了,喜闻乐见~问题定位到了,再实锤一下之前是不是这个问题,我看了一下localhost_access_log日志发现,确实是这个接口卡了一千多秒。
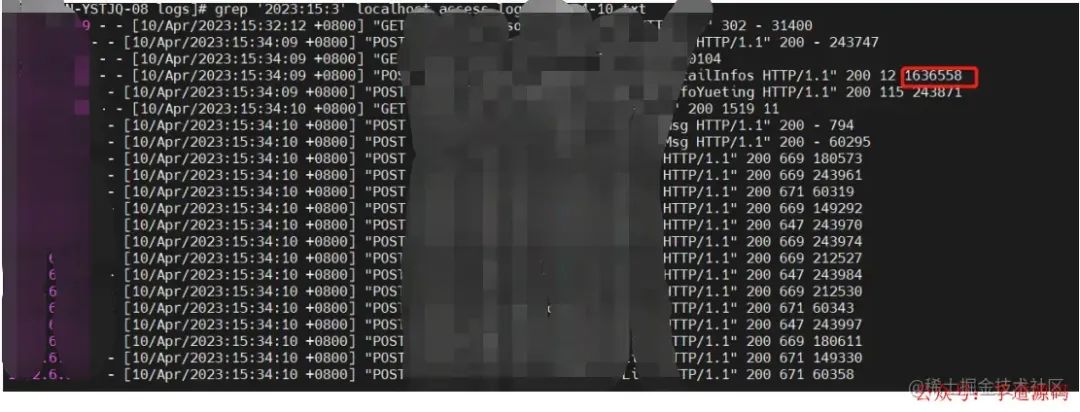 nginx日志
nginx日志
因为离线没什么人使用,所以问题过了很久再暴露出来。看了一下代码,主要是同事业务逻辑问题,有个参数没传进去,导致 sql 走了全表扫描,数据很多,要查很久,查到了几百万的数据,gc 也无法回收。
还好内存够大,要不然早就 OOM 了。
复盘
一开始我以为是某个接口调了很多次并发太高导致的,没想到点一下详情系统就挂了。。我们可以看到CPU在GC回收的时候STW,是没有线程能占用到CPU的,所以top -H -p pid 只能看到CPU全被GC线程占用了。如果是某个接口并发太高导致的,我们可以看jstack线程快照,里面是会有这个接口在执行的记录。
还有一个问题就是说系统GC卡了10-20分钟,却没有报OOM,还是一直在堵塞状态,后面还正常了一小会,这个是需要看堆内存的情况...
因为比较难排查所以只是通过现象知道GC还是可以回收一点点垃圾的
总结
1、CPU100%的时候可以打印线程快照jstack pid,查看是哪个线程占用了CPU,一般都是某个业务线程阻塞无法进行GC回收导致。
2、可以查看localhost_access_log查看系统接口用时,一般用时很久的都是有问题的接口。
3、同事的业务代码参数没有传,导致全表扫描直接卡死系统。
审核编辑:汤梓红
-
cpu
+关注
关注
68文章
10862浏览量
211727 -
内存
+关注
关注
8文章
3024浏览量
74039 -
命令
+关注
关注
5文章
684浏览量
22021 -
代码
+关注
关注
30文章
4787浏览量
68591 -
nginx
+关注
关注
0文章
149浏览量
12173
原文标题:点一下详情系统挂了,CPU 100%
文章出处:【微信号:芋道源码,微信公众号:芋道源码】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
请问为什么am3354 刷新lcd时cpu占用率很高?
Linux的CPU和内存占用率查看
基于IMX6查看Linux下的CPU和内存的占用率
CPU占用率100%的故障解决
Chromebook安装更新Chrome OS或将导致CPU占用率达到100%和发热问题
stm32运用freertos库函数测试各个线程任务信息和cpu占用率






 工商网监
工商网监
评论